BigQuery incluye información de diagnóstico sobre el plan de consulta y los tiempos en las tareas de consulta. Es similar a la información que proporcionan las instrucciones como EXPLAIN en otros sistemas de bases de datos y analíticos. Esta información se puede obtener de las respuestas de la API de métodos como jobs.get.
En el caso de las consultas de larga duración, BigQuery actualizará periódicamente estas estadísticas. Estas actualizaciones se producen independientemente de la frecuencia con la que se consulta el estado del trabajo, pero normalmente no se producen con una frecuencia superior a 30 segundos. Además, los trabajos de consulta que no usen recursos de ejecución, como las solicitudes de prueba o los resultados que se puedan obtener de los resultados almacenados en caché, no incluirán la información de diagnóstico adicional, aunque puede que haya otras estadísticas.
Fondo
Cuando BigQuery ejecuta una tarea de consulta, convierte la instrucción SQL declarativa en un gráfico de ejecución, que se divide en una serie de fases de consulta, que a su vez se componen de conjuntos más granulares de pasos de ejecución. BigQuery aprovecha una arquitectura paralela muy distribuida para ejecutar estas consultas. Las fases modelan las unidades de trabajo que muchos trabajadores potenciales pueden ejecutar en paralelo. Las fases se comunican entre sí mediante una arquitectura de aleatorización distribuida rápida.
En el plan de consulta, los términos unidades de trabajo y trabajadores se usan para transmitir información específica sobre el paralelismo. En otras partes de BigQuery, puede que veas el término slot, que es una representación abstracta de varias facetas de la ejecución de consultas, incluidos los recursos de computación, memoria y E/S. Las estadísticas de las tareas de nivel superior proporcionan la estimación del coste de las consultas individuales mediante la totalSlotMs estimación de la consulta con esta contabilidad abstracta.
Otra propiedad importante de la arquitectura de ejecución de consultas es que es dinámica, lo que significa que el plan de consulta se puede modificar mientras se ejecuta una consulta. Las fases que se introducen mientras se ejecuta una consulta se suelen usar para mejorar la distribución de datos entre los trabajadores de la consulta. En los planes de consulta en los que esto ocurre, estas fases suelen etiquetarse como fases de repartición.
Además del plan de consulta, los trabajos de consulta también muestran una cronología de la ejecución, que proporciona un recuento de las unidades de trabajo completadas, pendientes y activas en los trabajadores de la consulta. Una consulta puede tener varias fases con trabajadores activos simultáneamente, y la cronología tiene como objetivo mostrar el progreso general de la consulta.
Ver información con la consola Google Cloud
En la Google Cloud consola, puedes ver los detalles del plan de consulta de una consulta completada haciendo clic en el botón Detalles de la ejecución (cerca del botón Resultados).
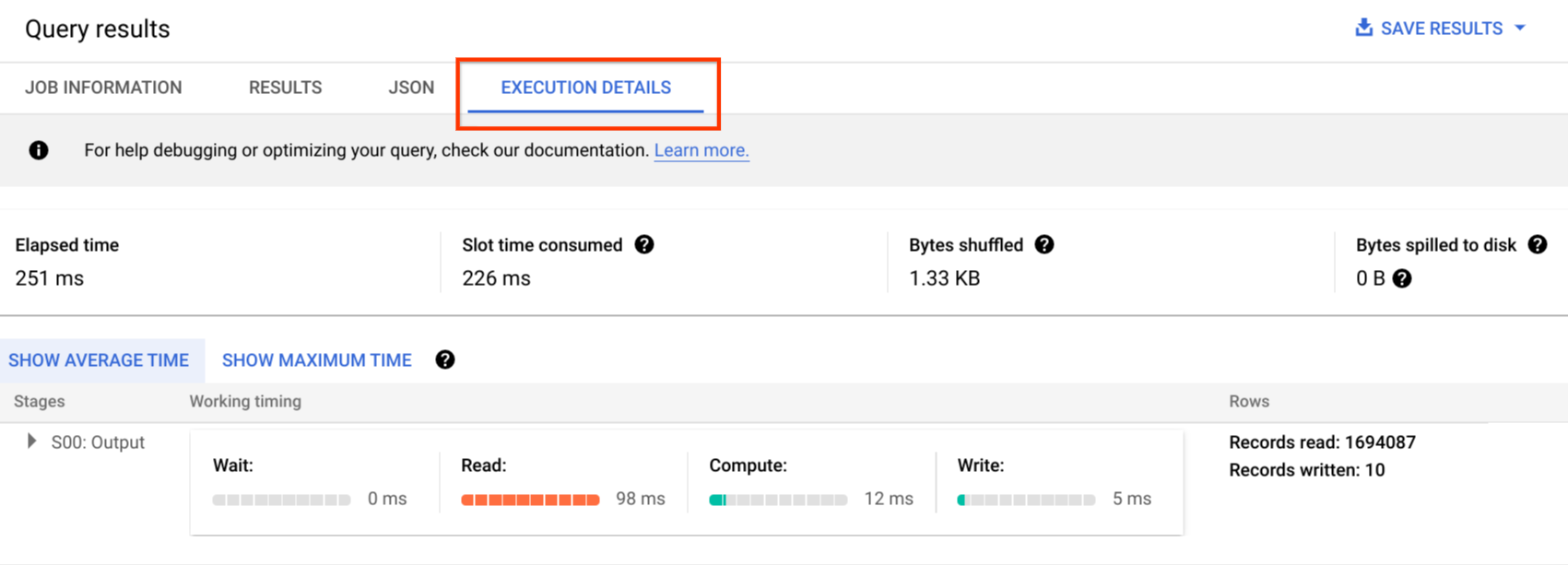
Información del plan de consultas
En la respuesta de la API, los planes de consulta se representan como una lista de fases de consulta. Cada elemento de la lista muestra estadísticas generales por fase, información detallada de los pasos y clasificaciones de los tiempos de las fases. No todos los detalles se muestran en la consola, pero pueden estar presentes en las respuestas de la API. Google Cloud
Vista general de la fase
Los campos de resumen de cada fase pueden incluir lo siguiente:
| Campo de la API | Descripción |
|---|---|
id |
ID numérico único de la fase. |
name |
Nombre de resumen sencillo de la fase. El steps de la fase proporciona más detalles sobre los pasos de ejecución. |
status |
Estado de ejecución de la fase. Entre los posibles estados se incluyen PENDING, RUNNING, COMPLETE, FAILED y CANCELLED. |
inputStages |
Lista de los IDs que forman el gráfico de dependencias de la fase. Por ejemplo, una fase JOIN a menudo necesita dos fases dependientes que preparen los datos de la parte izquierda y derecha de la relación JOIN. |
startMs |
Marca de tiempo, en milisegundos de época, que representa el momento en el que el primer trabajador de la fase empezó a ejecutarse. |
endMs |
Marca de tiempo, en milisegundos de época, que representa el momento en el que el último trabajador completó la ejecución. |
steps |
Lista más detallada de los pasos de ejecución de la fase. Para obtener más información, consulta la siguiente sección. |
recordsRead |
Tamaño de entrada de la fase como número de registros, en todos los trabajadores de la fase. |
recordsWritten |
Tamaño de salida de la fase como número de registros, en todos los trabajadores de la fase. |
parallelInputs |
