Questa pagina descrive come fornire più righe di dati ad AutoML Tables contemporaneamente e ricevere una previsione per ogni riga.
Introduzione
Dopo aver creato (addestrato) un modello, puoi effettuare una richiesta asincrona per un batch di previsioni utilizzando il metodo batchPredict. Fornisci i dati di input al metodo batchPredict in formato tabella.
Ogni riga fornisce valori per le caratteristiche
che il modello ha addestrato a utilizzare.
Il metodo batchPredict invia questi dati al modello e restituisce
le previsioni per ogni riga di dati.
I modelli devono essere riaddestrati ogni sei mesi per poter continuare a fornire previsioni.
Richiesta di una previsione batch
Per le previsioni batch, devi specificare un'origine dati e una destinazione dei risultati in una tabella BigQuery o un file CSV in Cloud Storage. Non è necessario utilizzare la stessa tecnologia per l'origine e la destinazione. Ad esempio, puoi utilizzare BigQuery per l'origine dati e un file CSV in Cloud Storage per la destinazione dei risultati. Segui i passaggi appropriati delle due attività di seguito a seconda delle tue esigenze.
L'origine dati deve contenere dati tabulari che includono tutte le colonne utilizzate per addestrare il modello. Puoi includere colonne che non erano presenti nei dati di addestramento o che erano nei dati di addestramento, ma escluse dall'utilizzo per l'addestramento. Queste colonne aggiuntive sono incluse nell'output della previsione, ma non vengono utilizzate per generare la previsione.
Utilizzo delle tabelle BigQuery
I nomi delle colonne e i tipi di dati dei dati di input devono corrispondere ai dati utilizzati nei dati di addestramento. Le colonne possono avere un ordine diverso rispetto ai dati di addestramento.
Requisiti delle tabelle BigQuery
- Le tabelle delle origini dati BigQuery non devono superare i 100 GB.
- Devi utilizzare un set di dati BigQuery multiregionale nelle località
USoEU. - Se la tabella si trova in un progetto diverso, devi fornire il ruolo
BigQuery Data Editorall'account di servizio AutoML Tables nel progetto. Scopri di più.
Richiesta della previsione batch
Console
Vai alla pagina AutoML Tables nella console Google Cloud.
Seleziona Modelli e apri il modello che vuoi utilizzare.
Seleziona la scheda Testa e utilizza.
Fai clic su Previsione batch.
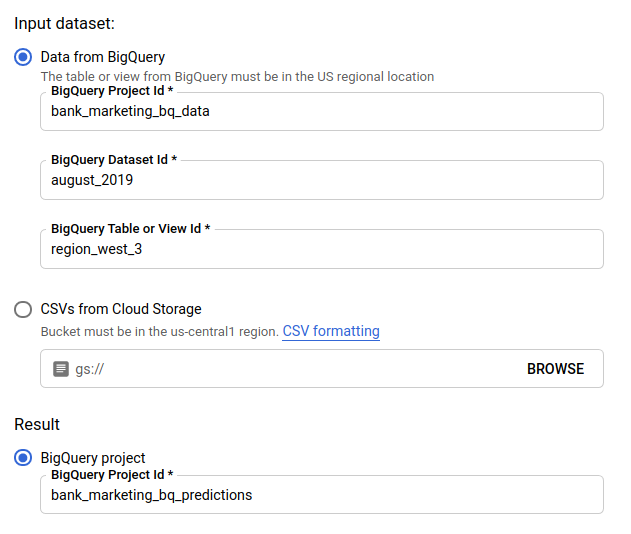
Per Set di dati di input, seleziona Tabella di BigQuery e fornisci il progetto, il set di dati e gli ID tabella per l'origine dati.
In Risultato, seleziona Progetto BigQuery e fornisci l'ID progetto per la destinazione dei risultati.
Se vuoi vedere in che modo ogni caratteristica ha influito sulla previsione, seleziona Genera importanza delle caratteristiche.
La generazione dell'importanza delle caratteristiche aumenta il tempo e le risorse di calcolo necessari per la previsione. L'importanza delle caratteristiche locali non è disponibile con una destinazione dei risultati di Cloud Storage.
Fai clic su Invia previsione batch per richiedere la previsione batch.
REST
Per richiedere previsioni batch, utilizza il metodo models.batchPredict.
Prima di utilizzare i dati della richiesta, effettua le seguenti sostituzioni:
-
endpoint:
automl.googleapis.comper la località globale eeu-automl.googleapis.comper la regione dell'UE. - project-id: il tuo ID progetto Google Cloud.
- location: la località per la risorsa:
us-central1per Globale oeuper l'Unione Europea. - model-id: l'ID del modello. Ad esempio,
TBL543. - dataset-id: l'ID del set di dati BigQuery in cui si trovano i dati di previsione.
