Incorporado dentro de los trabajos de consulta, BigQuery incluye el plan de consulta de diagnóstico y la información del tiempo. Esto es similar a la información que proporcionan declaraciones como EXPLAIN en otras bases de datos y sistemas analíticos. Esta información se puede recuperar a partir de las respuestas de la API de métodos como jobs.get.
BigQuery actualizará de forma periódica estas estadísticas para las consultas de larga duración. Estas actualizaciones ocurren sin importar la velocidad a la que se consulta el estado del trabajo, pero, por lo general, su frecuencia máxima será cada 30 segundos. Además, los trabajos de consulta que no usan recursos de ejecución, como las solicitudes o los resultados de las pruebas de validación que pueden entregarse a partir de los resultados almacenados en caché, no incluirán la información de diagnóstico adicional, aunque es posible que existan otras estadísticas.
Antecedentes
Cuando BigQuery ejecuta un trabajo de consulta, convierte la instrucción de SQL en un grafo de ejecución dividido en una serie de etapas de consulta, que se componen de conjuntos de pasos de ejecución más detallados. BigQuery aprovecha una arquitectura en paralelo muy distribuida para ejecutar estas consultas. Las etapas modelan las unidades de trabajo que muchos trabajadores potenciales pueden ejecutar en paralelo. Las etapas se comunican entre sí a través de una arquitectura aleatoria de distribución rápida.
En el plan de consulta, los términos unidades de trabajo y trabajadores se usan para transmitir información específicamente sobre el paralelismo. En otras partes de BigQuery, puede aparecer el término ranura, que es una representación abstracta de varias facetas de la ejecución de consultas, incluidos los recursos de procesamiento, de memoria y de E/S. Las estadísticas de trabajo principales proporcionan la estimación del costo de consulta individual mediante la estimación totalSlotMs de la consulta que usa esta contabilidad abstracta.
Otra propiedad importante de la arquitectura de ejecución de consultas es que es dinámica, lo que significa que el plan de consulta se puede modificar mientras se ejecuta una consulta. Las etapas que se ingresan mientras se ejecuta una consulta se suelen usar para mejorar la distribución de datos en todos los trabajadores de consulta. En los planes de consulta en los que esto ocurre, estas etapas suelen etiquetarse como etapas de repartición.
Además del plan de consulta, los trabajos de consulta exponen un cronograma de ejecución que proporciona un conteo de unidades de trabajo completadas, pendientes y activas dentro de los trabajadores de consulta. Una consulta puede tener varias etapas con trabajadores activos de forma simultánea. En el cronograma, se debe mostrar el progreso general de la consulta.
Ve información con la consola de Google Cloud
En la consola de Google Cloud, puedes ver los detalles del plan de una consulta que se haya completado. Para ello, haz clic en el botón Detalles de la ejecución (cerca del panel Resultados).
