Google Cloud と Apollo24|7: 臨床判断支援システム(CDSS)の共同構築

Google Cloud Japan Team
※この投稿は米国時間 2022 年 8 月 12 日に、Google Cloud blog に投稿されたものの抄訳です。
臨床判断支援システム(CDSS)は、医療従事者が患者のケアに関する意思決定を行うためにデータを分析する、医療業界にとって重要な技術です。臨床判断支援システムの世界市場規模は拡大傾向にあり、ある調査によると、2022 年から 2030 年までの年平均成長率(CAGR)が 10.4% で、107 億ドルに達すると予測しています。
CDSS システムを構築しようとする医療機関にとって、一つの重要なブロックは、臨床記録、医学雑誌、退院サマリーなどに存在する医療エンティティを探し出し、抽出することです。エンティティの抽出とともに、CDSS システムの他の重要な構成要素は、時間的関係、被験者、および確実性の評価をキャプチャすることです。
Google Cloud は、ヘルスケア業界にとって CDSS システムの構築がいかに重要であるかを理解しています。そのため、インド最大のマルチチャンネル デジタル ヘルスケア プラットフォームである Apollo 24|7 と協力して、CDSS ソリューションのキーブロックを構築しました。
Google Cloud は、退院時のサマリーや処方箋を解析して、医療エンティティを抽出する作業を支援しました。これらのエンティティを利用して、医師が医薬品や臨床検査などの「次の最善手」を提案するためのレコメンデーション エンジンを構築できます。
Apollo 24|7 のエンティティ抽出ソリューションと、技術スタックを形成するためにテストされたさまざまな Google AI テクノロジーを見てみましょう。
使用したデータセット
エンティティ抽出の実験を行うために、2 種類のデータセットを使用しました。
i2b2 Dataset - i2b2 は、オープンソースの臨床データ ウェアハウジングおよび分析研究プラットフォームです。このプラットフォームは、アノテーション付きで匿名化された患者退院サマリーを、研究目的のためにコミュニティに提供します。このデータセットは、主にモデルのトレーニングと検証に使用されました。
Apollo 24|7 のデータセット - Apollo 24|7 の匿名化された医師のメモがテストに使用されました。医師は、エンティティとオフセット値にラベルを付けるために、メモにアノテーションを行いました。
テストと正しいアプローチの選択 - 試した 4 つのモデル
エンティティ抽出には、Google Cloud プロダクトとオープンソースの両方が検討されました。詳しくは以下をご確認ください。
1. Healthcare Natural Language API: 医療用テキストから知見を導き出すための機械学習ソリューションを提供するコード不要アプローチです。このアプローチを用いて、非構造化医療テキストを解析し、データに格納された医療知識エンティティの構造化データ表現を生成し、ダウンストリームの解析と自動化に利用しました。プロセスには以下が含まれます。
疾患、医薬品、医療機器、医療処置、臨床関連の属性などの医療コンセプトに関する情報を抽出する
