Arquitetura
O diagrama seguinte mostra a arquitetura de alto nível de um pipeline de extração, carregamento e transformação (ELT) sem servidor através dos Workflows.

No diagrama anterior, considere uma plataforma de retalho que recolhe periodicamente eventos de vendas como ficheiros de várias lojas e, em seguida, escreve os ficheiros num contentor do Cloud Storage. Os eventos são usados para fornecer métricas empresariais através da importação e do processamento no BigQuery. Esta arquitetura oferece um sistema de orquestração fiável e sem servidor para importar os seus ficheiros para o BigQuery e está dividida nos dois módulos seguintes:
- Lista de ficheiros: mantém a lista de ficheiros não processados adicionados a um contentor do Cloud Storage numa coleção do Firestore.
Este módulo funciona através de uma função do Cloud Run acionada por um evento de armazenamento Object Finalize, que é gerado quando um novo ficheiro é adicionado ao contentor do Cloud Storage. O nome do ficheiro é anexado à matriz da coleção denominada
newno Firestore.files Fluxo de trabalho: executa os fluxos de trabalho agendados. O Cloud Scheduler aciona um fluxo de trabalho que executa uma série de passos de acordo com uma sintaxe baseada em YAML para orquestrar o carregamento e, em seguida, transformar os dados no BigQuery chamando funções do Cloud Run. Os passos no fluxo de trabalho chamam funções do Cloud Run para executar as seguintes tarefas:
- Crie e inicie uma tarefa de carregamento do BigQuery.
- Verifique o estado da tarefa de carregamento.
- Crie e inicie a tarefa de consulta de transformação.
- Verifique o estado da tarefa de transformação.
A utilização de transações para manter a lista de novos ficheiros no Firestore ajuda a garantir que nenhum ficheiro é ignorado quando um fluxo de trabalho os importa para o BigQuery. As execuções separadas do fluxo de trabalho são tornadas idempotentes através do armazenamento do estado e dos metadados das tarefas no Firestore.
Objetivos
- Crie uma base de dados do Firestore.
- Configure um acionador de função do Cloud Run para acompanhar os ficheiros adicionados ao contentor do Cloud Storage no Firestore.
- Implemente funções do Cloud Run para executar e monitorizar tarefas do BigQuery.
- Implemente e execute um fluxo de trabalho para automatizar o processo.
Custos
Neste documento, usa os seguintes componentes faturáveis do Google Cloud:
Para gerar uma estimativa de custos com base na sua utilização projetada,
use a calculadora de preços.
Quando terminar as tarefas descritas neste documento, pode evitar a faturação contínua eliminando os recursos que criou. Para mais informações, consulte o artigo Limpe.
Antes de começar
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Cloud Build, Cloud Run functions, Identity and Access Management, Resource Manager, and Workflows APIs.
Aceda à página Boas-vindas e tome nota do ID do projeto para usar num passo posterior.
In the Google Cloud console, activate Cloud Shell.
Prepare o seu ambiente
Para preparar o seu ambiente, crie uma base de dados do Firestore, clone os exemplos de código do repositório do GitHub, crie recursos com o Terraform, edite o ficheiro YAML dos fluxos de trabalho e instale os requisitos para o gerador de ficheiros.
Para criar uma base de dados do Firestore, faça o seguinte:
Na Google Cloud consola, aceda à página do Firestore.
Clique em Selecionar modo nativo.
No menu Selecionar uma localização, selecione a região onde quer alojar a base de dados do Firestore. Recomendamos que escolha uma região próxima da sua localização física.
Clique em Criar base de dados.
