Questa pagina descrive come utilizzare AutoML Tables per addestrare un modello personalizzato basato su del set di dati. Devi già avere ha creato un set di dati e vi ha importato i dati.
Introduzione
Puoi creare un modello personalizzato addestrandolo con un modello set di dati. AutoML Tables utilizza gli elementi del set di dati per addestrare il modello, testarlo e valutarne le prestazioni. Puoi esaminare i risultati, modificare set di dati di addestramento in base alle esigenze e addestra un nuovo modello utilizzando il set di dati migliorato.
Nell'ambito della preparazione all'addestramento di un modello, aggiorni le informazioni sullo schema del set di dati. Questi aggiornamenti dello schema influiscono su qualsiasi modello futuro che utilizza quel set di dati. I modelli che hanno già iniziato l'addestramento non sono interessati.
L'addestramento di un modello può richiedere diverse ore. Puoi controllare l'addestramento l'avanzamento nella console Google Cloud oppure utilizzando API Cloud AutoML.
Poiché AutoML Tables crea un nuovo modello a ogni avvio dell'addestramento, il tuo progetto può includere numerosi modelli. Puoi ottenere un dei modelli in il tuo progetto e puoi eliminare i modelli che non ti servono più.
I modelli devono essere riaddestrati ogni sei mesi in modo che possano continuare a essere pubblicati per le previsioni.
Addestramento di un modello
Console
Se necessario, apri la pagina Set di dati e fai clic sul set di dati che ti interessa. per l'utilizzo.
Il set di dati viene aperto nella scheda Addestra.

Seleziona la colonna target per il tuo modello.
Si tratta del valore che il modello è addestrato a prevedere. Il tipo di dati determina se il modello risultante è una regressione (numerica) o una di classificazione (categorica). Scopri di più.
Se la colonna target ha un tipo di dati Categorico, deve avere almeno due e non più di 500 valori distinti.
Esamina Tipo di dati, Nullabilità e le statistiche dei dati per ciascuna colonna nel tuo set di dati.
Puoi fare clic sulle singole colonne per visualizzarne i dettagli. Scopri di più sulla revisione dello schema.
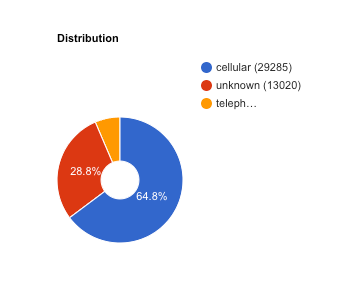
Se vuoi controllare la suddivisione dati, fai clic su Modifica parametri aggiuntivi. e specificare una colonna di suddivisione dati o una colonna Data/ora. Scopri di più.
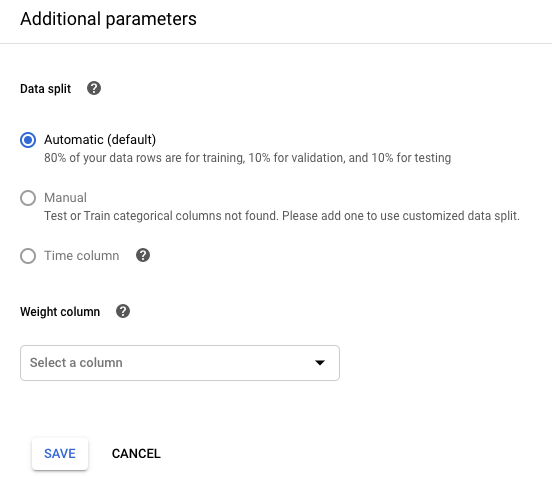
Se vuoi ponderare gli esempi di addestramento in base al valore di una colonna, fai clic su Modifica parametri aggiuntivi e specifica la colonna appropriata. Scopri di più.
Esamina le statistiche e i dettagli riepilogativi per assicurarti che la qualità dei dati sia quello che ti aspetti e che tu abbia identificato eventuali colonne che devono essere esclusi quando crei il modello.
Per ulteriori informazioni, consulta Analisi dei dati di addestramento.
Quando lo schema del set di dati ti soddisfa, fai clic su Addestra modello nella nella parte superiore dello schermo.
Quando apporti modifiche allo schema, AutoML Tables aggiorna il statistiche di riepilogo, il cui completamento può richiedere alcuni istanti. Non devi attendere il completamento di questo processo prima di avviare l'addestramento del modello.