医療コンセプトを RxNorm、ICD-10、MeSH、SNOMED CT(米国のユーザーのみ)などの標準的な医療用語にマッピングする
テキストから医療分析情報を抽出し、それを Google Cloud のデータ分析プロダクトと統合する
この手法には、MED_DOSE、MED_DURATION、LAB_UNIT、LAB_VALUE などの幅広いエンティティ タイプを抽出するだけでなく、時間関係、被験者、確実性評価などの機能的特徴を信頼度スコアとともに取得できるという利点があります。Google Cloud で利用できるため、長期的なプロダクトのサポートを提供できます。また、テストしたすべてのアプローチの中で唯一のフルマネージド NLP サービスであるため、導入と管理の労力が最も少なくて済みます。
ただし、注意点として、Healthcare Natural Language API は事前トレーニング済みの自然言語モデルを提供しているため、現状ではカスタム アノテーション付き医療テキストを用いて学習したカスタム エンティティ抽出モデルや、カスタム エンティティ抽出には使用できません。この作業は、カスタムモデル開発用の Google Cloud サービスである AutoML Entity Extraction for Healthcare で行う必要があります。カスタムモデルの開発は、新しい言語や地域特有の自然言語処理(たとえば、インドでは他の地域よりもある医学用語が頻出する可能性がある)に事前トレーニング済みのモデルを適応させるために重要です。
2. Vertex AutoML Entity Extraction for Healthcare: これは、Google Cloud ですでに利用可能な、ローコードのアプローチです。AutoML Entity Extraction を使用して、文書を分析し、分類し、文書内のエンティティを特定するカスタム機械学習モデルを構築し、デプロイしました。このカスタム機械学習モデルは、Apollo 24|7 チームから提供されたアノテーション付きデータセットによってトレーニングされました。
AutoML Entity Extraction の利点は、新しいデータセットでトレーニングするオプションがあることです。ただし、前提条件として、入力データを必要な JSONL 形式で取り込むために、多少の前処理が必要であることに留意してください。エンティティ抽出のためだけの AutoML モデルなので、関係性や確実性の評価などは抽出されません。
3. Vertex AI 上の BERT ベースのモデル: Vertex AI は、Google Cloud のフルマネージドな統合 AI プラットフォームで、事前トレーニング済みのツールやカスタムツールを用いて、ML モデルを迅速に構築、デプロイ、スケールできます。Google Cloud は、多くの自然言語タスクで最先端の性能を示した事前トレーニング済みの BERT ベースのモデルに基づく複数のカスタム アプローチを実験しました。医療用語や医療処置の文脈的理解を深めるため、これらの BERT ベースのアプローチは、医療領域のデータで明示的にトレーニングされています。Google の実験は、BioClinical BERT、BioLink BERT、Pubmed データセットでトレーニングした Blue BERT、Pubmed + MIMIC データセットでトレーニングした Blue BERT に基づいています。