No Cloud Shell, clone o repositório de origem:
cd $HOME && git clone https://github.com/GoogleCloudPlatform/workflows-demos cd workflows-demos/workflows-bigquery-loadNo Cloud Shell, crie os seguintes recursos com o Terraform:
terraform init terraform apply \ -var project_id=PROJECT_ID \ -var region=REGION \ -var zone=ZONE \ --auto-approveSubstitua o seguinte:
PROJECT_ID: o ID do seu Google Cloud projetoREGION: uma localização geográfica Google Cloud específica para alojar os seus recursos, por exemplo,us-central1ZONE: uma localização numa região para alojar os seus recursos, por exemplo,us-central1-b
Deverá ver uma mensagem semelhante à seguinte:
Apply complete! Resources: 7 added, 0 changed, 1 destroyed.O Terraform pode ajudar a criar, alterar e atualizar a infraestrutura em grande escala de forma segura e previsível. Os seguintes recursos são criados no seu projeto:
- Contas de serviço com os privilégios necessários para garantir o acesso seguro aos seus recursos.
- Um conjunto de dados do BigQuery denominado
serverless_elt_datasete uma tabela denominadaword_countpara carregar os ficheiros recebidos. - Um contentor do Cloud Storage com o nome
${project_id}-ordersbucketpara preparar ficheiros de entrada. - As cinco funções do Cloud Run seguintes:
- O
file_add_handleradiciona o nome dos ficheiros que são adicionados ao contentor do Cloud Storage à coleção do Firestore. create_jobcria uma nova tarefa de carregamento do BigQuery e associa ficheiros na coleção do Firebase à tarefa.create_querycria uma nova tarefa de consulta do BigQuery.poll_bigquery_jobrecebe o estado de uma tarefa do BigQuery.run_bigquery_jobinicia uma tarefa do BigQuery.
- O
Obtenha os URLs das funções do
create_job,create_query,poll_joberun_bigquery_jobdo Cloud Run que implementou no passo anterior.gcloud functions describe create_job | grep url gcloud functions describe poll_bigquery_job | grep url gcloud functions describe run_bigquery_job | grep url gcloud functions describe create_query | grep url
O resultado é semelhante ao seguinte:
url: https://REGION-PROJECT_ID.cloudfunctions.net/create_job url: https://REGION-PROJECT_ID.cloudfunctions.net/poll_bigquery_job url: https://REGION-PROJECT_ID.cloudfunctions.net/run_bigquery_job url: https://REGION-PROJECT_ID.cloudfunctions.net/create_query
Tome nota destes URLs, uma vez que são necessários quando implementar o fluxo de trabalho.
Crie e implemente um fluxo de trabalho
No Cloud Shell, abra o ficheiro de origem do fluxo de trabalho,
workflow.yaml:Substitua o seguinte:
CREATE_JOB_URL: o URL da função para criar uma nova tarefaPOLL_BIGQUERY_JOB_URL: o URL da função para sondar o estado de uma tarefa em execuçãoRUN_BIGQUERY_JOB_URL: o URL da função para iniciar uma tarefa de carregamento do BigQueryCREATE_QUERY_URL: o URL da função para iniciar uma tarefa de consulta do BigQueryBQ_REGION: a região do BigQuery onde os dados são armazenados, por exemplo,USBQ_DATASET_TABLE_NAME: o nome da tabela do conjunto de dados do BigQuery no formatoPROJECT_ID.serverless_elt_dataset.word_count
Implemente o ficheiro