Número de unidades de trabajo paralelizable de la fase. En función de la fase y la consulta, puede representar el número de segmentos de columnas de una tabla o el número de particiones de una ordenación aleatoria intermedia. |
completedParallelInputs |
Número de unidades de trabajo de la fase que se han completado. En algunas consultas, no es necesario completar todas las entradas de una fase para que esta se complete. |
shuffleOutputBytes |
Representa el total de bytes escritos en todos los trabajadores de una fase de una consulta. |
shuffleOutputBytesSpilled |
Las consultas que transmiten una cantidad significativa de datos entre fases pueden tener que recurrir a la transmisión basada en disco. La estadística de bytes derramados indica la cantidad de datos que se han derramado en el disco. Depende de un algoritmo de optimización, por lo que no es determinista para ninguna consulta. |
Clasificación de tiempos por etapa
Las fases de la consulta proporcionan clasificaciones de los tiempos de las fases, tanto relativas como absolutas. Como cada fase de ejecución representa el trabajo realizado por uno o varios trabajadores independientes, la información se proporciona tanto en tiempos medios como en los peores casos. Estos tiempos representan el rendimiento medio de todos los trabajadores de una fase, así como el rendimiento del trabajador más lento de la cola larga para una clasificación determinada. Además, los tiempos medios y máximos se desglosan en representaciones absolutas y relativas. En el caso de las estadísticas basadas en ratios, los datos se proporcionan como una fracción del tiempo máximo que ha dedicado cualquier trabajador a cualquier segmento.
La consola muestra los tiempos de las fases mediante representaciones de tiempo relativas. Google Cloud
La información sobre los tiempos de las fases se indica de la siguiente manera:
| Tiempos relativos | Tiempos absolutos | Numerador de la proporción |
|---|---|---|
waitRatioAvg |
waitMsAvg |
Tiempo medio que ha esperado el trabajador para que se le asigne una tarea. |
waitRatioMax |
waitMsMax |
Tiempo que ha pasado el trabajador más lento esperando a que se le asigne una tarea. |
readRatioAvg |
readMsAvg |
Tiempo que ha dedicado de media el trabajador a leer los datos de entrada. |
readRatioMax |
readMsMax |
Tiempo que ha tardado el trabajador más lento en leer los datos de entrada. |
computeRatioAvg |
computeMsAvg |
Tiempo que el trabajador medio ha estado limitado por la CPU. |
computeRatioMax |
computeMsMax |
Tiempo que el trabajador más lento ha dedicado a tareas dependientes de la CPU. |
writeRatioAvg |
writeMsAvg |
Tiempo que ha dedicado el trabajador medio a escribir datos de salida. |
writeRatioMax |
writeMsMax |
Tiempo que ha dedicado el trabajador más lento a escribir los datos de salida. |
Resumen de los pasos
Los pasos contienen las operaciones que ejecuta cada trabajador en una fase, presentadas como una lista ordenada de operaciones. Cada operación de paso tiene una categoría y algunas operaciones proporcionan información más detallada. Las categorías de operaciones presentes en el plan de consulta incluyen las siguientes:
| Categoría del paso | Descripción |
|---|---|
READ |
Lectura de una o varias columnas de una tabla de entrada o de un shuffle intermedio. En los detalles del paso solo se devuelven las primeras dieciséis columnas que se leen. |
WRITE |
Escritura de una o varias columnas en una tabla de salida o en un paso intermedio de barajado. En el caso de las salidas particionadas de HASH de una fase, también se incluyen las columnas que se usan como clave de partición. |
COMPUTE |
Evaluación de expresiones y funciones de SQL. |
FILTER |
Se usa en las cláusulas WHERE, OMIT IF y HAVING. |
SORT |
ORDER BY que incluye las claves de columna y el orden de clasificación. |
AGGREGATE |
Implementa agregaciones para cláusulas como GROUP BY o COUNT, entre otras. |
LIMIT |
Implementa la cláusula LIMIT. |
JOIN |
Implementa uniones para cláusulas como JOIN, entre otras. Incluye el tipo de unión y, posiblemente, las condiciones de unión. |
ANALYTIC_FUNCTION |
Una invocación de una función de ventana (también conocida como "función analítica"). |
USER_DEFINED_FUNCTION |
Una invocación a una función definida por el usuario. |
Interpretar los detalles de los pasos
BigQuery proporciona detalles de los pasos que explican qué ha hecho cada paso en una fase. Es necesario conocer los pasos de una fase para identificar la fuente de los problemas de rendimiento de las consultas.
Para ver los detalles de los pasos de una fase, sigue estos pasos:
En el panel Resultados de la consulta, haz clic en Gráfico de ejecución.
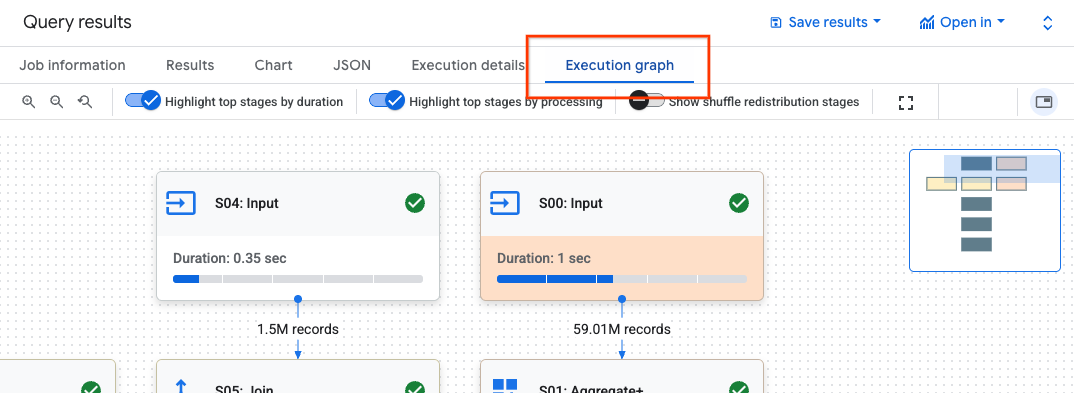
Haga clic en la fase que le interese para abrir un panel con información sobre ella.