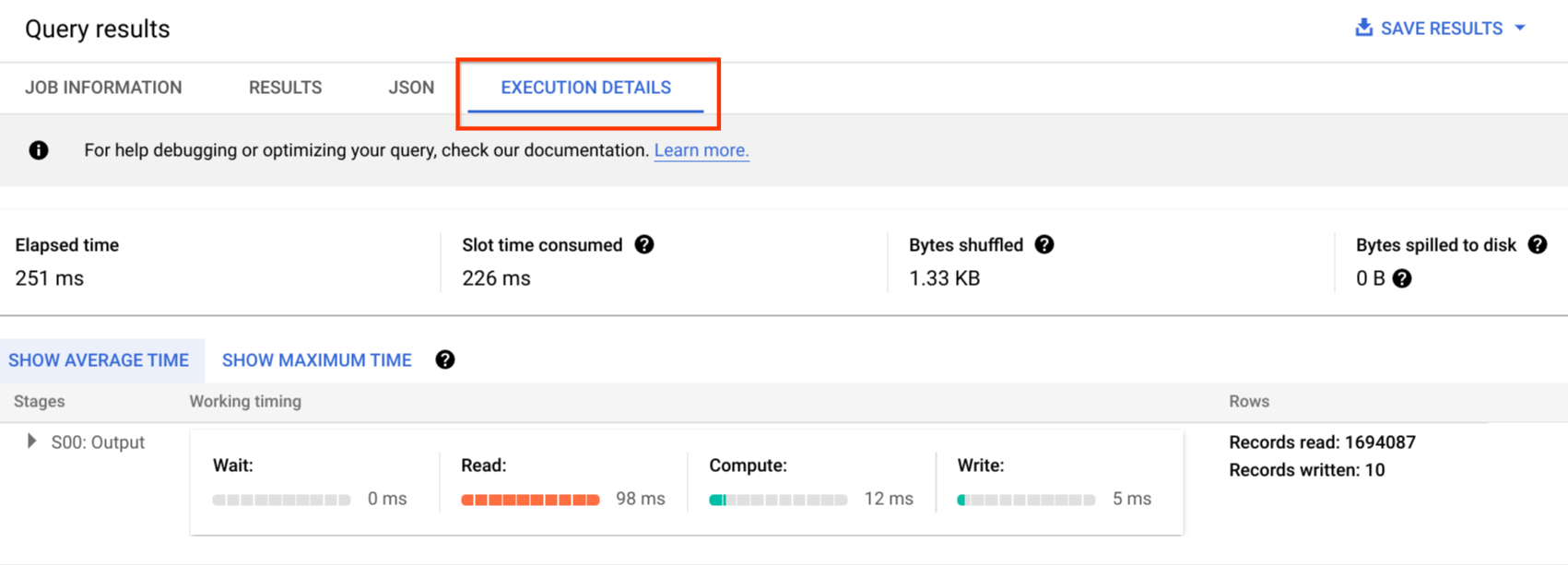
Información del plan de consultas
Dentro de la respuesta de la API, los planes de consultas se representan como una lista de etapas de consulta. Cada elemento de la lista muestra estadísticas de descripción general por etapa, información detallada de los pasos y clasificaciones del tiempo de las etapas. No todos los detalles se procesan en la consola de Google Cloud, pero todos pueden estar presentes en las respuestas de la API.
Descripción general de la etapa
Los campos de descripción general de cada etapa pueden incluir lo siguiente:
| Campo de API | Descripción |
|---|---|
id |
ID numérico exclusivo para la etapa. |
name |
Nombre de resumen sencillo de la etapa. Los steps dentro de la etapa proporcionan detalles adicionales sobre los pasos de ejecución. |
status |
Estado de ejecución de la etapa. Entre los estados posibles, se incluyen PENDIENTE, EN EJECUCIÓN, COMPLETO, CON ERRORES Y CANCELADO. |
inputStages |
Una lista de los ID que forman el grafo de dependencia de la etapa. Por ejemplo, en una etapa JOIN, se suelen necesitar dos etapas dependientes que preparan los datos en el lado izquierdo y derecho de la relación JOIN. |
startMs |
Marca de tiempo en milisegundos de ciclo de entrenamiento, que representa el momento cuando el primer trabajador dentro de la etapa comenzó la ejecución. |
endMs |
Marca de tiempo en milisegundos de ciclo de entrenamiento, que representa el momento cuando el último trabajador completó la ejecución. |
steps |
Lista más detallada de pasos de ejecución dentro de la etapa. Consulta la siguiente sección para obtener más información. |
recordsRead |
Tamaño de entrada de la etapa como número de registros en todos los trabajadores de la etapa. |
recordsWritten |
Tamaño de salida de la etapa como número de registros en todos los trabajadores de la etapa. |
parallelInputs |
Número de unidades de trabajo que se pueden paralelizar para la etapa. Según la etapa y la consulta, esto puede representar la cantidad de segmentos de columnas de una tabla o la cantidad de particiones de un orden aleatorio intermedio. |
completedParallelInputs |
Número de unidades de trabajo en la etapa que se completaron. Para algunas consultas, no todas las entradas en una etapa deben completarse a fin de que la etapa se complete. |
shuffleOutputBytes |
Representa el total de bytes escritos en todos los trabajadores dentro de una etapa de consulta. |
shuffleOutputBytesSpilled |
Es posible que las consultas que transmiten datos importantes entre etapas deban recurrir a la transmisión basada en disco. La estadística de bytes volcados comunica la cantidad de datos volcados al disco. Depende de un algoritmo de optimización, por lo que no es determinista para ninguna consulta determinada. |
Información de pasos por etapa
Los pasos representan las operaciones más detalladas que cada trabajador dentro de una etapa debe ejecutar, presentado como una lista ordenada de operaciones. Los pasos se categorizan con algunas operaciones que proporcionan información más detallada. Las categorías de operación que se encuentran en el plan de consulta incluyen lo siguiente:
| Paso | Descripción |
|---|---|
| READ | Lectura de una o más columnas desde una tabla de entrada o de orden aleatorio intermedio. Solo se muestran las primeras dieciséis columnas que se leen en los detalles del paso. |
| WRITE | Escritura de una o más columnas en una tabla de salida o resultado intermedio. Para las salidas con particiones HASH de una etapa, esto también incluye las columnas que se usan como clave de partición. |
| COMPUTE | Operaciones como la evaluación de expresiones y funciones de SQL. |
| FILTER | Operador que implementa las cláusulas WHERE, OMIT IF y HAVING. |
| SORT | Las operaciones SORT y ORDER-BY incluyen la dirección de clasificación y las claves de columna. |
| AGGREGATE | Una operación de agregación, como GROUP BY o COUNT. |
| LIMIT | Operador que implementa la cláusula LIMIT. |
| JOIN | Operación JOIN que incluye el tipo de unión y las columnas que se usan. |
| ANALYTIC_FUNCTION | Invocación de una función analítica. |
| USER_DEFINED_FUNCTION | Llamada a una función definida por el usuario. |
Clasificación de tiempo por etapa
Las etapas de consulta también proporcionan clasificaciones de tiempo por etapa en forma relativa y absoluta. Como cada etapa de ejecución representa el trabajo que realizaron los trabajadores independientes, la información se proporciona en el tiempo promedio y en el peor de los casos. Estos tiempos representan el rendimiento promedio de todos los trabajadores de una etapa, así como el rendimiento del trabajador de cola larga más lento de una clasificación determinada. Además, los tiempos promedio y máximo se desglosan en representaciones absolutas y relativas. Para las estadísticas basadas en la proporción, los datos se proporcionan como una fracción del tiempo más prolongado que cualquier trabajador invirtió en cualquier segmento.
La consola de Google Cloud presenta el tiempo por etapas mediante las representaciones de tiempo relativas.
La información del tiempo por etapas se muestra de la siguiente manera:
| Tiempo relativo | Tiempo absoluto | Numerador de proporción |
|---|---|---|
waitRatioAvg |
waitMsAvg |
Tiempo que el trabajador promedio esperó para programarse. |
waitRatioMax |
waitMsMax |
Tiempo que el trabajador más lento esperó para programarse. |
readRatioAvg |
readMsAvg |
Tiempo que el trabajador promedio dedicó a leer datos de entrada. |
readRatioMax |
readMsMax |
Tiempo que el trabajador más lento dedicó a leer datos de entrada. |
computeRatioAvg |
computeMsAvg |
Tiempo que el trabajador promedio pasó vinculado a la CPU. |
computeRatioMax |
computeMsMax |
Tiempo que el trabajador más lento pasó vinculado a la CPU. |
writeRatioAvg |
writeMsAvg |
Tiempo que el trabajador promedio dedicó a escribir datos de salida. |
writeRatioMax |
writeMsMax |
Tiempo que el trabajador más lento dedicó a escribir datos de salida. |
Explicación de las consultas federadas
Las consultas federadas te permiten enviar una
declaración de consulta a una fuente de datos externa a través de la
función EXTERNAL_QUERY.
