솔루션 가이드: 베어메탈 솔루션의 Oracle용 Google Cloud 백업 및 DR
개요
베어메탈 솔루션 환경 내에서 Oracle 데이터베이스의 탄력성을 제공하려면 데이터베이스 백업 및 재해 복구에 대한 명확한 전략이 필요합니다. 이 요구사항을 해결할 수 있도록 Google Cloud의 솔루션 설계자팀은 Google Cloud 백업 및 DR 서비스의 광범위한 테스트를 수행하고 발견 항목을 이 가이드에 컴파일했습니다. 따라서 백업 및 DR 서비스를 사용하여 베어메탈 솔루션 환경 내에서 Oracle 데이터베이스용 백업 및 복구 옵션을 배포, 구성, 최적화하는 가장 좋은 방법을 소개합니다. 또한 자체 환경과 비교할 벤치마크를 만들 수 있도록 테스트 결과에서 가져온 성능 수치도 공유합니다. 이 가이드는 백업 관리자, Google Cloud 관리자 또는 Oracle DBA에게 유용합니다.
배경
2022년 6월, 솔루션 설계자팀은 기업 고객을 위한 Google Cloud 백업 및 DR의 개념 증명(PoC) 데모를 시작했습니다 성공 기준을 충족하려면 50TB Oracle 데이터베이스 복구를 지원하고 24시간 이내에 데이터베이스를 복원해야 했습니다.
이 목표를 달성하기에는 여러 가지 어려움이 있었지만 PoC에 참여한 대부분의 사람들은 이 결과를 달성할 수 있고 PoC를 진행해야 한다고 생각했습니다. 우리는 이러한 결과를 얻을 수 있음을 보여 주는 백업 및 DR 엔지니어링팀의 이전 테스트 데이터가 있었기 때문에 위험성이 비교적 낮다고 생각했습니다. 또한 고객이 PoC 진행을 편안하게 생각할 수 있도록 테스트 결과를 고객에게 공유했습니다.
PoC 중에 베어메탈 솔루션 환경에서 Oracle, Google Cloud 백업 및 DR, 스토리지, 리전별 확장 링크 등 여러 요소를 성공적으로 구성하는 방법을 학습했습니다. Google에서 학습한 권장사항을 따르면 성공적인 결과를 얻을 수 있습니다.
'효율성이 다를 수 있습니다'는 이 문서의 전반적인 결과를 생각하기에 좋은 방법입니다. Google의 목표는 우리가 학습한 내용, 고객이 집중해야 하는 사항, 피해야 할 사항, 원하는 성능이나 결과를 얻지 못한 경우 파악할 영역에 관한 지식을 공유하는 것입니다. 이 가이드를 통해 제안된 솔루션에 대한 신뢰를 구축하고 요구사항을 충족할 수 있기를 바랍니다.
아키텍처
그림 1은 베어메탈 솔루션 환경에서 실행되는 Oracle 데이터베이스를 보호하기 위해 백업 및 DR을 배포할 때 빌드해야 하는 인프라의 간소화된 보기를 보여줍니다.
그림 1: 베어메탈 솔루션 환경에서 Oracle 데이터베이스에 백업 및 DR을 사용하는 구성요소

다이어그램에서 볼 수 있듯이 이 솔루션에는 다음 구성요소가 필요합니다.
- 베어메탈 솔루션 리전 확장 프로그램:Google Cloud 데이터 센터에 인접한 서드 파티 데이터 센터에서 Oracle 데이터베이스를 실행하고 기존 온프레미스 소프트웨어 라이선스를 사용할 수 있습니다.
- 백업 및 DR 서비스 프로젝트: 백업/복구 어플라이언스를 호스팅하고 Cloud Storage 버킷에 베어메탈 솔루션 및 Google Cloud 워크로드를 백업할 수 있습니다.
- Compute 서비스 프로젝트: Compute Engine VM을 실행할 위치를 제공합니다.
- 백업 및 DR 서비스: 백업 및 재해 복구를 유지할 수 있는 백업 및 DR 관리 콘솔을 제공합니다.
- 호스트 프로젝트: 베어메탈 솔루션 리전 확장 프로그램을 백업 및 DR 서비스, 백업/복구 어플라이언스, Cloud Storage 버킷 및 Compute Engine VM에 연결할 수 있는 공유 VPC에 리전별 서브넷을 만들 수 있습니다.
Google Cloud 백업 및 DR 설치
백업 및 DR 솔루션이 작동하려면 다음 두 가지 주요 구성요소가 필요합니다.
- 백업 및 DR 관리 콘솔: Google Cloud 콘솔 내에서 백업을 만들고 관리할 수 있는 HTML 5 UI 및 API 엔드포인트입니다.
- 백업/복구 어플라이언스: 이 기기는 백업을 수행하는 태스크 작업자 역할을 하며 유형 태스크를 마운트 및 복원합니다.
Google Cloud에서 백업 및 DR 관리 콘솔을 관리합니다. 서비스 프로듀서 프로젝트(Google Cloud 관리 측)에 관리 콘솔을 배포해야 하며 서비스 소비자 프로젝트(고객 측)에 백업/복원 어플라이언스를 배포해야 합니다. 백업 및 DR에 대한 자세한 내용은 백업 및 DR 배포 설정 및 계획을 참조하세요. 서비스 프로듀서 및 서비스 소비자의 정의를 보려면 Google Cloud 용어집을 참조하세요.
시작하기 전에
Google Cloud 백업 및 DR 서비스를 설치하려면 배포를 시작하기 전에 다음 구성 단계를 완료해야 합니다.
- 비공개 서비스 액세스 연결을 사용 설정합니다. 설치를 시작하려면 먼저 이 연결을 설정해야 합니다. 비공개 서비스 액세스 서브넷이 이미 구성되어 있는 경우에도 최소
/23서브넷이 있어야 합니다. 예를 들어 비공개 서비스 액세스 연결에 이미/24서브넷을 구성한 경우/23서브넷을 추가하는 것이 좋습니다. 또한 나중에 서비스를 더 추가할 수 있도록/20서브넷을 추가할 수도 있습니다. - 백업/복구 어플라이언스를 배포하는 VPC 네트워크에서 액세스할 수 있도록 Cloud DNS를 구성합니다. 이렇게 하면 비공개 또는 공개 조회를 통해 googleapis.com을 적절하게 해결할 수 있습니다.
- 네트워크 기본 경로 및 방화벽 규칙을 구성하여
*.googleapis.com(공개 IP 사용) 또는 TCP 포트 443의private.googleapis.com(199.36.153.8/30)으로의 이그레스 트래픽을 허용하거나0.0.0.0/0의 명시적 이그레스를 허용합니다. 다시 백업/복구 어플라이언스를 설치할 VPC 네트워크에서 경로와 방화벽을 구성해야 합니다. 또한 선호 옵션으로 Google 비공개 액세스를 사용하는 것이 좋습니다. 자세한 내용은 비공개 Google 액세스 구성을 참조하세요. - 소비자 프로젝트에 다음 API 사용 설정:
- 조직 정책을 사용 설정한 경우 다음을 구성해야 합니다.
constraints/cloudkms.allowedProtectionLevels에는SOFTWARE또는ALL이 포함됩니다.
- 다음 방화벽 규칙을 구성합니다.
- Compute Engine VPC의 백업/복구 어플라이언스에서 포트 TCP-5106의 Linux 호스트(에이전트)로 인그레스합니다.
- iSCSI와 함께 블록 기반 백업 디스크를 사용하는 경우 베어메탈 솔루션의 Linux 호스트(에이전트)에서 TCP-3260 포트의 Compute Engine VPC에 있는 백업/복구 어플라이언스로 이그레스합니다.
- NFS 또는 dNFS 기반 백업 디스크를 사용하는 경우 베어메탈 솔루션의 Linux 호스트(에이전트)에서 다음 포트의 Compute Engine VPC에서 백업/복구 어플라이언스로 이그레스합니다.
- TCP/UDP-111(rpcbind)
- TCP/UDP-756(status)
- TCP/UDP-2049(nfs)
- TCP/UDP-4001(mountd)
- TCP/UDP-4045(nlockmgr)
- 베어메탈 솔루션 호스트 이름 및 도메인을 확인하도록 Google Cloud DNS를 구성하여 베어메탈 솔루션 서버, VM, 백업 및 DR 서비스와 같은 Compute Engine 기반 리소스에서 이름 변환이 일관되도록 합니다.
백업 및 DR 관리 콘솔 설치
- 백업 및 DR 서비스 API를 아직 사용 설정하지 않았다면 사용 설정합니다.
Google Cloud 콘솔에서 탐색 메뉴를 사용하여 작업 섹션으로 이동하고 백업 및 DR을 선택합니다.
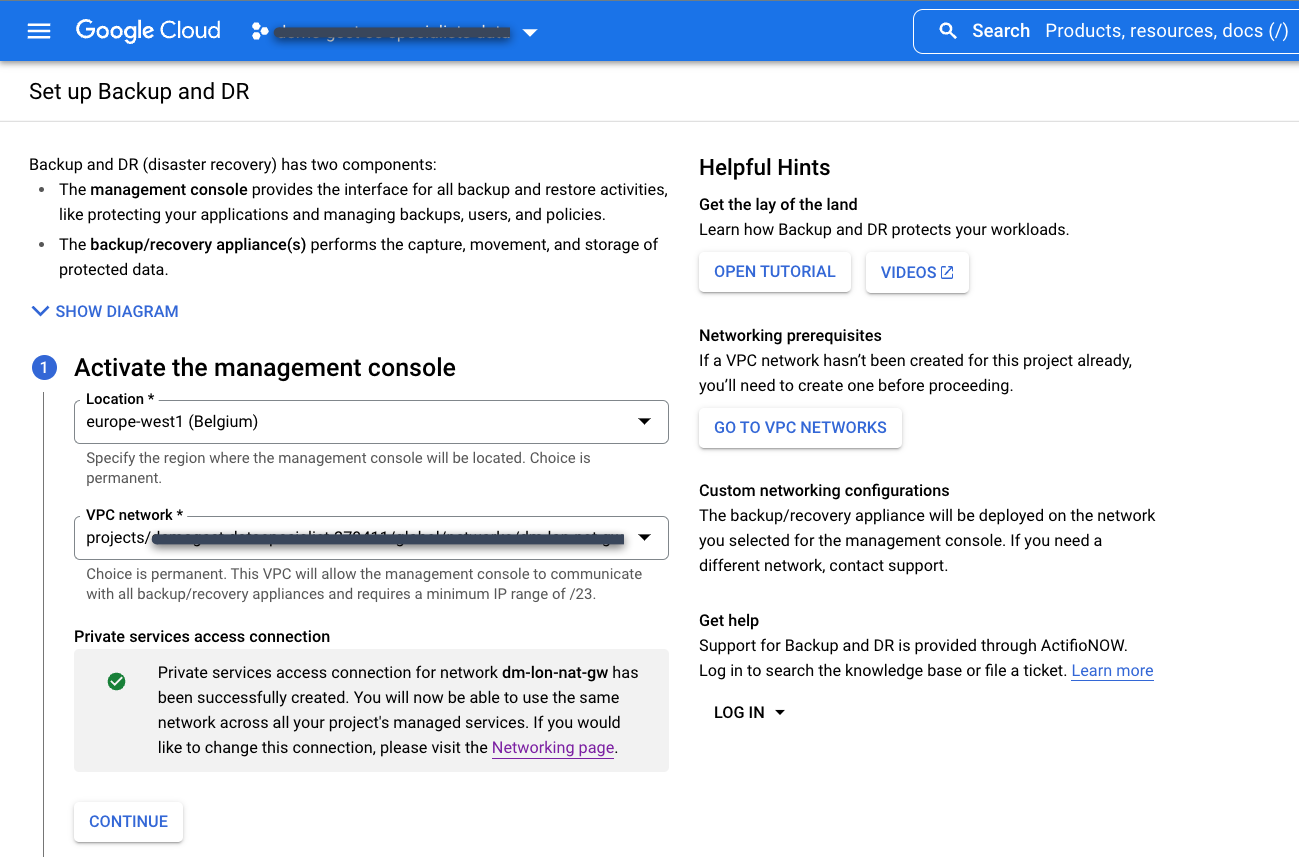
이전에 만든 기존의 비공개 서비스 액세스 연결을 선택합니다.
백업 및 DR 관리 콘솔의 위치를 선택합니다. 서비스 프로듀서 프로젝트에서 백업 및 DR 관리 콘솔 사용자 인터페이스를 배포하는 리전입니다. Google Cloud는 관리 콘솔 리소스를 소유하고 유지보수합니다.
백업 및 DR 서비스에 연결하려는 서비스 소비자 프로젝트에서 VPC 네트워크를 선택합니다. 이는 일반적으로 공유 VPC 또는 호스트 프로젝트입니다.
최대 1시간을 기다린 후 배포가 완료되면 다음 화면이 표시됩니다.
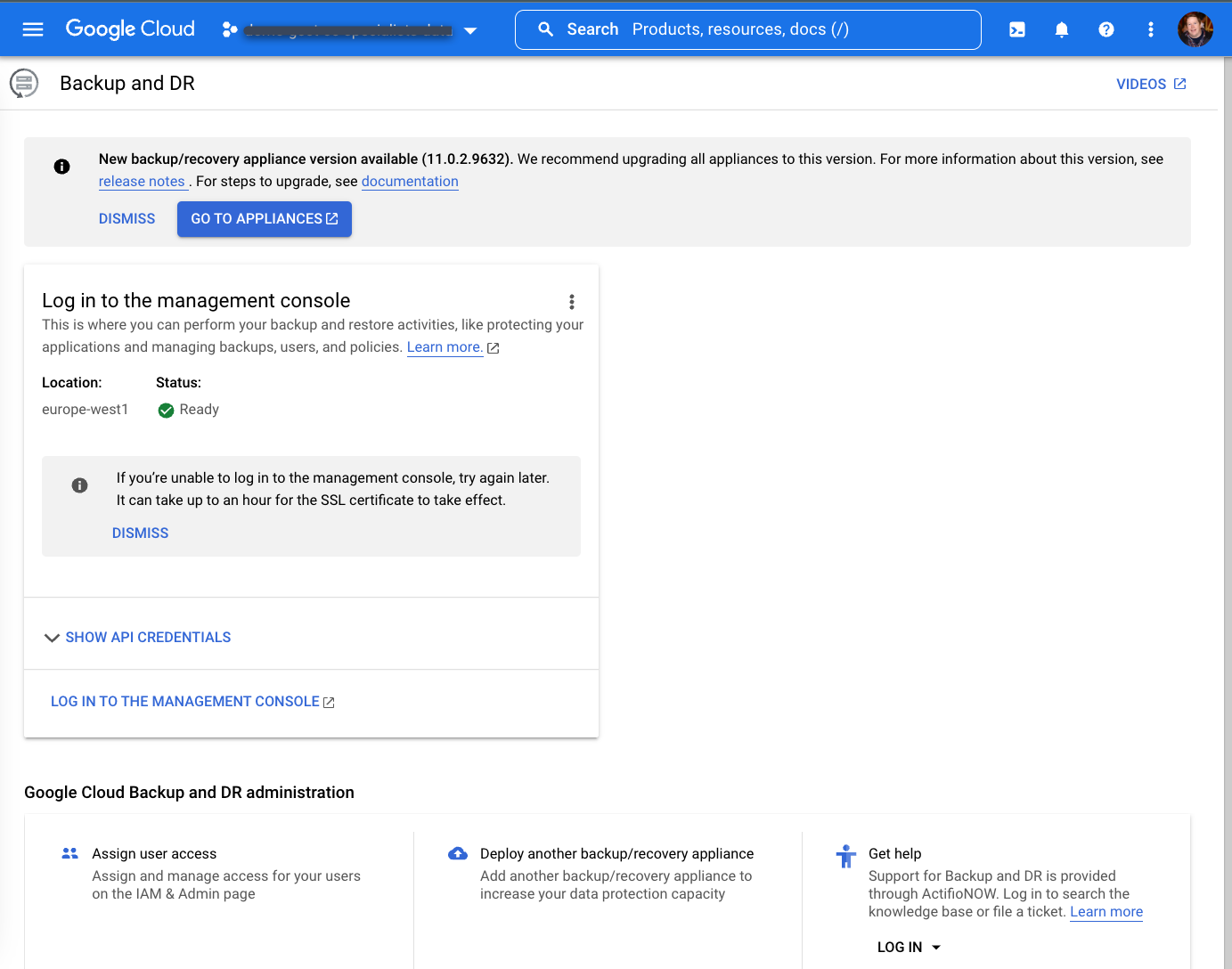
백업/복구 어플라이언스 설치
백업 및 DR 페이지에서 관리 콘솔에 로그인을 클릭합니다.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/
백업 및 DR 관리 콘솔의 기본 페이지에서 어플라이언스 페이지로 이동합니다.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#clusters
백업/복구 어플라이언스의 이름을 입력합니다. Google Cloud는 배포가 시작된 후 이름 끝에 난수를 자동으로 추가합니다.
백업/복구 어플라이언스를 설치할 소비자 프로젝트를 선택합니다.
원하는 리전, 영역, 서브네트워크를 선택합니다.
스토리지 유형 선택 PoC에는 표준 영구 디스크를, 프로덕션 환경에서는 SSD 영구 디스크를 선택하는 것이 좋습니다.
설치 시작 버튼을 클릭합니다. 백업 및 DR 관리 콘솔과 첫 번째 백업/복구 어플라이언스를 모두 배포하는 데 1시간 정도 걸릴 것으로 예상됩니다.
초기 설치 프로세스가 완료된 후 다른 리전 또는 영역에 다른 백업/복구 어플라이언스를 추가할 수 있습니다.
Google Cloud 백업 및 DR 구성
이 섹션에서는 백업 및 DR 서비스를 구성하고 워크로드를 보호하는 데 필요한 단계를 알아봅니다.
서비스 계정 구성
버전 11.0.2(백업 및 DR의 2022년 12월 출시 버전)부터는 단일 서비스 계정을 사용하여 백업/복구 어플라이언스를 실행하여 Cloud Storage 버킷에 액세스하고 Compute Engine 가상 머신(VM)을 보호할 수 있습니다(이 문서에서 다루지 않음).
서비스 계정 역할
Google Cloud 백업 및 DR은 사용자 및 서비스 계정 승인과 인증에 Google Cloud Identity and Access Management(IAM)를 사용합니다. 사전 정의된 역할을 사용하여 다양한 백업 기능을 사용 설정할 수 있습니다. 다음 두 가지가 가장 중요합니다.
- 백업 및 DR Cloud Storage 작업자: Cloud Storage 버킷에 연결하는 백업/복구 어플라이언스에서 사용하는 서비스 계정에 이 역할을 할당합니다. 이 역할로 Compute Engine 스냅샷 백업을 위한 Cloud Storage 버킷을 만들고 워크로드 복원을 위해 기존 에이전트 기반 백업 데이터가 포함된 버킷에 액세스할 수 있습니다.
- 백업 및 DR Compute Engine 작업자: 백업/복구 어플라이언스에서 Compute Engine 가상 머신의 영구 디스크 스냅샷을 만드는 데 사용하는 서비스 계정에 이 역할을 할당합니다. 이 역할을 사용하면 스냅샷을 만드는 것 외에도 서비스 계정이 동일한 소스 프로젝트 또는 대체 프로젝트에서 VM을 복원할 수 있게 해줍니다.
소비자/서비스 프로젝트에서 백업/복구 어플라이언스를 실행하는 Compute Engine VM을 보고 API 및 ID 관리 섹션에 나열된 서비스 계정 값을 확인하여 서비스 계정을 찾을 수 있습니다.
백업/복구 어플라이언스에 적절한 권한을 제공하려면 Identity and Access Management 페이지로 이동하고 다음 Identity and Access Management 역할을 백업/복구 어플라이언스 서비스 계정에 부여합니다.
- 백업 및 DR Cloud Storage 작업자
- 백업 및 DR Compute Engine 작업자(선선택사항)
스토리지 풀 구성
스토리지 풀은 데이터를 물리적 스토리지 위치에 저장합니다. 최신 데이터(1~14일)에 영구 디스크를 사용하고 장기 보관 데이터(일, 주, 월, 년)에 Cloud Storage를 사용해야 합니다.
Cloud Storage
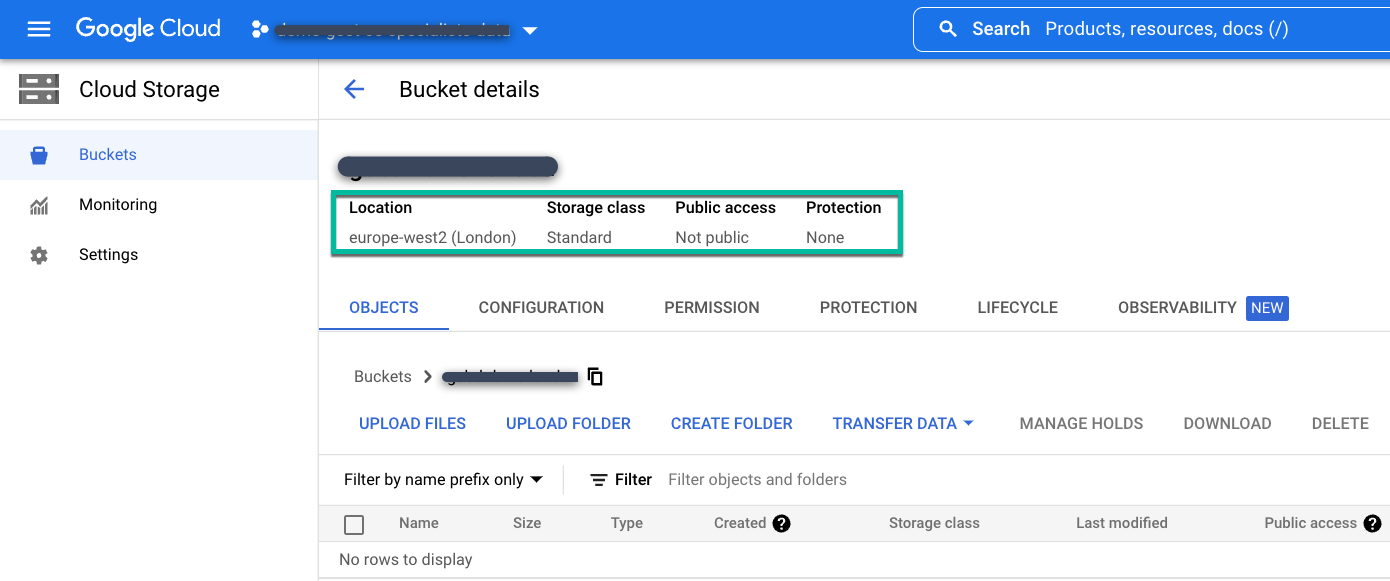
백업 데이터를 저장해야 하는 위치에 리전 또는 멀티 리전 표준 버킷을 만듭니다.
다음 안내에 따라 Cloud Storage 버킷을 만듭니다.
- Cloud Storage 버킷 페이지에서 버킷 이름을 지정합니다.
- 스토리지 위치를 선택합니다.
- Standard, Nearline, Coldline과 같은 스토리지 클래스를 선택합니다.
- Nearline 또는 Coldline 스토리지를 선택하는 경우 액세스 제어 모드를 세분화된 액세스 제어로 설정합니다. 표준 스토리지의 경우 기본 액세스 제어 모드인 동일을 수락합니다.
마지막으로 추가 데이터 보호 옵션을 구성하지 말고 만들기를 클릭합니다.
그런 다음 이 버킷을 백업/복구 어플라이언스에 추가합니다. 백업 및 DR 관리 콘솔로 이동합니다.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/
관리 > 스토리지 풀 메뉴 항목을 선택합니다.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#pools
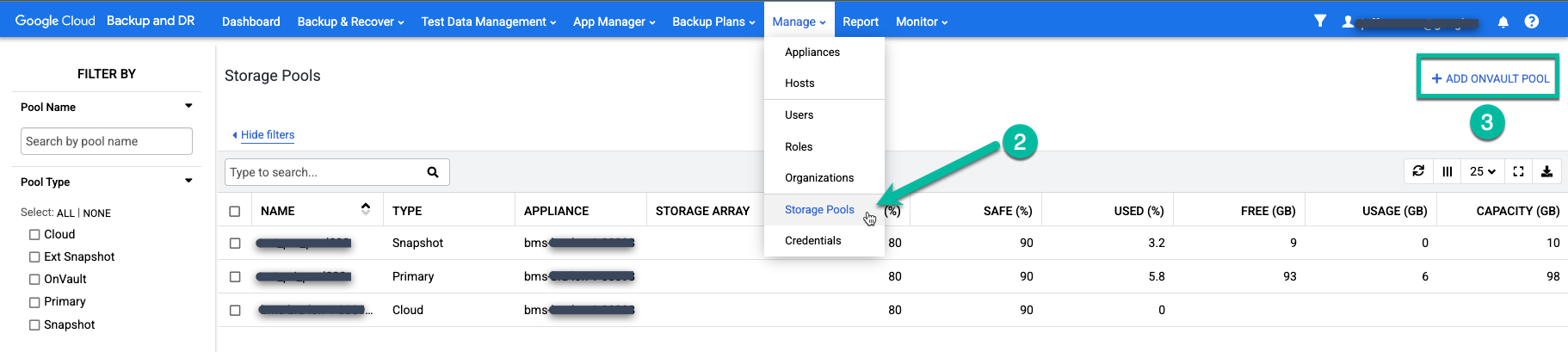
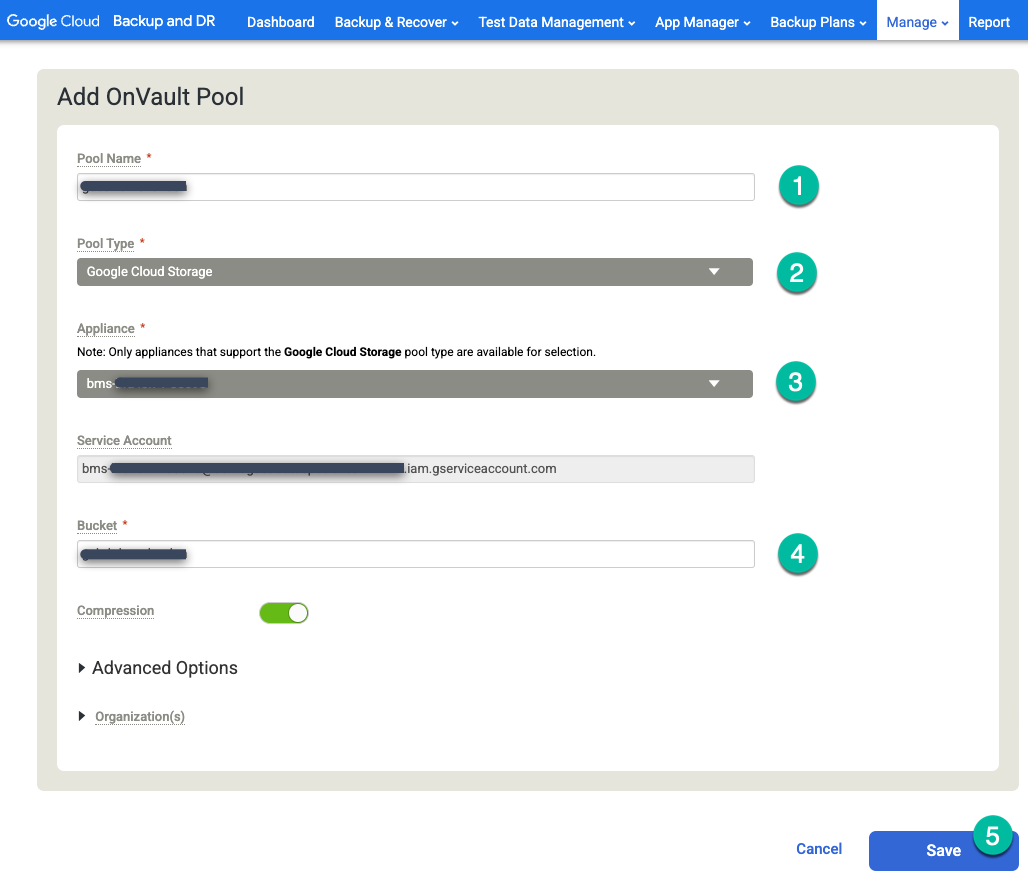
맨 오른쪽 옵션 +OnVault 풀 추가를 클릭합니다.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#addonvaultpool
- 풀 이름에 이름을 입력합니다.