En el panel con la información de la fase, ve a la sección Detalles del paso.
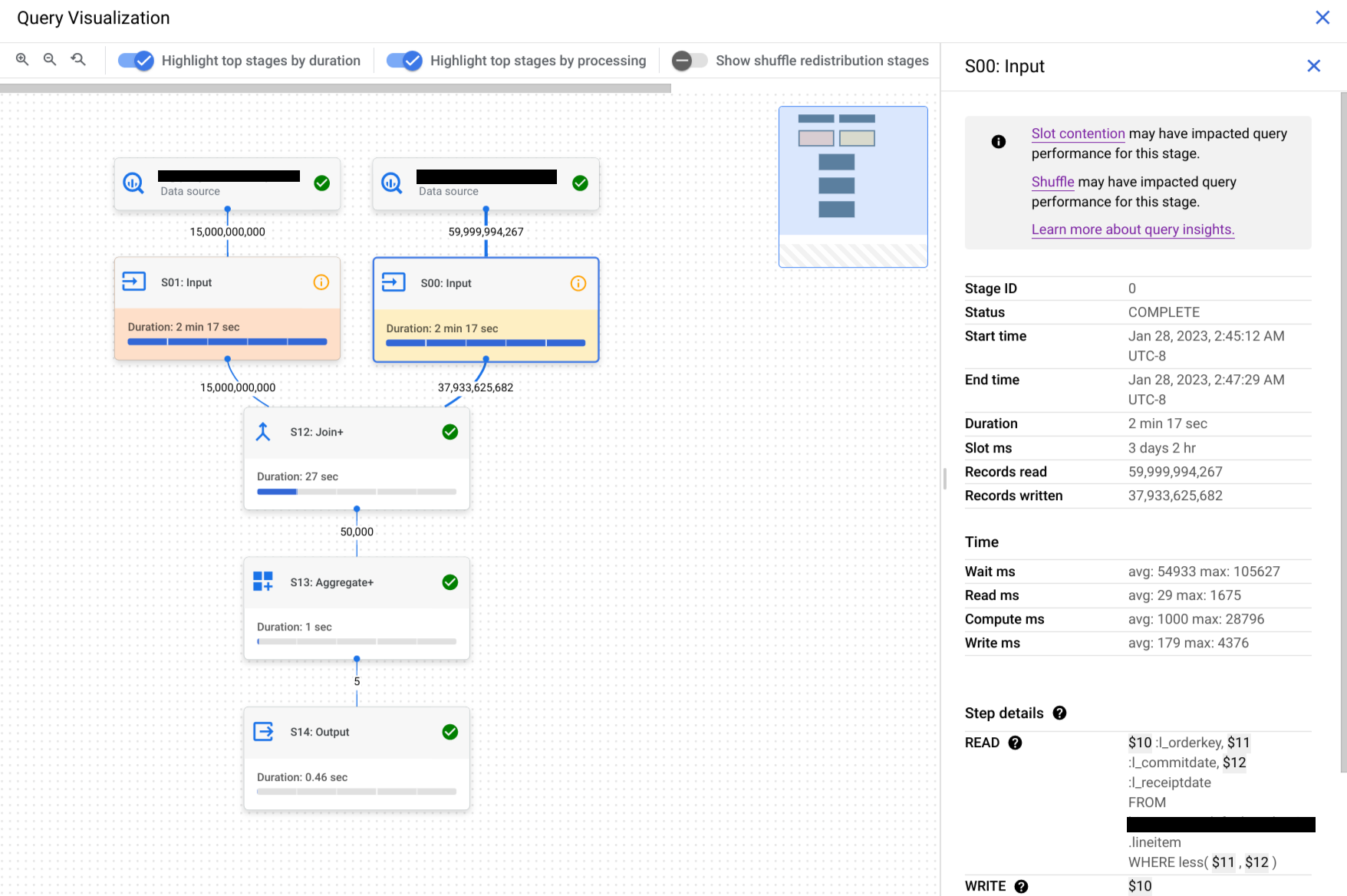
Cada paso consta de subpasos que describen lo que se ha hecho en ese paso. Los subpasos usan variables para describir las relaciones entre los pasos. Las variables empiezan por el signo de dólar seguido de un número único.
A continuación, se muestra un ejemplo de los detalles de los pasos de una fase con variables compartidas entre pasos:
READ $30:l_orderkey, $31:l_quantity FROM lineitem AGGREGATE GROUP BY $100 := $30 $70 := SUM($31) WRITE $100, $70 TO __stage00_output BY HASH($100)
Los detalles del paso del ejemplo hacen lo siguiente:
La fase lee las columnas
l_orderkeyyl_quantityde la tablalineitemusando las variables$30y$31, respectivamente.La fase agregada en las variables
$30y$31, que almacena las agregaciones en las variables$100y$70, respectivamente.La fase ha escrito los resultados de las variables
$100y$70para barajar. La fase usó$100para ordenar los resultados de la fase de forma aleatoria.
BigQuery puede truncar los detalles de los pasos cuando el gráfico de ejecución de la consulta es lo suficientemente complejo como para que, al proporcionar los detalles completos de los pasos de la fase, se produzcan problemas con el tamaño de la carga útil al recuperar la información de la consulta.
Entender los pasos con el texto de la consulta
Si necesitas ayuda durante la vista previa, envía un correo a bq-query-inspector-feedback@google.com.
Puede ser difícil entender cómo se relacionan los pasos de la fase con la consulta. En la sección Texto de la consulta se muestra cómo se relacionan algunos pasos con el texto de la consulta original.
En la sección Texto de la consulta se destacan diferentes partes del texto de la consulta original y se muestran los pasos que se corresponden con el texto de la consulta que precede inmediatamente al texto de la consulta original destacado. Solo se aplican al texto de consulta destacado los pasos que se encuentran inmediatamente encima de la parte destacada del texto de consulta original.