Las consultas federadas están sujetas a la técnica de optimización conocida como envíos de SQL y el plan de consultas muestra las operaciones enviadas a la fuente de datos externa, si la hubiera.
Por ejemplo, ejecuta la siguiente consulta:
SELECT id, name
FROM EXTERNAL_QUERY("<connection>", "SELECT * FROM company")
WHERE country_code IN ('ee', 'hu') AND name like '%TV%'
El plan de consulta mostrará los siguientes pasos de etapa:
$1:id, $2:name, $3:country_code
FROM table_for_external_query_$_0(
SELECT id, name, country_code
FROM (
/*native_query*/
SELECT * FROM company
)
WHERE in(country_code, 'ee', 'hu')
)
WHERE and(in($3, 'ee', 'hu'), like($2, '%TV%'))
$1, $2
TO __stage00_output
En este plan, table_for_external_query_$_0(...) representa la función EXTERNAL_QUERY. Entre paréntesis puedes ver la consulta que ejecuta la fuente de datos externa. En función de eso, puedes notar lo siguiente:
- Una fuente de datos externa muestra solo 3 columnas seleccionadas.
- Una fuente de datos externa solo muestra filas en las que
country_codees'ee'o'hu'. - El operador
LIKEno se envía hacia abajo y BigQuery lo evalúa.
A modo de comparación, si no hay pushdown, el plan de consulta mostrará los siguientes pasos de etapa:
$1:id, $2:name, $3:country_code
FROM table_for_external_query_$_0(
SELECT id, name, description, country_code, primary_address, secondary address
FROM (
/*native_query*/
SELECT * FROM company
)
)
WHERE and(in($3, 'ee', 'hu'), like($2, '%TV%'))