workflow:gcloud workflows deploy WORKFLOW_NAME \ --location=WORKFLOW_REGION \ --description='WORKFLOW_DESCRIPTION' \ --service-account=workflow-runner@PROJECT_ID.iam.gserviceaccount.com \ --source=workflow.yamlSubstitua o seguinte:
WORKFLOW_NAME: o nome exclusivo do fluxo de trabalhoWORKFLOW_REGION: a região na qual o fluxo de trabalho é implementado, por exemplo,us-central1WORKFLOW_DESCRIPTION: a descrição do fluxo de trabalho
Crie um ambiente virtual do Python 3 e instale os requisitos para o gerador de ficheiros:
sudo apt-get install -y python3-venv python3 -m venv env . env/bin/activate cd generator pip install -r requirements.txt
Gere ficheiros para importar
O script
gen.pyPython gera conteúdo aleatório no formato Avro. O esquema é igual ao da tabelaword_countdo BigQuery. Estes ficheiros Avro são copiados para o contentor do Cloud Storage especificado.No Cloud Shell, gere os ficheiros:
python gen.py -p PROJECT_ID \ -o PROJECT_ID-ordersbucket \ -n RECORDS_PER_FILE \ -f NUM_FILES \ -x FILE_PREFIXSubstitua o seguinte:
RECORDS_PER_FILE: o número de registos num único ficheiroNUM_FILES: o número total de ficheiros a carregarFILE_PREFIX: o prefixo dos nomes dos ficheiros gerados
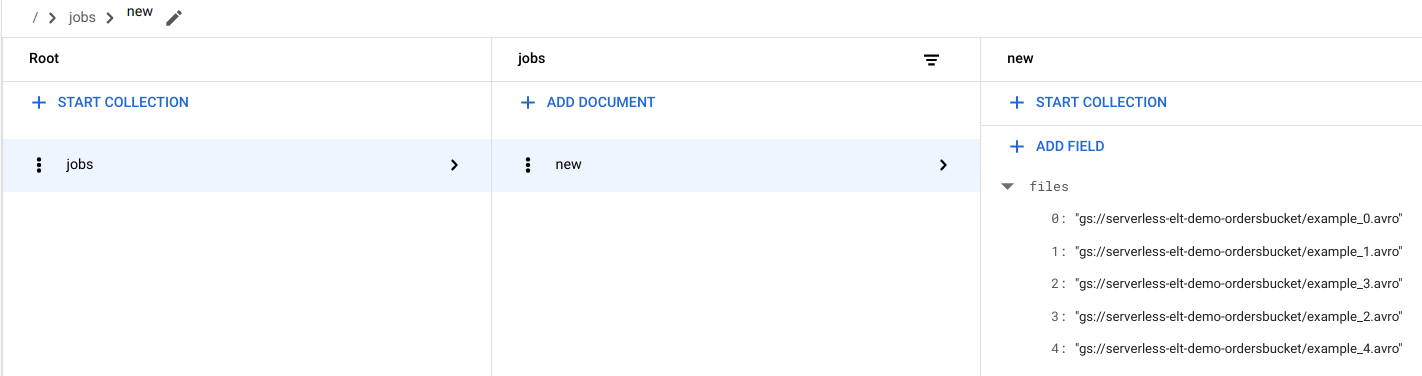
Veja entradas de ficheiros no Firestore
Quando os ficheiros são copiados para o Cloud Storage, a função do Cloud Run é acionada.
handle_new_fileEsta função adiciona a lista de ficheiros à matriz de listas de ficheiros no documentonewna coleçãojobsdo Firestore.Para ver a lista de ficheiros, na Google Cloud consola, aceda à página Dados do Firestore.
Acione o fluxo de trabalho
Os fluxos de trabalho associam uma série de tarefas sem servidor a partir dos serviços Google Cloud e API. Os passos individuais neste fluxo de trabalho são executados como funções do Cloud Run e o estado é armazenado no Firestore. Todas as chamadas para as funções do Cloud Run são autenticadas através da conta de serviço do fluxo de trabalho.
No Cloud Shell, execute o fluxo de trabalho:
gcloud workflows execute WORKFLOW_NAME
O diagrama seguinte mostra os passos usados no fluxo de trabalho:

O fluxo de trabalho está dividido em duas partes: o fluxo de trabalho principal e o fluxo de trabalho secundário. O fluxo de trabalho principal processa a criação de tarefas e a execução condicional, enquanto o subfluxo de trabalho executa uma tarefa do BigQuery. O fluxo de trabalho realiza as seguintes operações:
- A função do
create_jobCloud Run cria um novo objeto de tarefa, obtém a lista de ficheiros adicionados ao Cloud Storage a partir do documento do Firestore e associa os ficheiros à tarefa de carregamento. Se não existirem ficheiros para carregar, a função não cria uma nova tarefa. - A função do
create_queryCloud Run recebe a consulta que tem de ser executada, juntamente com a região do BigQuery na qual a consulta deve ser executada. A função cria a tarefa no Firestore e devolve o ID da tarefa. - A função do
run_bigquery_jobCloud Run recebe o ID da tarefa que tem de ser executada e, em seguida, chama a API BigQuery para enviar a tarefa. - Em vez de aguardar a conclusão da tarefa na função do Cloud Run, pode sondar periodicamente o estado da tarefa.
