BFloat16: The secret to high performance on Cloud TPUs
Shibo Wang
Software Engineer, TPU
Pankaj Kanwar
Technical Program Manager, TPU
Machine learning workloads are computationally intensive and often run for hours or days. To help organizations significantly improve the running time of these workloads, Google developed custom processors called Tensor Processing Units, or TPUs, which make it possible to train and run cutting-edge deep neural networks at higher performance and lower cost.
The second- and third-generation TPU chips are available to Google Cloud customers as Cloud TPUs. They deliver up to 420 teraflops per Cloud TPU device and more than 100 petaflops in a full Cloud TPU v3 Pod. Cloud TPUs achieve this high performance by uniting a well-established hardware architecture—the “systolic array”—with an innovative floating point format.
This custom floating point format is called “Brain Floating Point Format,” or “bfloat16” for short. The name flows from “Google Brain”, which is an artificial intelligence research group at Google where the idea for this format was conceived. Bfloat16 is carefully used within systolic arrays to accelerate matrix multiplication operations on Cloud TPUs. More precisely, each multiply-accumulate operation in a matrix multiplication uses bfloat16 for the multiplication and 32-bit IEEE floating point for accumulation. In this post, we’ll examine the bfloat16 format in detail and discuss how Cloud TPUs use it transparently. Then we’ll take a detailed look at some of the benefits it provides, including higher performance, model portability, and better numerical stability for a wide variety of deep learning workloads.
Bfloat16 semantics
Bfloat16 is a custom 16-bit floating point format for machine learning that’s comprised of one sign bit, eight exponent bits, and seven mantissa bits. This is different from the industry-standard IEEE 16-bit floating point, which was not designed with deep learning applications in mind. Figure 1 diagrams out the internals of three floating point formats: (a) FP32: IEEE single-precision, (b) FP16: IEEE half-precision, and (c) bfloat16.
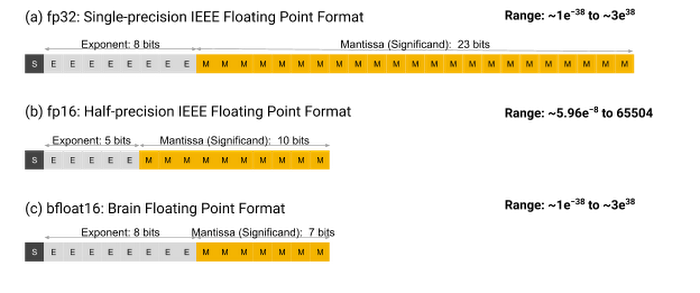
As Figure 1 shows, bfloat16 has a greater dynamic range—i.e., number of exponent bits—than FP16. In fact, the dynamic range of bfloat16 is identical to that of FP32. We’ve trained a wide range of deep learning models, and in our experience, the bfloat16 format works as well as the FP32 format while delivering increased performance and reducing memory usage.
Choosing bfloat16
Our hardware teams chose bfloat16 for Cloud TPUs to improve hardware efficiency while maintaining the ability to train accurate deep learning models, all with minimal switching costs from FP32. The physical size of a hardware multiplier scales with the square of the mantissa width. With fewer mantissa bits than FP16, the bfloat16 multipliers are about half the size in silicon of a typical FP16 multiplier, and they are eight times smaller than an FP32 multiplier!
Based on our years of experience training and deploying a wide variety of neural networks across Google’s products and services, we knew when we designed Cloud TPUs that neural networks are far more sensitive to the size of the exponent than that of the mantissa. To ensure identical behavior for underflows, overflows, and NaNs, bfloat16 has the same exponent size as FP32. However, bfloat16 handles denormals differently from FP32: it flushes them to zero. Unlike FP16, which typically requires special handling via techniques such as loss scaling [Mic 17], BF16 comes close to being a drop-in replacement for FP32 when training and running deep neural networks.