これらの BERT ベースのモデルの主な利点は、最小限の努力であらゆるエンティティ認識タスクに対して微調整が可能であることです。
ただし、カスタム アプローチであるため、技術的なノウハウが必要です。さらに、関係性、確実性評価などを抽出しません。これは、BERT ベースのモデルを使用する際の主な制限事項の一つです。
4. Vertex AI での ScispaCy: Google Cloud は ScispaCy をベースに、Vertex AI を使って実験を行いました。これは、生物医学、科学、臨床のテキストを処理するための spaCy モデルを含む Python パッケージです。
Vertex AI での Scispacy は、エンティティ抽出とともに、Abbreviation Detector、Entity Linking などの追加コンポーネントを提供しています。しかし、他のモデルと比較すると、精度が低く、「入院日」のようなジャンク フレーズをエンティティとしてキャプチャすることがよくありました。
Apollo 24|7 のエンジニアリング リーダーである Abdussamad M 氏は次のように述べています。「複数のアプローチを検討し、それぞれのアプローチの長所と短所を理解することで、当社のビジネス要件に合うものを選択することができました。」
評価戦略
解析されたエンティティとテストデータのラベルを照合するために、以下の 4 つの方法からなる大規模な照合ロジックを使用しました。
完全一致 - モデル出力とテスト データセットのエンティティが一致するエンティティをキャプチャします。ここでは、エンティティのオフセット値も考慮されています。たとえば、モデル出力とテストラベルの両方にそのまま存在するエンティティ「胃腸感染症」は「完全一致」とみなされます。
マッチスコア ロジック - エンティティのマッチングにスコアリング ロジックを使用しました。テストデータのラベルの各単語に対して、モデル出力の各単語がオフセットとともにマッチングされます。エンティティ間でスコアを計算し、そのしきい値に基づいて、一致と判断します。
部分一致 - このロジックは、「高血圧」と「高血圧症」のようなエンティティをファジー ロジックに基づいてマッチングさせます。
UMLS 略語検索 - また、医学書には腹痛(abdominal pain)を意味する AP のような略語があることが確認されました。これらはまず、それぞれの統一医学用語システム(UMLS)テーブルを検索することで元の単語に直され、その後、個々のエンティティ抽出モデルに渡されました。
パフォーマンス指標
Goggle Cloud の異なるモデル / テストの結果を比較するために、適合率と再現率の指標を使用しました。
適合率(陽性予測値ともいう)は、取得されたインスタンスのうちの関連するインスタンスの割合であり、再現率(感度ともいう)は、関連するインスタンスのうちの取得できたインスタンスの割合です。
以下の例は、与えられたサンプルに対してこれらの指標を計算する方法を示しています。
サンプルの例: 「Krish には発熱、頭痛があり、不快感もあります。」
期待されるエンティティ [発熱、頭痛]
モデルの出力 [熱、体調、不快感]