- 풀 유형으로 Google Cloud Storage를 선택합니다.
- Cloud Storage 버킷에 연결할 어플라이언스를 선택합니다.
- Cloud Storage 버킷 이름을 입력합니다.
저장을 클릭합니다.
영구 디스크 스냅샷 풀
표준 또는 SSD 옵션으로 백업/복구 어플라이언스를 배포한 경우 영구 디스크 스냅샷 풀은 기본적으로 4TB입니다. 소스 데이터베이스 또는 파일 시스템에 더 큰 크기 풀이 필요한 경우 배포된 백업/복구 어플라이언스의 설정을 수정하고 새 영구 디스크를 추가하고 새 커스텀 풀을 만들거나 다른 기본 풀을 구성할 수 있습니다.
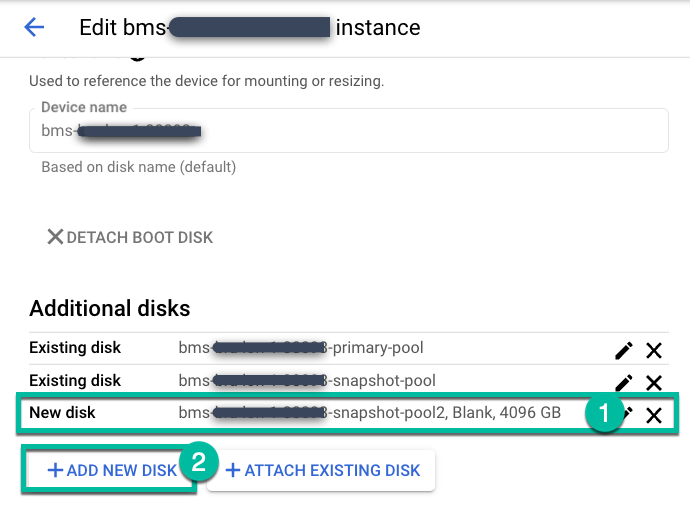
관리 > 어플라이언스 페이지로 이동합니다.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#clusters
백업 서버 인스턴스를 수정하고 +새 디스크 추가를 클릭합니다.
- 디스크에 이름을 지정합니다.
- 빈 디스크 유형을 선택합니다.
- 필요에 따라 표준, 균형 있는, SSD 중에서 선택합니다.
- 필요한 디스크 크기를 입력합니다.
저장을 클릭합니다.
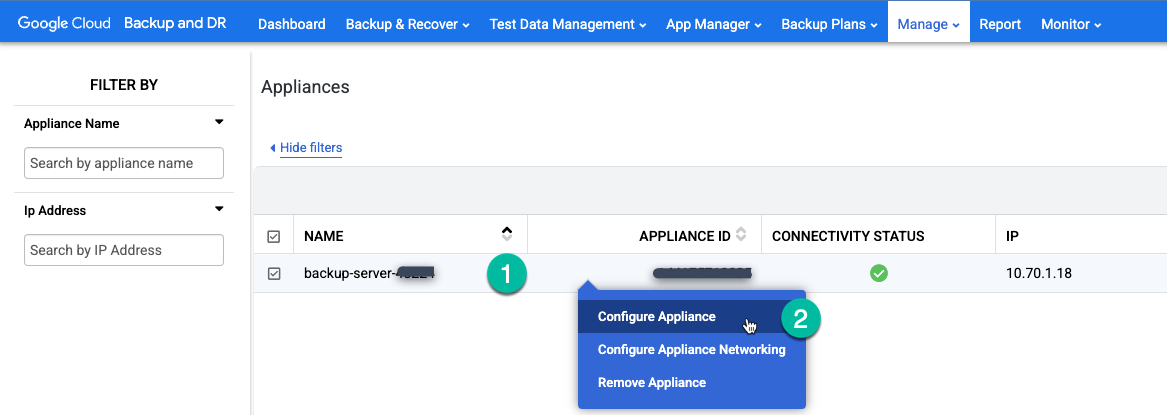
백업 및 DR 관리 콘솔에서 관리 > 어플라이언스 페이지로 이동합니다.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#clusters
어플라이언스 이름을 마우스 오른쪽 버튼으로 클릭하고 메뉴에서 어플라이언스 구성을 선택합니다.
디스크를 기존 스냅샷 풀(확장)에 추가하거나 새 풀을 만들 수 있습니다(단, 동일한 풀에 영구 디스크 유형을 혼합하지 않음). 확장하는 경우 확장하려는 풀의 오른쪽 상단 아이콘을 클릭합니다.
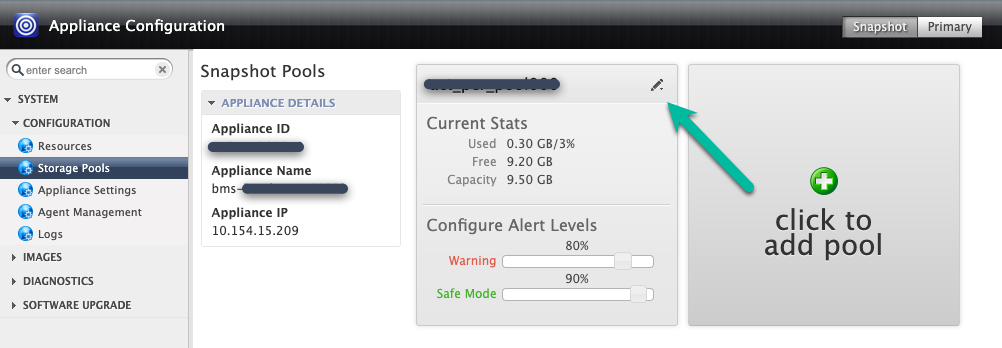
이 예시에서는 클릭하여 풀 추가 옵션을 사용하여 새 풀을 만듭니다. 이 버튼을 클릭한 후 20초 정도 기다리면 다음 페이지가 열립니다.
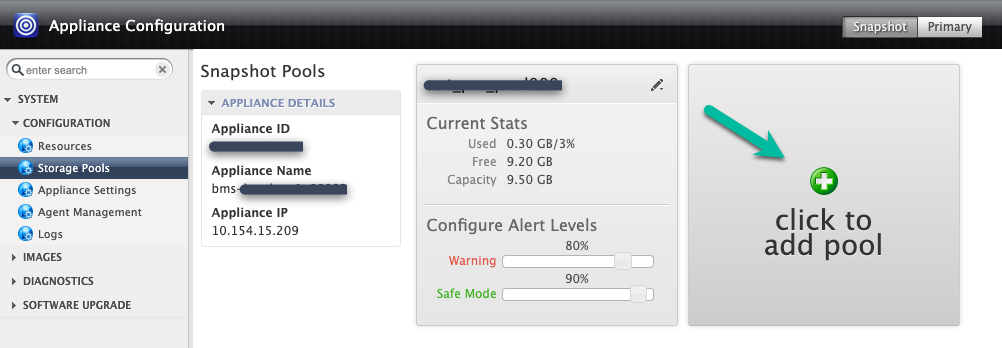
이 단계에서는 새 풀을 구성합니다.
- 풀에 이름을 지정하고 녹색 + 아이콘을 클릭하여 풀에 디스크를 추가합니다.
- 제출을 클릭합니다.
- 메시지가 표시되면 대문자로 PROCEED를 입력하여 계속 진행할지 확인합니다.
확인을 클릭합니다.
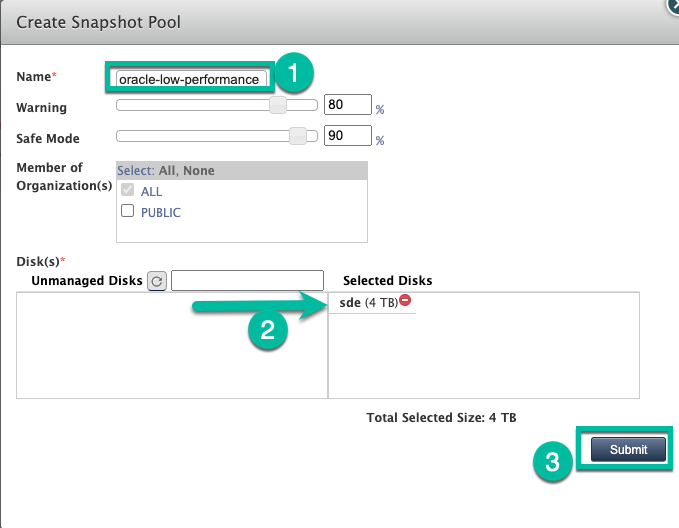
이제 풀이 영구 디스크로 확장되거나 생성됩니다.
백업 계획 구성
백업 계획을 사용하면 데이터베이스, VM 또는 파일 시스템을 백업하는 데 필요한 두 가지 주요 요소를 구성할 수 있습니다. 백업 계획에는 프로필과 템플릿이 통합됩니다.
- 프로필을 사용하면 백업 시기와 백업 데이터 보관 기간을 정의할 수 있습니다.
- 템플릿은 백업 태스크에 사용할 백업/복구 어플라이언스 및 스토리지 풀(영구 디스크, Cloud Storage 등)을 결정할 수 있게 해주는 구성 항목을 제공합니다.
프로필 만들기
백업 및 DR 관리 콘솔에서 백업 계획 > 프로필 페이지로 이동합니다.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#manageprofiles
이미 두 개의 프로필이 생성됩니다. Compute Engine VM 스냅샷에 하나의 프로필을 사용하고 다른 프로필을 수정하여 베어메탈 솔루션 백업에 사용할 수 있습니다. 프로필은 여러 개를 가질 수 있으며, 이는 백업에 서로 다른 디스크 등급이 필요한 여러 데이터베이스를 백업하는 경우에 유용합니다. 예를 들어 SSD에 대한 풀(고성능)을 하나 만들고 표준 영구 디스크(표준 성능)에 대한 풀을 만들 수 있습니다. 프로필마다 다른 스냅샷 풀을 선택할 수 있습니다.
이름이 LocalProfile인 기본 프로필을 마우스 오른쪽 버튼으로 클릭하고 LocalProfile을 선택합니다.
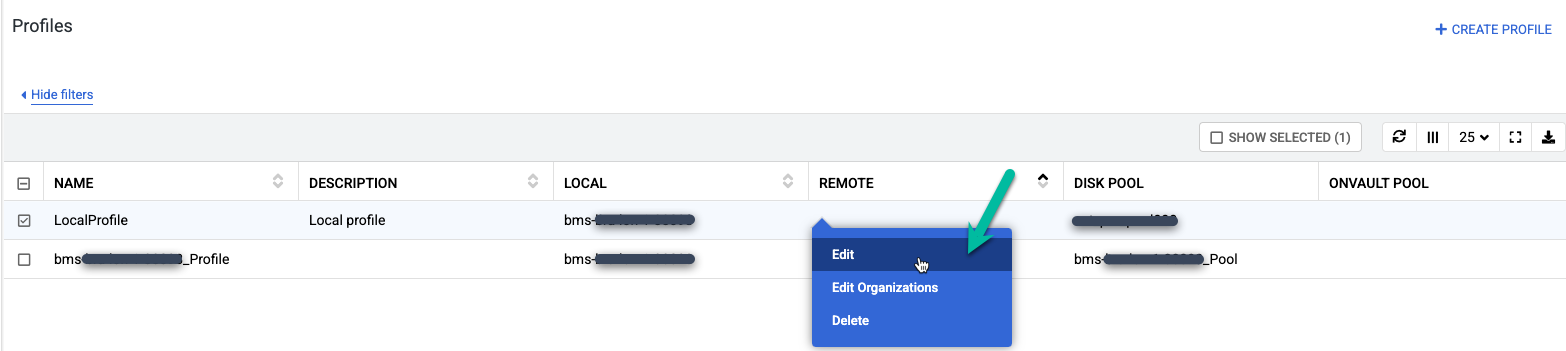
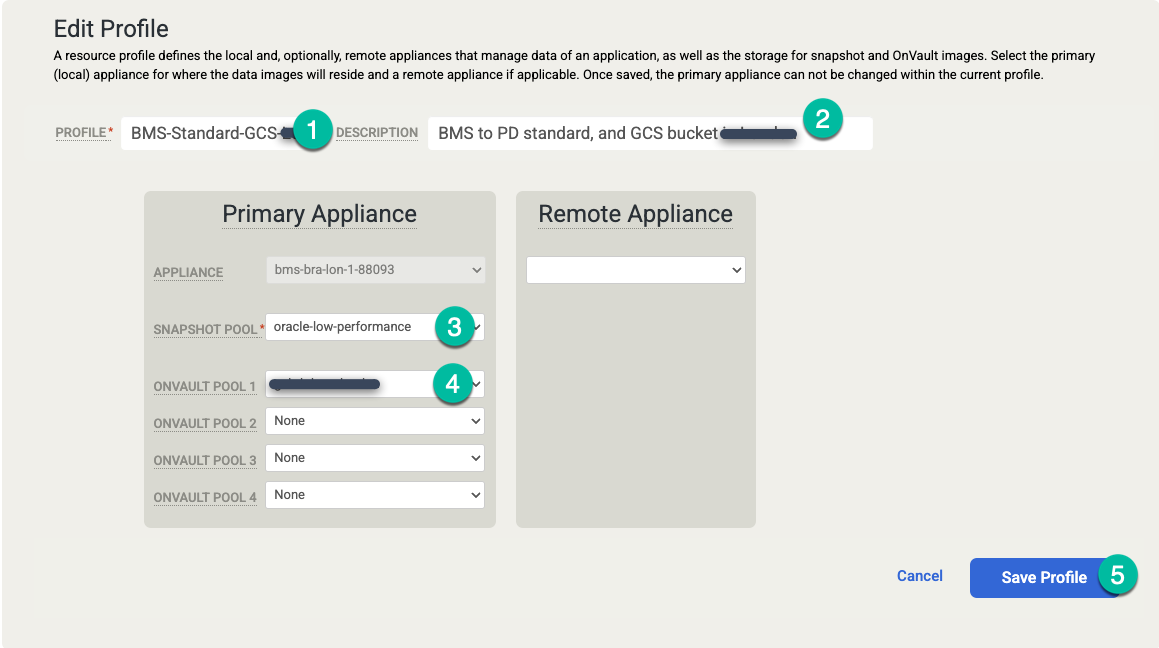
다음과 같이 변경하세요.
- 더 의미 있는 프로필 이름과 설명으로 프로필 설정을 업데이트합니다. 사용할 디스크 등급, Cloud Storage 버킷 위치 또는 이 프로필의 목적을 설명하는 기타 정보를 지정할 수 있습니다.
- 스냅샷 풀을 이전에 만든 확장된 풀 또는 새 풀로 변경합니다.
- 이 프로필의 OnVault 풀(Cloud Storage 버킷)을 선택합니다.
프로필 저장을 클릭합니다.
템플릿 만들기
백업 및 DR 관리 콘솔에서 백업 계획 > 템플릿 메뉴로 이동합니다.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#managetemplates
+템플릿 만들기를 클릭합니다.
- 템플릿 이름을 지정합니다.
- 정책 설정에서 재정의 허용에 대해 예를 선택합니다.
- 이 템플릿에 대한 설명을 추가합니다.
템플릿 저장을 클릭합니다.
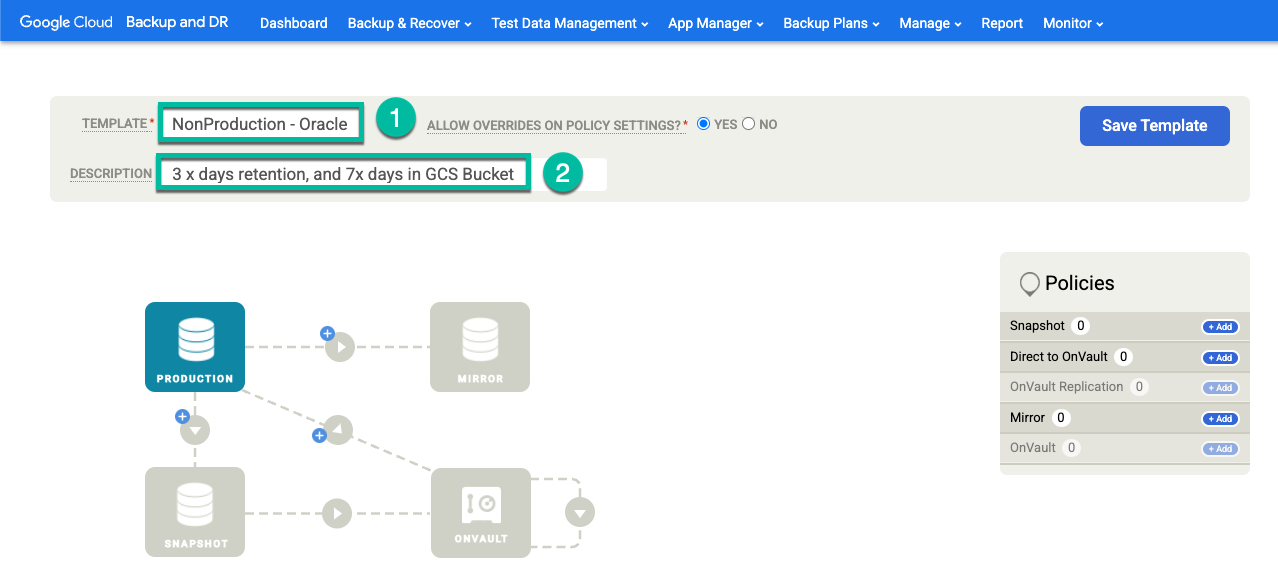
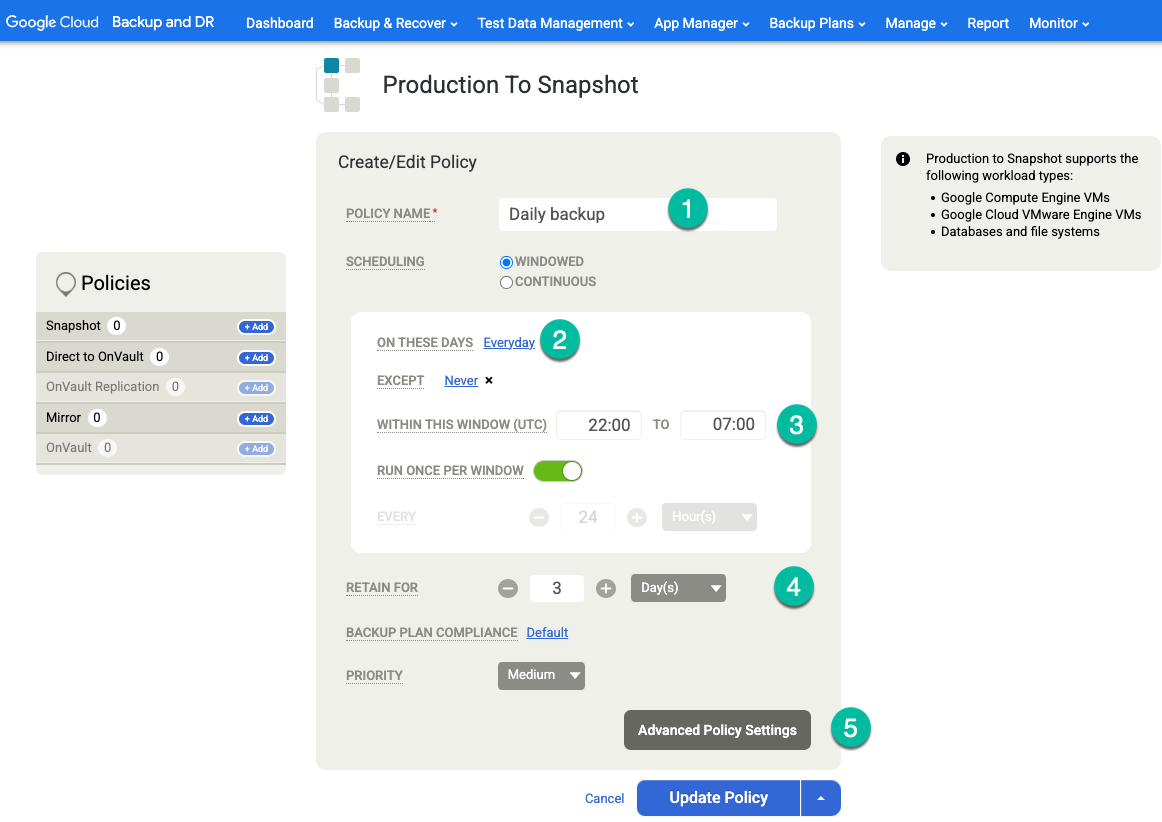
템플릿에서 다음을 구성합니다.
- 오른쪽의 정책 섹션에서 +추가를 클릭합니다.
- 정책 이름을 입력합니다.
- 정책을 실행할 요일의 체크박스를 선택하거나 기본값을 매일로 유지합니다.
- 이 기간 내에 실행할 작업의 창을 수정합니다.
- 보관 기간을 선택합니다.
고급 정책 설정을 클릭합니다.
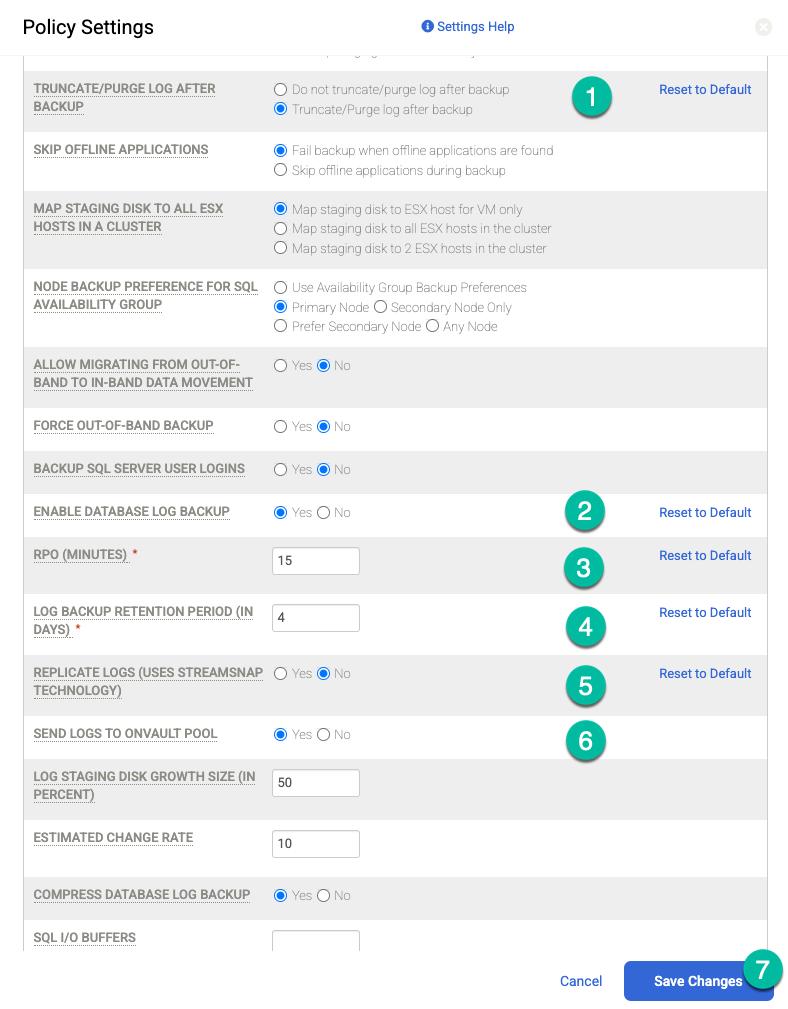
정기적으로(예: 15분마다) 보관처리 로그 백업을 수행하고 보관처리 로그를 Cloud Storage에 복제하려면 다음 정책 설정을 사용 설정해야 합니다.
- 원하는 경우 백업 후 로그 잘라내기/삭제를 잘라내기로 설정합니다.
- 원하는 경우 데이터베이스 로그 백업 사용 설정을 예로 설정합니다.
- RPO(분)를 원하는 보관처리 로그 백업 간격으로 설정합니다.
- 로그 백업 보관 기간(일)을 원하는 보관 기간으로 설정합니다.
- 로그 복제(Streamsnap 기술 사용)를 아니요로 설정합니다.
- 로그를 Cloud Storage 버킷으로 전송하려면 OnVault 풀에 로그 전송을 예로 설정합니다. 그렇지 않으면 아니요를 선택합니다.
변경사항 저장을 클릭합니다.
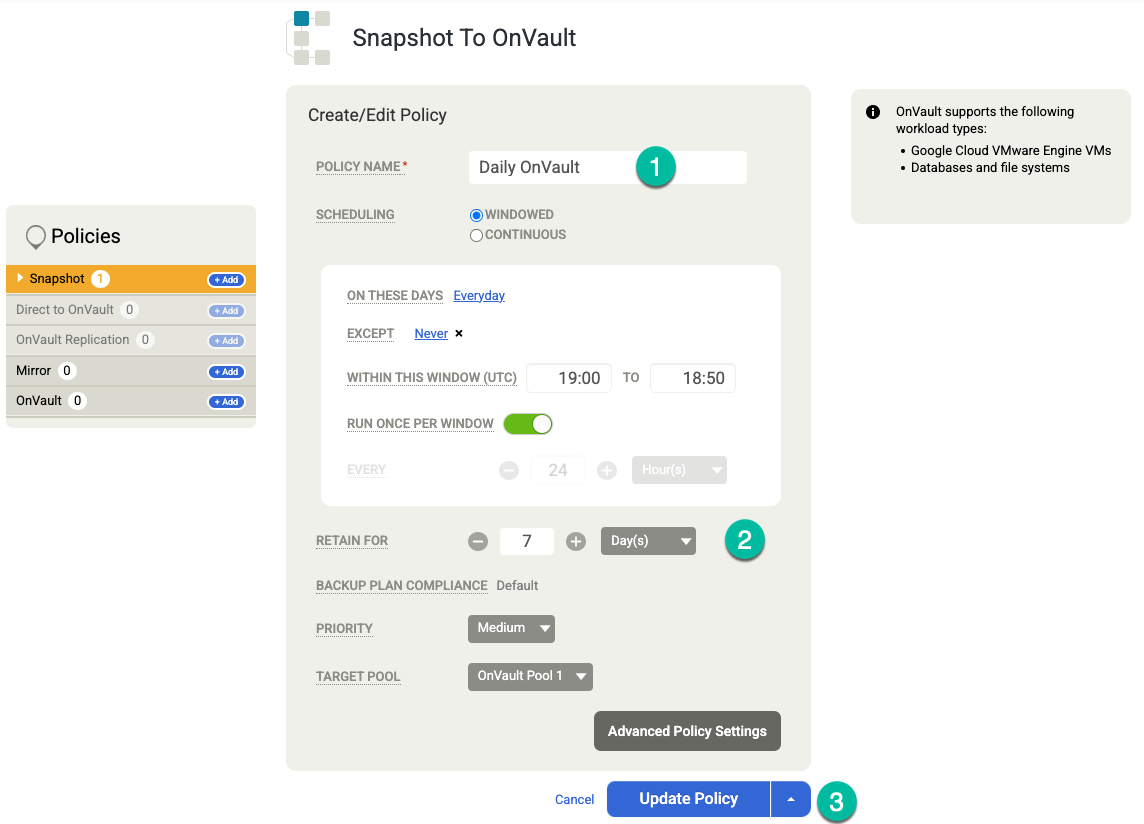
정책 업데이트를 클릭하여 변경사항을 저장합니다.