-
table-id: l'ID della tabella BigQuery in cui si trovano i dati di previsione.
AutoML Tables crea una sottocartella per i risultati della previsione denominata
prediction-<model_name>-<timestamp>in project-id.dataset-id.table-id.
Metodo HTTP e URL:
POST https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id:batchPredict
Corpo JSON della richiesta:
{
"inputConfig": {
"bigquerySource": {
"inputUri": "bq://project-id.dataset-id.table-id"
},
},
"outputConfig": {
"bigqueryDestination": {
"outputUri": "bq://project-id"
},
},
}
Per inviare la richiesta, scegli una delle seguenti opzioni:
arricciatura
Salva il corpo della richiesta in un file denominato request.json ed esegui questo comando:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "x-goog-user-project: project-id" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id:batchPredict"
PowerShell
Salva il corpo della richiesta in un file denominato request.json ed esegui questo comando:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred"; "x-goog-user-project" = "project-id" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id:batchPredict" | Select-Object -Expand Content
Per ottenere l'importanza delle caratteristiche locali, aggiungi il parametro feature_importance
ai dati della richiesta. Per saperne di più, consulta
Importanza delle caratteristiche locali.
Java
Se le risorse si trovano nella regione dell'UE, devi impostare esplicitamente l'endpoint. Scopri di più.
Node.js
Se le risorse si trovano nella regione dell'UE, devi impostare esplicitamente l'endpoint. Scopri di più.
Python
La libreria client per AutoML Tables include metodi Python aggiuntivi che semplificano l'utilizzo dell'API AutoML Tables. Questi metodi fanno riferimento a set di dati e modelli per nome anziché per ID. I nomi dei set di dati e dei modelli devono essere univoci. Per maggiori informazioni, consulta la documentazione di riferimento per i client.
Se le risorse si trovano nella regione dell'UE, devi impostare esplicitamente l'endpoint. Scopri di più.
Utilizzo dei file CSV in Cloud Storage
I nomi delle colonne e i tipi di dati dei dati di input devono corrispondere ai dati utilizzati nei dati di addestramento. Le colonne possono avere un ordine diverso rispetto ai dati di addestramento.
Requisiti dei file CSV
- La prima riga dell'origine dati deve contenere il nome delle colonne.
Ogni file dell'origine dati non deve essere più grande di 10 GB.
Puoi includere più file, fino a un massimo di 100 GB.
Il bucket Cloud Storage deve essere conforme ai requisiti dei bucket.
Se il bucket Cloud Storage si trova in un progetto diverso da quello in cui utilizzi AutoML Tables, devi fornire il ruolo
Storage Object Creatorall'account di servizio AutoML Tables nel progetto. Scopri di più.
Console
Vai alla pagina AutoML Tables nella console Google Cloud.
Seleziona Modelli e apri il modello che vuoi utilizzare.
Seleziona la scheda Testa e utilizza.
Fai clic su Previsione batch.
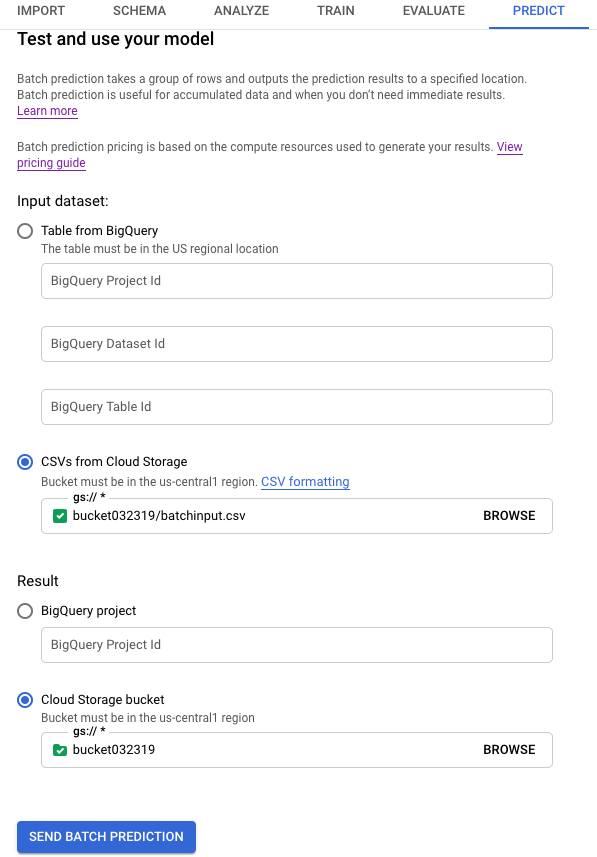
Per Set di dati di input, seleziona CSV da Cloud Storage e fornisci l'URI del bucket per l'origine dati.