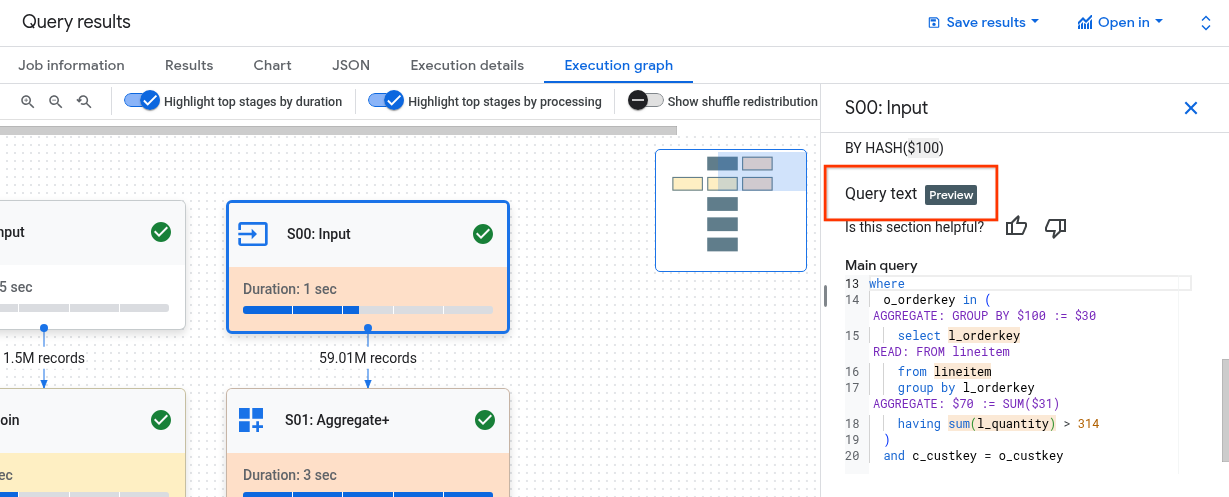
En la captura de pantalla de ejemplo se muestran estas asignaciones:
El paso
AGGREGATE: GROUP BY $100 := $30se corresponde con el texto de la consultaselect l_orderkey.El paso
READ: FROM lineitemse corresponde con el texto de la consultaselect ... from lineitem.El paso
AGGREGATE: $70 := SUM($31)se corresponde con el texto de la consultasum(l_quantity).
No todos los pasos se pueden asignar al texto de la consulta.
Si una consulta usa vistas y los pasos de la fase tienen asignaciones al texto de la consulta de una vista, la sección Texto de la consulta muestra el nombre de la vista y el texto de la consulta de la vista con sus asignaciones. Sin embargo, si se elimina la vista o si pierde el bigquery.tables.get permiso de gestión de identidades y accesos de la vista, la sección Texto de la consulta no mostrará las asignaciones de los pasos de la fase de la vista.
Interpretar y optimizar los pasos
En las siguientes secciones se explica cómo interpretar los pasos de un plan de consulta y se ofrecen formas de optimizar las consultas.
READ paso
El paso READ significa que una fase está accediendo a los datos para procesarlos. Los datos se pueden leer directamente de las tablas a las que se hace referencia en una consulta o de la memoria de aleatorización.
Cuando se leen datos de una fase anterior, BigQuery lee datos de la memoria de aleatorización. La cantidad de datos analizados influye en el coste cuando se usan ranuras bajo demanda y afecta al rendimiento cuando se usan reservas.
Posibles problemas de rendimiento
- Análisis grande de una tabla sin particiones: si la consulta solo necesita una pequeña parte de los datos, puede que el análisis de la tabla sea ineficiente. Crear particiones puede ser una buena estrategia de optimización.
- Análisis de una tabla grande con una proporción de filtro pequeña: esto sugiere que el filtro no reduce de forma eficaz los datos analizados. Revisa las condiciones del filtro.
- Bytes de mezcla que se han derramado en el disco: esto indica que los datos no se almacenan de forma eficaz mediante técnicas de optimización, como la agrupación en clústeres, que podría mantener datos similares en clústeres.
Optimizar
- Filtrado específico: usa las cláusulas
WHEREde forma estratégica para filtrar los datos irrelevantes lo antes posible en la consulta. De esta forma, se reduce la cantidad de datos que debe procesar la consulta. - Particiones y clústeres: BigQuery usa particiones y clústeres de tablas para localizar segmentos de datos específicos de forma eficiente.
Asegúrate de que tus tablas tengan particiones y clústeres en función de tus patrones de consulta habituales para minimizar los datos analizados durante los pasos
READ. - Selecciona las columnas pertinentes: evita usar instrucciones
SELECT *. En su lugar, selecciona columnas específicas o usaSELECT * EXCEPTpara evitar leer datos innecesarios. - Vistas materializadas: las vistas materializadas pueden precalcular y almacenar agregaciones que se usan con frecuencia, lo que puede reducir la necesidad de leer tablas base durante los pasos de
READde las consultas que usan esas vistas.
COMPUTE paso
En el paso COMPUTE, BigQuery realiza las siguientes acciones con tus datos:
- Evalúa las expresiones de las cláusulas
SELECT,WHERE,HAVINGy otras de la consulta, incluidas las operaciones de cálculo, comparación y lógicas. - Ejecuta funciones SQL integradas y funciones definidas por el usuario.
- Filtra las filas de datos según las condiciones de la consulta.
Optimizar
El plan de consulta puede revelar cuellos de botella en el paso COMPUTE. Busca fases con cálculos extensos o un número elevado de filas procesadas.
- Correlaciona el paso
COMPUTEcon el volumen de datos: si una fase muestra una computación significativa y procesa un gran volumen de datos, puede ser una buena candidata para la optimización. - Datos sesgados: en las fases en las que el máximo de computación es significativamente superior a la media, esto indica que la fase ha dedicado una cantidad de tiempo desproporcionada a procesar algunas porciones de datos. Te recomendamos que consultes la distribución de los datos para ver si hay sesgos.
- Ten en cuenta los tipos de datos: usa los tipos de datos adecuados para tus columnas. Por ejemplo, usar números enteros, fechas y horas, y marcas de tiempo en lugar de cadenas puede mejorar el rendimiento.
WRITE paso
WRITE pasos para los datos intermedios y el resultado final.
- Escritura en la memoria de aleatorización: en una consulta de varias fases, la
WRITEfase suele implicar el envío de los datos procesados a otra fase para su posterior procesamiento. Esto es habitual en la memoria de aleatorización, que combina o agrega datos de varias fuentes. Los datos escritos durante esta fase suelen ser un resultado intermedio, no el resultado final. - Salida final: el resultado de la consulta se escribe en el destino o en una tabla temporal.
Partición por hash
Cuando una fase del plan de consulta escribe datos en una salida con particiones hash, BigQuery escribe las columnas incluidas en la salida y la columna elegida como clave de partición.
Optimizar
Aunque el WRITE en sí no se pueda optimizar directamente, entender su función puede ayudarte a identificar posibles cuellos de botella en fases anteriores:
- Minimizar los datos escritos: céntrate en optimizar las fases anteriores con filtros y agregaciones para reducir la cantidad de datos escritos durante este paso.