오른쪽의 OnVault에 대해 다음 작업을 실행합니다.
- +추가를 클릭합니다.
- 정책 이름을 추가합니다.
- 보관 기간을 일, 주, 월 또는 년으로 설정합니다.
정책 업데이트를 클릭합니다.
(선택사항) 보관 옵션을 더 추가해야 하는 경우 주간, 월간, 연간 보관에 대한 추가 정책을 만듭니다. 보관 정책을 추가하려면 다음 단계를 따르세요.
- 오른쪽의 OnVault에 대해 +추가를 클릭합니다.
- 정책 이름을 추가합니다.
- 해당 날짜의 값을 이 작업을 트리거할 날짜로 변경합니다.
- 보관 기간을 일, 주, 월 또는 년으로 설정합니다.
정책 업데이트를 클릭합니다.
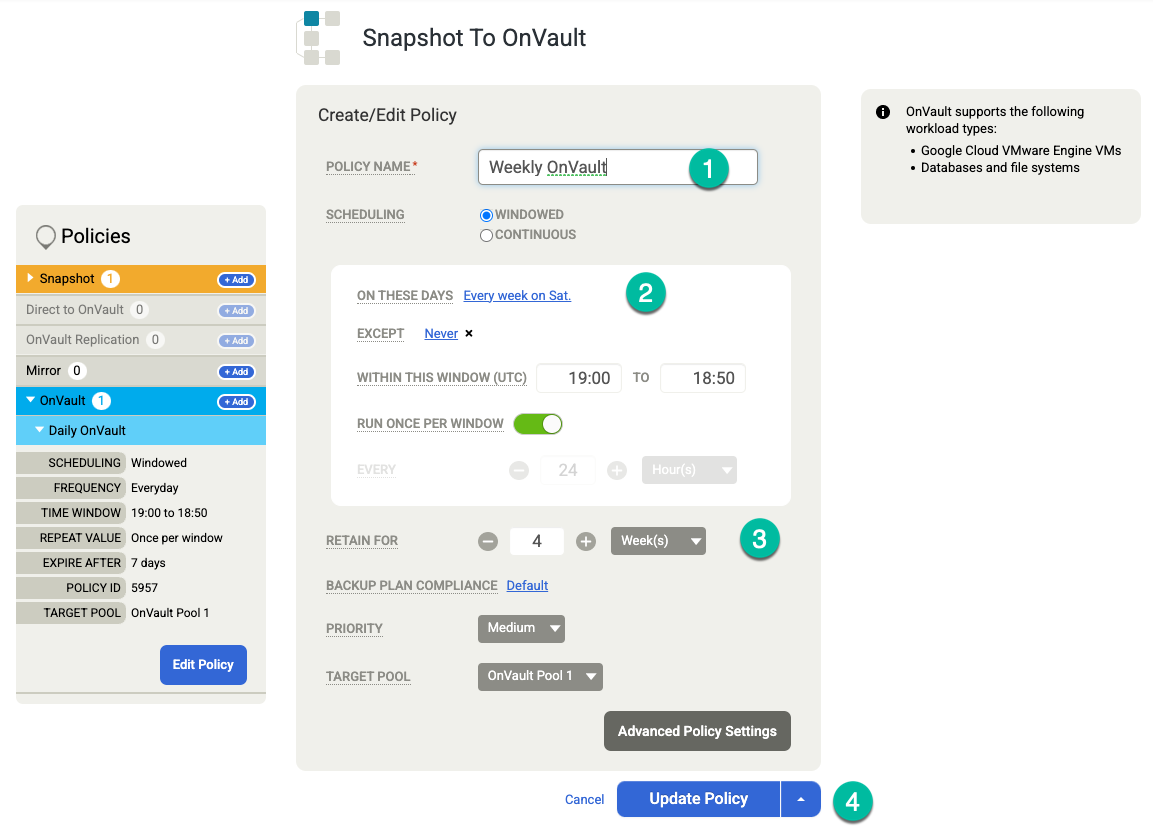
템플릿 저장을 클릭합니다. 다음 예시에서는 영구 디스크 계층에서 3일, OnVault 작업의 경우 7일, 총 4주 동안 백업을 보관하는 스냅샷 정책을 확인할 수 있습니다. 주간 백업은 토요일 밤에 실행됩니다.
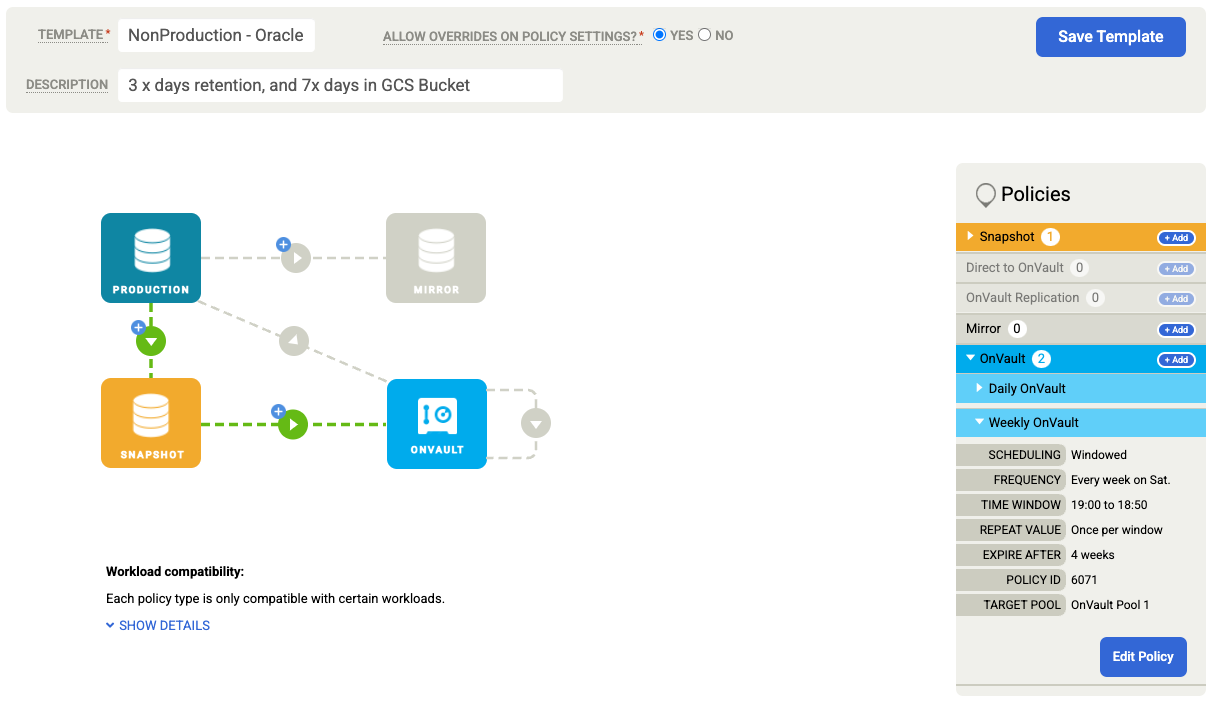
Oracle 데이터베이스 백업
Google Cloud 백업 및 DR 아키텍처는 Google Cloud에 애플리케이션 일관성이 있는 영구 증분 Oracle 백업과 테라바이트 단위의 Oracle 데이터베이스를 위한 즉각적인 복구 및 클론을 제공합니다.
Google Cloud 백업 및 DR은 다음 Oracle API를 사용합니다.
- RMAN 이미지 복사 API: 데이터 파일의 이미지 사본은 데이터 파일의 물리적 구조가 이미 존재하므로 복원 속도가 훨씬 빠릅니다. Recovery Manager(RMAN) 지시문 BACKUP AS COPY는 전체 데이터베이스의 모든 데이터 파일에 대한 이미지 사본을 만들고 데이터 파일 형식을 보관합니다.
- ASM 및 CRS API: 자동 스토리지 관리(ASM) 및 클러스터 준비 서비스(CRS) API를 사용하여 ASM 백업 디스크 그룹을 관리합니다.
- RMAN 아카이브 로그 백업 API – 이 API는 아카이브 로그를 생성하고 스테이징 디스크에 백업한 후 프로덕션 아카이브 위치에서 삭제합니다.
Oracle 호스트 구성
Oracle 호스트를 설정하는 단계에는 에이전트 설치, 백업 및 DR에 호스트 추가, 호스트 구성, Oracle 데이터베이스 검색이 포함됩니다. 모든 설정이 완료되면 백업 및 DR에 Oracle 데이터베이스를 백업할 수 있습니다.
백업 에이전트 설치
백업 및 DR 에이전트 설치는 비교적 간단합니다. 호스트를 처음 사용할 때만 에이전트를 설치하면 Google Cloud 콘솔의 백업 및 DR 사용자 인터페이스 내에서 이후 업그레이드를 수행할 수 있습니다. 상담사 설치를 실행하려면 루트 사용자로 로그인하거나 sudo 인증 세션에 있어야 합니다. 설치를 완료하기 위해 호스트를 재부팅하지 않아도 됩니다.
사용자 인터페이스에서 또는 관리 > 어플라이언스 페이지를 통해 백업 에이전트를 다운로드합니다.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#clusters
백업/복구 어플라이언스 이름을 마우스 오른쪽 버튼으로 클릭하고 어플라이언스 구성을 선택합니다. 새 브라우저 창이 열립니다.
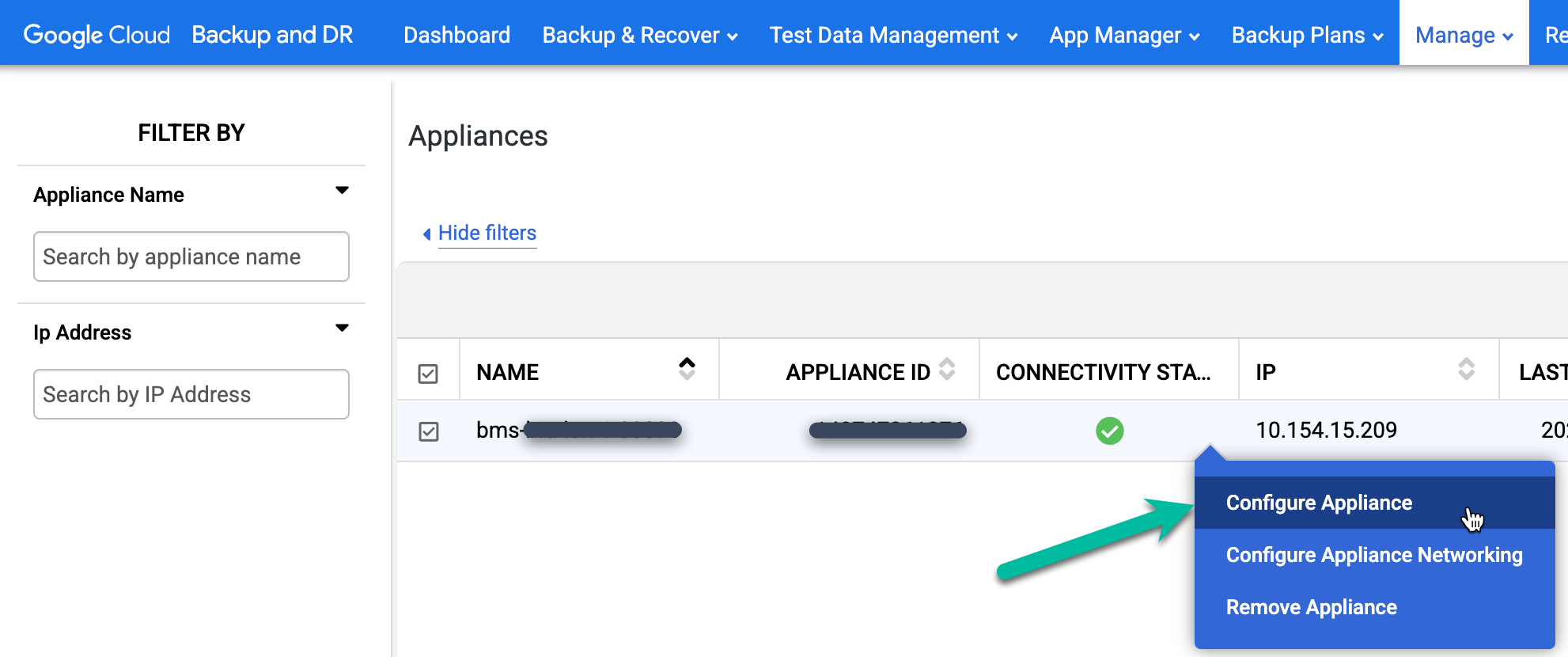
Linux 64비트 아이콘을 클릭하여 브라우저 세션을 호스팅하는 컴퓨터에 백업 에이전트를 다운로드합니다. scp(보안 복사)를 사용하여 다운로드된 에이전트 파일을 설치를 위해 Oracle 호스트로 이동합니다.
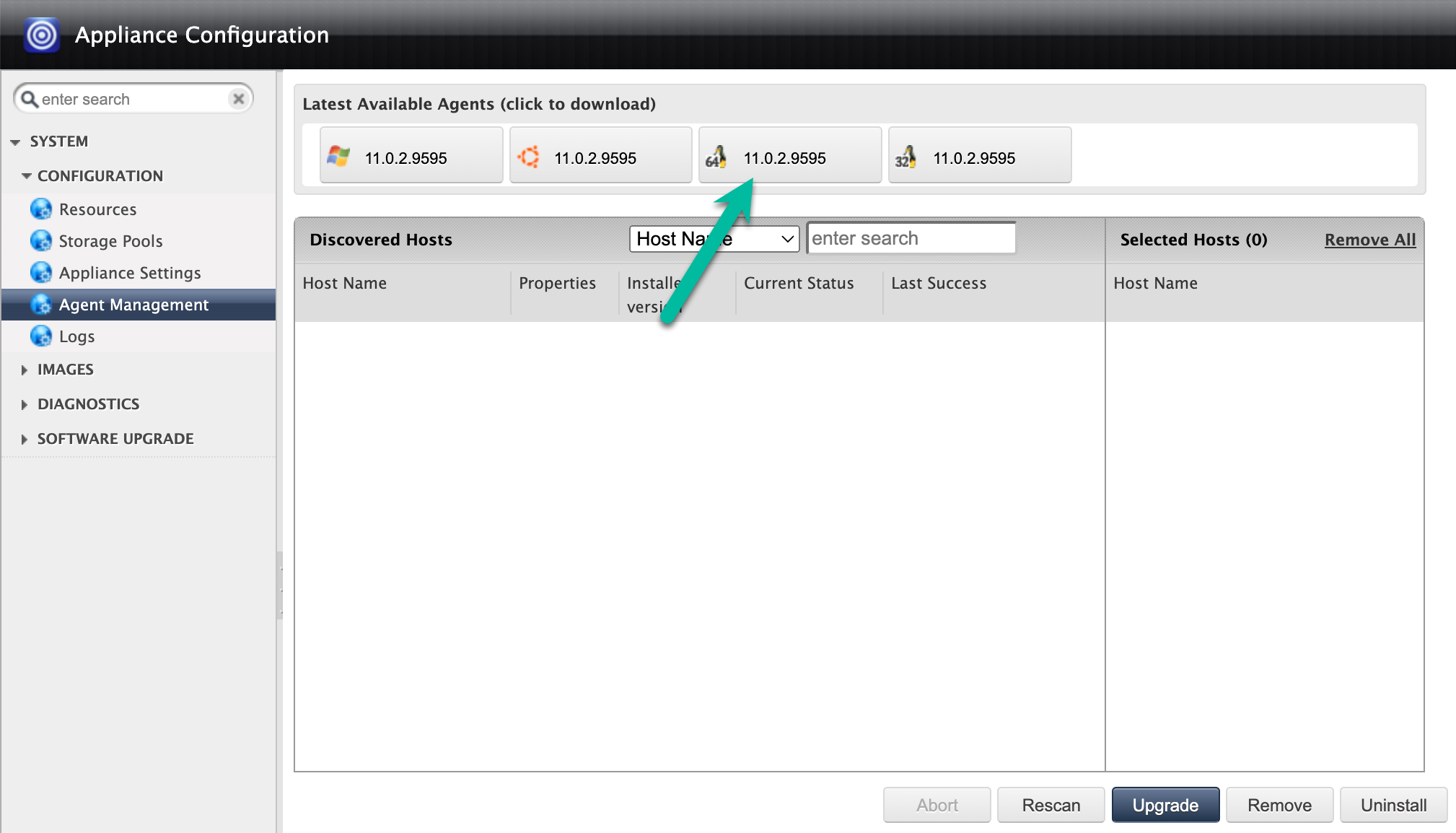
또는 Cloud Storage 버킷에 백업 에이전트를 저장하고 다운로드를 사용 설정하고
wget또는curl명령어를 사용하여 Linux 호스트에 직접 에이전트를 다운로드할 수 있습니다.curl -o agent-Linux-latestversion.rpm https://storage.googleapis.com/backup-agent-images/connector-Linux-11.0.2.9595.rpm
rpm -ivh명령어를 사용하여 백업 에이전트를 설치합니다.자동으로 생성된 비밀 키를 복사하는 것이 매우 중요합니다. 백업 및 DR 관리 콘솔을 사용하여 호스트 메타데이터에 보안 비밀 키를 추가해야 합니다.
이 명령어 출력은 다음과 비슷합니다.
[oracle@host `~]# sudo rpm -ivh agent-Linux-latestversion.rpm Verifying... ################################# [100%] Preparing... ################################# [100%] Updating / installing… 1:udsagent-11.0.2-9595 ################################# [100%] Created symlink /etc/systemd/system/multi-user.target.wants/udsagent.service → /usr/lib/systemd/system/udsagent.service. Action Required: -- Add this host to Backup and DR management console to backup/recover workloads from/to this host. You can do this by navigating to Manage->Hosts->Add Host on your management console. -- A secret key is required to complete this process. Please use b010502a8f383cae5a076d4ac9e868777657cebd0000000063abee83 (valid for 2 hrs) to register this host. -- A new secret key can be generated later by running: '/opt/act/bin/udsagent secret --reset --restart
iptables명령어를 사용하는 경우 백업 에이전트 방화벽(TCP 5106) 및 Oracle 서비스(TCP 1521)의 포트를 엽니다.sudo iptables -A INPUT -p tcp --dport 5106 -j ACCEPT sudo iptables -A INPUT -p tcp --dport 1521 -j ACCEPT sudo firewall-cmd --permanent --add-port=5106/tcp sudo firewall-cmd --permanent --add-port=1521/tcp sudo firewall-cmd --reload
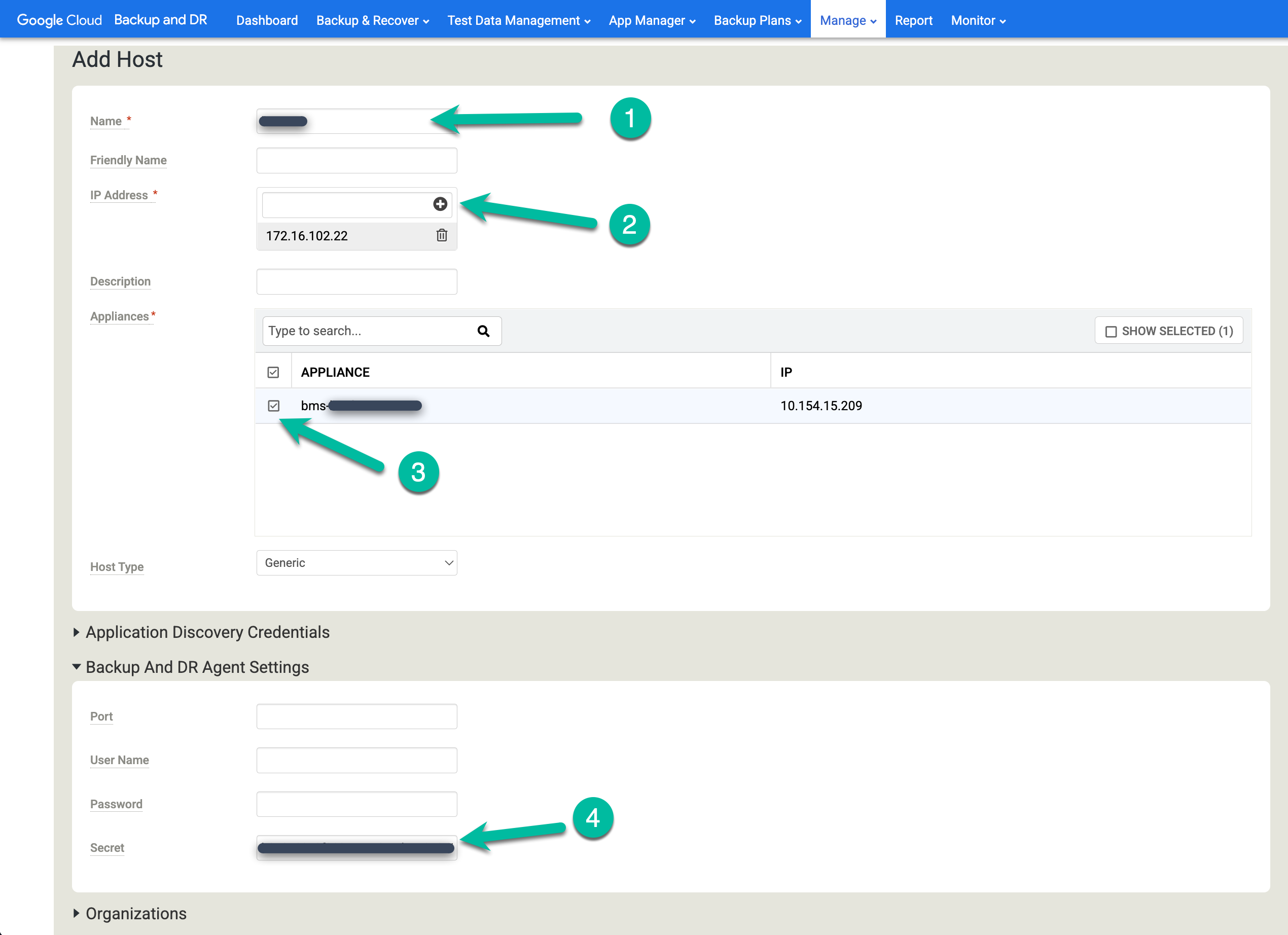
백업 및 DR에 호스트 추가
백업 및 DR 관리 콘솔에서 관리 > 호스트로 이동합니다.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#hosts
- +호스트 추가를 클릭합니다.
- 호스트 이름을 추가합니다.
- 호스트의 IP 주소를 추가하고 + 버튼을 클릭하여 구성을 확인합니다.
- 호스트를 추가할 어플라이언스를 클릭합니다.
- 비밀 키를 붙여넣습니다. 백업 에이전트를 설치하고 보안 비밀 키가 생성된 후 2시간 이내에 이 작업을 수행해야 합니다.
추가를 클릭하여 호스트를 저장합니다.
오류 또는 일부 성공 메시지가 표시되면 다음 해결 방법을 시도해 보세요.
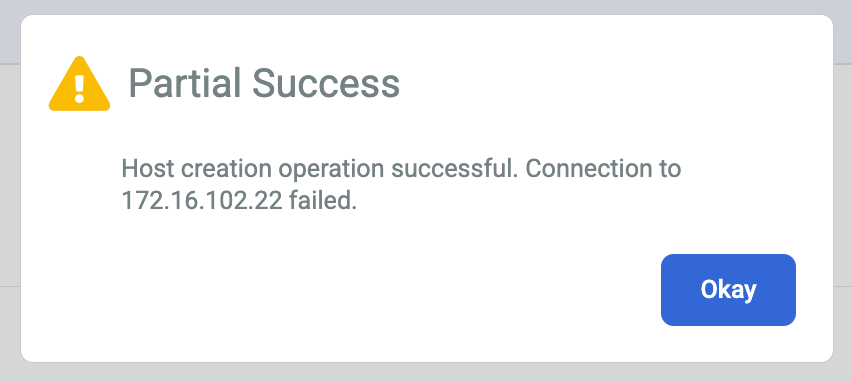
백업 에이전트 암호화 비밀 키의 시간 제한이 지난 것일 수 있습니다. 보안 비밀 키를 만든 후 2시간 이내에 호스트에 추가하지 않은 경우 다음 명령줄 구문을 사용하여 Linux 호스트에서 새 보안 비밀 키를 생성할 수 있습니다.
/opt/act/bin/udsagent secret --reset --restart
백업/복구 어플라이언스와 호스트에 설치된 에이전트 간의 통신을 허용하는 방화벽이 올바르게 구성되지 않았을 수 있습니다. 백업 에이전트 방화벽 및 Oracle 서비스용 포트를 열려면 단계를 수행합니다.
Linux 호스트의 네트워크 시간 프로토콜(ntp) 구성이 잘못 구성되었을 수 있습니다. NTP 설정이 올바른지 확인합니다.
근본 원인을 해결하면 인증서 상태가 해당 사항 없음에서 유효함으로 변경됩니다.

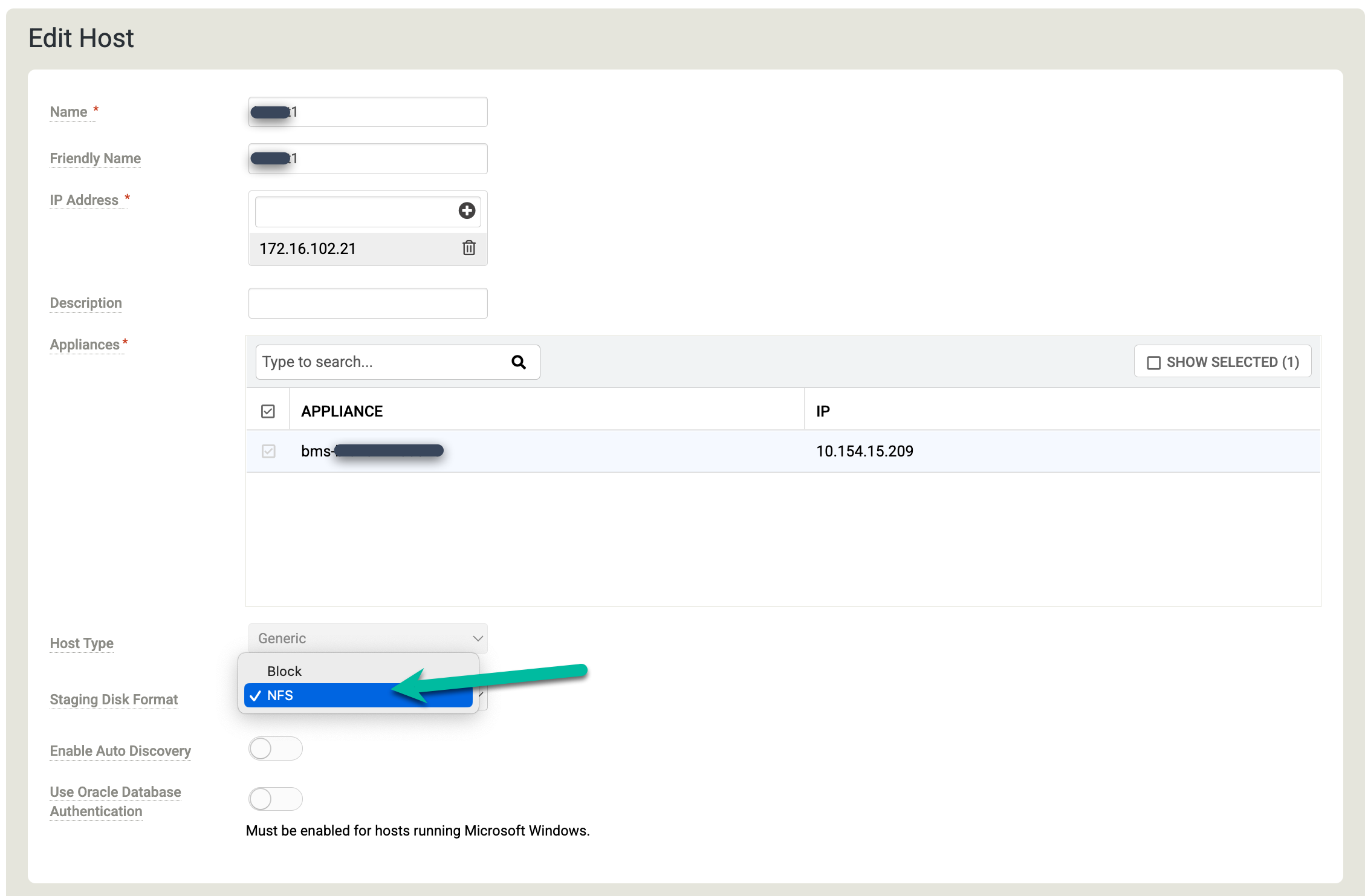
호스트 구성
백업 및 DR 관리 콘솔에서 관리 > 호스트로 이동합니다.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#hosts
Oracle 데이터베이스를 백업할 Linux 호스트를 마우스 오른쪽 버튼으로 클릭하고 수정을 선택합니다.