$1, $2
TO __stage00_output
Esta vez, una fuente de datos externa muestra todas las columnas y todas las filas de
la tabla company, y BigQuery realiza el filtrado.
Metadatos de cronograma
En los cronogramas de consultas, se informa el progreso en puntos específicos en el tiempo, lo que proporciona vistas instantáneas del progreso general de la consulta. El cronograma se representa como una serie de muestras en las que se informan los siguientes detalles:
| Campo | Descripción |
|---|---|
elapsedMs |
Milisegundos transcurridos desde el inicio de la ejecución de la consulta. |
totalSlotMs |
Una representación acumulativa de los milisegundos de ranura que usó la consulta. |
pendingUnits |
Total de unidades de trabajo programadas y en espera de ejecución. |
activeUnits |
Total de unidades de trabajo activas que los trabajadores procesan. |
completedUnits |
Total de unidades de trabajo que se completaron mientras se ejecutaba esta consulta. |
Consulta de ejemplo
En la siguiente consulta, se cuentan la cantidad de filas en el conjunto de datos públicos de Shakespeare. Esta tiene un segundo recuento condicional que restringe los resultados a las filas que hacen referencia a “hamlet”:
SELECT
COUNT(1) as rowcount,
COUNTIF(corpus = 'hamlet') as rowcount_hamlet
FROM `publicdata.samples.shakespeare`
Haz clic en Detalles de la ejecución para ver el plan de consulta:
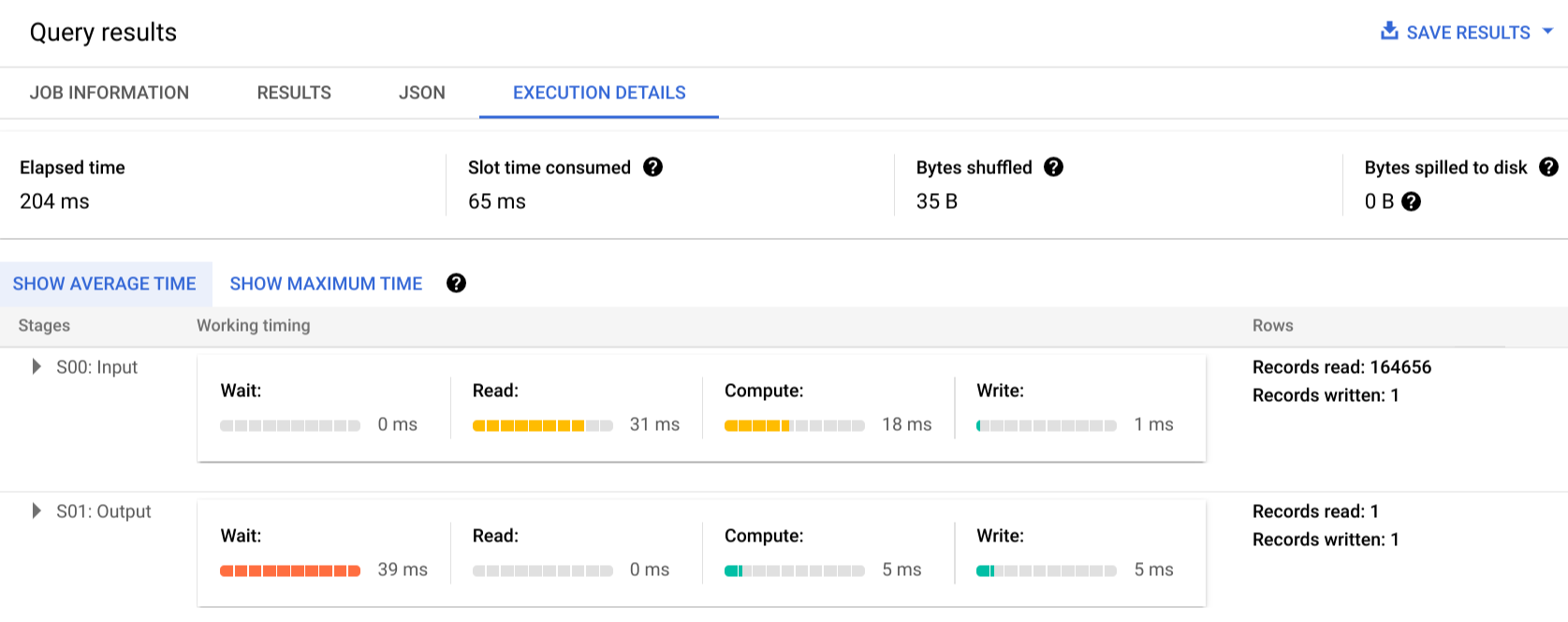