In Budget per l'addestramento, inserisci il numero massimo di ore di formazione per questo modello.
Il budget per l'addestramento è compreso tra 1 e 72 ore. Questo è l'importo massimo di tempo per l'addestramento che ti verranno addebitati.
Il tempo di addestramento suggerito è correlato alla dimensione dei dati di addestramento. La la seguente tabella mostra gli intervalli di tempo di addestramento suggeriti in base al numero di righe; un numero elevato di colonne aumenta anche il tempo di addestramento.
Righe Tempo di addestramento suggerito Meno di 100.000 1-3 ore 100.000 - 1.000.000 1-6 ore 1.000.000 - 10.000.000 1-12 ore Più di 10.000.000 3-24 ore La creazione del modello include altre attività oltre all'addestramento, quindi il tempo totale necessario per creare il modello è più lungo del tempo di addestramento. Ad esempio, se specifichi 2 ore di addestramento, potrebbero comunque essere necessarie 3 o più ore pronto per il deployment. Ti vengono addebitati solo i costi relativi al tempo effettivo di addestramento.
Scopri di più sui prezzi dell'addestramento.
Se AutoML Tables rileva che il modello non migliora più prima di esaurire il budget interrompe l'addestramento. Se vuoi utilizza tutto il tempo previsto per la formazione, apri Opzioni avanzate e disattiva l'opzione Interruzione anticipata.
Nella sezione Selezione delle caratteristiche di input, escludi le colonne che vuoi target per l'esclusione nel passaggio di analisi dello schema.
Se non vuoi utilizzare l'obiettivo di ottimizzazione predefinito, apri Opzioni avanzate e seleziona la metrica che preferisci. AutoML Tables da ottimizzare per l'addestramento del modello. Scopri di più.
A seconda del tipo di dati della colonna target, potrebbero essere presenti una scelta per l'obiettivo Ottimizzazione.
Fai clic su Addestra modello per iniziare l'addestramento del modello.
L'addestramento di un modello può richiedere diverse ore a seconda delle dimensioni il set di dati e il budget per l'addestramento. Puoi chiudere la finestra del browser senza influire sul processo di addestramento.
Al termine dell'addestramento del modello, la scheda Modelli mostra le metriche per il modello, come precisione e richiamo.
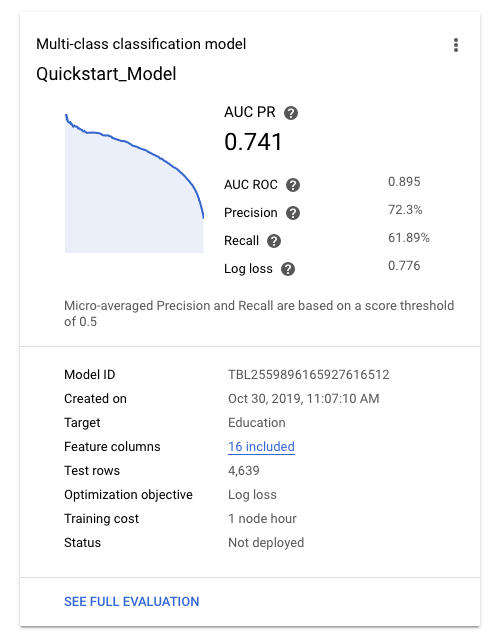
Per assistenza nella valutazione della qualità del modello, consulta Valutazione dei modelli.
REST
L'esempio seguente mostra come rivedere e aggiornare lo schema dei dati prima di addestrare il modello.
Se le tue risorse si trovano nella regione dell'UE, utilizza eu per {location}
e utilizzare l'endpoint eu-automl.googleapis.com. Altrimenti, usa us-central1.
Scopri di più.
Al termine dell'importazione, elenca le specifiche della tabella per ottenere l'ID tabella.
Prima di utilizzare i dati della richiesta, effettua le seguenti sostituzioni:
-
endpoint:
automl.googleapis.comper la località globale eeu-automl.googleapis.comper la regione UE. - project-id: l'ID del tuo progetto Google Cloud.
- location: la località della risorsa:
us-central1per tutto il mondo oeuper l'Unione europea. -
dataset-id: l'ID del set di dati. Ad esempio:
TBL6543.