스테이징 디스크 형식을 클릭하고 NFS를 선택합니다.
감지된 애플리케이션 섹션까지 아래로 스크롤하고 애플리케이션 탐색을 클릭하여 어플라이언스-에이전트 탐색 프로세스를 시작합니다.
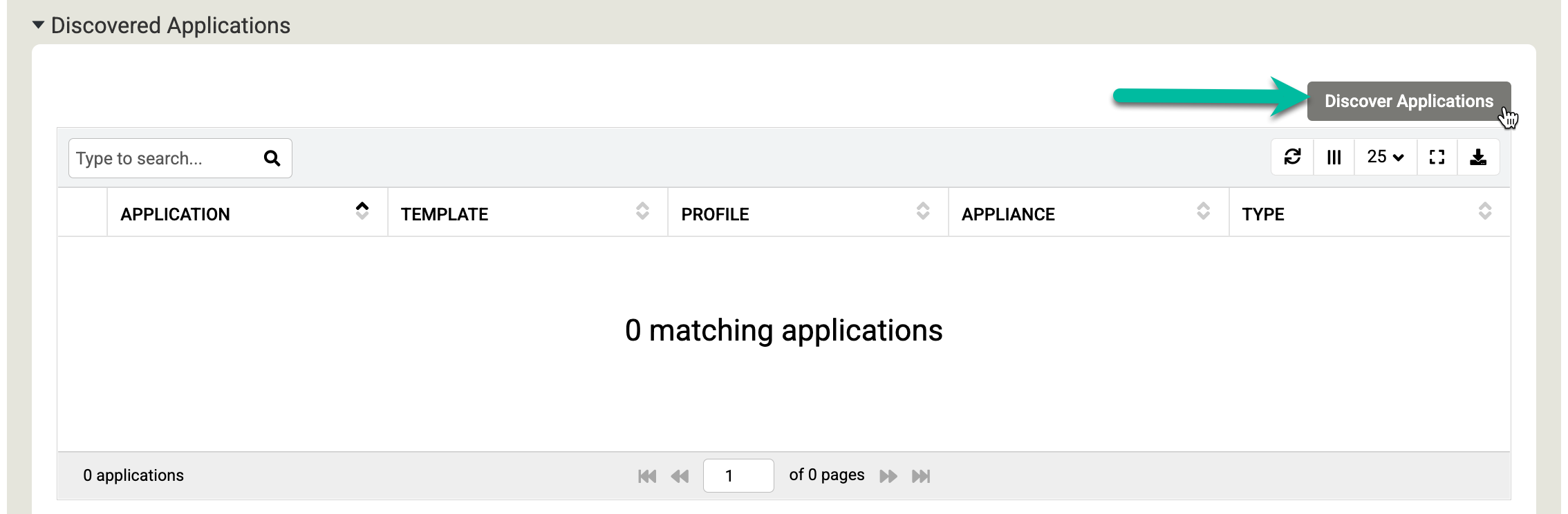
탐색을 클릭하여 프로세스를 시작합니다. 탐색 프로세스는 최대 5분이 걸립니다. 완료되면 발견된 파일 시스템과 Oracle 데이터베이스가 애플리케이션 창에 표시됩니다.
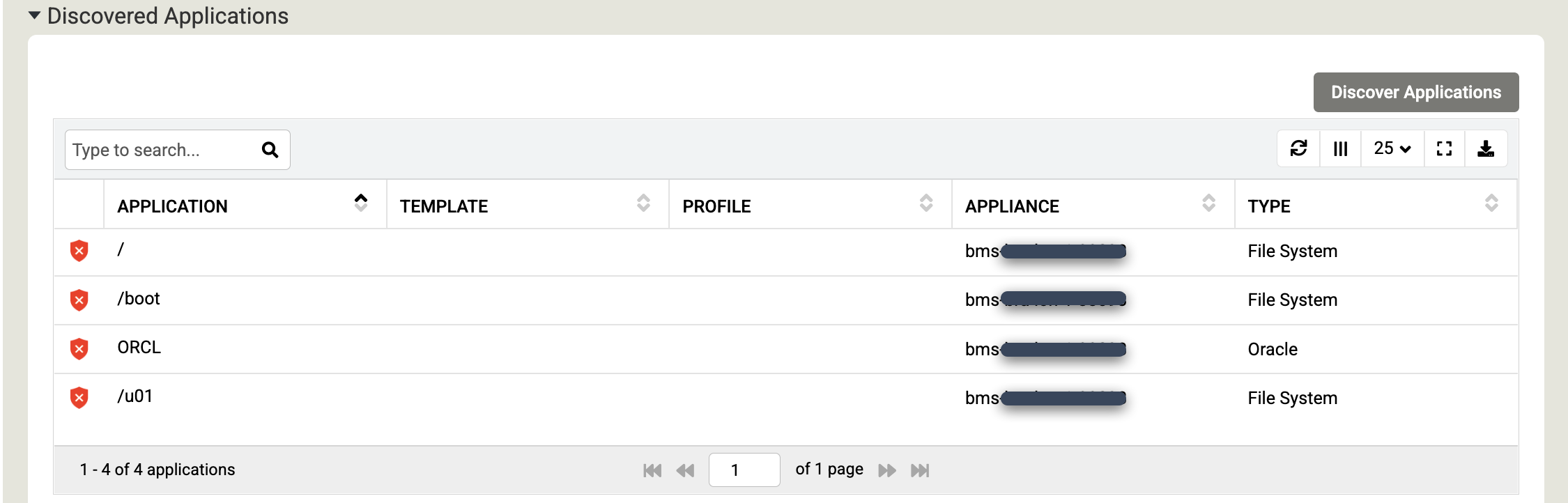
저장을 클릭하여 호스트의 변경사항을 업데이트합니다.
Linux 호스트 준비
Linux OS 기반 호스트에 iSCSI 또는 NFS 유틸리티 패키지를 설치하면 스테이징 디스크를 백업 데이터를 쓰는 기기에 매핑할 수 있습니다. 다음 명령어를 사용하여 iSCSI 및 NFS 유틸리티를 설치합니다. 유틸리티 세트 중 하나를 또는 둘 모두를 사용할 수 있지만, 이 단계에서는 필요할 때 필요한 것을 바로 사용할 수 있습니다.
iSCSI 유틸리티를 설치하려면 다음 명령어를 실행합니다.
sudo yum install -y iscsi-initiator-utils
NFS 유틸리티를 설치하려면 다음 명령어를 실행합니다.
sudo yum install -y nfs-utils
Oracle 데이터베이스 준비
이 가이드에서는 이미 Oracle 인스턴스 및 데이터베이스를 설정 및 구성했다고 가정합니다. Google Cloud 백업 및 DR은 파일 시스템, ASM, 실제 애플리케이션 클러스터(RAC), 기타 여러 구성에서 실행되는 데이터베이스 보호를 지원합니다. 자세한 내용은 Oracle 데이터베이스용 백업 및 DR을 참조하세요.
백업 작업을 시작하기 전에 몇 가지 항목을 구성해야 합니다. 이러한 태스크 중 일부는 선택사항이지만 최적의 성능을 위해 다음 설정을 사용하는 것이 좋습니다.
- SSH를 사용하여 Linux 호스트에 연결하고 su 권한이 있는 Oracle 사용자로 로그인합니다.
Oracle 환경을 특정 인스턴스로 설정합니다.
. oraenv ORACLE_SID = [ORCL] ? The Oracle base remains unchanged with value /u01/app/oracle
sysdba계정으로 SQL*Plus에 연결합니다.sqlplus / as sysdba
다음 명령어를 사용하여 ARCHIVELOG 모드를 사용 설정합니다. 명령어의 출력은 다음과 비슷합니다.
SQL> shutdown Database closed. Database dismounted. ORACLE instance shut down. SQL> startup mount ORACLE instance started. Total System Global Area 2415918600 bytes Fixed Size 9137672 bytes Variable Size 637534208 bytes Database Buffers 1761607680 bytes Redo Buffers 7639040 bytes Database mounted. SQL> alter database archivelog; Database altered. SQL> alter database open; Database altered. SQL> archive log list; Database log mode Archive Mode Automatic archival Enabled Archive destination /u01/app/oracle/product/19c/dbhome_1/dbs/arch Oldest online log sequence 20 Next log sequence to archive 22 Current log sequence 22 SQL> alter pluggable database ORCLPDB save state; Pluggable database altered.
Linux 호스트에 대해 Direct NFS를 구성합니다.
cd $ORACLE_HOME/rdbms/lib make -f [ins_rdbms.mk](http://ins_rdbms.mk/) dnfs_on
블록 변경 추적을 구성합니다. 먼저 사용 설정되어 있는지 또는 사용 중지되어 있는지 확인합니다. 다음 예시에서는 블록 변경 추적을 사용 중지로 보여줍니다.
SQL> select status,filename from v$block_change_tracking; STATUS FILENAME ---------- ------------------------------------------------------------------ DISABLED
SQL> alter database enable block change tracking using file +ASM_DISK_GROUP_NAME/DATABASE_NAME/DBNAME.bct; Database altered.
파일 시스템을 사용할 때 다음 명령어를 실행합니다.
SQL> alter database enable block change tracking using file '$ORACLE_HOME/dbs/DBNAME.bct';; Database altered.
이제 블록 변경 추적이 사용 설정되어 있는지 확인합니다.
SQL> select status,filename from v$block_change_tracking; STATUS FILENAME ---------- ------------------------------------------------------------------ ENABLED +DATADG/ORCL/CHANGETRACKING/ctf.276.1124639617
Oracle 데이터베이스 보호
백업 및 DR 관리 콘솔에서 앱 관리자 > 애플리케이션 페이지로 이동합니다.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#applications
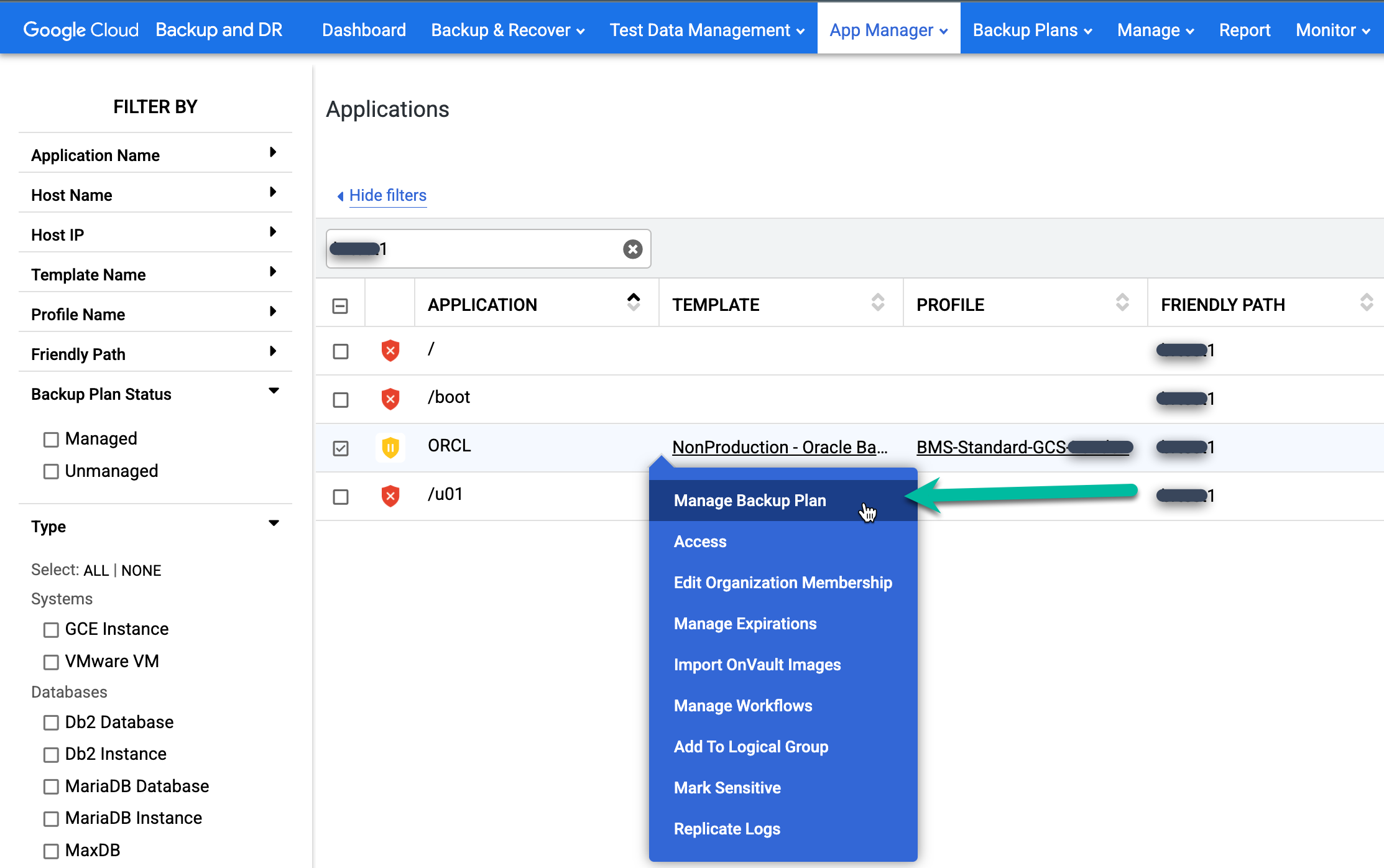
보호하려는 Oracle 데이터베이스 이름을 마우스 오른쪽 버튼으로 클릭하고 메뉴에서 백업 계획 관리를 선택합니다.
사용할 템플릿과 프로필을 선택한 후 백업 계획 적용을 클릭합니다.
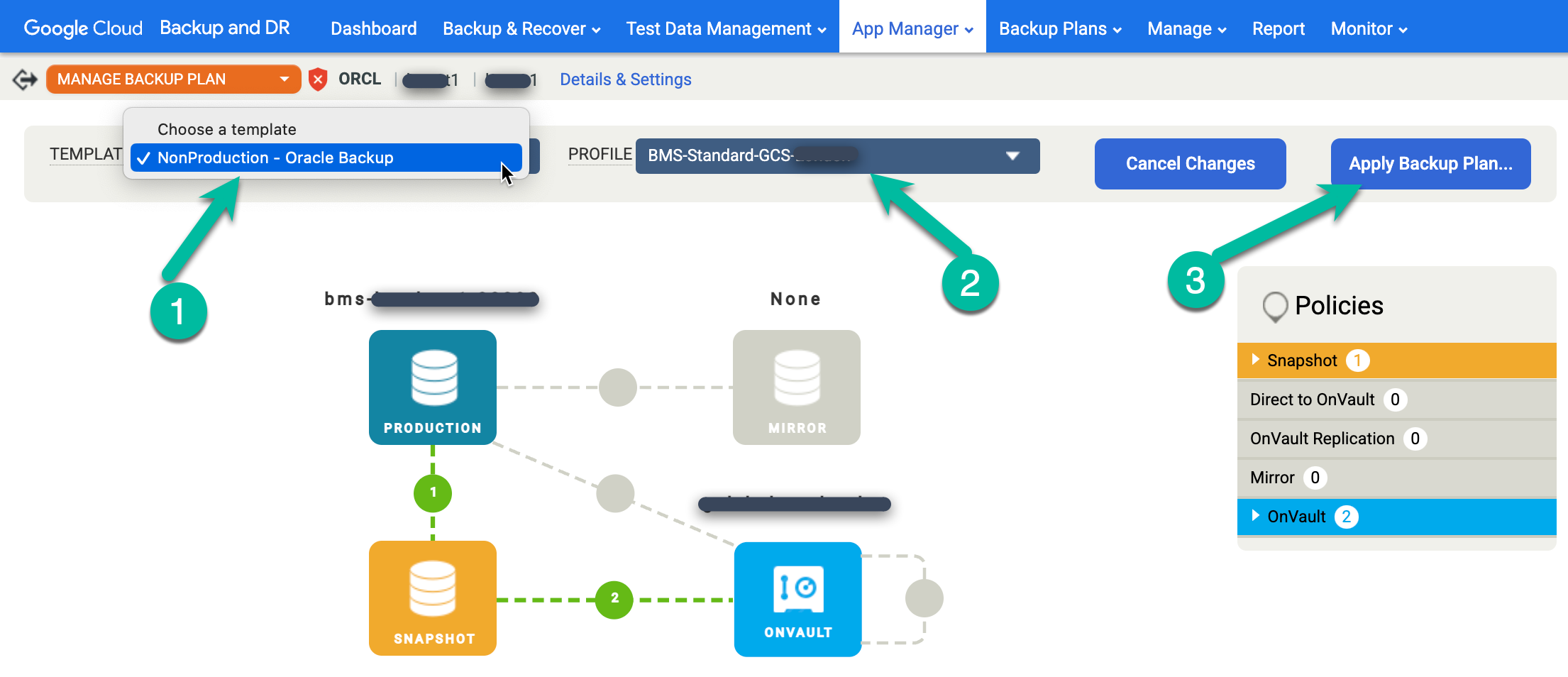
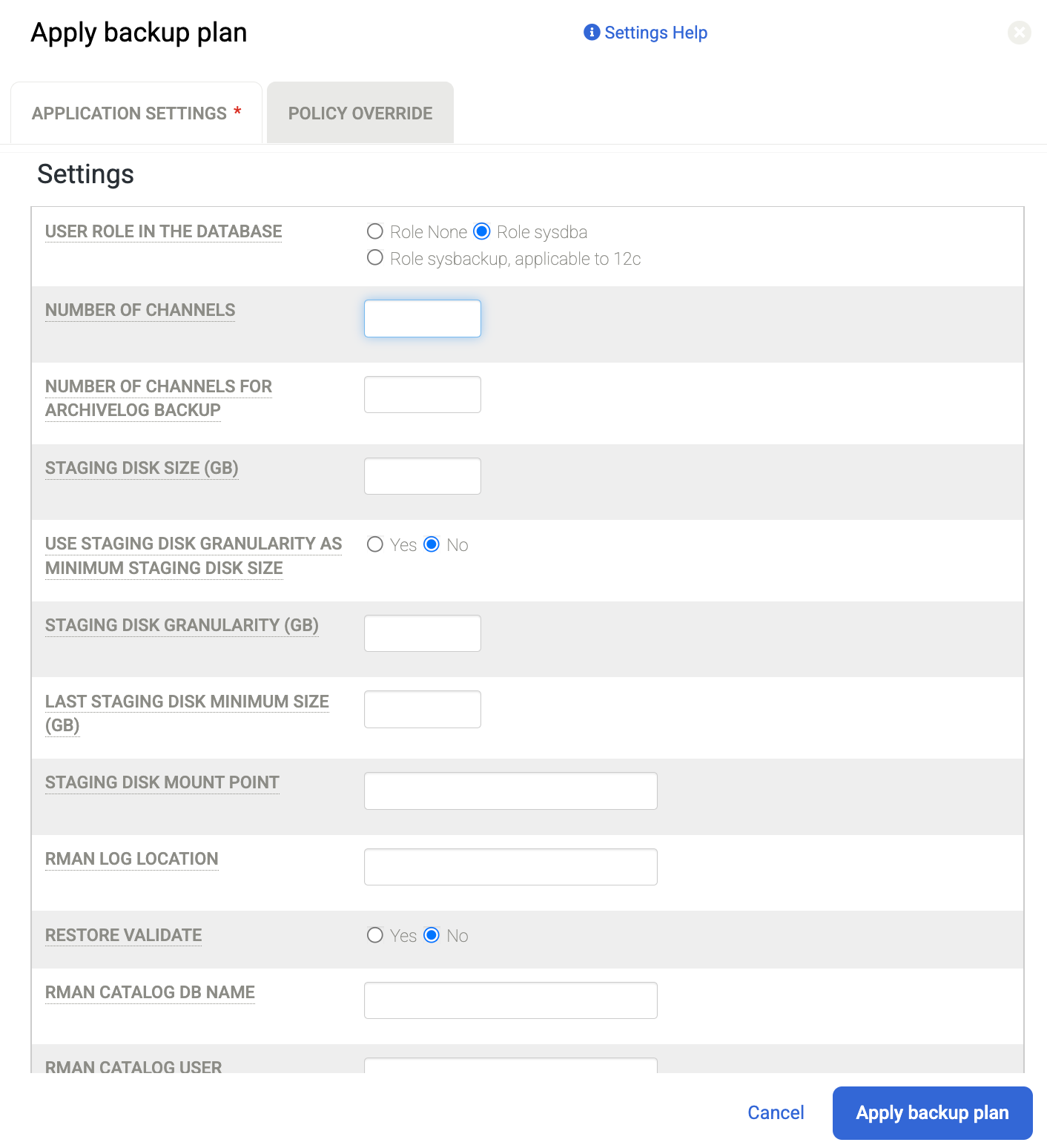
메시지가 표시되면 구성에 필요한 Oracle 및 RMAN 관련 고급 설정을 설정합니다. 완료되면 백업 계획 적용을 클릭합니다.
채널 수: 예를 들어 기본값은 2입니다. 따라서 CPU 코어 수가 더 많은 경우 동시 백업 작업을 위한 채널 수를 늘리고 이를 더 큰 숫자로 설정할 수 있습니다.
고급 설정에 대한 자세한 내용은 Oracle 데이터베이스용 애플리케이션 세부정보 및 설정 구성을 참조하세요.
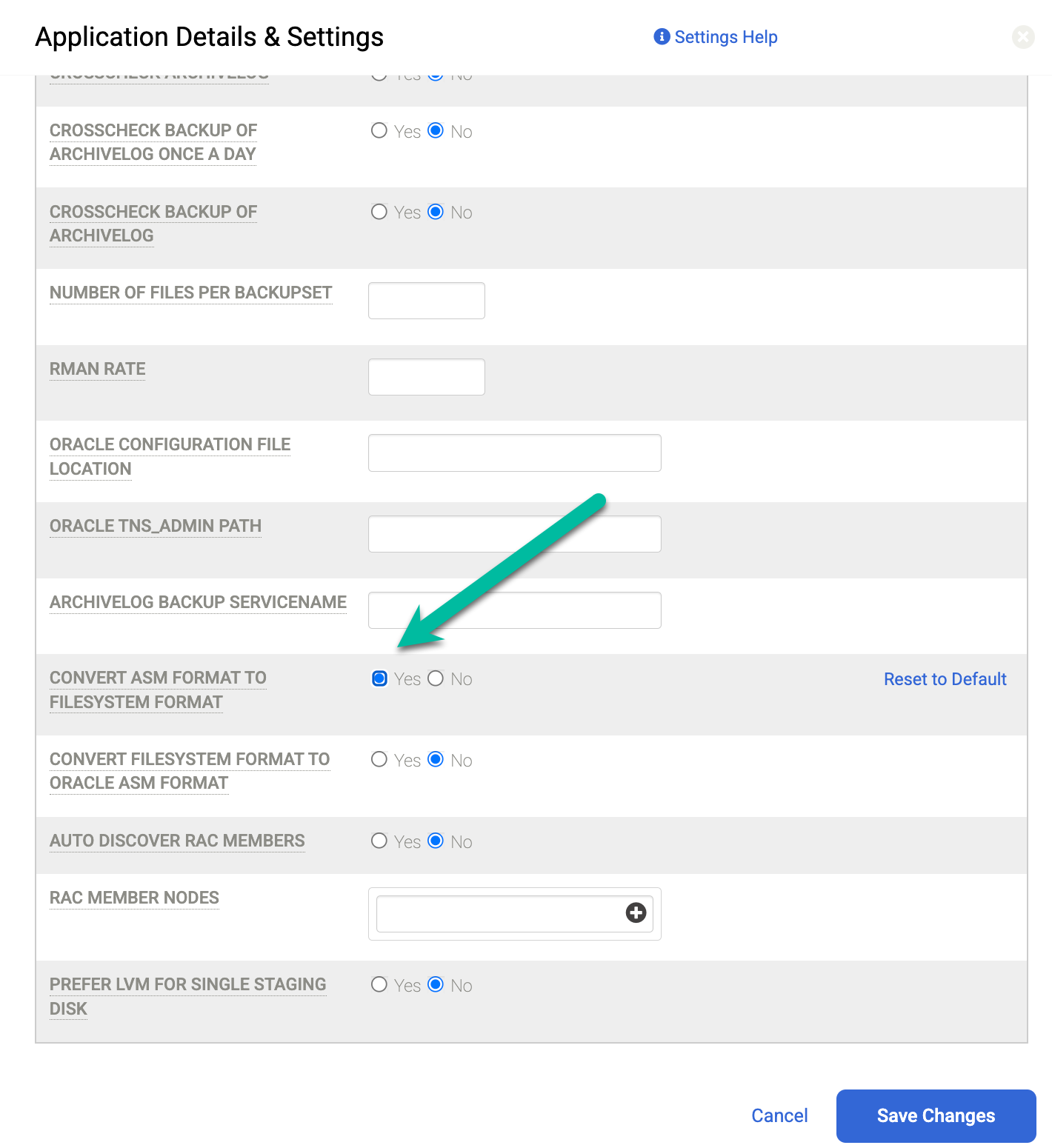
이러한 설정 외에도 스테이징 디스크가 백업 어플라이언스에서 호스트로 디스크를 매핑하는 데 사용하는 프로토콜을 변경할 수 있습니다. 관리 > 호스트 페이지로 이동하여 수정할 호스트를 선택합니다. 디스크 형식을 게스트에 스테이징 옵션을 선택합니다. 기본적으로 블록 형식이 선택되어 iSCSI를 통해 스테이징 디스크를 매핑합니다. 그렇지 않으면 NFS로 변경할 수 있으며 스테이징 디스크는 NFS 프로토콜을 대신 사용합니다.
