This page describes how you can use feature importance to gain visibility into how the model makes its predictions.
For more information about AI Explanations, see Introduction to AI Explanations for AI Platform.
Introduction
When you use a machine learning model to make business decisions, it's important to understand how your training data contributed to the final model, and how the model arrived at individual predictions. This understanding helps you ensure that your model is fair and accurate.
AutoML Tables provides feature importance, sometimes called feature attributions, which enables you to see which features contributed the most to model training (model feature importance) and individual predictions (local feature importance).
AutoML Tables computes feature importance using the Sampled Shapley method. For more information about model explainability, see Introduction to AI Explanations.
Model feature importance
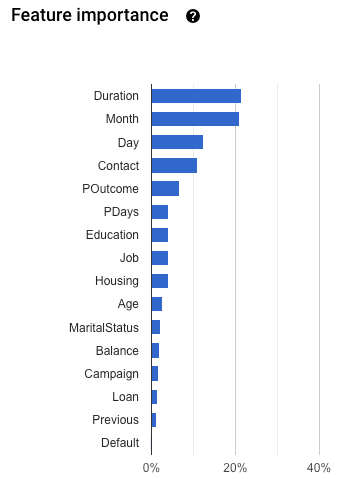
Model feature importance helps you ensure that the features that informed model training make sense for your data and business problem. All of the features with a high feature importance value should represent a valid signal for prediction, and be able to be consistently included in your prediction requests.
Model feature importance is provided as a percentage for each feature: the higher the percentage, the more strongly that feature impacted model training.
Getting model feature importance
Console
To see your model's feature importance values using the Google Cloud console:
Go to the AutoML Tables page in the Google Cloud console.
Select the Models tab in the left navigation pane, and select the model you want to get the evaluation metrics for.
Open the Evaluate tab.
Scroll down to see the Feature importance graph.
REST
To get the feature importance values for a model, you use the model.get method.
Before using any of the request data, make the following replacements:
-
endpoint:
automl.googleapis.comfor the global location, andeu-automl.googleapis.comfor the EU region. - project-id: your Google Cloud project ID.
- location: the location for the resource:
us-central1for Global oreufor the European Union. -
model-id: the ID of the model you want get the feature importance information for.
For example,
TBL543.
HTTP method and URL:
GET https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id
To send your request, choose one of these options:
curl
Execute the following command:
curl -X GET \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "x-goog-user-project: project-id" \
"https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id"
PowerShell
Execute the following command:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred"; "x-goog-user-project" = "project-id" }
Invoke-WebRequest `
-Method GET `
-Headers $headers `
-Uri "https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id" | Select-Object -Expand Content
{
"name": "projects/292381/locations/us-central1/models/TBL543",
"displayName": "Quickstart_Model",
...
"tablesModelMetadata": {
"targetColumnSpec": {
...
},
"inputFeatureColumnSpecs": [
...
],
"optimizationObjective": "MAXIMIZE_AU_ROC",
"tablesModelColumnInfo": [
{
"columnSpecName": "projects/292381/locations/us-central1/datasets/TBL543/tableSpecs/246/columnSpecs/331",
"columnDisplayName": "Contact",
"featureImportance": 0.093201876
},
{
"columnSpecName": "projects/292381/locations/us-central1/datasets/TBL543/tableSpecs/246/columnSpecs/638",
"columnDisplayName": "Month",
"featureImportance": 0.215029223
},
...
],
"trainBudgetMilliNodeHours": "1000",
"trainCostMilliNodeHours": "1000",
"classificationType": "BINARY",
"predictionSampleRows": [
...
],
"splitPercentageConfig": {
...
}
},
"creationState": "CREATED",
"deployedModelSizeBytes": "1160941568"
}
Java
If your resources are located in the EU region, you must explicitly set the endpoint. Learn more.
Node.js
If your resources are located in the EU region, you must explicitly set the endpoint. Learn more.
Python
The client library for AutoML Tables includes additional Python methods that simplify using the AutoML Tables API. These methods refer to datasets and models by name instead of id. Your dataset and model names must be unique. For more information, see the Client reference.
If your resources are located in the EU region, you must explicitly set the endpoint. Learn more.
Local feature importance
Local feature importance gives you visibility into how the individual features in a specific prediction request affected the resulting prediction.
To arrive at each local feature importance value, first the baseline prediction score is calculated. Baseline values are computed from the training data, using the median value for numeric features and the mode for categorical features. The prediction generated from the baseline values is the baseline prediction score.
For classification models, the local feature importance tells you how much each feature added to or subtracted from the probability assigned to the class with the highest score, as compared with the baseline prediction score. Score values are between 0.0 and 1.0, so local feature importance for classification models is always between -1.0 and 1.0 (inclusive).
For regression models, the local feature importance for a prediction tells you how much each feature added to or subtracted from the result as compared with the baseline prediction score.
Local feature importance is available for both online and batch predictions.
Getting local feature importance for online predictions
Console
To get local feature importance values for an online prediction using the Google Cloud console, follow the steps in Getting an online prediction, making sure you check the Generate feature importance checkbox.
REST
To get local feature importance for an online prediction request, you use
the model.predict method, setting
the feature_importance parameter to true.