In Risultato, seleziona Bucket Cloud Storage e fornisci l'URI del bucket per il bucket di destinazione.
Se vuoi vedere in che modo ogni caratteristica ha influito sulla previsione, seleziona Genera importanza delle caratteristiche.
La generazione dell'importanza delle caratteristiche aumenta il tempo e le risorse di calcolo necessari per la previsione. L'importanza delle caratteristiche locali non è disponibile con una destinazione dei risultati di Cloud Storage.
Fai clic su Invia previsione batch per richiedere la previsione batch.
REST
Per richiedere previsioni batch, utilizza il metodo models.batchPredict.
Prima di utilizzare i dati della richiesta, effettua le seguenti sostituzioni:
-
endpoint:
automl.googleapis.comper la località globale eeu-automl.googleapis.comper la regione dell'UE. - project-id: il tuo ID progetto Google Cloud.
- location: la località per la risorsa:
us-central1per Globale oeuper l'Unione Europea. - model-id: l'ID del modello. Ad esempio,
TBL543. - input-bucket-name: il nome del bucket Cloud Storage in cui si trovano i dati di previsione.
- input-directory-name: il nome della directory Cloud Storage in cui si trovano i dati di previsione.
- object-name: il nome dell'oggetto Cloud Storage in cui si trovano i dati di previsione.
- output-bucket-name: il nome del bucket Cloud Storage per i risultati della previsione.
-
output-directory-name: il nome della directory Cloud Storage per i risultati della previsione.
AutoML Tables crea una sottocartella per i risultati della previsione denominata
prediction-<model_name>-<timestamp>ings://output-bucket-name/output-directory-name. Devi disporre delle autorizzazioni di scrittura per questo percorso.
Metodo HTTP e URL:
POST https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id:batchPredict
Corpo JSON della richiesta:
{
"inputConfig": {
"gcsSource": {
"inputUris": [
"gs://input-bucket-name/input-directory-name/object-name.csv"
]
},
},
"outputConfig": {
"gcsDestination": {
"outputUriPrefix": "gs://output-bucket-name/output-directory-name"
},
},
}
Per inviare la richiesta, scegli una delle seguenti opzioni:
arricciatura
Salva il corpo della richiesta in un file denominato request.json ed esegui questo comando:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "x-goog-user-project: project-id" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id:batchPredict"
PowerShell
Salva il corpo della richiesta in un file denominato request.json ed esegui questo comando:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred"; "x-goog-user-project" = "project-id" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id:batchPredict" | Select-Object -Expand Content
Per ottenere l'importanza delle caratteristiche locali, aggiungi il parametro feature_importance
ai dati della richiesta. Per saperne di più, consulta
Importanza delle caratteristiche locali.
Java
Se le risorse si trovano nella regione dell'UE, devi impostare esplicitamente l'endpoint. Scopri di più.
Node.js
Se le risorse si trovano nella regione dell'UE, devi impostare esplicitamente l'endpoint. Scopri di più.
Python
La libreria client per AutoML Tables include metodi Python aggiuntivi che semplificano l'utilizzo dell'API AutoML Tables. Questi metodi fanno riferimento a set di dati e modelli per nome anziché per ID. I nomi dei set di dati e dei modelli devono essere univoci. Per maggiori informazioni, consulta la documentazione di riferimento per i client.
Se le risorse si trovano nella regione dell'UE, devi impostare esplicitamente l'endpoint. Scopri di più.
Recupero dei risultati
Recupero dei risultati della previsione in BigQuery
Se hai specificato BigQuery come destinazione di output, i risultati della richiesta di previsione batch vengono restituiti come nuovo set di dati nel progetto BigQuery specificato. Il set di dati BigQuery è il nome del modello, preceduto da "prediction_" e dal timestamp con l'inizio del job di previsione. Puoi trovare il nome del set di dati BigQuery in Previsioni recenti nella pagina Previsione batch della scheda Testa e utilizza del modello.
Il set di dati BigQuery contiene due tabelle: predictions e errors. La tabella errors contiene una riga per ogni riga nella richiesta di previsione
per la quale AutoML Tables non hanno potuto restituire una previsione (ad esempio,
se una caratteristica che non supporta valori null è null). La tabella predictions contiene una riga per ogni previsione restituita.
Nella tabella predictions, AutoML Tables restituisce i dati di previsione
e crea una nuova colonna per i risultati della previsione
anteponendo "predicted_" al nome della colonna di destinazione. La colonna dei risultati della previsione contiene una struttura BigQuery nidificata che contiene i risultati della previsione.
Per recuperare i risultati della previsione, puoi utilizzare una query nella console di BigQuery. Il formato della query dipende dal tipo di modello.