기본 설정은 데이터베이스 형식에 따라 다릅니다. ASM을 사용하는 경우 시스템은 iSCSI를 사용하여 백업을 ASM 디스크 그룹으로 전송합니다. 파일 시스템을 사용하는 경우 시스템은 iSCSI를 사용하여 백업을 파일 시스템으로 보냅니다. NFS 또는 Direct NFS(dNFS)를 사용하려면 스테이징 디스크의 호스트 설정을 NFS로 변경해야 합니다. 대신 기본 설정을 사용하면 모든 백업 스테이징 디스크에서 블록 스토리지 형식과 iSCSI를 사용합니다.
백업 작업 시작
백업 및 DR 관리 콘솔에서 앱 관리자 > 애플리케이션 페이지로 이동합니다.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#applications
보호하려는 Oracle 데이터베이스를 마우스 오른쪽 버튼으로 클릭하고 메뉴에서 백업 계획 관리를 선택합니다.
오른쪽의 스냅샷 메뉴를 클릭하고 지금 실행을 클릭합니다. 그러면 주문형 백업 작업이 시작됩니다.
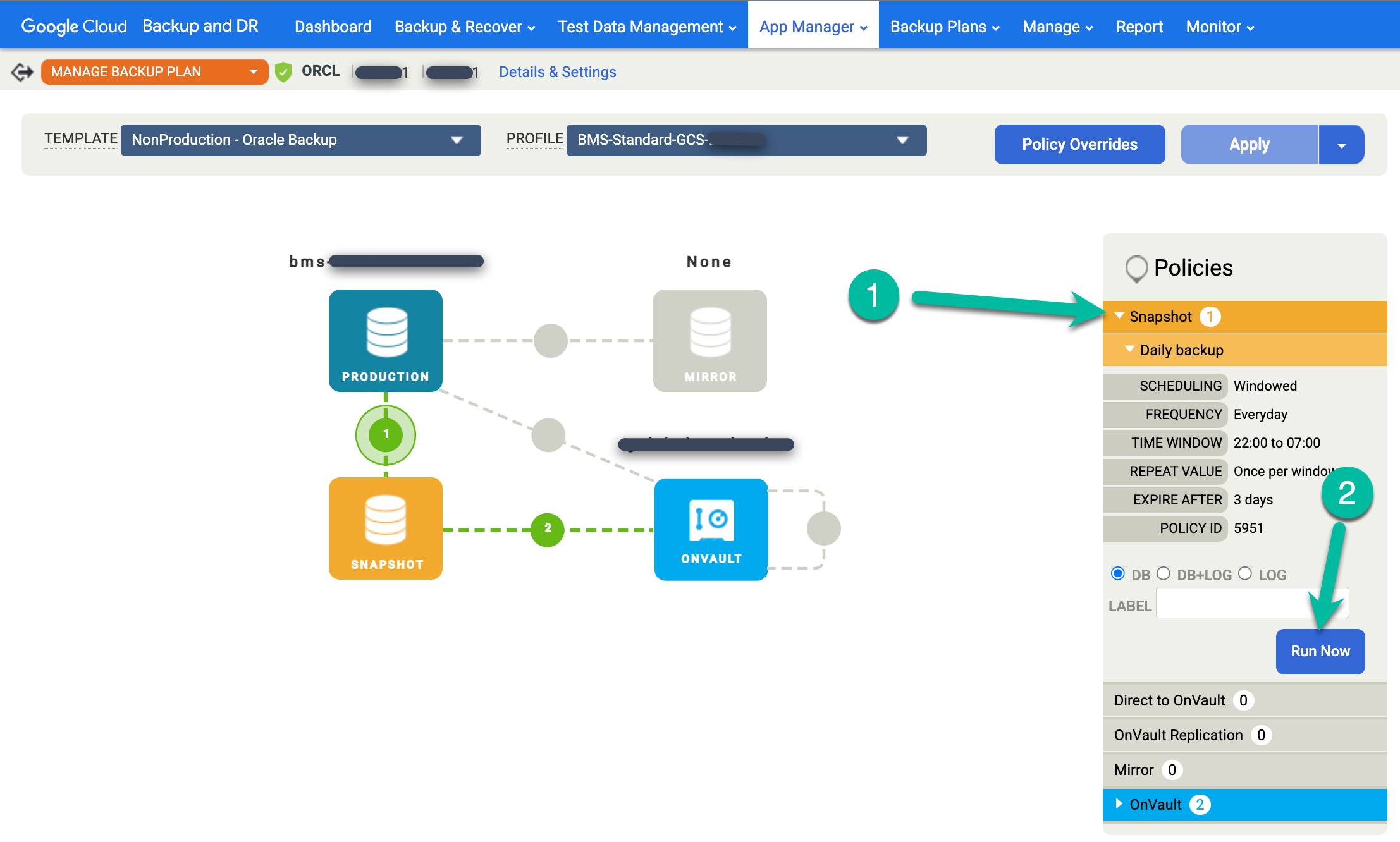
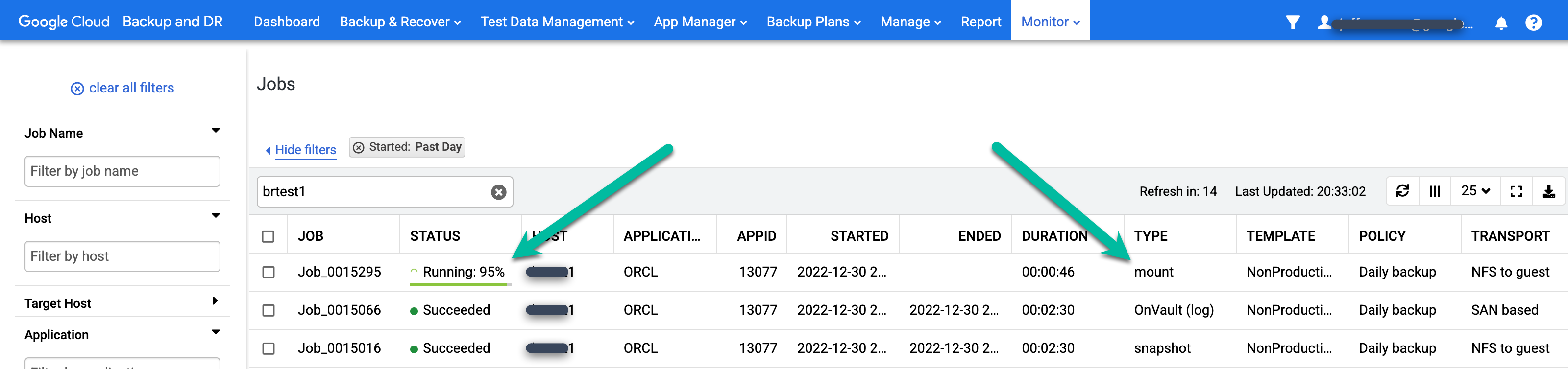
백업 작업 상태를 모니터링하려면 모니터링 > 작업 메뉴로 이동하여 작업 상태를 확인합니다. 작업이 작업 목록에 표시되기까지 5~10초가 걸릴 수 있습니다. 다음은 실행 중인 작업의 예시입니다.

작업이 성공하면 메타데이터를 사용하여 특정 작업의 세부정보를 볼 수 있습니다.
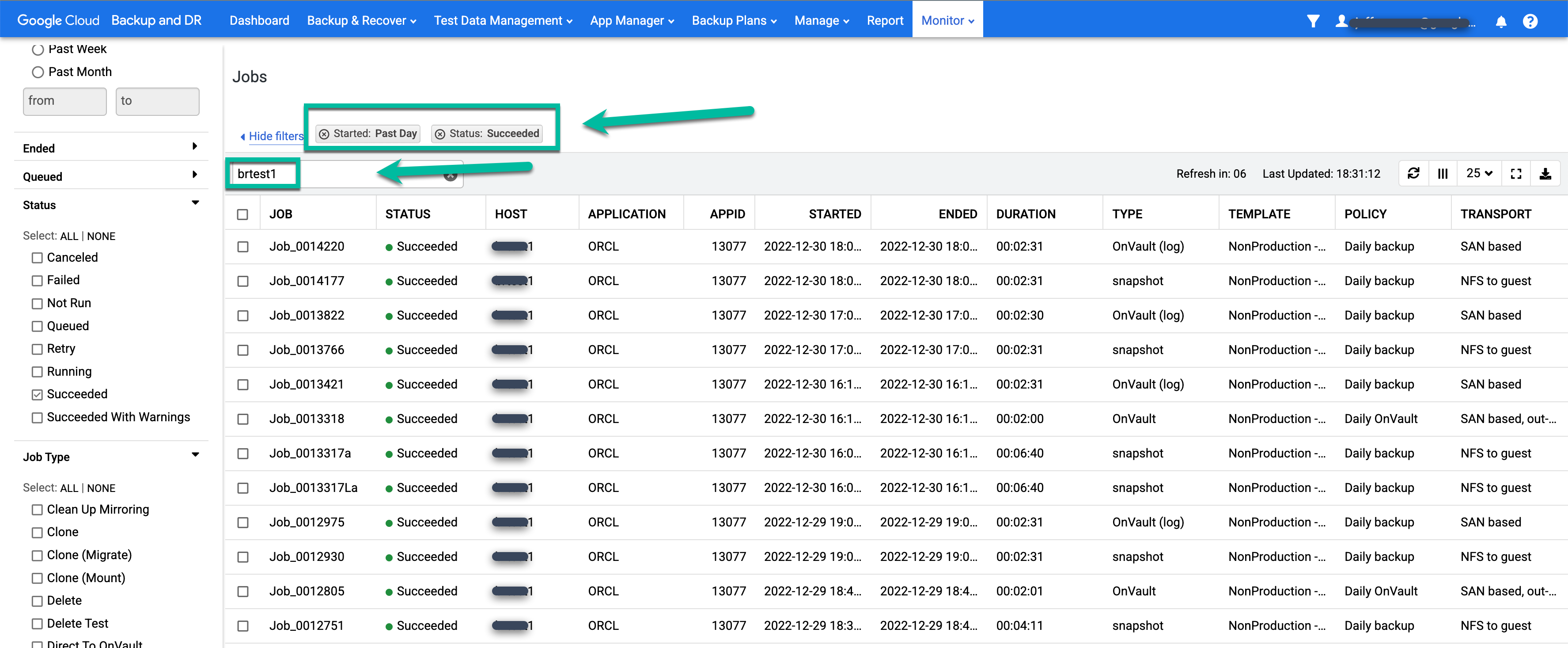
- 필터를 적용하고 검색어를 추가하여 관심 있는 작업을 찾습니다. 다음 예시에서는 성공 및 지난 날짜 필터와 test1 호스트 검색을 함께 사용합니다.
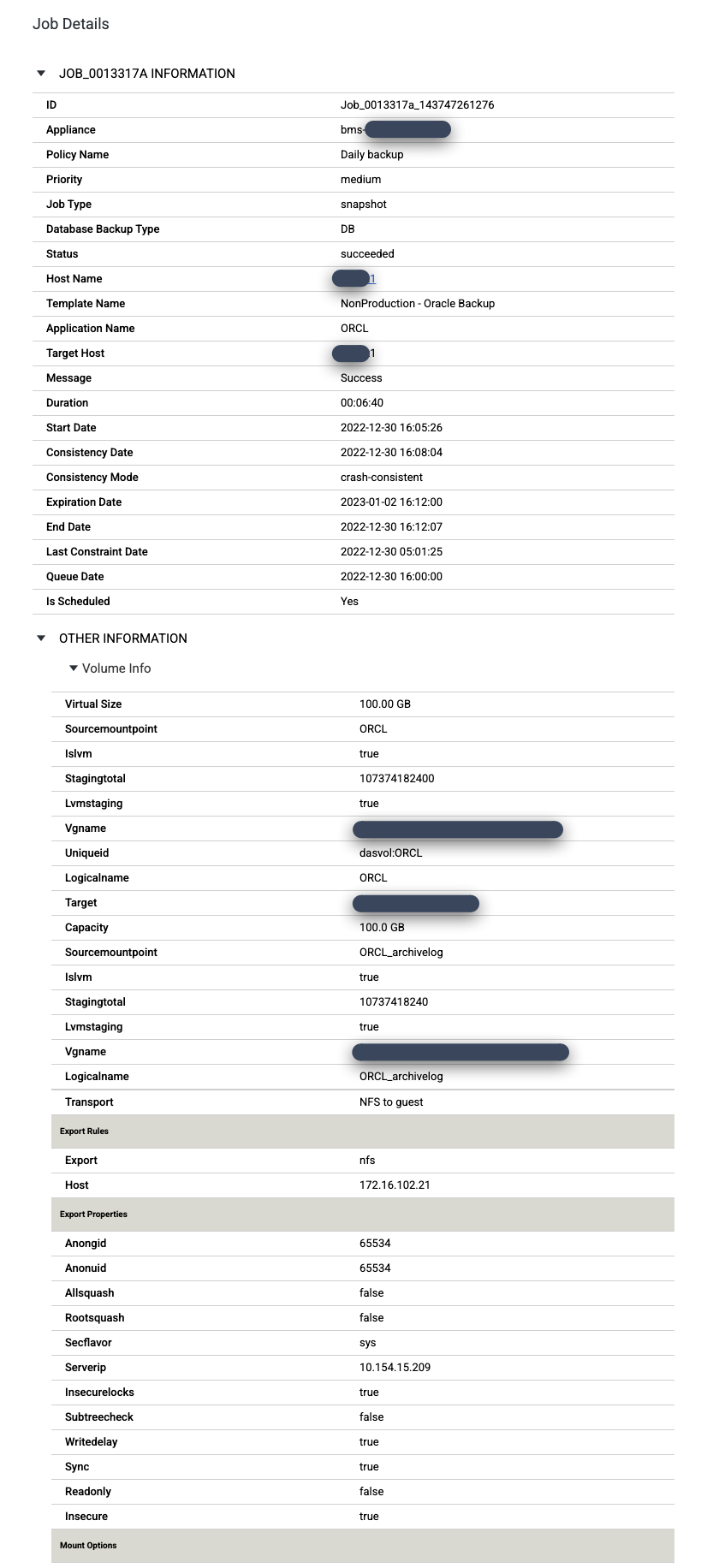
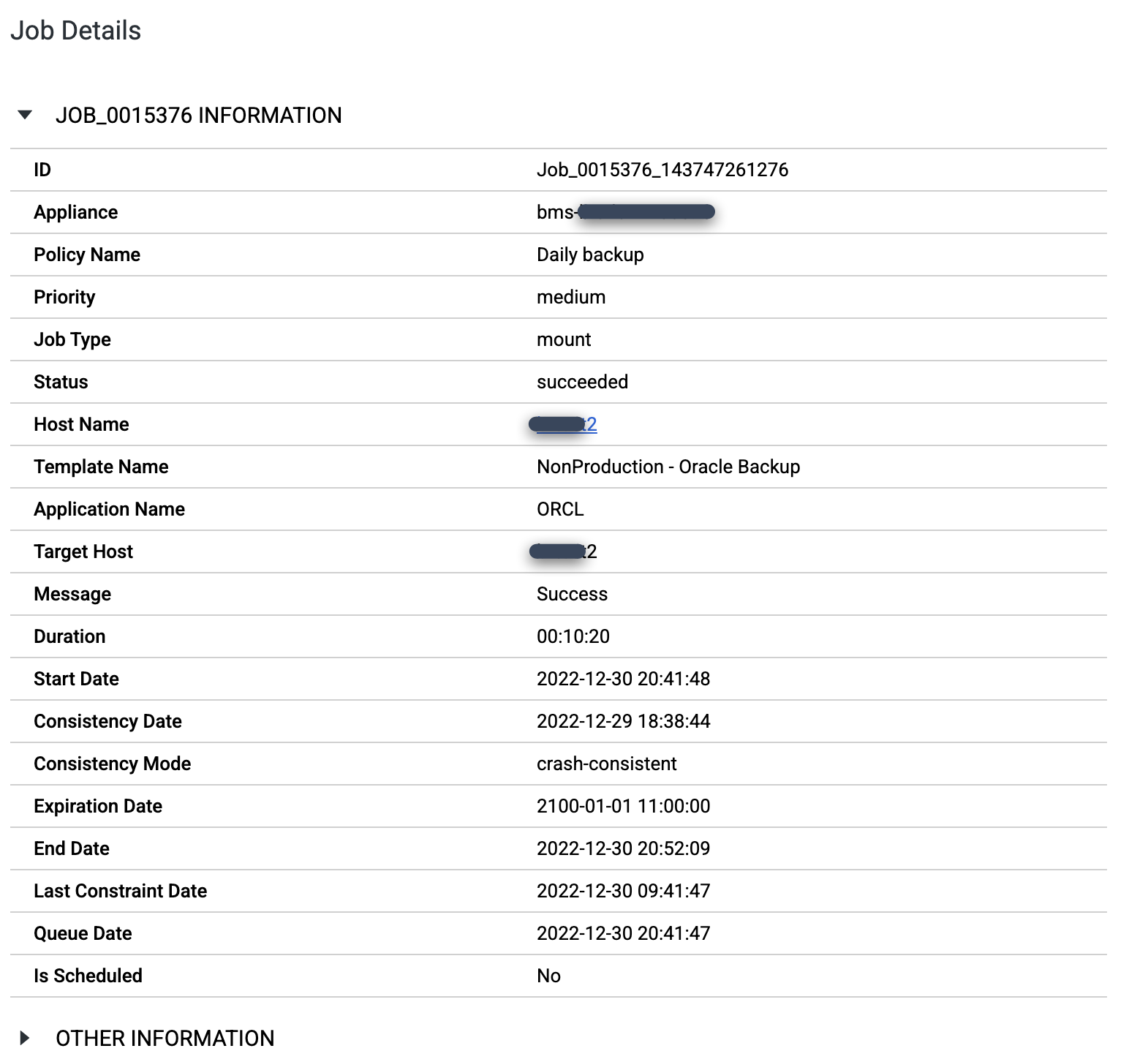
특정 작업을 자세히 살펴보려면 작업 열에서 작업을 클릭합니다. 새 창이 열립니다. 다음 예시에서 볼 수 있듯이 각 백업 작업은 많은 정보를 캡처합니다.
Oracle 데이터베이스 마운트 및 복원
Google Cloud 백업 및 DR에는 Oracle 데이터베이스 사본에 액세스하기 위한 다양한 기능이 있습니다. 두 가지 주요 방법은 다음과 같습니다.
- 앱 인식 마운트
- 복원(마운트 및 마이그레이션, 기존 복원)
이러한 각 메서드에는 각기 다른 이점이 있으므로 사용 사례, 성능 요구사항, 데이터베이스 사본을 보관해야 하는 기간에 따라 사용할 메서드를 선택해야 합니다. 다음 섹션에는 각 기능에 관한 몇 가지 권장사항이 포함되어 있습니다.
앱 인식 마운트
마운트를 사용하여 Oracle 데이터베이스의 가상 사본에 빠르게 액세스할 수 있습니다. 성능이 중요하지 않으며 데이터베이스 사본이 몇 시간에서 며칠 동안만 지속될 때 마운트를 구성할 수 있습니다.
마운트의 주요 이점은 추가 스토리지를 많이 사용하지 않는다는 것입니다. 대신 마운트는 백업 디스크 풀의 스냅샷을 사용하며, 이는 영구 디스크의 스냅샷 풀이나 Cloud Storage의 OnVault 풀일 수 있습니다. 가상 사본 스냅샷 기능을 사용하면 데이터를 먼저 복사할 필요가 없으므로 데이터에 액세스하는 시간이 최소화됩니다. 백업 디스크는 모든 읽기를 처리하며, 스냅샷 풀의 디스크는 모든 쓰기를 저장합니다. 따라서 가상 복사본을 마운트할 때 빠르게 액세스할 수 있으며 백업 디스크 복사본을 덮어쓰지 않습니다. 마운트는 스키마 변경사항 또는 업데이트를 프로덕션에 출시하기 전에 검증해야 하는 개발, 테스트, DBA 활동에 적합합니다.
Oracle 데이터베이스 마운트
백업 및 DR 관리 콘솔에서 백업 및 복구 > 복구 페이지로 이동합니다.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#recover/selectapp
애플리케이션 목록에서 마운트할 데이터베이스를 찾아 데이터베이스 이름을 마우스 오른쪽 버튼으로 클릭하고 다음을 클릭합니다.
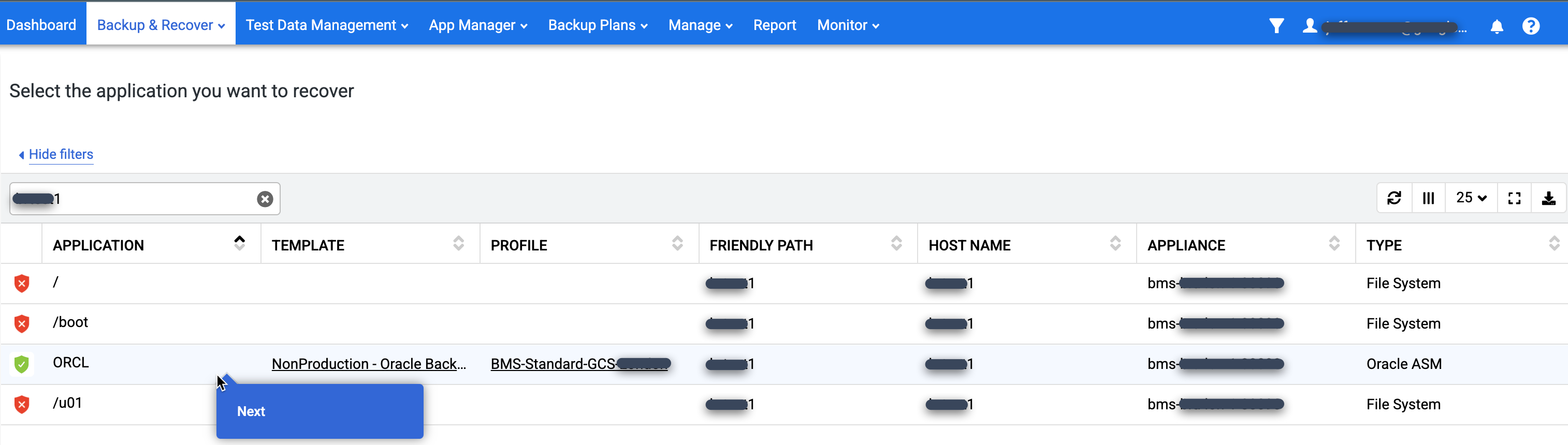
사용 가능한 모든 특정 시점 이미지가 표시된 타임라인 램프 뷰가 표시됩니다. 램프 뷰에 표시되지 않는 경우 뒤로 스크롤하여 장기 보관 이미지를 확인할 수도 있습니다. 기본적으로 최신 이미지를 선택합니다.
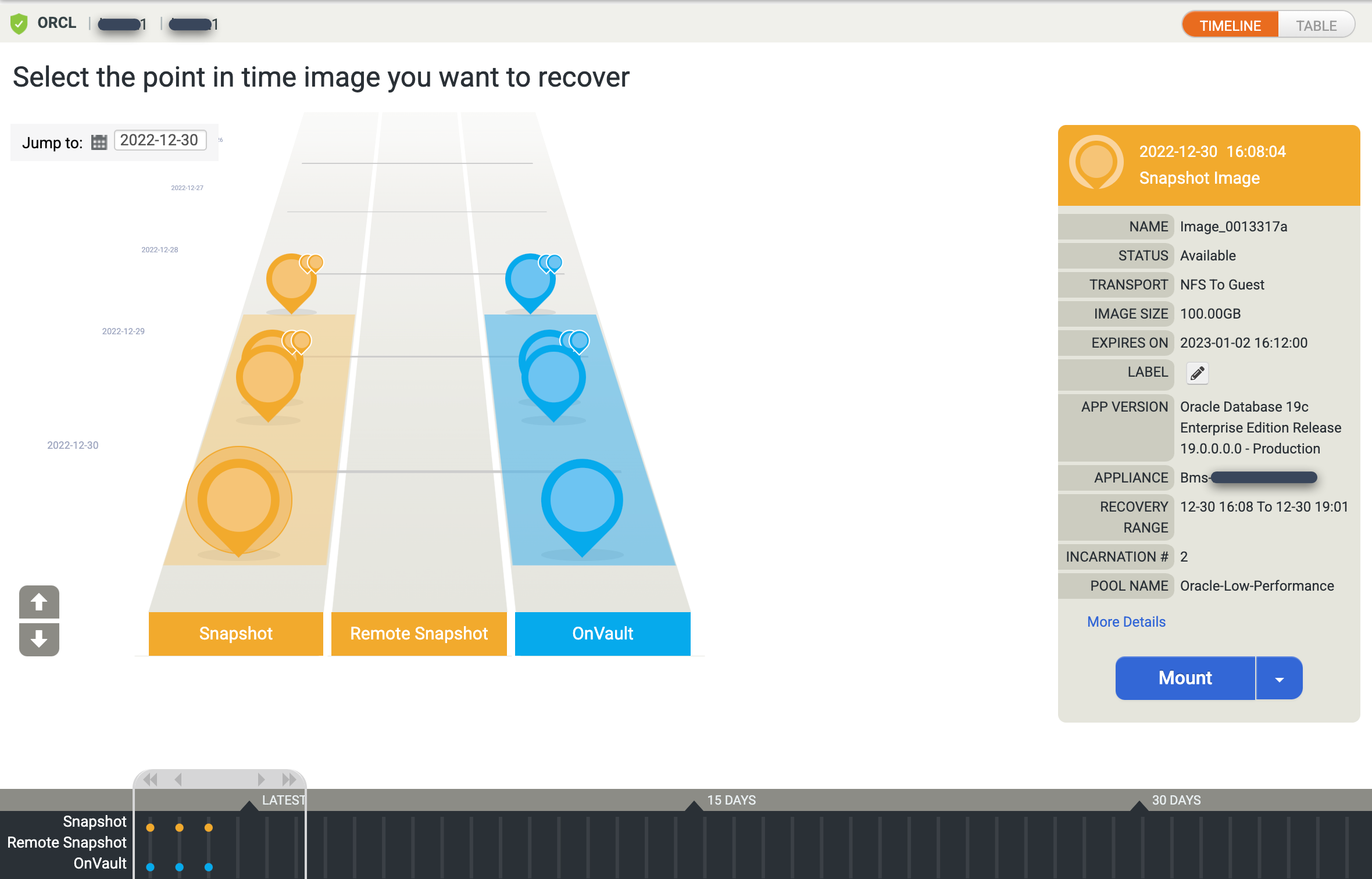
특정 시점 이미지의 테이블 뷰를 보려면 테이블 옵션을 클릭하여 뷰를 변경합니다.