Particiones: la escritura se beneficia enormemente de las particiones de tablas. Si los datos que escribe se limitan a particiones específicas, BigQuery puede escribir más rápido.
Si la instrucción DML tiene una cláusula
WHEREcon una condición estática en una columna de partición de tabla, BigQuery solo modifica las particiones de tabla pertinentes.Ventajas y desventajas de la desnormalización: la desnormalización a veces puede dar lugar a conjuntos de resultados más pequeños en el paso
WRITEintermedio. Sin embargo, también tiene inconvenientes, como el aumento del uso del almacenamiento y los problemas de coherencia de los datos.
JOIN paso
En el JOIN paso, BigQuery combina datos de dos fuentes de datos.
Las combinaciones pueden incluir condiciones de combinación. Las combinaciones consumen muchos recursos. Cuando se unen datos de gran tamaño en BigQuery, las claves de unión se redistribuyen de forma independiente para alinearse en la misma ranura, de modo que la unión se realiza de forma local en cada ranura.
El plan de consulta del paso JOIN suele revelar los siguientes detalles:
- Patrón de unión: indica el tipo de unión que se ha usado. Cada tipo define cuántas filas de las tablas unidas se incluyen en el conjunto de resultados.
- Columnas de unión: son las columnas que se usan para hacer coincidir las filas entre las fuentes de datos. La elección de las columnas es fundamental para el rendimiento de la combinación.
Patrones de unión
- Unión de difusión: cuando una tabla, normalmente la más pequeña, cabe en la memoria de un solo nodo o ranura de trabajador, BigQuery puede difundirla a todos los demás nodos para realizar la unión de forma eficiente. Busca
JOIN EACH WITH ALLen los detalles del paso. - Unión hash: cuando las tablas son grandes o no es adecuado usar una unión de difusión, se puede usar una unión hash. BigQuery usa operaciones de hash y aleatorización para aleatorizar las tablas de la izquierda y de la derecha, de forma que las claves coincidentes acaben en el mismo espacio para realizar una unión local. Las combinaciones hash son una operación costosa, ya que los datos deben moverse, pero permiten que las filas se correspondan de forma eficiente entre los hashes. Busca
JOIN EACH WITH EACHen los detalles del paso. - Autounión: antipatrón de SQL en el que una tabla se une a sí misma.
- Combinación cruzada: un antipatrón de SQL que puede provocar problemas de rendimiento significativos porque genera datos de salida más grandes que las entradas.
- Unión sesgada: la distribución de los datos en la clave de unión de una tabla está muy sesgada y puede provocar problemas de rendimiento. Busca casos en los que el tiempo de cálculo máximo sea mucho mayor que el tiempo de cálculo medio en el plan de consulta. Para obtener más información, consulta Cardinalidad alta en las uniones y Desviación de particiones.
Depuración
- Gran volumen de datos: si el plan de consulta muestra una cantidad significativa de datos procesados durante el paso
JOIN, investiga la condición de unión y las claves de unión. Prueba a filtrar o a usar claves de unión más selectivas. - Distribución de datos sesgada: analiza la distribución de datos de las claves de unión. Si una tabla está muy sesgada, prueba estrategias como dividir la consulta o prefiltrar.
- Joins de cardinalidad alta: las joins que producen muchas más filas que el número de filas de entrada de la izquierda y la derecha pueden reducir drásticamente el rendimiento de las consultas. Evita las combinaciones que generen un número muy elevado de filas.
- Orden incorrecto de la tabla: asegúrate de haber elegido el tipo de unión adecuado, como
INNERoLEFT, y de haber ordenado las tablas de mayor a menor según los requisitos de tu consulta.
Optimizar
- Teclas de unión selectivas: para las teclas de unión, usa
INT64en lugar deSTRINGcuando sea posible. Las comparacionesSTRINGson más lentas que las comparacionesINT64porque comparan cada carácter de una cadena. Los números enteros solo requieren una comparación. - Filtrar antes de combinar: aplica filtros de cláusula
WHEREen tablas individuales antes de la combinación. De esta forma, se reduce la cantidad de datos implicados en la operación de unión. - Evita usar funciones en columnas de unión: no llames a funciones en columnas de unión. En su lugar, estandariza los datos de la tabla durante el proceso de ingestión o posterior a la ingestión mediante las canalizaciones de SQL ELT. Este enfoque elimina la necesidad de modificar las columnas de unión de forma dinámica, lo que permite que las uniones sean más eficientes sin comprometer la integridad de los datos.
- Evita las combinaciones automáticas: las combinaciones automáticas se suelen usar para calcular relaciones dependientes de las filas. Sin embargo, las autouniones pueden cuadruplicar el número de filas de salida, lo que puede provocar problemas de rendimiento. En lugar de usar combinaciones automáticas, te recomendamos que utilices funciones de ventana (analíticas).
- Tablas grandes primero: aunque el optimizador de consultas SQL puede determinar qué tabla debe estar a cada lado de la unión, ordena las tablas unidas de forma adecuada. La práctica recomendada es colocar primero la tabla más grande, seguida de la más pequeña y, después, las demás en orden descendente de tamaño.
- Desnormalización: en algunos casos, la desnormalización estratégica de las tablas (añadir datos redundantes) puede eliminar las combinaciones por completo. Sin embargo, este enfoque conlleva ciertas desventajas en cuanto al almacenamiento y la coherencia de los datos.
- Particiones y clústeres: las particiones de tablas basadas en claves de unión y los clústeres de datos colocados pueden acelerar significativamente las uniones, ya que permiten que BigQuery se dirija a las particiones de datos relevantes.
- Optimizar las uniones sesgadas: para evitar problemas de rendimiento asociados a las uniones sesgadas, filtra previamente los datos de la tabla lo antes posible o divide la consulta en dos o más consultas.
AGGREGATE paso
En el AGGREGATE paso, BigQuery agrega y agrupa los datos.
Depuración
- Detalles de la fase: comprueba el número de filas de entrada y de salida de la agregación, así como el tamaño de la aleatorización, para determinar cuántos datos se han reducido en el paso de agregación y si se ha aleatorizado algún dato.
- Tamaño de Shuffle: un tamaño de Shuffle grande puede indicar que se ha movido una cantidad significativa de datos entre los nodos de trabajador durante la agregación.
- Comprueba la distribución de los datos: asegúrate de que los datos se distribuyan de forma uniforme entre las particiones. Una distribución de datos sesgada puede provocar cargas de trabajo desequilibradas en el paso de agregación.