Metodo HTTP e URL:
GET https://endpoint/v1beta1/projects/project-id/locations/location/datasets/dataset-id/tableSpecs/
Per inviare la richiesta, espandi una delle seguenti opzioni:
L'ID tabella è mostrato in grassetto nel campo
name.-
endpoint:
Elenca le specifiche della colonna.
Prima di utilizzare i dati della richiesta, effettua le seguenti sostituzioni:
-
endpoint:
automl.googleapis.comper la località globale eeu-automl.googleapis.comper la regione UE. - project-id: l'ID del tuo progetto Google Cloud.
- location: la località della risorsa:
us-central1per tutto il mondo oeuper l'Unione europea. -
dataset-id: l'ID del set di dati. Ad esempio:
TBL6543. - table-id: l'ID della tabella.
Metodo HTTP e URL:
GET https://endpoint/v1beta1/projects/project-id/locations/location/datasets/dataset-id/tableSpecs/table-id/columnSpecs/
Per inviare la richiesta, espandi una delle seguenti opzioni:
-
endpoint:
(Facoltativo) Configura la colonna di destinazione.
Si tratta del valore che il modello è addestrato a prevedere. Il tipo di dati determina se il modello risultante è una regressione (numerica) o una di classificazione (categorica). Scopri di più.
Se la colonna target ha un tipo di dati Categorico, deve avere almeno due e non più di 500 valori distinti.
Puoi anche specificare la colonna di destinazione quando addestri il modello. Se di farlo, mantieni l'ID tabella e l'ID colonna target desiderato per un secondo momento per gli utilizzi odierni.
Prima di utilizzare i dati della richiesta, effettua le seguenti sostituzioni:
-
endpoint:
automl.googleapis.comper la località globale eeu-automl.googleapis.comper la regione UE. - project-id: l'ID del tuo progetto Google Cloud.
- location: la località della risorsa:
us-central1per tutto il mondo oeuper l'Unione europea. - dataset-id: l'ID del set di dati.
- target-column-id: l'ID della colonna target.
Metodo HTTP e URL:
PATCH https://endpoint/v1beta1/projects/project-id/locations/location/datasets/dataset-id
Corpo JSON della richiesta:
{ "tablesDatasetMetadata": { "targetColumnSpecId": "target-column-id" } }Per inviare la richiesta, espandi una delle seguenti opzioni:
-
endpoint:
Se vuoi, aggiorna il campo
mlUseColumnSpecIdper specificare suddivisione dati e il campoweightColumnSpecIdper utilizzare una colonna peso.Prima di utilizzare i dati della richiesta, effettua le seguenti sostituzioni:
-
endpoint:
automl.googleapis.comper la località globale eeu-automl.googleapis.comper la regione UE. - project-id: l'ID del tuo progetto Google Cloud.
- location: la località della risorsa:
us-central1per tutto il mondo oeuper l'Unione europea. - dataset-id: l'ID del set di dati.
- split-column-id: l'ID della colonna target.
- weight-column-id: l'ID della colonna target.
Metodo HTTP e URL:
PATCH https://endpoint/v1beta1/projects/project-id/locations/location/datasets/dataset-id
Corpo JSON della richiesta:
{ "tablesDatasetMetadata": { "mlUseColumnSpecId": "split-column-id", "weightColumnSpecId": "weight-column-id" } }Per inviare la richiesta, espandi una delle seguenti opzioni:
-
endpoint:
Controlla le statistiche della colonna per verificare che i valori di
dataTypesiano corretti. e le colonne abbiano il valore corretto pernullable.Se un campo è contrassegnato come non null, significa che non ha valori null per il valore set di dati di addestramento. Assicurati che sia vero per i dati di previsione beh, se una colonna è contrassegnata come non nullable e non viene fornito un valore per quest'ultima viene restituito un errore di previsione per la riga in questione.
Controlla la qualità dei dati.
Addestrare il modello.
Prima di utilizzare i dati della richiesta, effettua le seguenti sostituzioni:
-
endpoint:
automl.googleapis.comper la località globale eeu-automl.googleapis.comper la regione UE. - project-id: l'ID del tuo progetto Google Cloud.
- location: la località della risorsa:
us-central1per tutto il mondo oeuper l'Unione europea. - dataset-id: l'ID del set di dati.
- table-id: l'ID tabella utilizzato per impostare la colonna di destinazione.
