このチュートリアルでは、Databricks ノートブックのデータを読み取り / 書き込みするために BigQuery テーブルやビューを接続する方法を説明します。ここでは、Google Cloud コンソールと Databricks ワークスペースを使用する手順を説明します。この処理は gcloud と databricks コマンドライン ツールでも可能ですが、このチュートリアルでは説明しません。
Databricks on Google Cloud は、 Google Cloudでホストされ、Google Kubernetes Engine(GKE)上で実行されるDatabricks 環境であり、BigQuery などの Google Cloud テクノロジーとの連携機能が予め組み込まれています。Databricks を初めて使用する場合は、Databricks Unified Data Platform の概要にある動画で Databricks レイクハウス プラットフォームの概要をご覧ください。
Google Cloudに Databricks をデプロイする
次の手順を行い、 Google Cloudに Databricks をデプロイする準備をします。
- Databricks アカウントを設定するには、Databricks のドキュメント Google Cloudアカウントで Databricks をセットアップする の手順を行います。
- 登録後は、Databricks アカウントの管理方法を確認してください。
Databricks ワークスペース、クラスタ、ノートブックを作成する
以下では、BigQuery にアクセスするコードを記述するために、Databricks ワークスペース、クラスタ、Python ノートブックを作成する方法について説明します。
Databrick の前提条件を確認します。
最初のワークスペースを作成します。Databricks アカウント コンソールで、[ワークスペースを作成] をクリックします。
[ワークスペース名] に
gcp-bqを指定し、リージョンを選択します。![ワークスペース名、リージョン、 Google Cloudプロジェクト ID が表示されている [ワークスペースを作成] 画面](https://cloud.google.com/static/bigquery/images/create-workspace-configuration.png?hl=ja)
Google Cloud プロジェクト ID を指定するには、 Google Cloud コンソールでプロジェクト ID をコピーし、[Google Cloud プロジェクト ID] フィールドに貼り付けます。
[保存] をクリックして、Databricks ワークスペースを作成します。
Databricks ランタイム 7.6 以降で Databricks クラスタを作成するには、左側のメニューバーで [クラスター] を選択し、上部にある [クラスターを作成] をクリックします。
クラスタの名前とサイズを指定して、[詳細オプション] をクリックし、 Google Cloudサービス アカウントのメールアドレスを指定します。
![Google サービス アカウントの詳細が表示されている [新しいクラスター] 画面](https://cloud.google.com/static/bigquery/images/new-databricks-cluster.png?hl=ja)
[クラスターを作成] をクリックします。
Databricks 用の Python ノートブックを作成するには、ノートブックを作成するの手順を行ってください。
Databricks から BigQuery へのクエリ
前述の構成を使用すると、Databricks を BigQuery に安全に接続できます。Databricks は、オープンソースの Google Spark アダプタの fork を使用して BigQuery にアクセスします。
Databricks は、ネストされた列のフィルタリングなど、特定のクエリ述語を自動的に BigQuery にプッシュダウンすることで、データ転送を削減してクエリを高速化します。また、query() API を使用して BigQuery で最初に SQL クエリを実行する追加機能により、結果のデータセットの転送サイズが削減されます。
以降の手順では、BigQuery のデータセットにアクセスして独自のデータを BigQuery に書き込む方法について説明します。
BigQuery の一般公開データセットにアクセスする
BigQuery には、利用可能な一般公開データセットのリストが用意されています。一般公開データセットの一部である BigQuery Shakespeare データセットにクエリを実行するには、次の手順を行います。
BigQuery テーブルを読み取るには、Databricks ノートブックで次のコード スニペットを使用します。
table = "bigquery-public-data.samples.shakespeare" df = spark.read.format("bigquery").option("table",table).load() df.createOrReplaceTempView("shakespeare")Shift+Returnを押してコードを実行します。これで、Spark DataFrame(