Los indicadores de color muestran los tiempos relativos de todos los pasos en todas las etapas.
Para obtener más información sobre los pasos de las etapas de ejecución, haz clic en a fin de expandir los detalles de la etapa:
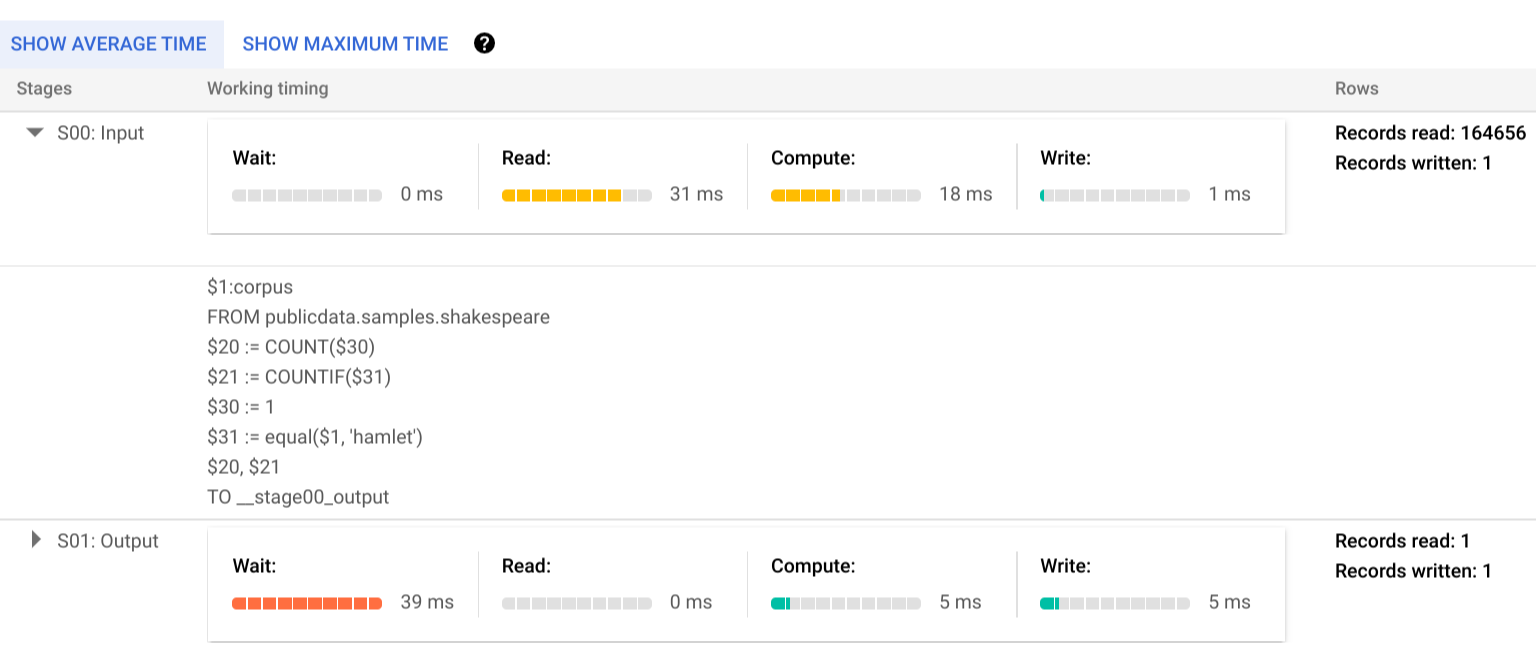
En este ejemplo, el tiempo más prolongado en cualquier segmento fue el tiempo que el trabajador único en la etapa 01 esperó a que se completara la etapa 00. Esto se debe a que la Etapa 01 dependía de la entrada de la Etapa 00 y no podía empezar hasta que la primera etapa escribió su salida en un orden aleatorio intermedio.
Informes de errores
Es posible que los trabajos de consulta fallen a mitad de la ejecución. Debido a que la información del plan se actualiza de forma periódica, podrás observar dónde se produjo la falla en el grafo de ejecución. Dentro de la consola de Google Cloud, las etapas correctas o con fallas se etiquetan con una marca de verificación o un signo de exclamación junto al nombre de la etapa.
Para obtener más información sobre cómo interpretar y abordar errores, consulta la Guía de solución de problemas.
Representación de muestra de la API
La información del plan de consulta está incorporada en la información de la respuesta del trabajo y puedes recuperarla mediante una llamada a jobs.get. Por ejemplo, en el siguiente extracto de una respuesta JSON de un trabajo que muestra la consulta de Hamlet de muestra se señala el plan de consulta y la información del cronograma.