- target-column-id: l'ID della colonna di destinazione.
- model-display-name: il nome visualizzato del nuovo modello.
-
(Facoltativo) optimization-objective con la metrica da ottimizzare.
Consulta Informazioni sugli obiettivi di ottimizzazione del modello.
-
train-budget-milli-node-hours con il numero di milli-nodi di ore per l'addestramento. Ad esempio, 1000 = 1 ora.
Il tempo di addestramento suggerito è correlato alla dimensione dei dati di addestramento. La la seguente tabella mostra gli intervalli di tempo di addestramento suggeriti in base al numero di righe; un numero elevato di colonne aumenta anche il tempo di addestramento.
Righe Tempo di addestramento suggerito Meno di 100.000 1-3 ore 100.000 - 1.000.000 1-6 ore 1.000.000 - 10.000.000 1-12 ore Più di 10.000.000 3-24 ore La creazione del modello include altre attività oltre all'addestramento, quindi il tempo totale necessario per creare il modello è più lungo del tempo di addestramento. Ad esempio, se specifichi 2 ore di addestramento, potrebbero comunque essere necessarie 3 o più ore pronto per il deployment. Ti vengono addebitati solo i costi relativi al tempo effettivo di addestramento.
Scopri di più sui prezzi dell'addestramento.
Se AutoML Tables rileva che il modello non migliora più prima di esaurire il budget interrompe l'addestramento. Se vuoi utilizza tutto il tempo previsto per l'addestramento, imposta
disableEarlyStoppingnell'oggettotablesModelMetadataatrue.
Metodo HTTP e URL:
POST https://endpoint/v1beta1/projects/project-id/locations/location/models/
Corpo JSON della richiesta:
{ "datasetId": "dataset-id", "displayName": "model-display-name", "tablesModelMetadata": { "trainBudgetMilliNodeHours": "train-budget-milli-node-hours", "optimizationObjective": "optimization-objective", "targetColumnSpec": { "name": "projects/project-id/locations/location/datasets/dataset-id/tableSpecs/table-id/columnSpecs/target-column-id" } }, }Per inviare la richiesta, espandi una delle seguenti opzioni:
Dovresti ricevere una risposta JSON simile alla seguente:
{ "name": "projects/292381/locations/us-central1/operations/TBL64984", "metadata": { "@type": "type.googleapis.com/google.cloud.automl.v1beta1.OperationMetadata", "createTime": "2019-12-30T22:12:03.014058Z", "updateTime": "2019-12-30T22:12:03.014058Z", "cancellable": true, "createModelDetails": { "modelDisplayName": "new_model1" }, "worksOn": [ "projects/292381/locations/us-central1/datasets/TBL3718" ], "state": "RUNNING" } }L'addestramento di un modello è un'operazione a lunga esecuzione. Puoi eseguire il polling per verificare lo stato dell'operazione o attendere che venga eseguita per tornare indietro. Scopri di più.
-
endpoint:
Java
Se le risorse si trovano nella regione dell'UE, devi impostare esplicitamente l'endpoint. Scopri di più.
Node.js
Se le risorse si trovano nella regione dell'UE, devi impostare esplicitamente l'endpoint. Scopri di più.
Python
La libreria client per AutoML Tables include ulteriori metodi Python che semplificano l'utilizzo l'API AutoML Tables. Questi metodi fanno riferimento a set di dati e modelli per nome anziché per ID. Il tuo i nomi dei set di dati e dei modelli devono essere univoci. Per ulteriori informazioni, consulta Riferimento del cliente.
Se le risorse si trovano nella regione dell'UE, devi impostare esplicitamente l'endpoint. Scopri di più.
Revisione dello schema
AutoML Tables deduce il tipo di dati e se una colonna può essere impostata su null per ogni colonna in base al tipo di dati originale (se è stato importato BigQuery) e i valori nella colonna. Devi controllare ogni colonna e assicurati che sia corretta.
Utilizza il seguente elenco per esaminare lo schema:
I campi che contengono testo in formato libero devono essere di tipo Testo.
I campi di testo sono separati in token UnicodeScriptTokenizer, con i singoli token utilizzati per durante l'addestramento del modello. UnicodeScriptTokenizer tokenizza il testo per spazio vuoto, e allo stesso tempo separa la punteggiatura dal testo e le diverse lingue tra loro.