- A função
poll_bigquery_jobCloud Run fornece o estado da tarefa. É chamado repetidamente até que a tarefa seja concluída. - Para adicionar um atraso entre as chamadas à função do Cloud Run, é chamada uma
sleeprotina a partir dos fluxos de trabalho.poll_bigquery_job
- A função
Veja o estado da tarefa
Pode ver a lista de ficheiros e o estado da tarefa.
NaGoogle Cloud consola, aceda à página Dados do Firestore.
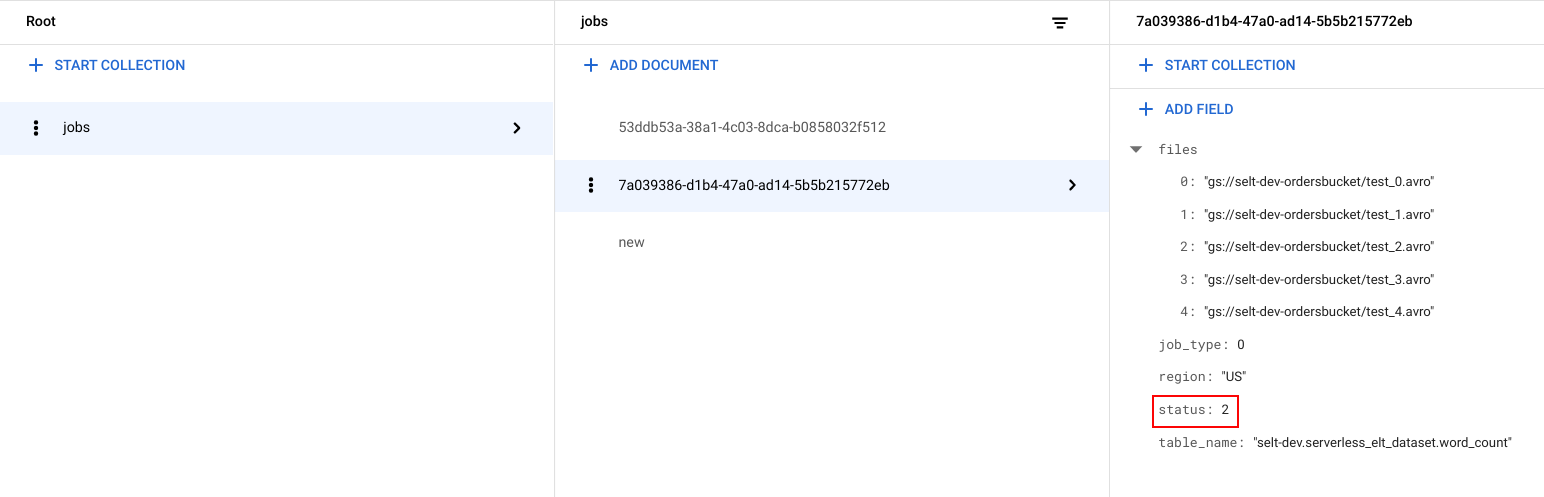
É gerado um identificador exclusivo (UUID) para cada tarefa. Para ver o
job_typee ostatus, clique no ID da tarefa. Cada tarefa pode ter um dos seguintes tipos e estados:job_type: o tipo de tarefa que está a ser executada pelo fluxo de trabalho com um dos seguintes valores:- 0: Carregue dados para o BigQuery.