- Revisa las agregaciones: analiza las cláusulas de agregación para confirmar que son necesarias y eficientes.
Optimizar
- Agrupación en clústeres: agrupa tus tablas en columnas que se usen con frecuencia en
GROUP BY,COUNTu otras cláusulas de agregación. - Particiones: elige una estrategia de partición que se ajuste a tus patrones de consulta. Te recomendamos que uses tablas con particiones basadas en el momento de la ingestión para reducir la cantidad de datos analizados durante la agregación.
- Agrega antes: si es posible, realiza las agregaciones antes en la pipeline de consultas. De esta forma, se puede reducir la cantidad de datos que se deben procesar durante la agregación.
- Optimización de la aleatorización: si la aleatorización es un cuello de botella, busca formas de minimizarla. Por ejemplo, desnormalizar tablas o usar la agrupación en clústeres para colocar datos relevantes en el mismo lugar.
Casos límite
- Agregaciones DISTINCT: las consultas con agregaciones
DISTINCTpueden ser computacionalmente costosas, especialmente en conjuntos de datos grandes. Considera alternativas comoAPPROX_COUNT_DISTINCTpara obtener resultados aproximados. - Gran número de grupos: si la consulta genera un gran número de grupos, puede consumir una cantidad considerable de memoria. En estos casos, plantéate limitar el número de grupos o usar otra estrategia de agregación.
REPARTITION paso
Tanto REPARTITION como COALESCE son técnicas de optimización que BigQuery aplica directamente a los datos aleatorizados de la consulta.
REPARTITION: esta operación tiene como objetivo reequilibrar la distribución de datos entre los nodos de trabajo. Supongamos que, después de la aleatorización, un nodo de trabajador acaba teniendo una cantidad de datos desproporcionadamente grande. El pasoREPARTITIONredistribuye los datos de forma más uniforme, lo que evita que un solo trabajador se convierta en un cuello de botella. Esto es especialmente importante en el caso de las operaciones que requieren muchos recursos computacionales, como las uniones.COALESCE: este paso se produce cuando tienes muchos pequeños contenedores de datos después de la aleatorización. En el pasoCOALESCE, estos contenedores se combinan en otros más grandes, lo que reduce la sobrecarga asociada a la gestión de numerosos fragmentos de datos pequeños. Esto puede ser especialmente útil cuando se trata de conjuntos de resultados intermedios muy pequeños.
Si ves los pasos REPARTITION o COALESCE en tu plan de consulta, no significa necesariamente que haya un problema con tu consulta. A menudo, es una señal de que BigQuery está optimizando de forma proactiva la distribución de datos para mejorar el rendimiento. Sin embargo, si ves estas operaciones repetidamente, puede indicar que tus datos están sesgados o que tu consulta está provocando un movimiento excesivo de datos.
Optimizar
Para reducir el número de REPARTITION pasos, prueba lo siguiente:
- Distribución de datos: asegúrate de que tus tablas tengan particiones y clústeres de forma eficaz. Los datos bien distribuidos reducen la probabilidad de que se produzcan desequilibrios significativos después de la aleatorización.
- Estructura de la consulta: analiza la consulta para identificar posibles fuentes de sesgo en los datos. Por ejemplo, ¿hay filtros o uniones muy selectivos que provoquen que un solo trabajador procese un pequeño subconjunto de datos?
- Estrategias de unión: experimenta con diferentes estrategias de unión para ver si consigues una distribución de datos más equilibrada.
Para reducir el número de COALESCE pasos, prueba lo siguiente:
- Estrategias de agregación: plantéate realizar agregaciones en una fase anterior de la canalización de consultas. Esto puede ayudar a reducir el número de conjuntos de resultados intermedios pequeños que podrían provocar pasos
COALESCE. - Volumen de datos: si trabajas con conjuntos de datos muy pequeños,
COALESCEpuede que no sea un problema importante.
No optimices demasiado. La optimización prematura puede hacer que tus consultas sean más complejas sin ofrecer ventajas significativas.
Explicación de las consultas federadas
Las consultas federadas te permiten enviar una declaración de consulta a una fuente de datos externa mediante la EXTERNAL_QUERYfunción.
Las consultas federadas están sujetas a la técnica de optimización conocida como inserciones de SQL y el plan de consulta muestra las operaciones insertadas en la fuente de datos externa, si las hay. Por ejemplo, si ejecutas la siguiente consulta:
SELECT id, name
FROM EXTERNAL_QUERY("<connection>", "SELECT * FROM company")
WHERE country_code IN ('ee', 'hu') AND name like '%TV%'
El plan de consulta mostrará los siguientes pasos de la fase:
$1:id, $2:name, $3:country_code
FROM table_for_external_query_$_0(
SELECT id, name, country_code
FROM (
/*native_query*/
SELECT * FROM company
)
WHERE in(country_code, 'ee', 'hu')
)
WHERE and(in($3, 'ee', 'hu'), like($2, '%TV%'))
$1, $2
TO __stage00_output
En este plan, table_for_external_query_$_0(...) representa la función EXTERNAL_QUERY. Entre paréntesis, puedes ver la consulta que ejecuta la fuente de datos externa. En función de esto, puedes observar lo siguiente:
- Una fuente de datos externa devuelve solo 3 columnas seleccionadas.
- Una fuente de datos externa devuelve solo las filas en las que
country_codees'ee'o'hu'. - El operador
LIKEno se envía y lo evalúa BigQuery.
En comparación, si no hay pushdowns, el plan de consulta mostrará los siguientes pasos de la fase:
$1:id, $2:name, $3:country_code
FROM table_for_external_query_$_0(
SELECT id, name, description, country_code, primary_address, secondary address
FROM (
/*native_query*/
SELECT * FROM company
)
)
WHERE and(in($3, 'ee', 'hu'), like($2, '%TV%'))
$1, $2
TO __stage00_output
En esta ocasión, una fuente de datos externa devuelve todas las columnas y todas las filas de la tabla company, y BigQuery realiza el filtrado.