Se il valore di una colonna fa parte di un insieme finito di valori, probabilmente categorica, indipendentemente dal tipo di dati utilizzato nel campo.
Ad esempio, potresti avere codici per i colori: 1 = rosso, 2 = giallo e così via. deve assicurarsi che tale campo sia stato designato come Categorico.
Un'eccezione a queste indicazioni è il caso in cui la colonna contenga stringhe composte da più parole. In questo caso, devi impostarla come colonna Testo, anche se ha una bassa cardinalità. AutoML Tables tokenizza le colonne di testo e potrebbe essere essere in grado di ricavare indicatori di previsione dai singoli token o dal loro ordine.
Se un campo è contrassegnato come non null, significa che non ha valori null per il valore set di dati di addestramento. Assicurati che sia vero per i dati di previsione beh, se una colonna è contrassegnata come non nullable e non viene fornito un valore per quest'ultima viene restituito un errore di previsione per la riga in questione.
analisi dei dati di addestramento
Se una colonna ha un'alta percentuale di valori mancanti, assicurati che sia previsto e non a causa di un problema di raccolta dei dati.
Assicurati che il numero di valori non validi sia relativamente basso o pari a zero.
Tutte le righe che contengono uno o più valori non validi vengono escluse automaticamente per l'addestramento del modello.
Se Valori distinti per una colonna categorica si avvicina al numero di righe (ad esempio, più del 90%), la colonna non fornirà molto segnale di addestramento. Deve essere escluso dall'addestramento. Le colonne ID devono essere sempre escluse.
Se il valore Correlazione con il target di una colonna è elevato, assicurati che sia previsto e non è un'indicazione della perdita di obiettivo.
Se la colonna è disponibile quando richiedi previsioni, è probabilmente una caratteristica con un forte potere esplicativo e può essere inclusa. Tuttavia, a volte le caratteristiche con un'alta correlazione in realtà derivano da il target o raccolto dopo l'evento. Queste funzionalità devono essere escluse dalla perché non sono disponibili al momento della previsione, quindi il modello è inutilizzabile in produzione.
La correlazione viene calcolata per le colonne categoriche, numeriche e timestamp, utilizzando V di Cramer. Per come colonne numeriche, questo valore viene calcolato utilizzando i conteggi dei bucket generati dai quantili.
Informazioni sugli obiettivi di ottimizzazione del modello
L'obiettivo dell'ottimizzazione influisce sul modo in cui il modello viene addestrato, pertanto come si comporta in produzione. La tabella seguente fornisce alcuni dettagli per quali tipi di problemi è più adatto ciascun obiettivo:
| Obiettivo ottimizzazione | Tipo di problema | Valore API | Usa questo scopo se vuoi... |
|---|---|---|---|
| AUC ROC | Classificazione | MAXIMIZE_AU_ROC |
Fai distinzione tra le classi. Valore predefinito per la classificazione binaria. |
| Perdita logaritmica | Classificazione | MINIMIZE_LOG_LOSS |
Mantieni le probabilità di previsione il più precise possibile. Solo obiettivo supportato per la classificazione multiclasse. |
| AUC PR | Classificazione | MAXIMIZE_AU_PRC |
Ottimizza i risultati per le previsioni per la classe meno comune. |
| Precisione al richiamo | Classificazione | MAXIMIZE_PRECISION_AT_RECALL |
Ottimizza la precisione in base a un valore di richiamo specifico. |
| Richiamo alla precisione | Classificazione | MAXIMIZE_RECALL_AT_PRECISION |
Ottimizza il richiamo in base a un valore di precisione specifico. |
| RMSE | Regressione | MINIMIZE_RMSE |
Acquisisci con accuratezza i valori più estremi. |
| MAE | Regressione | MINIMIZE_MAE |
Visualizza i valori estremi come outlier con un minore impatto sul modello. |
| RMSLE | Regressione | MINIMIZE_RMSLE |
Penalizza l'errore sulla dimensione relativa anziché sul valore assoluto. Utile in particolar modo quando i valori previsti ed effettivi possono essere molto grandi. |
Passaggi successivi
- Esaminare l'architettura del modello.
- Valuta il modello.
- Ottieni previsioni batch dal modello.
- Ottieni previsioni online dal modello.
- Esporta il modello.
- Scopri di più sull'utilizzo delle operazioni a lunga esecuzione.