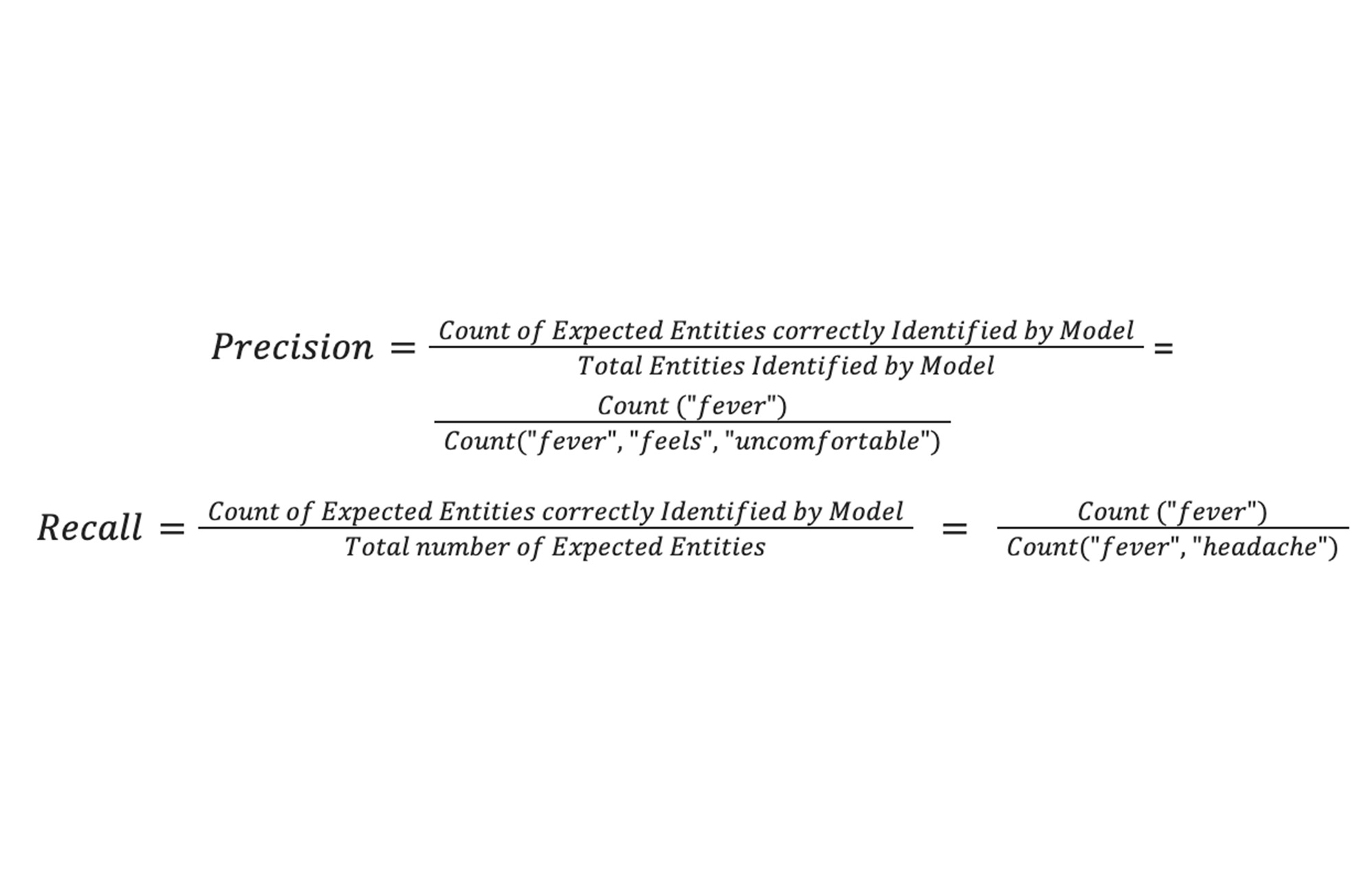
つまり、

テストの結果
以下の表は、Apollo24|7 の内部データセットで上記の実験を行った結果をキャプチャしたものです。
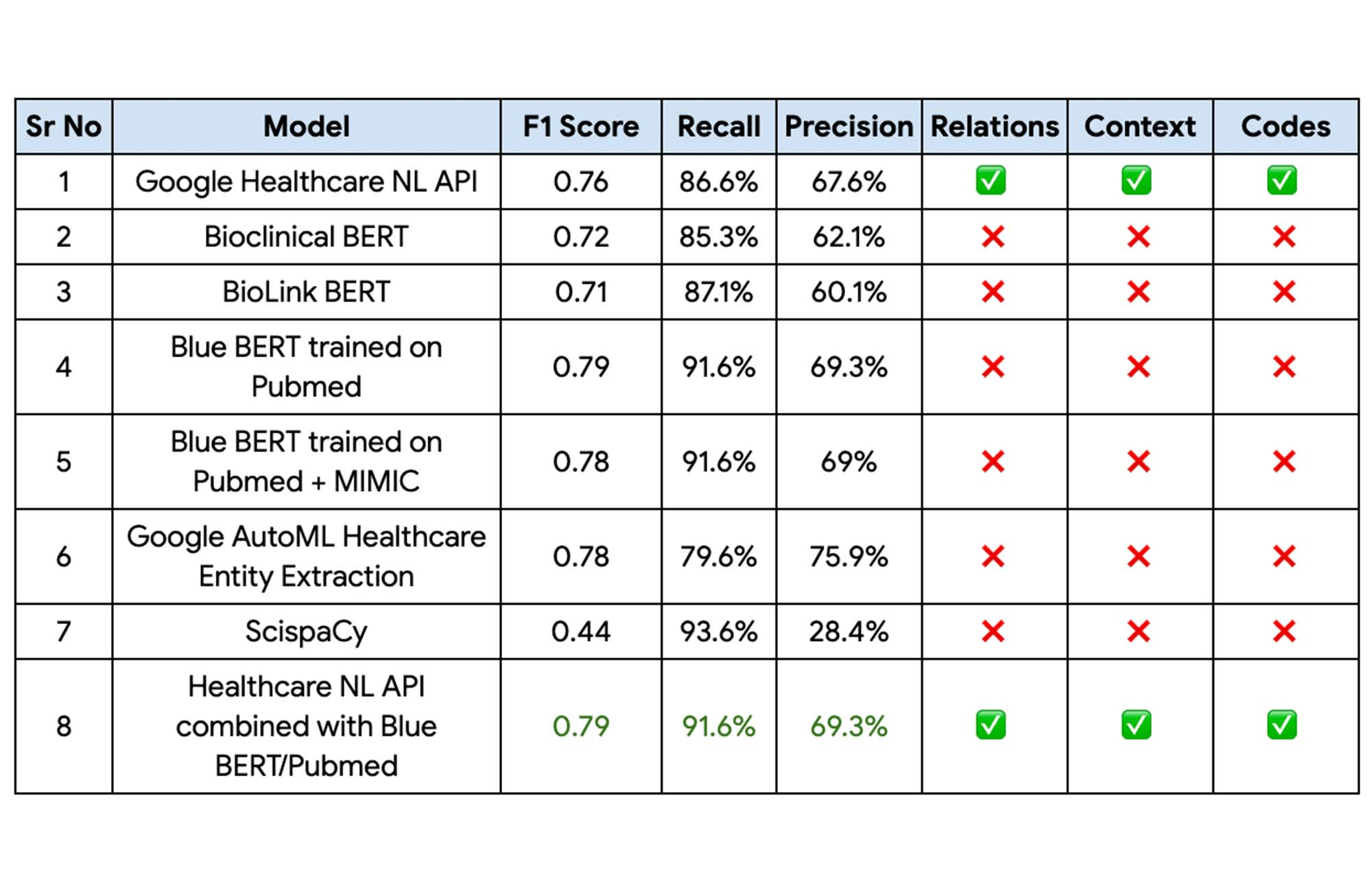
最後に、Pubmed データセットでトレーニングした Blue BERT モデルは、Healthcare Natural Language API がコンテキスト、関係、コードを提供する Apollo 24|7 のベースライン モードに対して 81% の改善を見せ、最高のパフォーマンス指標を記録しました。この性能は、この 2 つのモデルのアンサンブルを実装することで、さらに向上できます。
Abdussamad 氏は次のように述べています。「Blue BERT モデルが Vertex AI 上のエンティティ抽出に最高のパフォーマンスを発揮し、Healthcare NL API が関係性や確実性の評価などを抽出できることから、最終的にこの 2 つのアプローチのアンサンブルを採用することにしました。」
Google Cloud AI サービス(AIS)によるエンドツーエンドの迅速な導入
Google AIS(Professional Services Organization)は、Apollo24|7 による CDSS システムのキーブロック構築を支援しました。
Google Cloud と Apollo 24|7 のパートナーシップは、組織が望ましい結果を推進するために、複雑な問題を解決する AI 搭載ソリューションを提供している最新の例のひとつです。Google Cloud の AI サービスの詳細については、AI & ML プロダクト ページをご覧ください。Google Cloud のヘルスケア向けソリューションの詳細については、Google Cloud Healthcare Data Engine のページをご覧ください。
謝辞
プロジェクトを通してサポートと指導を提供いただいた Nitin Aggarwal 氏、Gopala Dhar 氏、Kartik Chaudhary 氏に特別な感謝を捧げたいと思います。また、Manisha Yadav 氏、Santosh Gadgei 氏、Vasantha Kumar 氏には、GCP のインフラストラクチャを導入していただき、感謝しています。Apollo チーム(Chaitanya Bharadwaj 氏、Abdussamad GM 氏、Lavish M 氏、Dinesh Singamsetty 氏、Anmol Singh 氏、Prithwiraj 氏)および HCL / Wipro のパートナー チーム(Durga Tulluru 氏、Praful Turanur 氏)が、このプロジェクトを成功に導いてくださったことに感謝します。Cloud Healthcare NLP API チーム(Donny Cheung 氏、Amirhossein Simjour 氏、Kalyan Pamarthy 氏)に感謝します。
- Apollo 24|7、クリニカル AI プロダクト責任者 Chaitanya Bharadwaj 氏
- Google Cloud、AI プロジェクト リード Sharmila Devi