Metadatos de la cronología
La cronología de las consultas informa del progreso en momentos específicos, lo que proporciona vistas de resumen del progreso general de las consultas. La cronología se representa como una serie de muestras que informan de los siguientes detalles:
| Campo | Descripción |
|---|---|
elapsedMs |
Milisegundos transcurridos desde el inicio de la ejecución de la consulta. |
totalSlotMs |
Representación acumulativa de los milisegundos de ranura utilizados por la consulta. |
pendingUnits |
Total de unidades de trabajo programadas y pendientes de ejecución. |
activeUnits |
Número total de unidades de trabajo activas que están procesando los trabajadores. |
completedUnits |
Unidades de trabajo totales que se han completado al ejecutar esta consulta. |
Consulta de ejemplo
La siguiente consulta cuenta el número de filas del conjunto de datos público de Shakespeare y tiene un segundo recuento condicional que restringe los resultados a las filas que hacen referencia a "hamlet":
SELECT
COUNT(1) as rowcount,
COUNTIF(corpus = 'hamlet') as rowcount_hamlet
FROM `publicdata.samples.shakespeare`
Haz clic en Detalles de la ejecución para ver el plan de consulta:
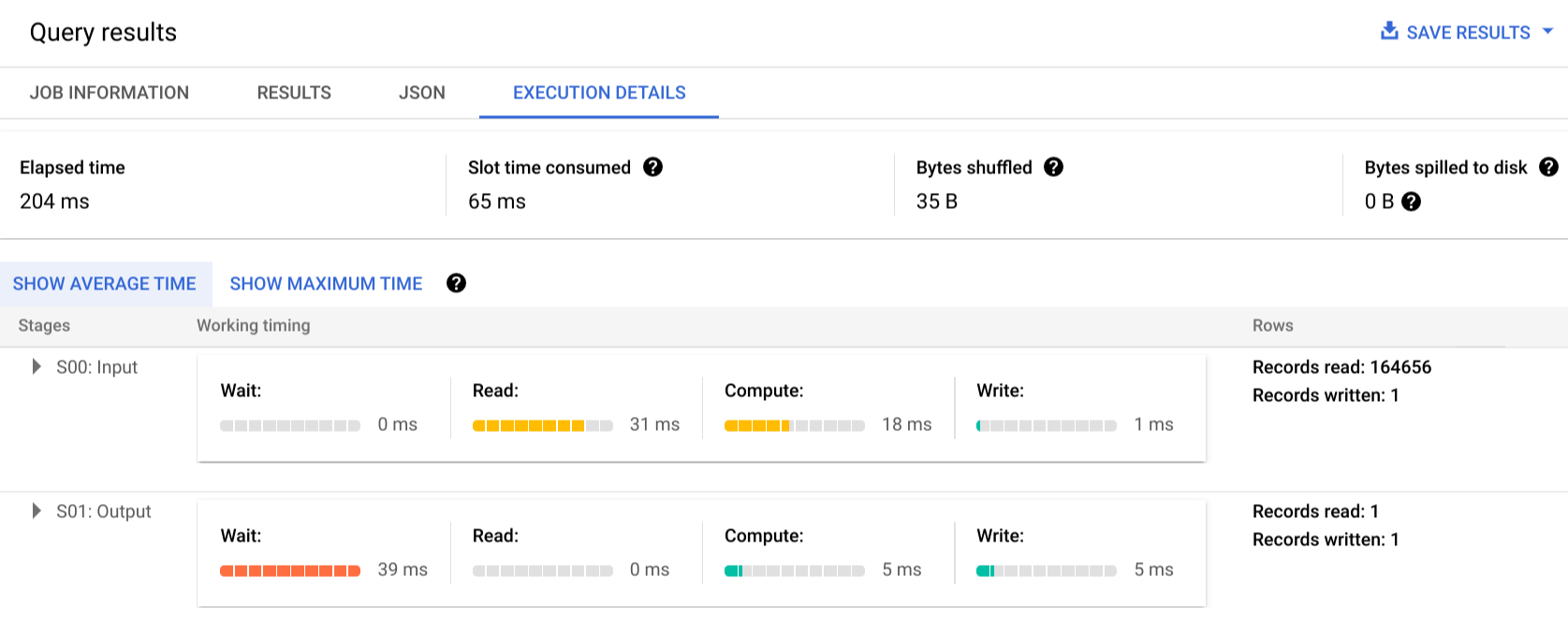
Los indicadores de color muestran los tiempos relativos de todos los pasos en todas las fases.
Para obtener más información sobre los pasos de las fases de ejecución, haz clic en para ver los detalles de la fase:
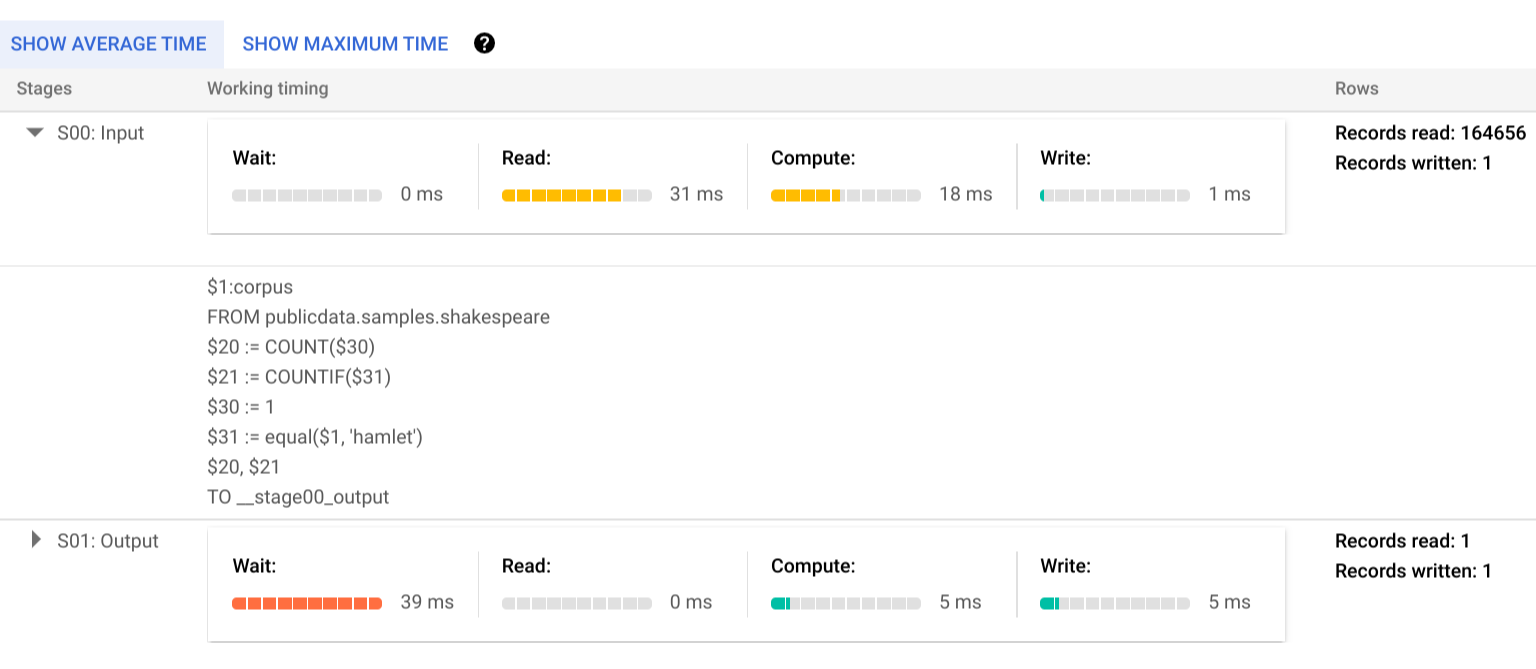
En este ejemplo, el tiempo más largo de cualquier segmento fue el tiempo que el único trabajador de la fase 01 esperó a que se completara la fase 00. Esto se debe a que la fase 01 dependía de la entrada de la fase 00 y no podía empezar hasta que la primera fase escribiera su salida en el paso intermedio.