"statistics": {
"creationTime": "1576544129234",
"startTime": "1576544129348",
"endTime": "1576544129681",
"totalBytesProcessed": "2464625",
"query": {
"queryPlan": [
{
"name": "S00: Input",
"id": "0",
"startMs": "1576544129436",
"endMs": "1576544129465",
"waitRatioAvg": 0.04,
"waitMsAvg": "1",
"waitRatioMax": 0.04,
"waitMsMax": "1",
"readRatioAvg": 0.32,
"readMsAvg": "8",
"readRatioMax": 0.32,
"readMsMax": "8",
"computeRatioAvg": 1,
"computeMsAvg": "25",
"computeRatioMax": 1,
"computeMsMax": "25",
"writeRatioAvg": 0.08,
"writeMsAvg": "2",
"writeRatioMax": 0.08,
"writeMsMax": "2",
"shuffleOutputBytes": "18",
"shuffleOutputBytesSpilled": "0",
"recordsRead": "164656",
"recordsWritten": "1",
"parallelInputs": "1",
"completedParallelInputs": "1",
"status": "COMPLETE",
"steps": [
{
"kind": "READ",
"substeps": [
"$1:corpus",
"FROM publicdata.samples.shakespeare"
]
},
{
"kind": "AGGREGATE",
"substeps": [
"$20 := COUNT($30)",
"$21 := COUNTIF($31)"
]
},
{
"kind": "COMPUTE",
"substeps": [
"$30 := 1",
"$31 := equal($1, 'hamlet')"
]
},
{
"kind": "WRITE",
"substeps": [
"$20, $21",
"TO __stage00_output"
]
}
]
},
{
"name": "S01: Output",
"id": "1",
"startMs": "1576544129465",
"endMs": "1576544129480",
"inputStages": [
"0"
],
"waitRatioAvg": 0.44,
"waitMsAvg": "11",
"waitRatioMax": 0.44,
"waitMsMax": "11",
"readRatioAvg": 0,
"readMsAvg": "0",
"readRatioMax": 0,
"readMsMax": "0",
"computeRatioAvg": 0.2,
"computeMsAvg": "5",
"computeRatioMax": 0.2,
"computeMsMax": "5",
"writeRatioAvg": 0.16,
"writeMsAvg": "4",
"writeRatioMax": 0.16,
"writeMsMax": "4",
"shuffleOutputBytes": "17",
"shuffleOutputBytesSpilled": "0",
"recordsRead": "1",
"recordsWritten": "1",
"parallelInputs": "1",
"completedParallelInputs": "1",
"status": "COMPLETE",
"steps": [
{
"kind": "READ",
"substeps": [
"$20, $21",
"FROM __stage00_output"
]
},
{
"kind": "AGGREGATE",
"substeps": [
"$10 := SUM_OF_COUNTS($20)",
"$11 := SUM_OF_COUNTS($21)"
]
},
{
"kind": "WRITE",
"substeps": [
"$10, $11",
"TO __stage01_output"
]
}
]
}
],
"estimatedBytesProcessed": "2464625",
"timeline": [
{
"elapsedMs": "304",
"totalSlotMs": "50",
"pendingUnits": "0",
"completedUnits": "2"
}
],
"totalPartitionsProcessed": "0",
"totalBytesProcessed": "2464625",
"totalBytesBilled": "10485760",
"billingTier": 1,
"totalSlotMs": "50",
"cacheHit": false,
"referencedTables": [
{
"projectId": "publicdata",
"datasetId": "samples",
"tableId": "shakespeare"
}
],
"statementType": "SELECT"
},
"totalSlotMs": "50"
},
Usa información de ejecución
En los planes de consulta de BigQuery se proporciona información sobre cómo el servicio ejecuta consultas, pero la naturaleza administrada del servicio limita la practicidad directa de algunos detalles. Muchas optimizaciones se realizan de manera automática cuando usas el servicio, lo que puede diferir de otros entornos en los que el ajuste, el aprovisionamiento y la supervisión pueden requerir personal dedicado y especializado.
Para ver técnicas específicas que pueden mejorar la ejecución de consultas y el rendimiento, consulta la documentación de prácticas recomendadas. El plan de consulta y las estadísticas de cronograma te ayudan a comprender si algunas etapas dominan el uso de recursos. Por ejemplo, una etapa JOIN que genera muchas más filas de salida que filas de entrada indica una oportunidad para aplicar un filtro con anticipación en la consulta.
Además, la información de cronograma puede ayudar a identificar si una consulta determinada es lenta en sí o si lo es debido a los efectos de otras consultas que compiten por los mismos recursos. Si te das cuenta de que la cantidad de unidades activas es limitada durante toda la vida útil de la consulta, pero que la cantidad de unidades de trabajo en cola es alta, esto podría representar casos en los que reducir el número de consultas simultáneas puede mejorar de manera significativa el tiempo de ejecución general de determinadas consultas.