df)を介して BigQuery テーブルにクエリを実行できるようになりました。たとえば、データフレームの最初の 3 行を表示するには、次のように入力します。df.show(3)別のテーブルにクエリを実行するには、
table変数を更新します。Databricks ノートブックの主な特長は、Scala、Python、SQL などのさまざまな言語のセルを 1 つのノートブックに混在できる点です。
次の SQL クエリを使用すると、一時ビューを作成する前のセルを実行した後に、Shakespeare 内の単語数を可視化できます。
%sql SELECT word, SUM(word_count) AS word_count FROM words GROUP BY word ORDER BY word_count DESC LIMIT 12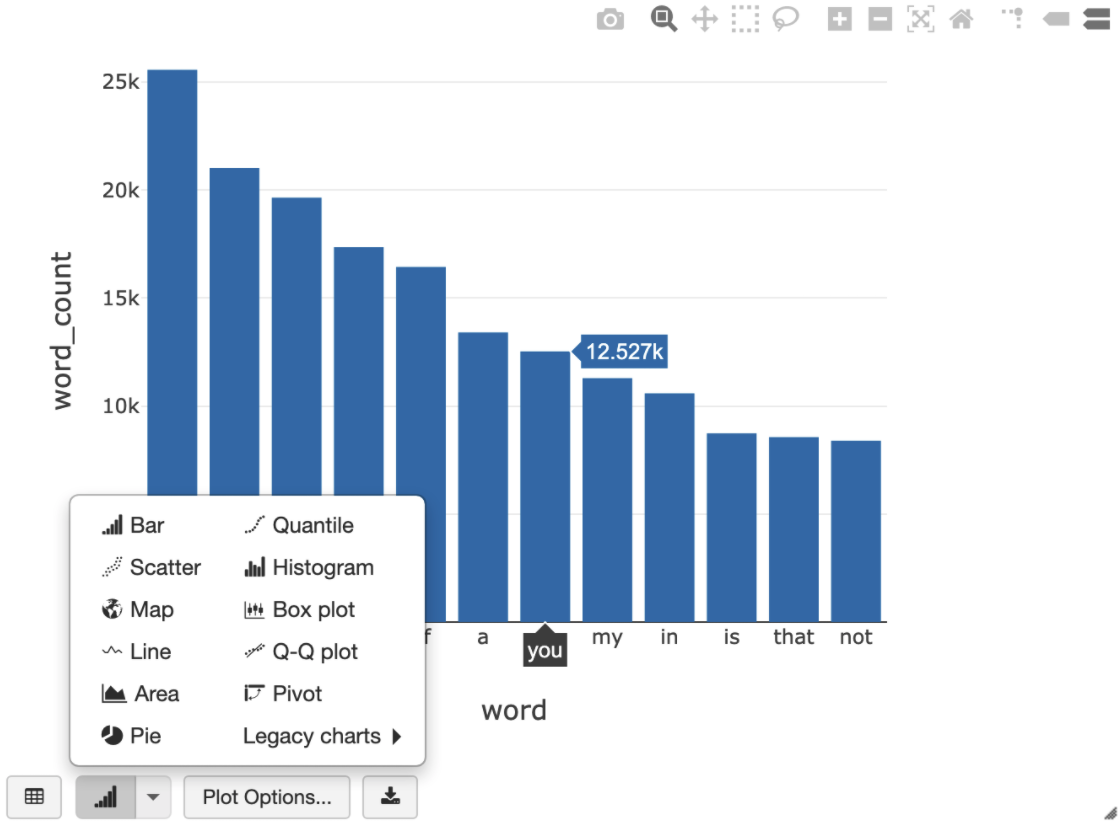
上述のセルは、BigQuery ではなく、Databricks クラスタ内のデータフレームに Spark SQL クエリを実行します。このアプローチの利点は、データ分析が Spark レベルで行われるため、それ以上 BigQuery API 呼び出しは発行されず、追加の BigQuery コストが発生しない点です。
また、
query()API を使用して SQL クエリの実行を BigQuery に委任することで、結果として生じるデータフレームの転送サイズを小さくすることもできます。この方法を使用すると、Spark で処理を行う上述の例とは異なり、BigQuery でのクエリの実行に対して料金とクエリの最適化が適用されます。次の例では、Scala、
query()API、および 一般公開の Shakespeare データセットを BigQuery で使用して、シェイクスピア作品の中で出現頻度の高い上位 5 つの単語を計算します。コードを実行する前に、BigQuery でmdatasetという空のデータセットを作成し、コードから参照できるようにします。詳細については、BigQuery へのデータの書き込みをご覧ください。%scala // public dataset val table = "bigquery-public-data.samples.shakespeare" // existing dataset where the Google Cloud user has table creation permission val tempLocation = "mdataset" // query string val q = s"""SELECT word, SUM(word_count) AS word_count FROM ${table} GROUP BY word ORDER BY word_count DESC LIMIT 10 """ // read the result of a GoogleSQL query into a DataFrame val df2 = spark.read.format("bigquery") .option("query", q) .option("materializationDataset", tempLocation) .load() // show the top 5 common words in Shakespeare df2.show(5)その他のコード例については、Databricks BigQuery サンプル ノートブックをご覧ください。
BigQuery へのデータの書き込み
BigQuery テーブルは、データセットに存在します。BigQuery テーブルにデータを書き込む前に、BigQuery に新しいデータセットを作成する必要があります。Databricks Python ノートブックのデータセットを作成するには、次の操作を行います。
Google Cloud コンソールの [BigQuery] ページに移動します。
[アクションを表示] オプションを開き、[データセットを作成] をクリックして、「
together」という名前を付けます。Databricks Python ノートブックで次のコード スニペットを使用して、Python リストから 3 つの文字列エントリを含むシンプルな Spark データフレームを作成します。
from pyspark.sql.types import StringType mylist = ["Google", "Databricks", "better together"] df = spark.createDataFrame(mylist, StringType())別のセルをノートブックに追加し、前の手順で作成した Spark データフレームをデータセット
togetherの BigQuery テーブルmyTableに書き込みます。テーブルが作成または上書きされます。前に指定したバケット名が使用されます。bucket = YOUR_BUCKET_NAME table = "together.myTable" df.write .format("bigquery") .option("temporaryGcsBucket", bucket) .option("table", table) .mode("overwrite").save()データが正常に書き込まれたことを確認するには、Spark データフレーム(
df)を介して BigQuery テーブルにクエリを実行し、結果を表示します。display(spark.read.format("bigquery").option("table", table).load)