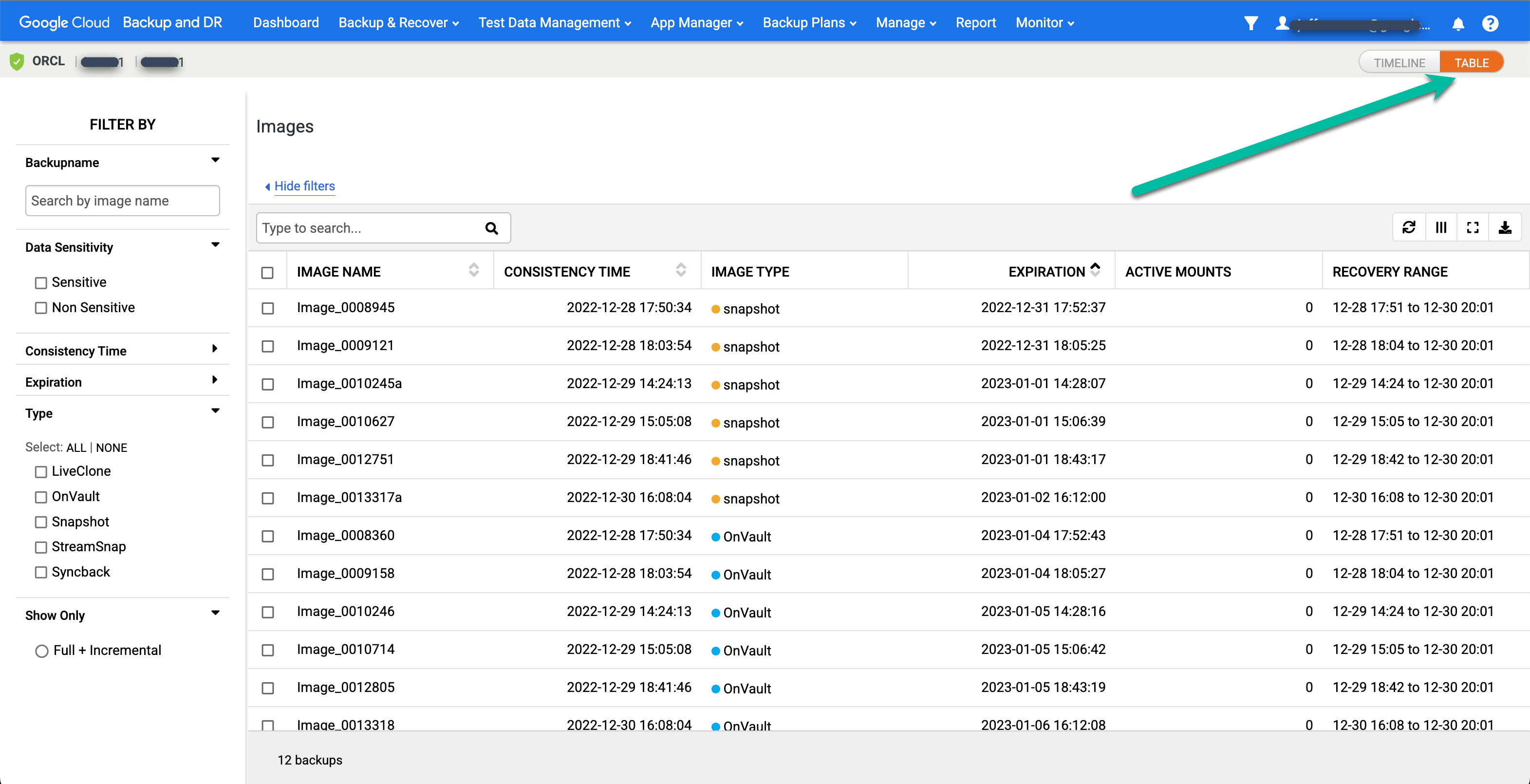
원하는 이미지를 찾아 마운트를 선택합니다.
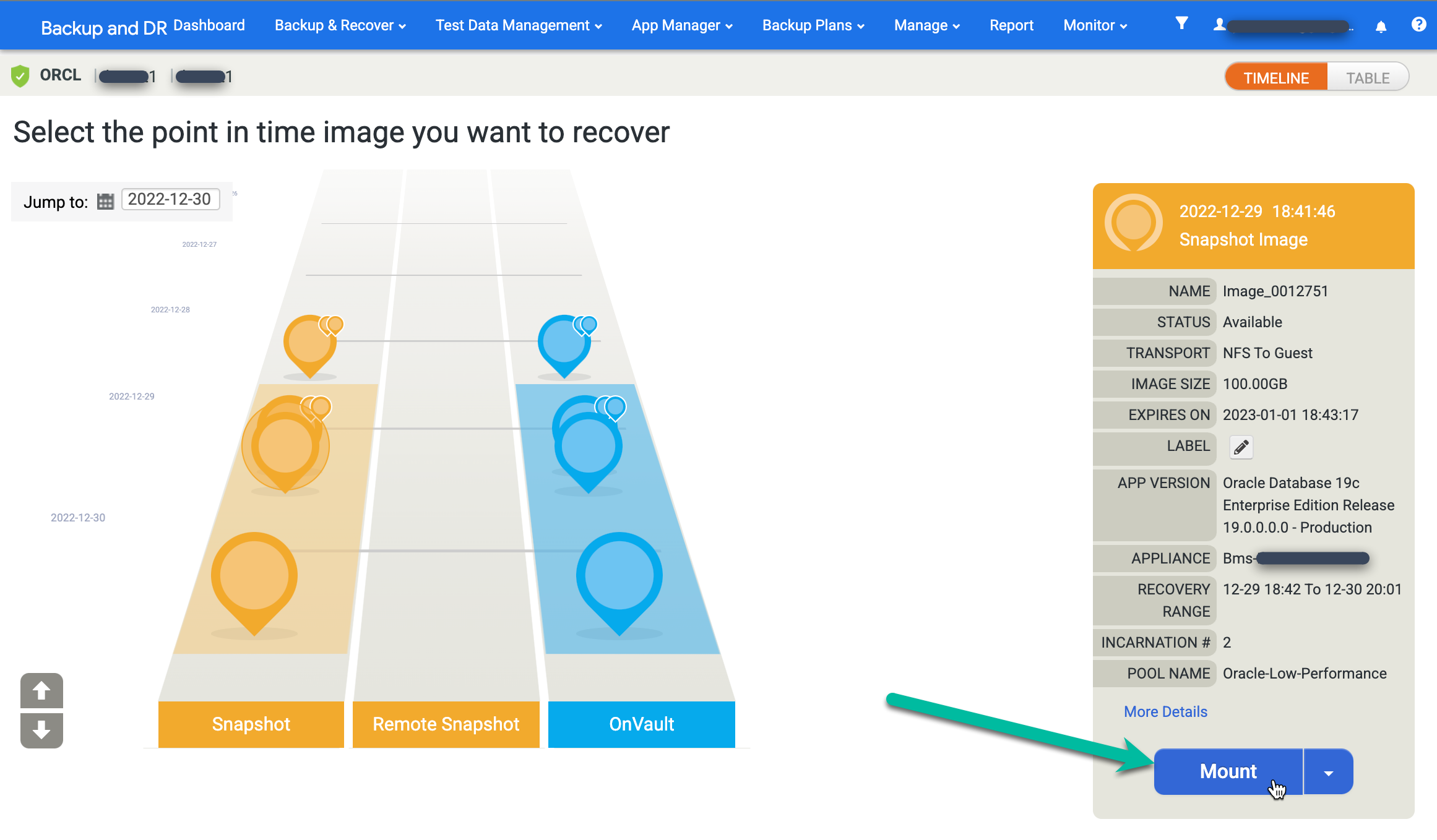
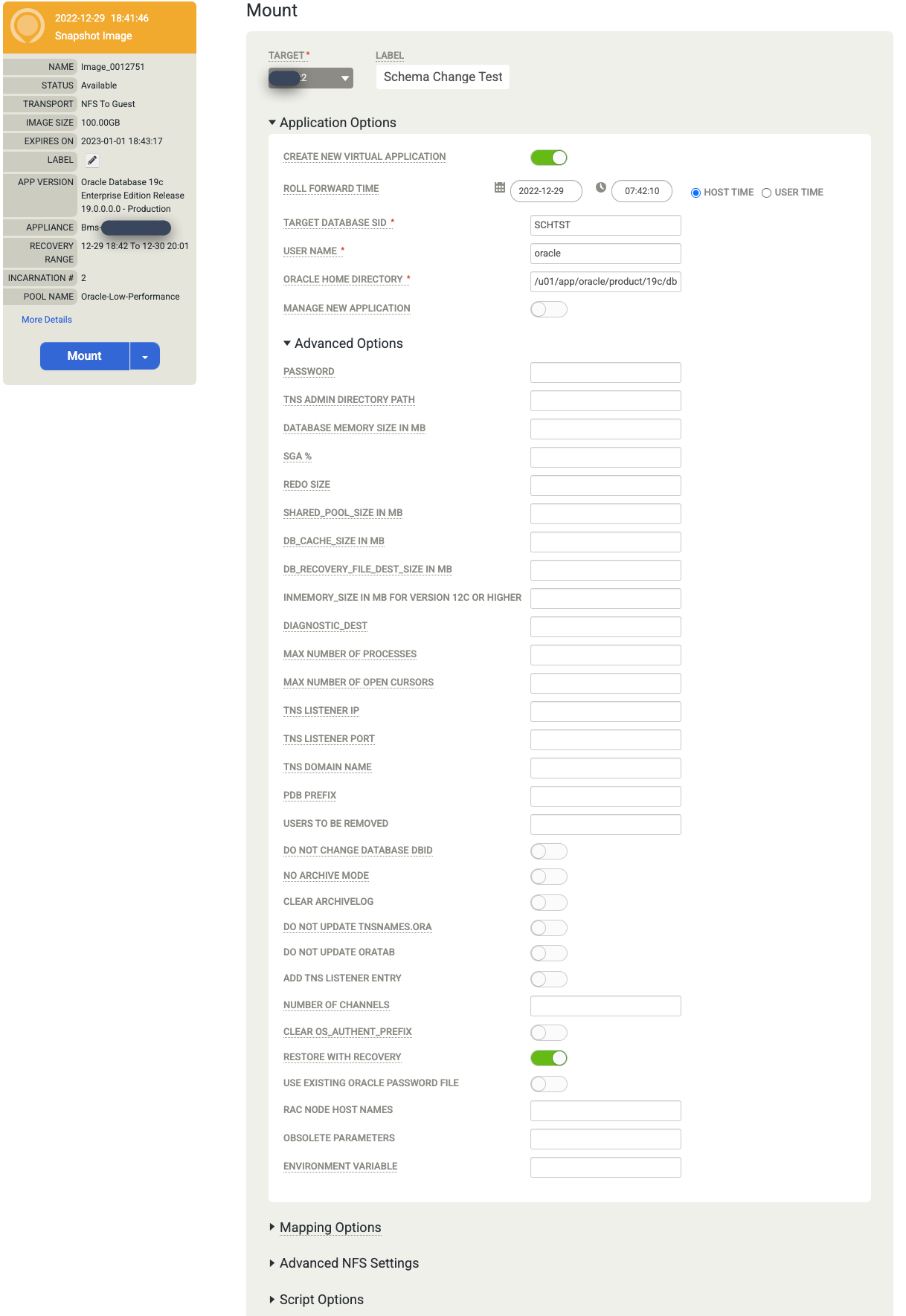
마운트할 데이터베이스의 애플리케이션 옵션을 선택합니다.
- 드롭다운 메뉴에서 타겟 호스트를 선택합니다. 이전에 호스트를 추가한 경우 이 목록에 호스트가 표시됩니다.
- (선택사항) 라벨을 입력합니다.
- 타겟 데이터베이스 SID 필드에 대상 데이터베이스의 식별자를 입력합니다.
- 사용자 이름을 Oracle로 설정합니다. 이 이름은 인증을 위한 OS 사용자 이름이 됩니다.
- Oracle 홈 디렉터리를 입력합니다. 이 예시에서는
/u01/app/oracle/product/19c/dbhome_1을 사용합니다. - 데이터베이스 로그를 백업하도록 구성하면 롤 포워드 시간을 사용할 수 있습니다. 시계/시간 선택기를 클릭하고 롤 포워드 지점을 선택합니다.
- 복구를 사용하여 복원은 기본적으로 사용 설정됩니다. 이 옵션은 데이터베이스를 마운트하고 엽니다.
정보 입력을 마쳤으면 제출을 클릭하여 마운트 프로세스를 시작합니다.
작업 진행 상황 및 성공 모니터링
모니터링 > 작업 페이지로 이동하여 실행 중인 작업을 모니터링할 수 있습니다.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#jobs
페이지에 상태와 작업 유형이 표시됩니다.
마운트 작업이 완료되면 작업 번호를 클릭하여 작업 세부정보를 확인할 수 있습니다.
만든 SID의 pmon 프로세스를 보려면 대상 호스트에 로그인하고
ps -ef |grep pmon명령어를 실행합니다. 다음 출력 예시에서 SCHTEST 데이터베이스가 작동하고 프로세스 ID가 173953입니다.[root@test2 ~]# ps -ef |grep pmon oracle 1382 1 0 Dec23 ? 00:00:28 asmpmon+ASM oracle 56889 1 0 Dec29 ? 00:00:06 ora_pmon_ORCL oracle 173953 1 0 09:51 ? 00:00:00 ora_pmon_SCHTEST root 178934 169484 0 10:07 pts/0 00:00:00 grep --color=auto pmon
Unmount an Oracle database
After you finish using the database, you should unmount and delete the database. There are two methods to find a mounted database:
Go to App Manager > Active Mounts page.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#activemounts
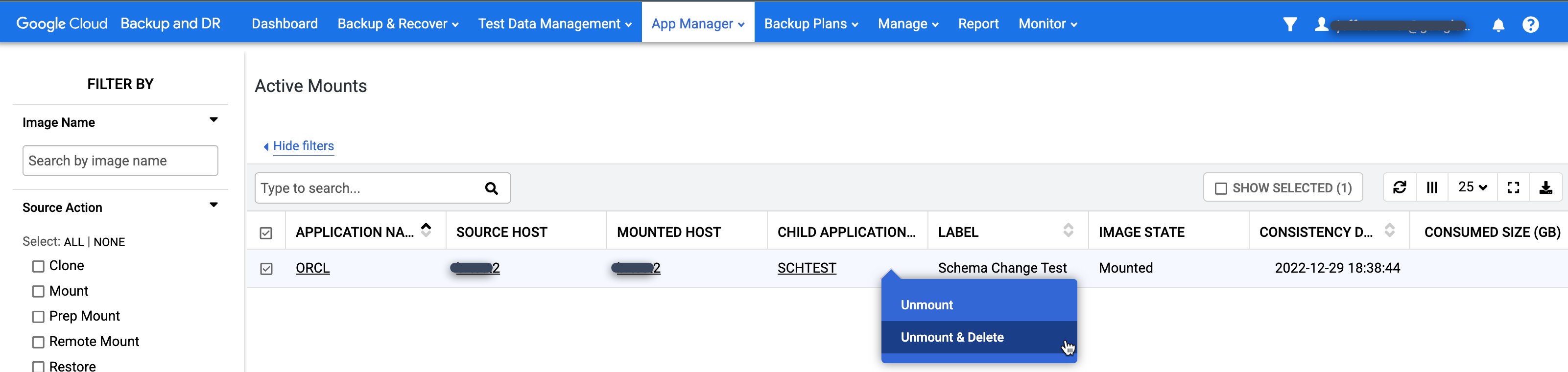
이 페이지에는 현재 사용 중인 모든 마운트된 애플리케이션(파일 시스템 및 데이터베이스)의 전역 뷰가 포함되어 있습니다.
삭제하려는 마운트를 마우스 오른쪽 버튼으로 클릭하고 메뉴에서 마운트 해제 및 삭제를 선택합니다. 이 작업으로 백업 데이터는 삭제되지 않습니다. 대상 호스트와 데이터베이스의 저장된 쓰기가 포함된 스냅샷 캐시 디스크에서만 가상 마운트된 데이터베이스를 삭제합니다.
앱 관리자 > 애플리케이션 페이지로 이동합니다.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#applications
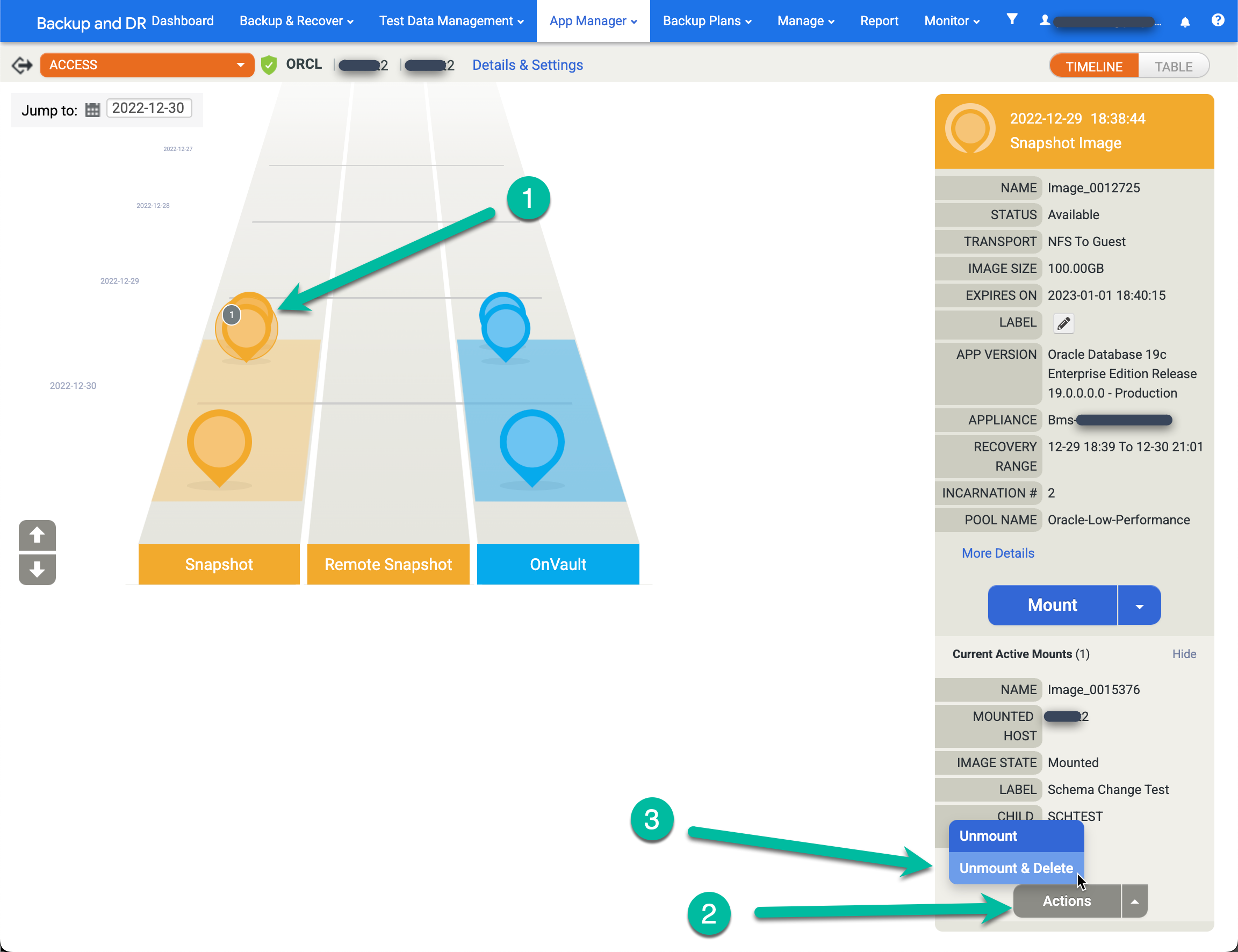
- 소스 앱(데이터베이스)을 마우스 오른쪽 버튼으로 클릭하고 액세스를 선택합니다.
- 왼쪽 램프에는 이 시점의 활성 마운트 수를 나타내는 숫자가 있는 회색 원이 표시됩니다. 해당 이미지를 클릭하면 새 메뉴가 표시됩니다.
- 작업을 클릭합니다.
- 마운트 해제 및 삭제를 클릭합니다.
- 제출을 클릭하고 다음 화면에서 이 작업을 확인합니다.
몇 분 후 시스템이 대상 호스트에서 데이터베이스를 삭제하고 모든 디스크를 정리 및 삭제합니다. 이 작업을 실행하면 활성 마운트의 재시도 디스크에 쓰는 데 사용되는 스냅샷 풀의 디스크 공간이 확보됩니다.
마운트 해제된 작업은 다른 작업과 동일하게 모니터링할 수 있습니다. 모니터링 > 작업 메뉴로 이동하여 마운트 해제되는 작업의 진행 상황을 모니터링하고 작업이 완료되었는지 확인합니다.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#jobs
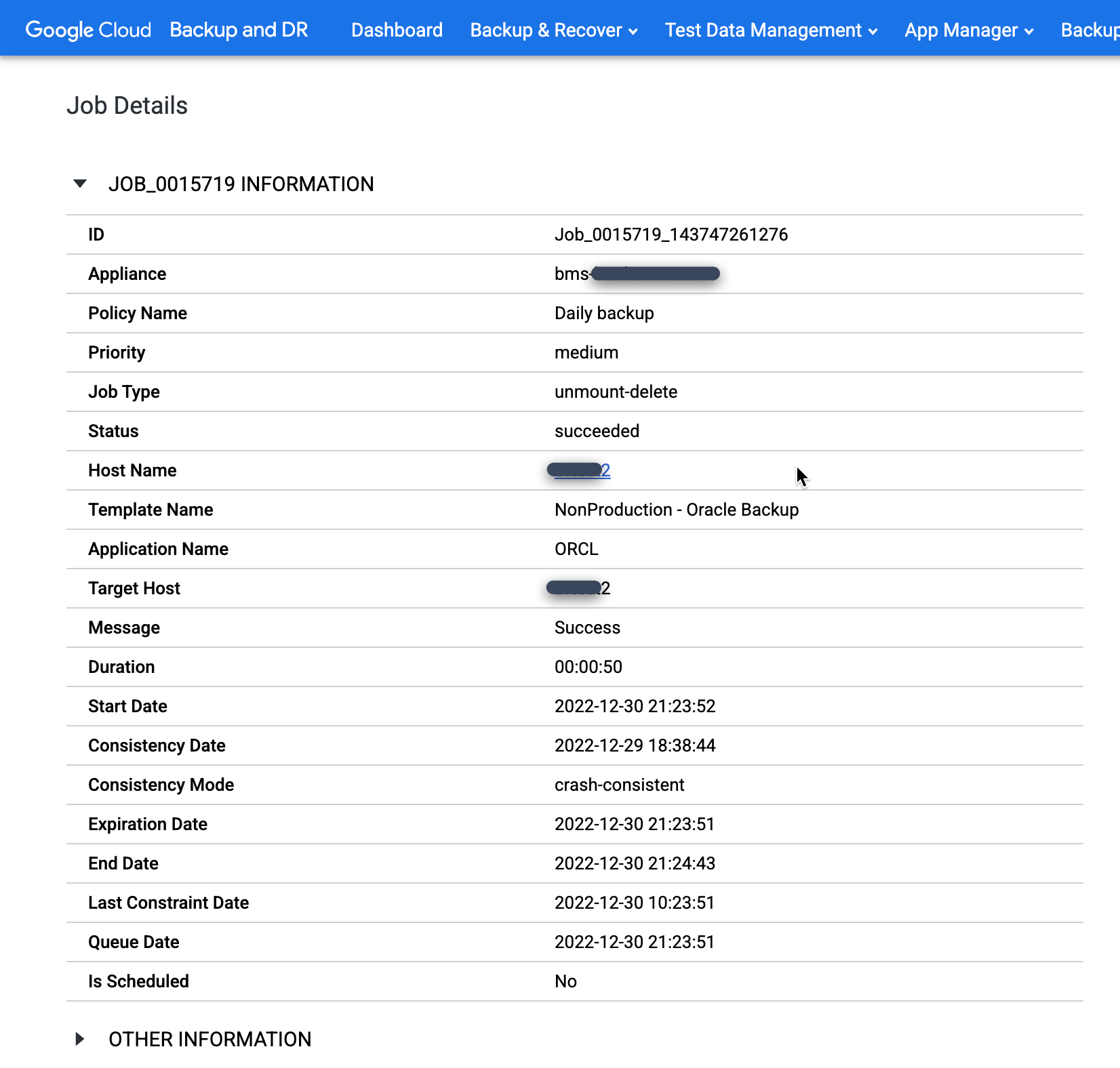
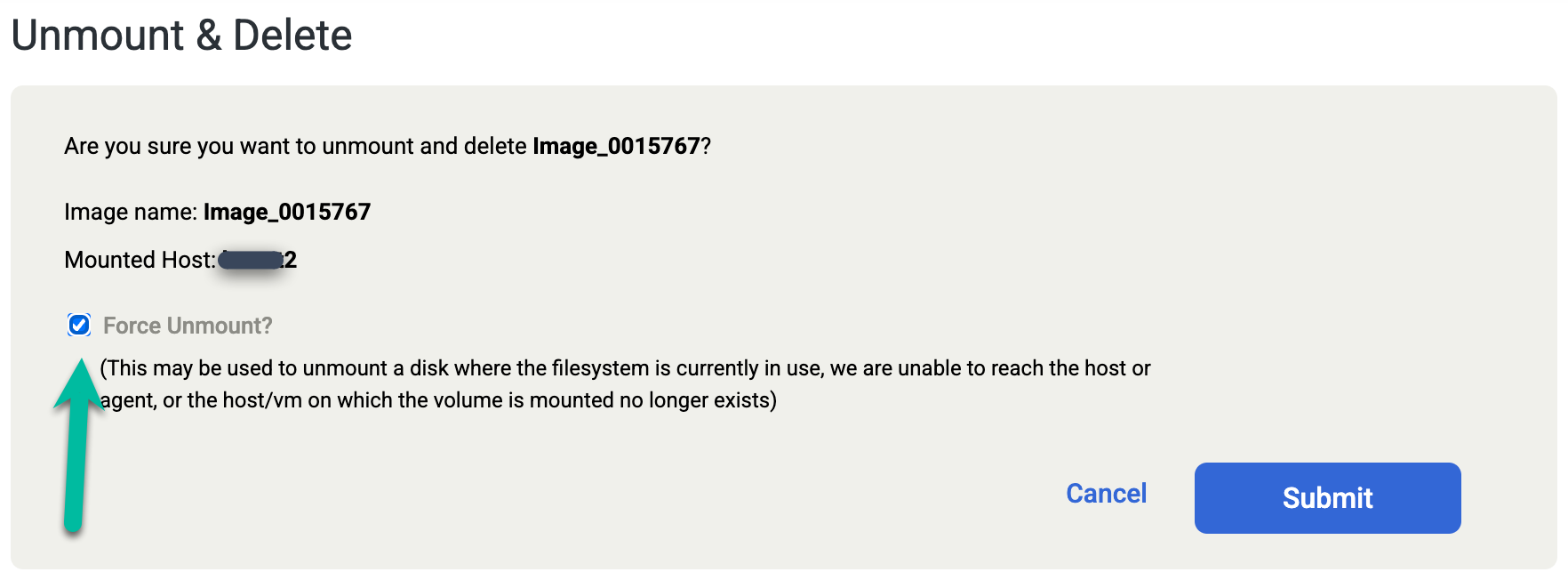
실수로 Oracle 데이터베이스를 수동으로 삭제하거나 마운트 해제 및 삭제 작업을 실행하기 전에 데이터베이스를 종료하는 경우 마운트 해제 및 삭제 작업을 다시 수행하고 확인 화면에서 강제 마운트 해제 옵션을 선택합니다. 이 작업을 실행하면 대상 호스트에서 재실행 스테이징 디스크가 강제로 삭제되고 스냅샷 풀에서 디스크가 삭제됩니다.
복원
문제 또는 손상이 발생할 때 백업 사본에서 로컬 호스트로 데이터베이스의 모든 파일을 복사해야 하는 경우 복원을 사용하여 프로덕션 데이터베이스를 복구합니다. 일반적으로 재해 유형 이벤트 후 또는 프로덕션 외 테스트 사본의 경우 복원을 실행합니다. 이러한 경우 고객은 일반적으로 이전 파일이 소스 호스트에 복사될 때까지 기다린 후 데이터베이스를 다시 시작해야 합니다. 그러나 Google Cloud 백업 및 DR은 복원 기능(파일 복사 및 데이터베이스 시작)과 데이터베이스를 마운트하는 마운트 및 마이그레이션 기능(액세스 시간이 빠름)을 지원하며 데이터베이스가 마운트되고 액세스할 수 있으면 데이터 파일을 로컬 머신에 복사할 수 있습니다. 마운트 및 마이그레이션 기능은 낮은 복구 시간 목표(RTO) 시나리오에 유용합니다.