Informes de errores
Es posible que los trabajos de consulta fallen durante la ejecución. Como la información del plan se actualiza periódicamente, puedes observar en qué parte del gráfico de ejecución se ha producido el error. En la Google Cloud consola, las fases completadas o fallidas se marcan con una marca de verificación o un signo de exclamación junto al nombre de la fase.
Para obtener más información sobre cómo interpretar y solucionar errores, consulta la guía de solución de problemas.
Representación de ejemplo de la API
La información del plan de consulta se incluye en la información de respuesta del trabajo y puedes obtenerla llamando a jobs.get.
Por ejemplo, el siguiente fragmento de una respuesta JSON de una tarea que devuelve la consulta de ejemplo de Hamlet muestra tanto el plan de consulta como la información de la cronología.
"statistics": {
"creationTime": "1576544129234",
"startTime": "1576544129348",
"endTime": "1576544129681",
"totalBytesProcessed": "2464625",
"query": {
"queryPlan": [
{
"name": "S00: Input",
"id": "0",
"startMs": "1576544129436",
"endMs": "1576544129465",
"waitRatioAvg": 0.04,
"waitMsAvg": "1",
"waitRatioMax": 0.04,
"waitMsMax": "1",
"readRatioAvg": 0.32,
"readMsAvg": "8",
"readRatioMax": 0.32,
"readMsMax": "8",
"computeRatioAvg": 1,
"computeMsAvg": "25",
"computeRatioMax": 1,
"computeMsMax": "25",
"writeRatioAvg": 0.08,
"writeMsAvg": "2",
"writeRatioMax": 0.08,
"writeMsMax": "2",
"shuffleOutputBytes": "18",
"shuffleOutputBytesSpilled": "0",
"recordsRead": "164656",
"recordsWritten": "1",
"parallelInputs": "1",
"completedParallelInputs": "1",
"status": "COMPLETE",
"steps": [
{
"kind": "READ",
"substeps": [
"$1:corpus",
"FROM publicdata.samples.shakespeare"
]
},
{
"kind": "AGGREGATE",
"substeps": [
"$20 := COUNT($30)",
"$21 := COUNTIF($31)"
]
},
{
"kind": "COMPUTE",
"substeps": [
"$30 := 1",
"$31 := equal($1, 'hamlet')"
]
},
{
"kind": "WRITE",
"substeps": [
"$20, $21",
"TO __stage00_output"
]
}
]
},
{
"name": "S01: Output",
"id": "1",
"startMs": "1576544129465",
"endMs": "1576544129480",
"inputStages": [
"0"
],
"waitRatioAvg": 0.44,
"waitMsAvg": "11",
"waitRatioMax": 0.44,
"waitMsMax": "11",
"readRatioAvg": 0,
"readMsAvg": "0",
"readRatioMax": 0,
"readMsMax": "0",
"computeRatioAvg": 0.2,
"computeMsAvg": "5",
"computeRatioMax": 0.2,
"computeMsMax": "5",
"writeRatioAvg": 0.16,
"writeMsAvg": "4",
"writeRatioMax": 0.16,
"writeMsMax": "4",
"shuffleOutputBytes": "17",
"shuffleOutputBytesSpilled": "0",
"recordsRead": "1",
"recordsWritten": "1",
"parallelInputs": "1",
"completedParallelInputs": "1",
"status": "COMPLETE",
"steps": [
{
"kind": "READ",
"substeps": [
"$20, $21",
"FROM __stage00_output"
]
},
{
"kind": "AGGREGATE",
"substeps": [
"$10 := SUM_OF_COUNTS($20)",
"$11 := SUM_OF_COUNTS($21)"
]
},
{
"kind": "WRITE",
"substeps": [
"$10, $11",
"TO __stage01_output"
]
}
]
}
],
"estimatedBytesProcessed": "2464625",
"timeline": [
{
"elapsedMs": "304",
"totalSlotMs": "50",
"pendingUnits": "0",
"completedUnits": "2"
}
],
"totalPartitionsProcessed": "0",
"totalBytesProcessed": "2464625",
"totalBytesBilled": "10485760",
"billingTier": 1,
"totalSlotMs": "50",
"cacheHit": false,
"referencedTables": [
{
"projectId": "publicdata",
"datasetId": "samples",
"tableId": "shakespeare"
}
],
"statementType": "SELECT"
},
"totalSlotMs": "50"
},
Usar información de ejecución
Los planes de consulta de BigQuery proporcionan información sobre cómo ejecuta el servicio las consultas, pero la naturaleza gestionada del servicio limita si algunos detalles se pueden aplicar directamente. Muchas optimizaciones se realizan automáticamente al usar el servicio, que puede ser diferente de otros entornos en los que la configuración, el aprovisionamiento y la monitorización pueden requerir personal especializado.
Para consultar técnicas específicas que pueden mejorar la ejecución y el rendimiento de las consultas, consulta la documentación sobre prácticas recomendadas. Las estadísticas del plan de consulta y de la cronología pueden ayudarte a determinar si determinadas fases dominan la utilización de recursos. Por ejemplo, una fase JOIN que genera muchas más filas de salida que de entrada puede indicar que se puede filtrar antes en la consulta.
Además, la información de la cronología puede ayudar a identificar si una consulta determinada es lenta de forma aislada o debido a los efectos de otras consultas que compiten por los mismos recursos. Si observa que el número de unidades activas sigue siendo limitado durante toda la vida útil de la consulta, pero la cantidad de unidades de trabajo en cola sigue siendo alta, puede que se trate de casos en los que reducir el número de consultas simultáneas puede mejorar significativamente el tiempo de ejecución general de determinadas consultas.