Cloud TPU v2 and Cloud TPU v3 primarily use bfloat16 in the matrix multiplication unit (MXU), a 128 x 128 systolic array. There are two MXUs per TPUv3 chip and multiple TPU chips per Cloud TPU system. Collectively, these MXUs deliver the majority of the total system FLOPS. (A TPU can perform FP32 multiplications via multiple iterations of the MXU.) Inside the MXU, multiplications are performed in bfloat16 format, while accumulations are performed in full FP32 precision.

Mixed-precision training
Deep learning models are known to tolerate lower numerical precision [Suyog Gupta et al., 2015, Courbariaux et al., 2014]. For the overwhelming majority of computations within a deep neural network, it isn’t essential to compute, say, the 18th digit of each number; the network can accomplish a task with the same accuracy using a lower-precision approximation. Surprisingly, some models can even reach a higher accuracy with lower precision, which research usually attributes to regularization effects from the lower precision [Choi et al., 2018].
When programming Cloud TPUs, the TPU software stack provides automatic format conversion: values are seamlessly converted between FP32 and bfloat16 by the XLA compiler, which is capable of optimizing model performance by automatically expanding the use of bfloat16 as far as possible without materially changing the math in the model. This allows ML practitioners to write models using the FP32 format by default and achieve some performance benefits without having to worry about any manual format conversions—no loss scaling or code changes required. While it is possible to observe the effects of bfloat16, this typically requires careful numerical analysis of the computation’s outputs.
Model portability
Thanks to automatic format conversion in TPU hardware, the values of parameters and activations in a model can be stored in full 32-bit format. This means that model portability across hardware platforms is not a concern. Checkpoints obtained from a model trained on Cloud TPUs can be deployed on other hardware platforms (e.g. inference or fine-tuning on CPUs or GPUs) without extensive manual conversions.
This serving tutorial demonstrates how to use TensorFlow Serving to serve a model from a saved checkpoint using the standard IEEE FP32 format. You can also deploy a TPU-trained model on hardware with lower precision arithmetic by using TensorFlow’s robust quantization toolchain.
Achieving even more performance with bfloat16
While automatic format conversion in TPUs lets model developers avoid thinking about numerical precision, further performance improvements can be achieved by manually representing values in bfloat16 format. There are two reasons for this:
Storing values in bfloat16 format saves on-chip memory, making 8 GB of memory per core feel more like 16 GB, and 16 GB feel more like 32 GB. More extensive use of bfloat16 enables Cloud TPUs to train models that are deeper, wider, or have larger inputs. And since larger models often lead to a higher accuracy, this improves the ultimate quality of the products that depend on them. In addition, better compiler trade-offs between compute and memory saving can be achieved, resulting in performance improvements for large models.
Some operations are memory-bandwidth-bound, which means the on-chip memory bandwidth determines how much time is spent computing the output. Storing operands and outputs of those ops in the bfloat16 format reduces the amount of data that must be transferred, improving speed.
Choosing values to represent in bfloat16
When it comes to representing values in bfloat16, you have a choice for each of: weights (parameters), activations, and gradients. Past research [Mic 17] suggested that representing all of these values at lower precision can reduce achieved accuracy, and recommended keeping weights at full-precision FP32.
However, our experience shows that representing activations in bfloat16 is generally safe, though a small amount of special handling may be necessary in extreme cases. Some models are even more permissive, and in these cases representing both activations and weights in bfloat16 still leads to peak accuracy. We typically recommend keeping weights and gradients in FP32 but converting activations to bfloat16. We also advise ML practitioners to run an occasional baseline using FP32 for weights, gradients, and activations to ensure that the model behavior is comparable.