마운트 및 마이그레이션
마운트 및 이전 기반 복구에는 두 가지 단계가 있습니다.
- 1단계: 마운트 복원 단계에서 마운트된 사본에서 시작하여 데이터베이스에 대한 즉각적인 액세스를 제공합니다.
- 2단계: 마이그레이션 복원 단계에서 데이터베이스가 온라인 상태일 때 데이터베이스를 프로덕션 스토리지 위치로 마이그레이션합니다.
마운트 복원 - 1단계
이 단계에서는 백업/복구 어플라이언스에서 제공한 선택된 이미지에서 데이터베이스에 즉시 액세스할 수 있습니다.
- 선택한 백업 이미지의 사본이 대상 데이터베이스 서버에 매핑되고 소스 데이터베이스 백업 이미지 형식에 따라 ASM 또는 파일 시스템 레이어에 제공됩니다.
- RMAN API를 사용하여 다음 작업을 실행합니다.
- 제어 파일 및 재실행 로그 파일을 지정된 로컬 제어 파일로 복원하고 파일 위치(ASM 디스크 그룹 또는 파일 시스템)를 다시 실행합니다.
- 데이터베이스를 백업/복구 어플라이언스에서 제공한 이미지의 사본으로 전환합니다.
- 사용 가능한 모든 보관처리 로그를 지정된 복구 지점으로 롤포워드합니다.
- 데이터베이스를 읽기 및 쓰기 모드로 엽니다.
- 데이터베이스는 백업/복구 어플라이언스에서 제공하는 백업 이미지의 매핑된 사본에서 실행됩니다.
- 데이터베이스의 제어 파일 및 재실행 로그 파일은 대상의 선택된 로컬 프로덕션 스토리지 위치(ASM 디스크 그룹 또는 파일 시스템)에 배치됩니다.
- 복원 마운트 작업이 완료되면 프로덕션 작업에 데이터베이스를 사용할 수 있습니다. Oracle 온라인 데이터 파일 이동 API를 사용하여 데이터베이스와 애플리케이션이 실행 중인 동안에 다시 프로덕션 스토리지 위치(ASM 디스크 그룹 또는 파일 시스템)로 데이터를 이동할 수 있습니다.
마이그레이션 복원 - 2단계
데이터베이스 데이터 파일을 온라인으로 프로덕션 스토리지로 이동합니다.
- 데이터 마이그레이션은 백그라운드에서 실행됩니다. Oracle 온라인 데이터 파일 이동 API를 사용하여 데이터를 마이그레이션합니다.
- 백업 이미지의 백업 및 DR 제공 사본에서 선택한 대상 데이터베이스 스토리지(ASM 디스크 그룹 또는 파일 시스템)로 데이터 파일을 이동합니다.
- 마이그레이션 작업이 완료되면 시스템이 백업 및 DR 제공 백업 이미지 사본(ASM 디스크 그룹 또는 파일 시스템)을 대상에서 삭제 및 매핑 해제하고 데이터베이스가 프로덕션 스토리지에서 실행됩니다.
마운트 및 마이그레이션 복구에 대한 자세한 내용은 모든 대상에 즉시 복구를 위한 Oracle 백업 이미지 마운트 및 마이그레이션을 참조하세요.
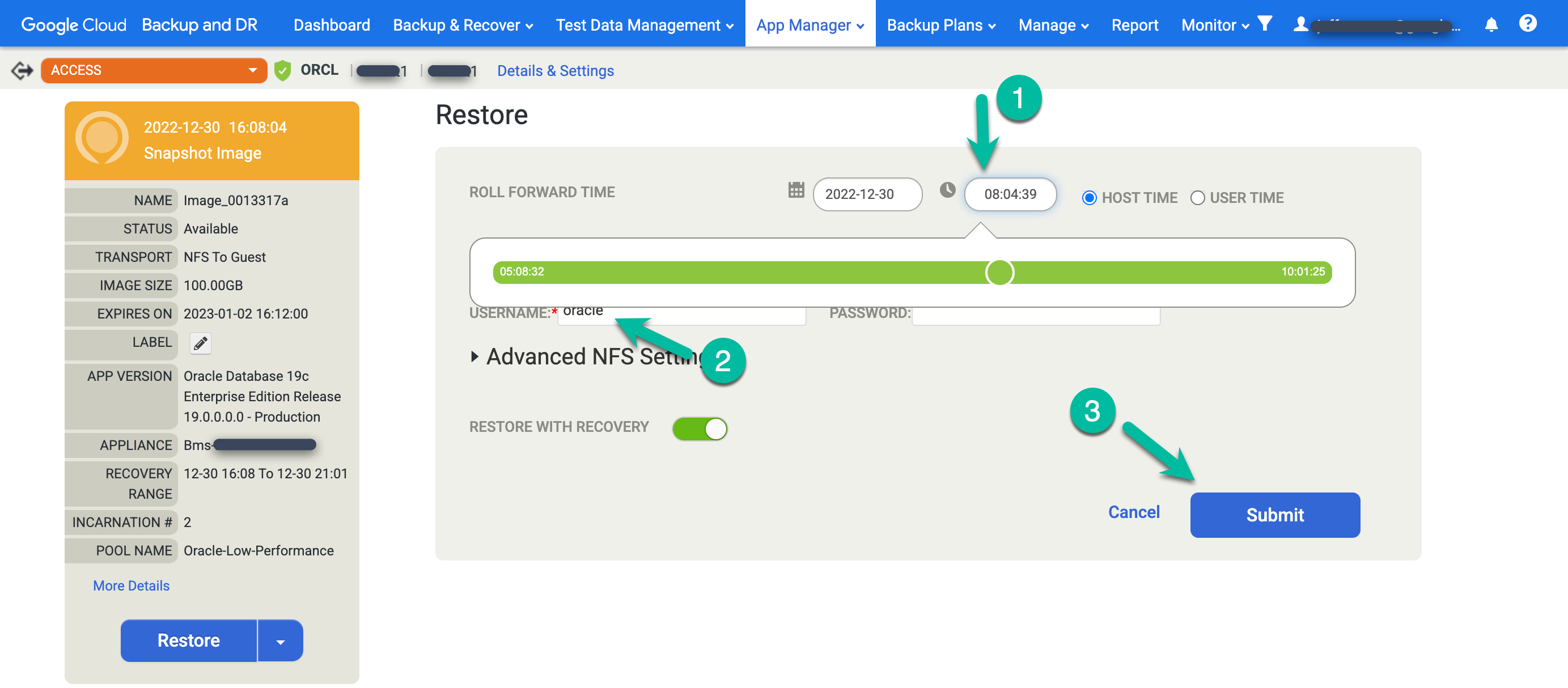
Oracle 데이터베이스 복원
백업 및 DR 관리 콘솔에서 백업 및 복구 > 복구 페이지로 이동합니다.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#recover/selectapp
애플리케이션 목록에서 복원하려는 데이터베이스의 이름을 마우스 오른쪽 버튼으로 클릭하고 다음을 선택합니다.
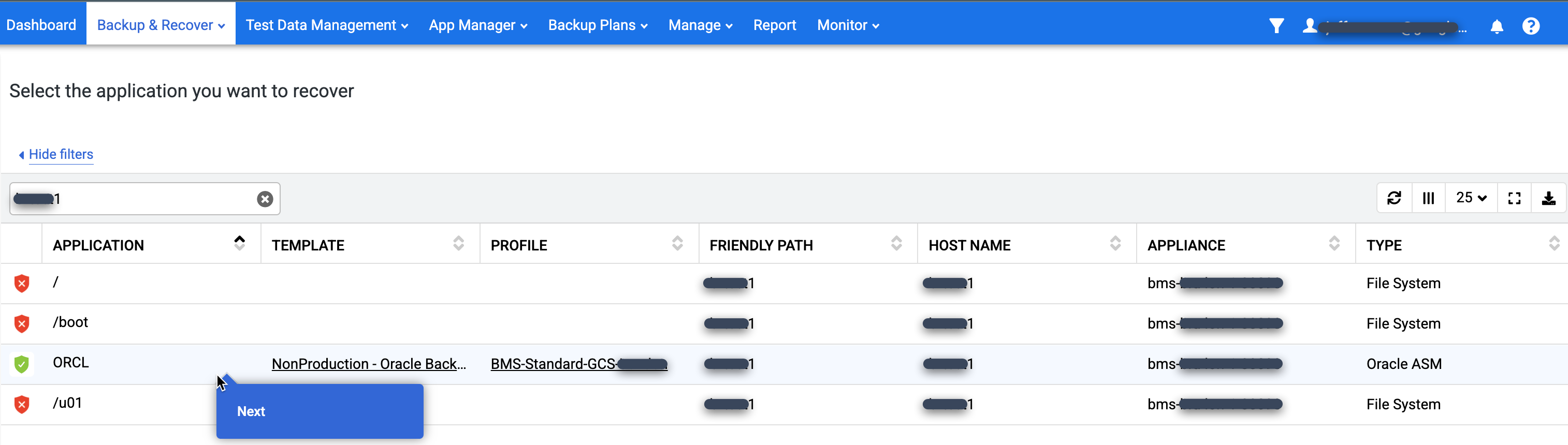
사용 가능한 모든 특정 시점 이미지가 표시된 타임라인 램프 뷰가 표시됩니다. 램프에 표시되지 않는 장기 보관 이미지를 확인해야 하는 경우 뒤로 스크롤할 수도 있습니다. 시스템은 기본적으로 항상 최신 이미지를 선택합니다.
이미지를 복원하려면 마운트 메뉴를 클릭하고 복원을 선택합니다.
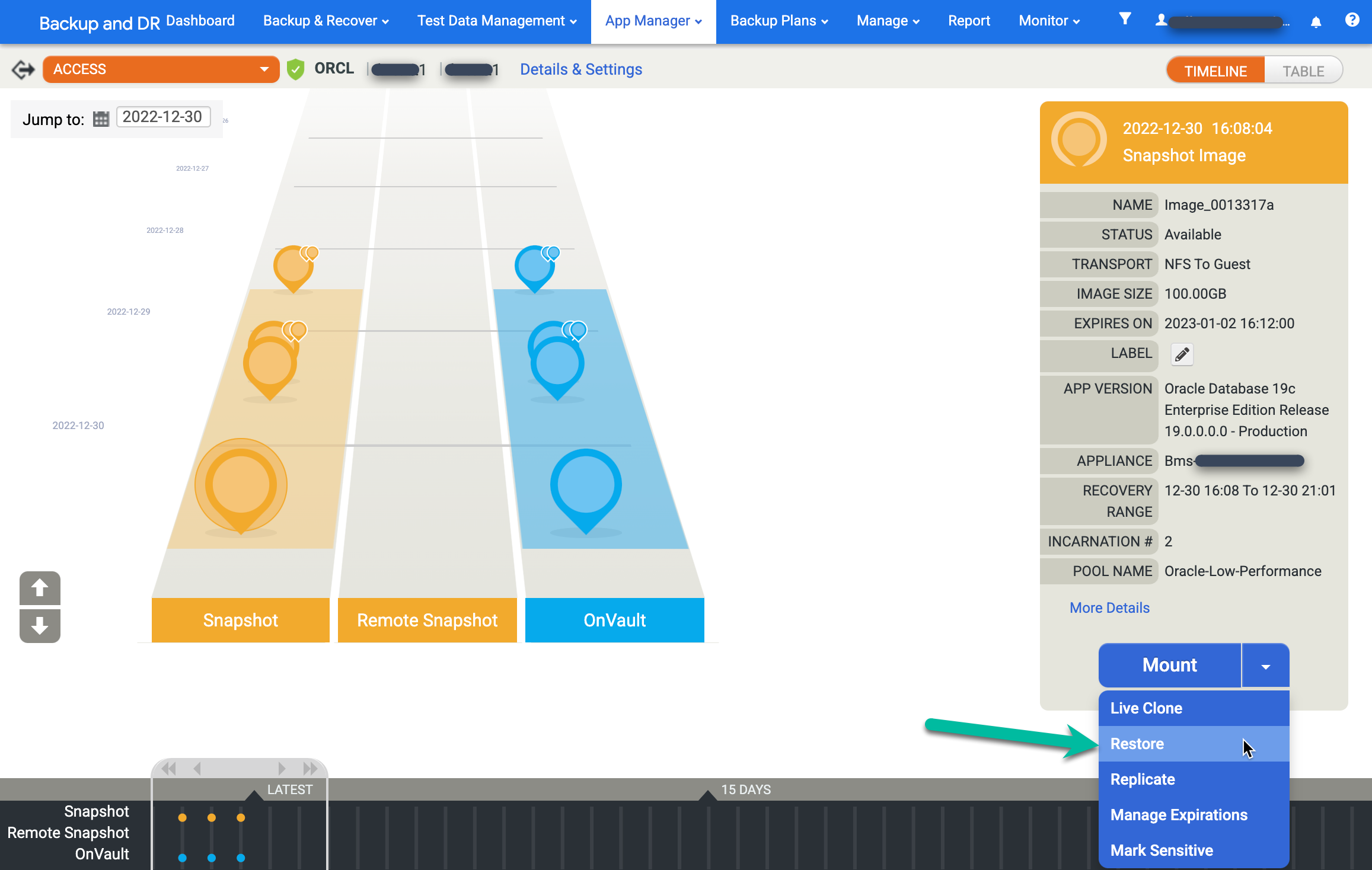
복원 옵션을 선택합니다.
- 롤 포워드 시간을 선택합니다. 시계를 클릭하고 원하는 시점을 선택합니다.
- Oracle에 사용할 사용자 이름을 입력합니다.
- 시스템에서 데이터베이스 인증을 사용하는 경우 비밀번호를 입력합니다.
작업을 시작하려면 제출을 클릭합니다.
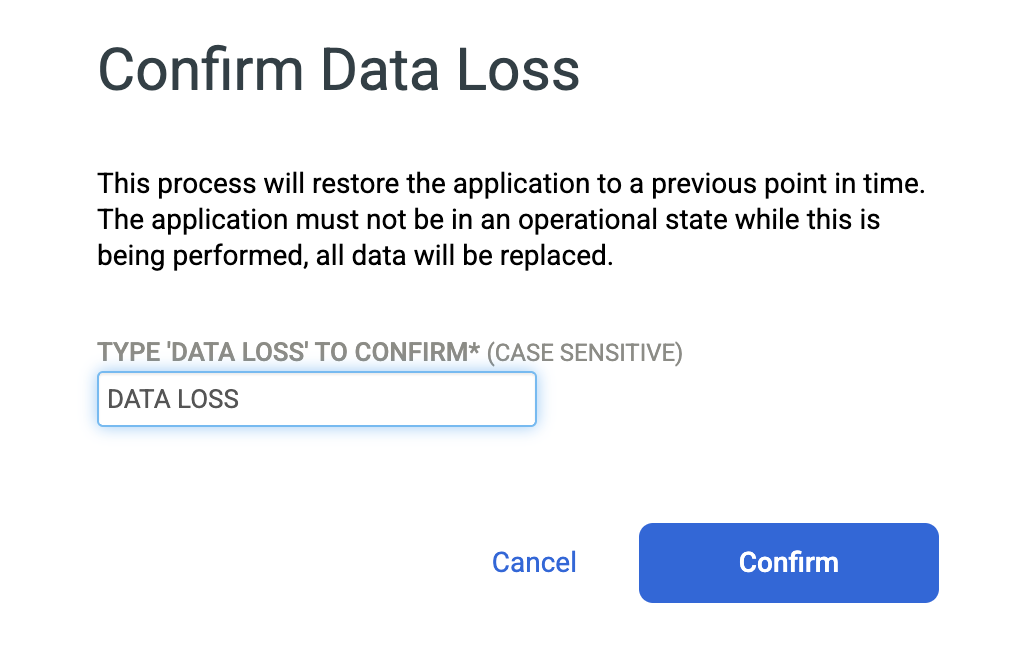
소스 데이터베이스를 덮어쓰려면 확인을 위해 DATA LOSS를 입력하고 확인을 클릭합니다.
작업 진행 상황 및 성공 모니터링
작업을 모니터링하려면 모니터링 > 작업 페이지로 이동합니다.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#jobs
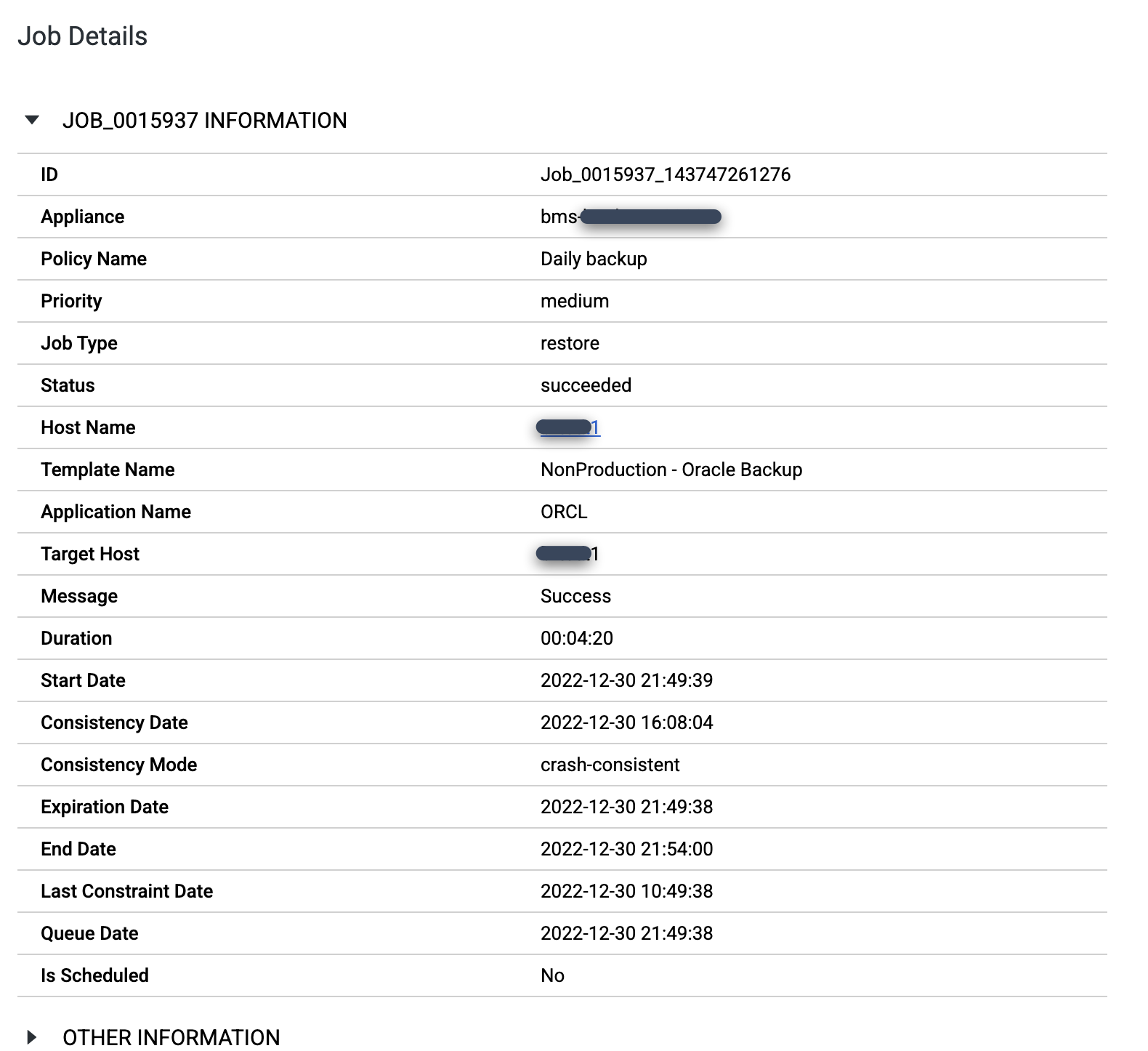
작업이 완료되면 작업 번호를 클릭하여 작업 세부정보와 메타데이터를 검토합니다.
복원된 데이터베이스 보호
데이터베이스 복원 작업이 완료되면 시스템이 복원된 후 데이터베이스를 자동으로 백업하지 않습니다. 즉, 이전에 백업 계획이 있었던 데이터베이스를 복원할 때 백업 계획이 기본적으로 활성화되지 않습니다.
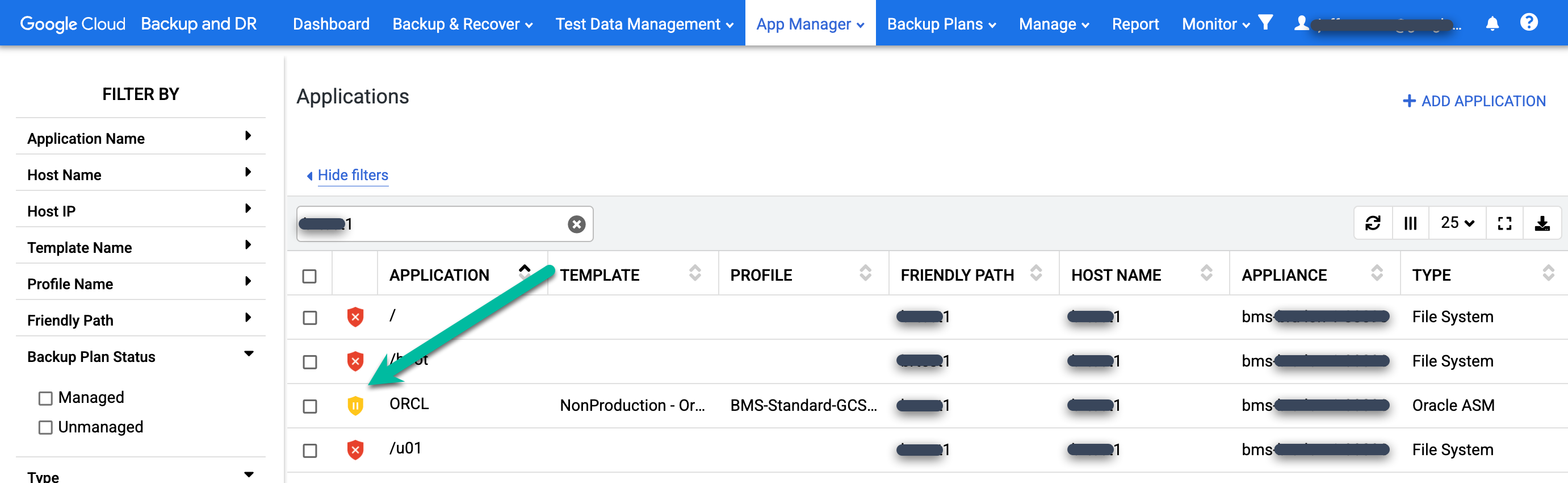
백업 계획이 실행되고 있지 않은지 확인하려면 앱 관리자 > 애플리케이션 페이지로 이동합니다.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#applications
목록에서 복원된 데이터베이스를 찾습니다. 보호 아이콘이 녹색에서 노란색으로 변경됩니다. 이는 시스템이 데이터베이스의 백업 작업을 실행하도록 예약되지 않았음을 나타냅니다.
복원된 데이터베이스를 보호하려면 애플리케이션 열에서 보호하려는 데이터베이스를 찾습니다. 데이터베이스 이름을 마우스 오른쪽 버튼으로 클릭하고 백업 계획 관리를 선택합니다.
복원된 데이터베이스의 예약 백업 작업을 다시 사용 설정합니다.
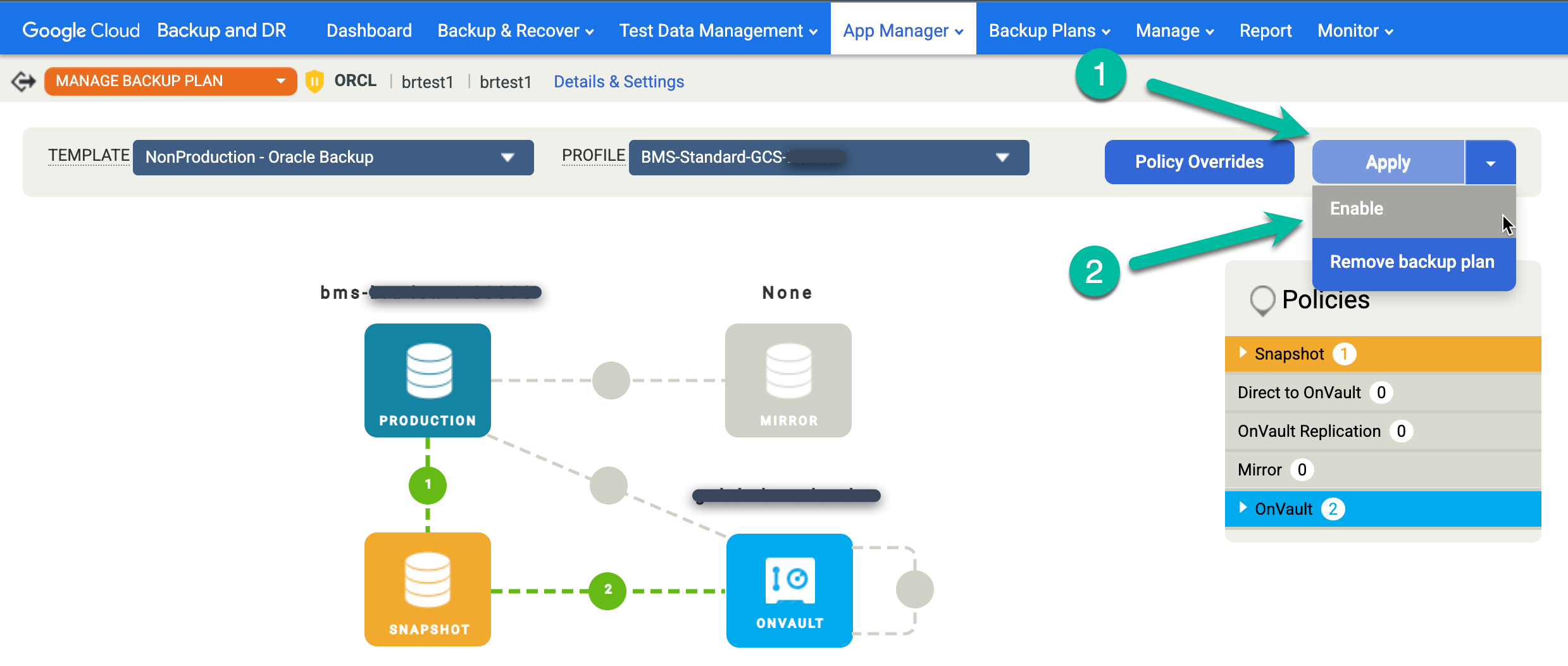
- 적용 메뉴를 클릭하고 사용 설정을 선택합니다.
Oracle Advanced 설정을 확인하고 백업 계획 사용 설정을 클릭합니다.
문제 해결 및 최적화
이 섹션에서는 Oracle 백업 문제 해결, 시스템 최적화, RAC 및 Data Guard 환경 조정을 고려할 때 도움이 되는 몇 가지 유용한 팁을 제공합니다.
Oracle 백업 문제 해결
Oracle 구성에는 백업 태스크가 성공하도록 여러 종속 항목이 포함되어 있습니다. 다음 단계에서는 Oracle 인스턴스, 리스너, 데이터베이스를 구성하여 성공을 거두기 위한 몇 가지 제안을 제공합니다.