Classificazione binaria:
SELECT predicted_<target-column-name>[OFFSET(0)].tables AS value_1, predicted_<target-column-name>[OFFSET(1)].tables AS value_2 FROM <bq-dataset-name>.predictions
"value_1" e "value_2" sono indicatori di luogo, che puoi sostituire con i valori target o un valore equivalente.
Classificazione multiclasse:
SELECT predicted_<target-column-name>[OFFSET(0)].tables AS value_1, predicted_<target-column-name>[OFFSET(1)].tables AS value_2, predicted_<target-column-name>[OFFSET(2)].tables AS value_3, ... predicted_<target-column-name>[OFFSET(4)].tables AS value_5 FROM <bq-dataset-name>.predictions
"value_1", "value_2" e così via sono indicatori di luogo, puoi sostiturli con i valori target o un equivalente.
Regressione:
SELECT predicted_<target-column-name>[OFFSET(0)].tables.value, predicted_<target-column-name>[OFFSET(0)].tables.prediction_interval.start, predicted_<target-column-name>[OFFSET(0)].tables.prediction_interval.end FROM <bq-dataset-name>.predictions
Recupero dei risultati in Cloud Storage
Se hai specificato Cloud Storage come destinazione di output, i risultati della richiesta di previsione batch vengono restituiti come file CSV in una nuova cartella nel bucket specificato. Il nome della cartella è il nome del modello, preceduto da "prediction-" e dal timestamp con l'inizio del job di previsione. Puoi trovare il nome della cartella Cloud Storage in Previsioni recenti nella parte inferiore della pagina Previsione batch della scheda Test e utilizzo del tuo modello.
La cartella Cloud Storage contiene due tipi di file: file di errore e file di previsione. Se i risultati sono di grandi dimensioni, vengono creati file aggiuntivi.
I file di errore sono denominati errors_1.csv, errors_2.csv e così via. Contengono una riga di intestazione e una riga per ogni riga nella richiesta di previsione per cui AutoML Tables non ha restituito una previsione.
I file di previsione sono denominati tables_1.csv, tables_2.csv e così via. Contengono una riga di intestazione con i nomi delle colonne e una riga per ogni previsione restituita.
Nei file di previsione, AutoML Tables restituisce i dati di previsione e crea una o più nuove colonne per i risultati delle previsioni, a seconda del tipo di modello:
Classificazione:
Per ogni valore potenziale della colonna di destinazione, ai risultati viene aggiunta una colonna denominata <target-column-name>_<value>_score. Questa colonna contiene il punteggio o la stima di confidenza per quel valore.
Regressione:
Il valore previsto per quella riga viene restituito in una colonna denominata predicted_<target-column-name>. L'intervallo di previsione non viene restituito per
l'output CSV.
L'importanza delle caratteristiche locali non è disponibile per i risultati in Cloud Storage.
Interpretazione dei risultati
Il modo in cui interpreti i risultati dipende dai problemi aziendali che stai risolvendo e dalla modalità di distribuzione dei dati.
Interpretazione dei risultati per i modelli di classificazione
I risultati della previsione per i modelli di classificazione (binari e multi-classe) restituiscono un punteggio di probabilità per ogni valore potenziale della colonna di destinazione. Devi decidere come vuoi utilizzare i punteggi. Ad esempio, per ottenere una classificazione binaria dai punteggi forniti, devi identificare un valore soglia. Se esistono due classi, "A" e "B", devi classificare l'esempio come "A" se il punteggio per "A" è maggiore della soglia scelta e "B" in caso contrario. Per i set di dati sbilanciati, la soglia potrebbe ri avvicinarsi al 100% o allo 0%.
Puoi utilizzare il grafico della curva del richiamo della precisione, il grafico della curva degli operatori del ricevitore e altre statistiche pertinenti per etichetta nella pagina Valuta del tuo modello nella console Google Cloud per vedere come la modifica della soglia modifica le metriche di valutazione. Questo può aiutarti a determinare il modo migliore per utilizzare i valori dei punteggi per interpretare i risultati delle previsioni.
Interpretazione dei risultati per i modelli di regressione
Per i modelli di regressione, viene restituito un valore previsto che puoi utilizzare direttamente in caso di molti problemi. Puoi anche utilizzare l'intervallo di previsione, se viene restituito e se un intervallo ha senso per il tuo problema aziendale.
Interpretazione dei risultati relativi all'importanza delle caratteristiche locali
Per informazioni su come interpretare i risultati relativi all'importanza delle caratteristiche locali, consulta Importanza delle caratteristiche locali.
Passaggi successivi
- Scopri di più sull'importanza delle caratteristiche locali.
- Scopri di più sulle operazioni a lunga esecuzione.