Before using any of the request data, make the following replacements:
-
endpoint:
automl.googleapis.comfor the global location, andeu-automl.googleapis.comfor the EU region. - project-id: your Google Cloud project ID.
- location: the location for the resource:
us-central1for Global oreufor the European Union. - model-id: the ID of the model. For example,
TBL543. - valueN: the values for each column, in the correct order.
HTTP method and URL:
POST https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id:predict
Request JSON body:
{
"payload": {
"row": {
"values": [
value1, value2,...
]
}
}
"params": {
"feature_importance": "true"
}
}
To send your request, choose one of these options:
curl
Save the request body in a file named request.json,
and execute the following command:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "x-goog-user-project: project-id" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id:predict"
PowerShell
Save the request body in a file named request.json,
and execute the following command:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred"; "x-goog-user-project" = "project-id" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id:predict" | Select-Object -Expand Content
"tablesModelColumnInfo": [
{
"columnSpecName": "projects/2381/locations/us-central1/datasets/TBL8440/tableSpecs/766336/columnSpecs/4704",
"columnDisplayName": "Promo",
"featureImportance": 1626.5464
},
{
"columnSpecName": "projects/2381/locations/us-central1/datasets/TBL8440/tableSpecs/766336/columnSpecs/6800",
"columnDisplayName": "Open",
"featureImportance": -7496.5405
},
{
"columnSpecName": "projects/2381/locations/us-central1/datasets/TBL8440/tableSpecs/766336/columnSpecs/9824",
"columnDisplayName": "StateHoliday"
}
],
When a column has a feature importance value of 0, feature importance is not displayed for that column.
Java
If your resources are located in the EU region, you must explicitly set the endpoint. Learn more.
Node.js
If your resources are located in the EU region, you must explicitly set the endpoint. Learn more.
Python
The client library for AutoML Tables includes additional Python methods that simplify using the AutoML Tables API. These methods refer to datasets and models by name instead of id. Your dataset and model names must be unique. For more information, see the Client reference.
If your resources are located in the EU region, you must explicitly set the endpoint. Learn more.
Getting local feature importance for batch predictions
Console
To get local feature importance values for a batch prediction using the Google Cloud console, follow the steps in Requesting a batch prediction, making sure you check the Generate feature importance checkbox.

Feature importance is returned by adding a new column for every feature,
named feature_importance.<feature_name>.
REST
To get local feature importance for a batch prediction request, you use
the model.batchPredict method, setting
the feature_importance parameter to true.
The following example uses BigQuery for the request data and the results; you use the same additional parameter for requests using Cloud Storage.
Before using any of the request data, make the following replacements:
-
endpoint:
automl.googleapis.comfor the global location, andeu-automl.googleapis.comfor the EU region. - project-id: your Google Cloud project ID.
- location: the location for the resource:
us-central1for Global oreufor the European Union. - model-id: the ID of the model. For example,
TBL543. - dataset-id: the ID of the BigQuery dataset where the prediction data is located.
-
table-id: the ID of the BigQuery table where the prediction data is located.
AutoML Tables creates a subfolder for the prediction results named
prediction-<model_name>-<timestamp>in project-id.dataset-id.table-id.
HTTP method and URL:
POST https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id:batchPredict
Request JSON body:
{
"inputConfig": {
"bigquerySource": {
"inputUri": "bq://project-id.dataset-id.table-id"
},
},
"outputConfig": {
"bigqueryDestination": {
"outputUri": "bq://project-id"
},
},
"params": {"feature_importance": "true"}
}
To send your request, choose one of these options:
curl
Save the request body in a file named request.json,
and execute the following command:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "x-goog-user-project: project-id" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id:batchPredict"
PowerShell
Save the request body in a file named request.json,
and execute the following command:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred"; "x-goog-user-project" = "project-id" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id:batchPredict" | Select-Object -Expand Content
Feature importance is returned by adding a new column for every feature,
named feature_importance.<feature_name>.
Considerations for using local feature importance:
Local feature importance results are available only for models trained on or after 15 November, 2019.
Enabling local feature importance on a batch prediction request with more than 1,000,000 rows or 300 columns is not supported.
Each local feature importance value shows only how much the feature affected the prediction for that row. To understand the overall behavior of the model, use model feature importance.
Local feature importance values are always relative to the baseline value. Make sure you reference the baseline value when you are evaluating your local feature importance results. The baseline value is available only from the Google Cloud console.
The local feature importance values depend entirely on the model and data used to train the model. They can tell only the patterns the model found in the data, and can't detect any fundamental relationships in the data. So, the presence of a high feature importance for a certain feature does not demonstrate a relationship between that feature and the target; it merely shows that the model is using the feature in its predictions.
If a prediction includes data that falls completely outside of the range of the training data, local feature importance might not provide meaningful results.
Generating feature importance increases the time and compute resources required for your prediction. In addition, your request uses a different quota than for prediction requests without feature importance. Learn more.
Feature importance values alone do not tell you if your model is fair, unbiased, or of sound quality. You should carefully evaluate your training dataset, procedure, and evaluation metrics, in addition to feature importance.