보호하려는 서비스 및 인스턴스의 Oracle 리스너가 구성되어 실행 중인지 확인하려면
lsnrctl status명령어를 실행합니다.[oracle@test2 lib]$ lsnrctl status LSNRCTL for Linux: Version 19.0.0.0.0 - Production on 29-DEC-2022 07:43:37 Copyright (c) 1991, 2021, Oracle. All rights reserved. Connecting to (ADDRESS=(PROTOCOL=tcp)(HOST=)(PORT=1521)) STATUS of the LISTENER ------------------------ Alias LISTENER Version TNSLSNR for Linux: Version 19.0.0.0.0 - Production Start Date 23-DEC-2022 20:34:17 Uptime 5 days 11 hr. 9 min. 20 sec Trace Level off Security ON: Local OS Authentication SNMP OFF Listener Parameter File /u01/app/19c/grid/network/admin/listener.ora Listener Log File /u01/app/oracle/diag/tnslsnr/test2/listener/alert/log.xml Listening Endpoints Summary... (DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=test2.localdomain)(PORT=1521))) (DESCRIPTION=(ADDRESS=(PROTOCOL=ipc)(KEY=EXTPROC1521))) Services Summary... Service "+ASM" has 1 instance(s). Instance "+ASM", status READY, has 1 handler(s) for this service... Service "+ASM_DATADG" has 1 instance(s). Instance "+ASM", status READY, has 1 handler(s) for this service... Service "ORCL" has 1 instance(s). Instance "ORCL", status READY, has 1 handler(s) for this service... Service "ORCLXDB" has 1 instance(s). Instance "ORCL", status READY, has 1 handler(s) for this service... Service "f085620225d644e1e053166610ac1c27" has 1 instance(s). Instance "ORCL", status READY, has 1 handler(s) for this service... Service "orclpdb" has 1 instance(s). Instance "ORCL", status READY, has 1 handler(s) for this service... The command completed successfully
ARCHIVELOG 모드에서 Oracle 데이터베이스를 구성했는지 확인합니다. 데이터베이스가 다른 모드에서 실행되는 경우 다음과 같이 오류 코드 5556 메시지와 함께 실패한 작업이 표시될 수 있습니다.
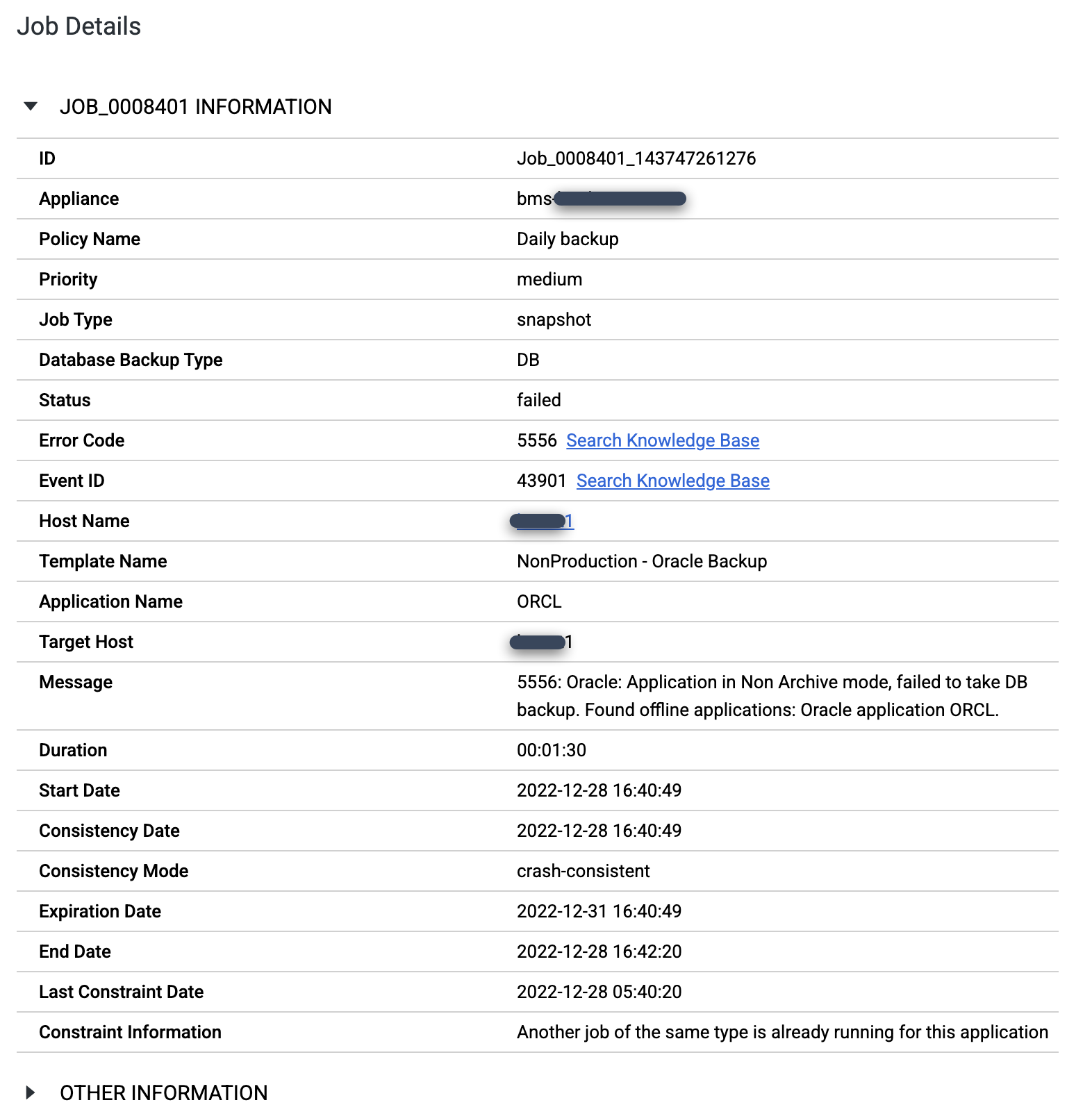
export ORACLE_HOME=ORACLE_HOME_PATH export ORACLE_SID=DATABASE_INSTANCE_NAME export PATH=$ORACLE_HOME/bin:$PATH sqlplus / as sysdba SQL> set tab off SQL> archive log list; Database log mode Archive Mode Automatic archival Enabled Archive destination +FRA Oldest online log sequence 569 Next log sequence to archive 570 Current log sequence 570
Oracle 데이터베이스에서 블록 변경 추적을 사용 설정합니다. 솔루션이 작동하는 데 꼭 필요한 것은 아니지만 블록 변경 추적을 사용 설정하면 변경된 블록을 계산하기 위해 상당한 후처리 작업을 수행할 필요가 없으며 백업 작업 시간을 줄이는 데 도움이 됩니다.
SQL> select status,filename from v$block_change_tracking; STATUS FILENAME ---------- ------------------------------------------------------------------ ENABLED +DATADG/ORCL/CHANGETRACKING/ctf.276.1124639617
데이터베이스가
spfile을 사용하는지 확인합니다.sqlplus / as sysdba SQL> show parameter spfile NAME TYPE VALUE ------------------ ----------- ------------ spfile string +DATA/ctdb/spfilectdb.ora
Oracle 데이터베이스 호스트용 Direct NFS(dnfs)를 사용 설정합니다. 필수는 아니지만 Oracle 데이터베이스를 백업 및 복원하는 가장 빠른 방법이 필요한 경우 dnfs를 선택하는 것이 좋습니다. 처리량을 더 개선하려면 호스트별로 스테이징 디스크를 변경하고 Oracle용 dnfs를 사용 설정하면 됩니다.
Oracle 데이터베이스 호스트용 확인을 위해 tnsname을 구성합니다. 이 설정을 포함하지 않으면 RMAN 명령어가 실패하는 경우가 많습니다. 다음은 출력 샘플입니다.
[oracle@test2 lib]$ tnsping ORCL TNS Ping Utility for Linux: Version 19.0.0.0.0 - Production on 29-DEC-2022 07:55:18 Copyright (c) 1997, 2021, Oracle. All rights reserved. Used parameter files: Used TNSNAMES adapter to resolve the alias Attempting to contact (DESCRIPTION = (ADDRESS = (PROTOCOL = TCP)(HOST = test2.localdomain)(PORT = 1521)) (CONNECT_DATA = (SERVER = DEDICATED) (SERVICE_NAME = ORCL))) OK (0 msec)
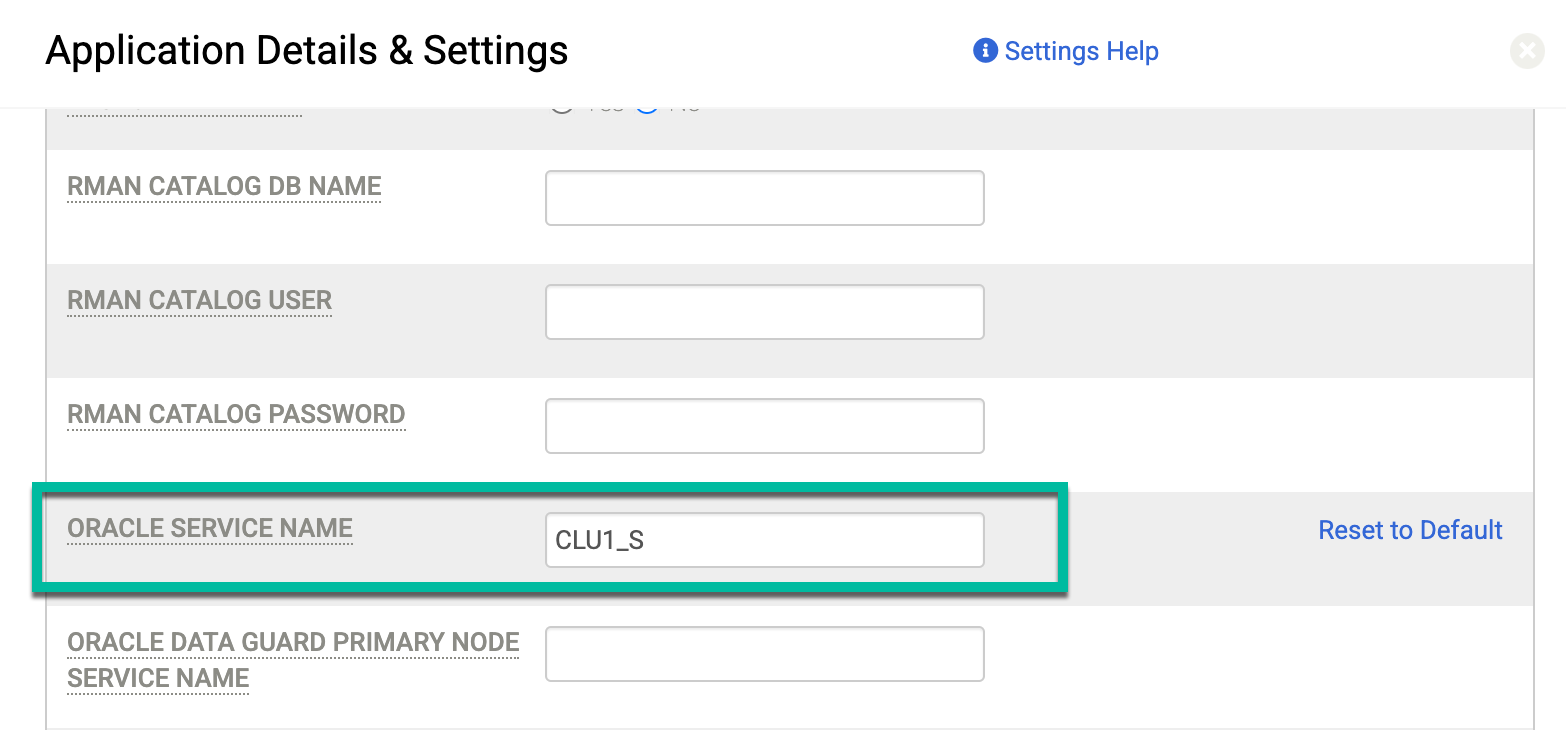
SERVICE_NAME필드는 RAC 구성에 중요합니다. 서비스 이름은 클러스터와 통신하는 외부 리소스에 시스템을 광고할 때 사용하는 별칭을 나타냅니다. 보호된 데이터베이스의 세부정보 및 설정 옵션에서 Oracle 서비스 이름용 고급 설정을 사용합니다. 백업 작업을 실행하는 노드에서 사용할 특정 서비스 이름을 입력합니다.Oracle 데이터베이스는 데이터베이스 인증을 위해서만 서비스 이름을 사용합니다. 데이터베이스가 OS 인증에 서비스 이름을 사용하지 않습니다. 예를 들어 데이터베이스 이름이 CLU1_S이고 인스턴스 이름이 CLU1_S일 수 있습니다.
Oracle 서비스 이름이 나열되지 않은 경우 다음 항목을 추가하여
$ORACLE_HOME/network/admin또는$GRID_HOME/network/admin에 있는 tnsnames.ora 파일의 서버에 서비스 이름 항목을 만듭니다.CLU1_S = (DESCRIPTION = (ADDRESS = (PROTOCOL = TCP)(HOST =
)(PORT = 1521)) (CONNECT_DATA = (SERVER = DEDICATED) (SERVICE_NAME = CLU1_S) ) ) tnsnames.ora 파일이 비표준 위치에 있는 경우 Oracle 데이터베이스용 애플리케이션 세부정보 및 설정 구성에 설명된 애플리케이션 세부정보 및 설정 페이지의 파일에 절대 경로를 제공합니다.
데이터베이스의 서비스 이름 항목을 올바르게 구성했는지 확인합니다. Oracle Linux에 로그인하고 Oracle 환경을 구성합니다.
TNS_ADMIN=TNSNAMES.ORA_FILE_LOCATION tnsping CLU1_S
데이터베이스 사용자 계정을 검토하여 백업 및 DR 애플리케이션에 대한 연결이 성공했는지 확인합니다.
sqlplus act_rman_user/act_rman_user@act_svc_dbstd as sysdba
Oracle 데이터베이스용 애플리케이션 세부정보 및 설정에 설명된 애플리케이션 세부정보 및 설정 페이지에서 Oracle 서비스 이름 필드에 만든 서비스 이름(CLU1_S)을 입력합니다.
오류 코드 870은 'NFS 스테이징 디스크에 ASM이 있는 ASM 백업은 지원되지 않음'이라고 표시됩니다. 이 오류가 발생하면 보호하려는 인스턴스에 대해 세부정보 및 설정에 올바른 설정이 구성되어 있지 않은 것입니다. 이 잘못된 구성에서 호스트는 스테이징 디스크에 NFS를 사용하지만 소스 데이터베이스는 ASM에서 실행됩니다.

이 문제를 해결하려면 ASM 형식을 파일 시스템 형식으로 변환 필드를 예로 설정합니다. 이 설정을 변경한 후 백업 작업을 다시 실행합니다.
오류 코드 15는 백업 및 DR 시스템이 '백업 호스트에 연결할 수 없음'을 알려줍니다. 이 오류가 발생하면 다음 3가지 문제 중 하나를 나타냅니다.
- 백업/복구 어플라이언스와 에이전트를 설치한 호스트 간의 방화벽에서 TCP 포트 5106(에이전트 수신 포트)을 허용하지 않습니다.
- 에이전트를 설치하지 않았습니다.
- 에이전트가 실행되고 있지 않습니다.
이 문제를 해결하려면 필요에 따라 방화벽 설정을 다시 구성하고 에이전트가 작동하는지 확인합니다. 근본 원인을 해결한 후
service udsagent status명령어를 실행합니다. 다음 출력 예는 백업 및 DR 에이전트 서비스가 올바르게 실행되고 있음을 보여줍니다.[root@test2 ~]# service udsagent status Redirecting to /bin/systemctl status udsagent.service udsagent.service - Google Cloud Backup and DR service Loaded: loaded (/usr/lib/systemd/system/udsagent.service; enabled; vendor preset: disabled) Active: active (running) since Wed 2022-12-28 05:05:45 UTC; 2 days ago Process: 46753 ExecStop=/act/initscripts/udsagent.init stop (code=exited, status=0/SUCCESS) Process: 46770 ExecStart=/act/initscripts/udsagent.init start (code=exited, status=0/SUCCESS) Main PID: 46789 (udsagent) Tasks: 8 (limit: 48851) Memory: 74.0M CGroup: /system.slice/udsagent.service ├─46789 /opt/act/bin/udsagent start └─60570 /opt/act/bin/udsagent start Dec 30 05:11:30 test2 su[150713]: pam_unix(su:session): session closed for user oracle Dec 30 05:11:30 test2 su[150778]: (to oracle) root on none
백업의 로그 메시지는 문제를 진단하는 데 도움이 될 수 있습니다. 백업 작업이 실행되는 소스 호스트의 로그에 액세스할 수 있습니다. Oracle 데이터베이스 백업의 경우
/var/act/log디렉터리에 두 개의 기본 로그 파일을 사용할 수 있습니다.- UDSAgent.log–API 요청, 작업 통계 실행, 기타 세부정보를 기록하는 Google Cloud 백업 및 DR 에이전트 로그
- SID_rman.log–모든 RMAN 명령어를 기록하는 Oracle RMAN 로그
추가 Oracle 고려사항
Oracle 데이터베이스용 백업 및 DR을 구현할 때는 Data Guard 및 RAC를 배포할 때 다음 고려 사항을 알고 있어야 합니다.
Data Guard 고려사항
기본 및 대기 Data Guard 노드를 모두 백업할 수 있습니다. 하지만 대기 노드에서만 데이터베이스를 보호하도록 선택한 경우에는 데이터베이스를 백업할 때 OS 인증이 아닌 Oracle 데이터베이스 인증을 사용해야 합니다.
RAC 고려사항
스테이징 디스크가 NFS 모드로 설정된 경우 백업 및 DR 솔루션은 RAC 데이터베이스의 여러 노드에서 동시 백업을 지원하지 않습니다. 시스템에 여러 RAC 노드의 동시 백업이 필요한 경우 블록(iSCSI)을 스테이징 디스크 모드로 사용하고 이를 호스트 단위로 설정합니다.
ASM을 사용하는 Oracle RAC 데이터베이스의 경우 공유 디스크에 스냅샷 제어 파일을 배치해야 합니다. 이 구성을 확인하려면 RMAN에 연결하고 show all 명령어를 실행합니다.
rman target / RMAN> show all
CONFIGURE RETENTION POLICY TO REDUNDANCY 1; # default CONFIGURE BACKUP OPTIMIZATION OFF; # default CONFIGURE DEFAULT DEVICE TYPE TO DISK; # default CONFIGURE CONTROLFILE AUTOBACKUP OFF; # default CONFIGURE CONTROLFILE AUTOBACKUP FORMAT FOR DEVICE TYPE DISK TO '%F'; # default CONFIGURE DEVICE TYPE DISK PARALLELISM 1 BACKUP TYPE TO BACKUPSET; # default CONFIGURE SNAPSHOT CONTROLFILE NAME TO '/mnt/ctdb/snapcf_ctdb.f';
RAC 환경에서는 스냅샷 제어 파일을 공유 ASM 디스크 그룹에 매핑해야 합니다. ASM 디스크 그룹에 파일을 할당하려면 Configure Snapshot Controlfile Name 명령어를 사용합니다.
CONFIGURE SNAPSHOT CONTROLFILE NAME TO '+/snap_ .f';
권장사항
요구사항에 따라 전체 솔루션에 영향을 미치는 특정 기능에 관해 결정을 내려야 할 수 있습니다. 일부 결정은 가격에 영향을 미칠 수 있으며, 이는 백업/복구 어플라이언스 스냅샷 풀에 표준 영구 디스크(pd-standard) 또는 성능 영구 디스크(pd-ssd)를 선택하는 것과 같이 성능에 영향을 줄 수 있습니다.
이 섹션에서는 Oracle 데이터베이스 백업 처리량에 최적의 성능을 보장하는 데 도움이 되는 권장사항을 공유합니다.
최적의 머신 유형 및 영구 디스크 유형 선택
파일 시스템 또는 데이터베이스와 같은 애플리케이션에서 백업/복구 어플라이언스를 사용할 때 호스트 인스턴스의 데이터가 Compute Engine 인스턴스 간에 전송되는 속도를 기준으로 성능을 측정할 수 있습니다.
- Compute Engine 영구 디스크 기기 속도는 머신 유형, 인스턴스에 연결된 총 메모리 양, 인스턴스의 vCPU 수의 3가지 요소를 기반으로 합니다.
- 인스턴스의 vCPU 수가 Compute Engine 인스턴스에 할당된 네트워크 속도를 결정합니다. 속도 범위는 공유 vCPU의 경우 1Gbps부터, 8개 이상의 vCPU의 경우 16Gbps까지입니다.
- 이러한 한도를 결합하여 Google Cloud 백업 및 DR은 기본적으로 백업/복구 어플라이언스의 표준 크기 머신 유형에 e2-standard-16을 사용합니다. 시작할 때 디스크 할당에 대해 선택할 수 있는 세 가지 옵션이 있습니다.
원하는 대로 선택 |
풀 디스크 |
최대 지속 쓰기 |
최대 지속 읽기 |
최소 |
10GB |
해당 사항 없음 |
해당 사항 없음 |
표준 |
4,096GB |
400MiB/s |
1200MiB/s |
SSD |
4,096GB |
1000MiB/s |
1200MiB/s |
Compute Engine 인스턴스는 연결된 영구 디스크에 I/O를 위해 할당된 네트워크의 최대 60%를 사용하고 다른 용도를 위해 40%를 남겨둡니다. 자세한 내용은 성능에 영향을 미치는 기타 요인을 참조하세요.
권장사항: e2-standard-16 머신 유형과 최소 4096GB의 PD-SSD를 선택하면 최고의 백업/복구 어플라이언스 성능을 얻을 수 있습니다. 두 번째 방법으로 백업/복구 어플라이언스에 n2-standard-16 머신 유형을 선택할 수 있습니다. 이 옵션을 사용하면 10~20%의 추가 성능 이점을 얻을 수 있지만 추가 비용이 발생합니다. 사용 사례와 일치하면 Cloud Customer Care에 문의하여 변경하세요.
스냅샷 최적화
단일 백업/복구 어플라이언스의 생산성을 높이기 위해 여러 소스에서 동시 스냅샷 작업을 실행할 수 있습니다. 각 개별 작업의 속도가 느려집니다. 그러나 작업 숫자가 충분하면 스냅샷 풀의 영구 디스크에 대한 지속적인 쓰기 한도를 달성할 수 있습니다.
스테이징 디스크에 iSCSI를 사용하면 단일 대규모 인스턴스를 백업/복구 어플라이언스에 백업할 수 있으며, 이때 쓰기 속도는 약 300~330MB/s로 유지됩니다. 테스트에서 스냅샷의 2TB~80TB 전체에서 동일하다는 것을 확인했습니다(소스 호스트와 백업/복구 어플라이언스가 모두 최적 크기로 구성되고 동일한 리전과 영역에 있다고 가정).
올바른 스테이징 디스크 선택
뛰어난 성능과 처리량이 필요한 경우, Oracle 데이터베이스 백업에 사용할 스테이징 디스크로 Direct NFS를 선택하면 iSCSI와 비교하여 상당한 이점이 부가될 수 있습니다. Direct NFS는 TCP 연결 수를 통합하여 확장성과 네트워크 성능을 향상시킵니다.
Oracle 데이터베이스에 Direct NFS를 사용 설정할 때는 충분한 소스 CPU를 구성하고(예: vCPU 8x개 및 RMAN 채널 8개) 베어메탈 솔루션 리전 확장 프로그램과 Google Cloud 간에 10GB 링크를 설정하여 700~900MB/s 이상으로 늘어난 처리량을 사용하여 단일 Oracle 데이터베이스를 백업할 수 있습니다. RMAN 복원 속도는 처리량 수준이 850MB/s 범위 이상에 도달하는 것을 확인할 수 있는 Direct NFS의 이점도 활용합니다.
비용과 처리량의 조화
모든 백업 데이터가 비용 절감을 위해 백업/복구 어플라이언스 스냅샷 풀에 압축된 형식으로 저장된다는 점을 이해하는 것도 중요합니다. 이 압축 이점에 대한 성능 오버헤드는 크지 않습니다. 그러나 암호화된 데이터(TDE) 또는 과도하게 압축된 데이터 세트의 경우 처리량 수치에는 미미한 영향을 미치지만 일부 값이 측정될 수 있습니다.
네트워크와 백업 서버의 성능에 영향을 미치는 요인 이해
다음 항목은 베어메탈 솔루션의 Oracle과 Google Cloud의 백업 서버 간의 네트워크 I/O에 영향을 줍니다.
플래시 스토리지
Google Cloud Persistent Disk와 마찬가지로 베어메탈 솔루션 시스템에 스토리지를 제공하는 플래시 스토리지 배열은 호스트에 할당하는 스토리지에 따라 I/O 기능을 증가시킵니다. 스토리지를 더 할당할수록 I/O가 향상됩니다. 일관된 결과를 얻으려면 최소 8TB의 플래시 스토리지를 프로비저닝하는 것이 좋습니다.
네트워크 지연 시간
Google Cloud 백업 및 DR 백업 작업은 베어메탈 솔루션 호스트와 Google Cloud의 백업/복구 어플라이언스 간의 네트워크 지연 시간에 민감합니다. 지연 시간이 조금만 늘어나도 백업 및 복원 시간이 크게 변경될 수 있습니다. Compute Engine 영역마다 베어메탈 솔루션 호스트에 제공되는 네트워크 지연 시간이 다릅니다. 백업/복구 어플라이언스를 최적으로 배치하기 위해 각 영역을 테스트하는 것이 좋습니다.
사용된 프로세서 수
베어메탈 솔루션 서버는 여러 가지 크기로 제공됩니다. 사용 가능한 CPU에 맞게 RMAN 채널을 확장하고 더 큰 시스템에서 더 빠른 속도를 사용하는 것이 좋습니다.
Cloud Interconnect
베어메탈 솔루션과 Google Cloud 간의 하이브리드 상호 연결은 5Gbps, 10Gbps, 2x10Gbps와 같은 여러 크기로 제공되며 듀얼 10GB 옵션에서 최대 성능을 발휘합니다. 백업 및 복원 작업에만 사용할 전용 상호 연결 링크를 구성할 수도 있습니다. 이 옵션은 백업 트래픽을 동일한 링크를 전달할 수 있는 데이터베이스 또는 애플리케이션 트래픽에서 격리하거나, 복구 지점 목표(RPO) 및 복구 시간 목표(RTO) 충족을 보장하기 위해 백업 및 복원 작업이 중요하므로 최대 대역폭을 보장하려는 고객에게 권장됩니다.
다음 단계
다음은 Google Cloud 백업 및 DR에 대한 유용한 추가 링크와 정보입니다.
- Google Cloud 백업 및 DR 설정에 대한 추가 단계는 백업 및 DR 제품 문서를 참조하세요.
- 제품 설치 및 기능 데모를 보려면 Google Cloud 백업 및 DR 동영상 재생목록을 참조하세요.
- Google Cloud 백업 및 DR의 호환성 정보를 보려면 지원 매트릭스: 백업 및 DR을 참조하세요. 지원되는 Linux 및 Oracle 데이터베이스 인스턴스 버전을 실행 중인지 확인하는 것이 중요합니다.
- Oracle 데이터베이스 보호와 관련된 추가 단계는 Oracle 데이터베이스용 백업 및 DR과 탐색된 Oracle 데이터베이스 보호를 참조하세요.
- NFS, CIFS, ext3, ext4와 같은 파일 시스템도 Google Cloud 백업 및 DR로 보호할 수 있습니다. 사용 가능한 옵션을 보려면 백업 계획을 적용하여 파일 시스템 보호를 참고하세요.
- Google Cloud 백업 및 DR에 대한 알림을 사용 설정하려면 로그 기반 알림 구성을 참조하고 Google Cloud 백업 및 DR 알림 설정 동영상을 시청하세요.
- 지원 케이스를 열려면 Cloud Customer Care에 문의하세요.