- 1: execute uma consulta no BigQuery.
status: o estado atual da tarefa com um dos seguintes valores:- 0: a tarefa foi criada, mas não iniciada.
- 1: O trabalho está em execução.
- 2: O trabalho concluiu a execução com êxito.
- 3: Ocorreu um erro e a tarefa não foi concluída com êxito.
O objeto de tarefa também contém atributos de metadados, como a região do conjunto de dados do BigQuery, o nome da tabela do BigQuery e, se for uma tarefa de consulta, a string de consulta que está a ser executada.
Ver dados no BigQuery
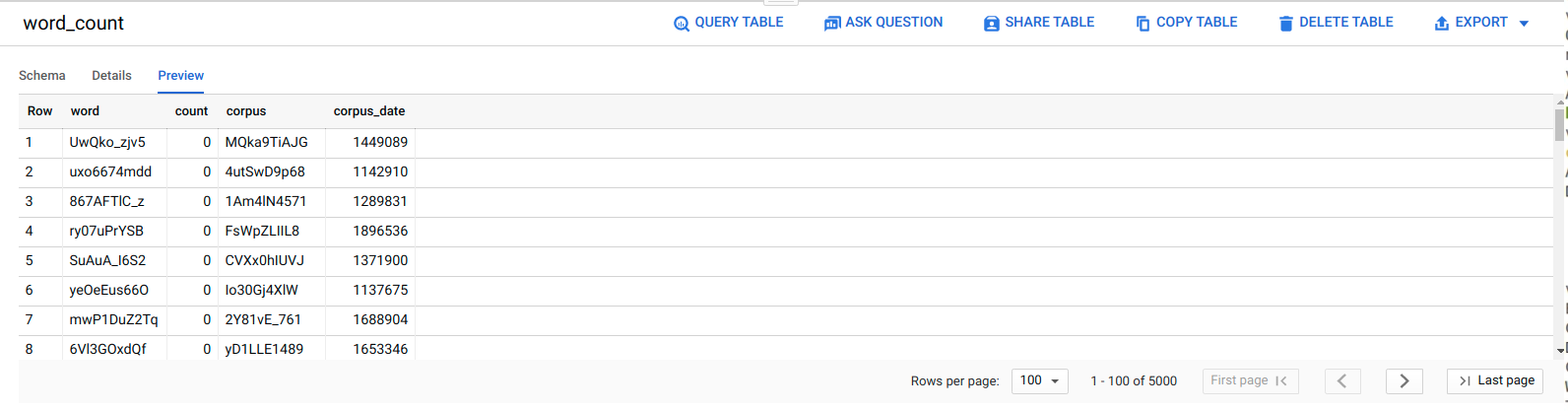
Para confirmar que a tarefa de ELT foi bem-sucedida, verifique se os dados aparecem na tabela.
Na Google Cloud consola, aceda à página do editor do BigQuery.
Clique na tabela
serverless_elt_dataset.word_count.Clique no separador Pré-visualizar.
Agende o fluxo de trabalho
Para executar periodicamente o fluxo de trabalho de acordo com uma programação, pode usar o Cloud Scheduler.
Limpar
A forma mais fácil de eliminar a faturação é eliminar o Google Cloud projeto que criou para o tutorial. Em alternativa, pode eliminar os recursos individuais.Elimine os recursos individuais
No Cloud Shell, remova todos os recursos criados com o Terraform:
cd $HOME/bigquery-workflows-load terraform destroy \ -var project_id=PROJECT_ID \ -var region=REGION \ -var zone=ZONE \ --auto-approve
Na Google Cloud consola, aceda à página Dados do Firestore.
Junto a Empregos, clique em Menu e selecione Eliminar.
Elimine o projeto
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
O que se segue?
- Para saber mais acerca do BigQuery, consulte a documentação do BigQuery.
- Saiba como criar pipelines de aprendizagem automática personalizados sem servidor.
- Para ver mais arquiteturas de referência, diagramas e práticas recomendadas, explore o Centro de arquitetura na nuvem.