Mixed precision API
Using different precision levels for different types of values in a model can be time consuming for model developers. The TensorFlow team is working on a Mixed Precision API that will make it easier to use a variety of numeric precisions, including IEEE FP16 and other common floating point formats. Until that is ready, because bfloat16 is often a drop-in replacement for FP32, you can use the special bfloat16_scope() on Cloud TPUs today. Here’s an example from ResNet:
Performance wins
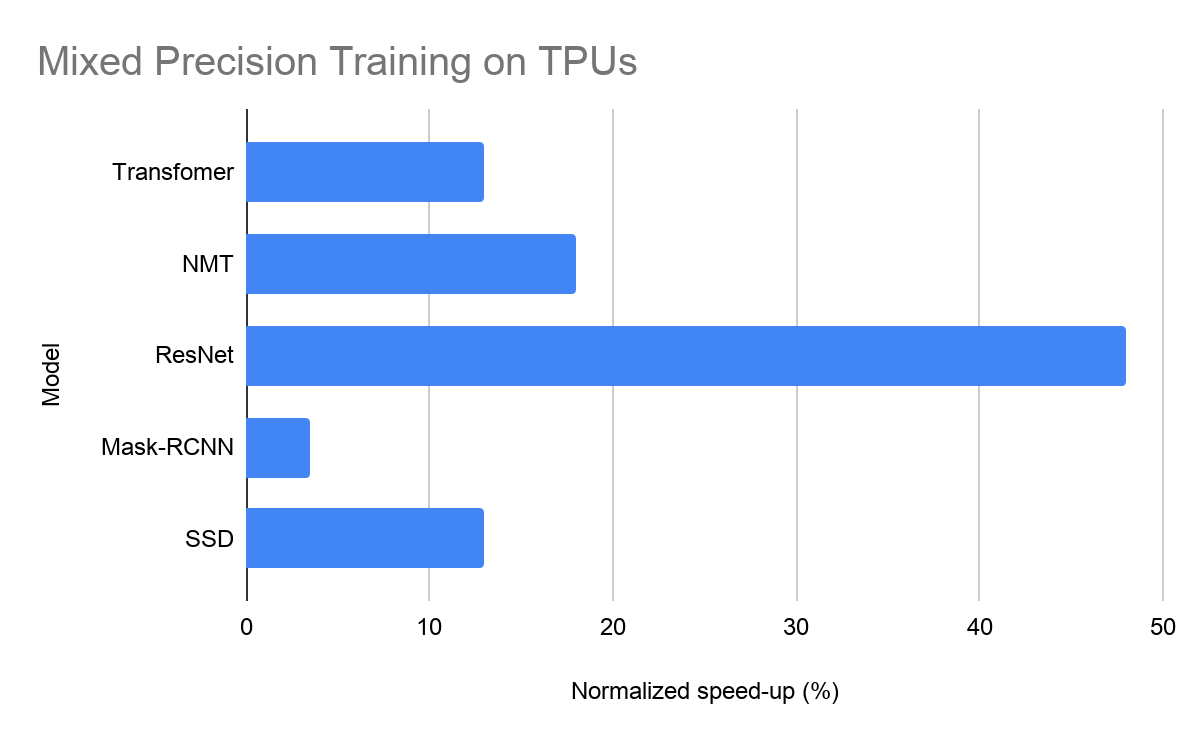
We have optimized the majority of Cloud TPU reference models to use mixed precision training with bfloat16. Figure 3 shows the performance gains from this optimization, which range from 4% to 47%, with a geometric mean of 13.9%.
Conclusion
In this blog, we laid out how the custom bfloat16 format available on Cloud TPUs can provide significant boosts in performance without having any noticeable impact on model accuracy. Support for mixed-precision training throughout the TPU software stack allows for seamless conversion between the formats, and can make these conversions transparent to the ML practitioner.
To get started,we recommend getting some hands-on experience with one of the bfloat16-enabled reference models we have optimized for Cloud TPUs. After that, our performance guide, profiling tools guide, and troubleshooting guide provide in-depth technical information to help you create and optimize machine learning models on your own. Once you’re ready to request a Cloud TPU Pod or Cloud TPU Pod slice to scale up your ML workloads even further, please contact a Google Cloud sales representative.
Acknowledgements:
- Dehao Chen, Software Engineer, TPU
- Chiachen Chou, Software Engineer, TPU
- Yuanzhong Xu, Software Engineer, TPU
- Jonathan Hseu, Software Engineer, TPU




