이 문서는 Google Cloud에서 AI Platform을 사용하여 고객평생가치(CLV)를 예측하는 방법을 설명하는 4부로 구성된 시리즈 중 세 번째 문서입니다.
이 시리즈의 문서는 다음과 같습니다.
- 1부: 소개. CLV를 설명하고 CLV 예측을 위한 두 가지 모델링 기법을 소개합니다.
- 2부: 모델 학습. 데이터를 준비하고 모델을 학습시키는 방법을 설명합니다.
- 3부: 프로덕션에 배포(이 문서). 2부에서 설명된 모델을 프로덕션 시스템에 배포하는 방법을 설명합니다.
- 4부: AutoML Tables 사용. AutoML Tables를 사용하여 모델을 빌드 및 배포하는 방법을 설명합니다.
코드 설치
이 문서에 설명된 절차를 따르려면 GitHub에서 샘플 코드를 설치해야 합니다.
gcloud CLI가 설치되었으면 컴퓨터에서 터미널 창을 열어 이 명령어를 실행합니다. gcloud CLI가 설치되지 않았으면 Cloud Shell 인스턴스를 엽니다.
샘플 코드 저장소를 클론합니다.
git clone https://github.com/GoogleCloudPlatform/tensorflow-lifetime-value
README 파일의 설치 및 자동화 섹션에 있는 설치 안내에 따라 환경을 설정하고 솔루션 구성요소를 배포합니다. 여기에는 예시 데이터 세트와 Cloud Composer 환경이 포함됩니다.
다음 섹션의 예시 명령어는 이 두 단계를 모두 완료했다고 가정합니다.
설치 안내에 따라 README 파일의 설정 섹션에 설명된 대로 사용자 환경의 변수를 설정합니다.
지리적으로 가장 가까운 Google Cloud 리전에 맞게 REGION 변수를 변경합니다. 리전 목록은 리전 및 영역을 참고하세요.
아키텍처 및 구현
다음 다이어그램은 이 논의에서 사용되는 아키텍처를 보여 줍니다.

아키텍처는 다음 기능으로 나뉩니다.
- 데이터 수집: 데이터를 BigQuery로 가져옵니다.
- 데이터 준비: 모델이 사용할 수 있도록 원시 데이터를 변환합니다.
- 모델 학습: 예측 실행에 사용할 수 있도록 모델을 빌드하고 학습시키고 미세 조정합니다.
- 예측 제공: 오프라인 예측을 저장하고 짧은 지연 시간으로 제공합니다.
- 자동화: 이러한 모든 작업이 Cloud Composer를 통해 실행되고 관리됩니다.
데이터 수집
이 문서 시리즈는 데이터 수집을 수행하는 특정 방법에 대해 다루지 않습니다. BigQuery가 데이터를 수집하는 방법에는 Pub/Sub, Cloud Storage, BigQuery Data Transfer Service 등 여러 가지가 있습니다. 자세한 내용은 데이터 웨어하우스 실무자를 위한 BigQuery를 참조하세요. 이 시리즈에서 설명하는 방식은 공개 데이터 세트를 사용합니다. README 파일의 샘플 코드에 설명된 대로 이 데이터 세트를 BigQuery로 가져옵니다.
데이터 준비
데이터를 준비하려면 이 시리즈의 2부에 나온 것과 같은 쿼리를 BigQuery에서 실행합니다. 프로덕션 아키텍처에서는 Apache Airflow DAG(Directed Acyclic Graph)의 일부로 쿼리를 실행합니다. 데이터 준비를 위한 쿼리 실행은 이 문서 뒷부분의 자동화 관련 섹션에서 자세히 설명합니다.
AI Platform의 모델 학습
이 섹션에서는 아키텍처 학습 부분의 개요를 제공합니다.
어떤 유형의 모델을 선택하든 이 솔루션에 나온 코드는 학습과 예측을 위해 AI Platform에서 실행되도록 패키징되어 있습니다. AI Platform의 이점은 다음과 같습니다.
- 로컬로 또는 분산 환경의 클라우드에서 실행할 수 있습니다.
- Cloud Storage와 같은 다른 Google 제품과의 연결을 기본 제공합니다.
- 몇 가지 명령어만 사용하여 실행할 수 있습니다.
- 초매개변수 조정이 쉬워집니다.
- 최소한의 인프라 변경으로 확장이 가능합니다.
AI Platform이 모델을 학습시키고 평가할 수 있으려면 학습, 평가, 테스트 데이터세트를 제공해야 합니다. 이 시리즈의 2부에 나온 것과 같은 SQL 쿼리를 실행하여 이 데이터 세트를 만듭니다. 그런 다음 이 데이터 세트를 BigQuery 테이블에서 Cloud Storage로 내보냅니다. 이 문서에 설명된 프로덕션 아키텍처에서는 Airflow DAG에 의해 쿼리가 실행됩니다. Airflow DAG는 아래의 자동화 섹션에서 자세히 설명합니다. README 파일의 DAG 실행 섹션에 설명된 대로 DAG를 수동으로 실행할 수 있습니다.
예측 제공
예측은 온라인이나 오프라인으로 만들 수 있습니다. 하지만 예측을 만드는 것과 제공하는 것은 다릅니다. 이 CLV 컨텍스트에서 고객이 웹사이트에 로그인하거나 소매 매장을 방문하는 것과 같은 이벤트는 해당 고객의 평생가치에 극적인 영향을 미치지 않습니다. 따라서 결과를 실시간으로 표시해야 하는 경우에도 오프라인으로 예측을 수행할 수 있습니다. 오프라인 예측의 작동상 특징은 다음과 같습니다.
- 학습과 예측에 동일한 사전 처리 단계를 수행할 수 있습니다. 학습과 예측이 서로 다르게 사전 처리되면 예측의 정확도가 떨어질 수 있습니다. 이 현상을 학습 제공 편향이라고 합니다.
- 학습 및 예측을 위한 데이터를 준비하는 데 동일한 도구를 사용할 수 있습니다. 이 시리즈에서 다루는 방식은 주로 BigQuery를 사용하여 데이터를 준비합니다.
배치 작업을 사용하여 모델을 배포하고 오프라인 예측을 하는 데 AI Platform을 사용할 수 있습니다. 예측의 경우 AI Platform을 사용하면 다음과 같은 작업이 쉬워집니다.
- 버전 관리
- 최소 인프라 변경으로 확장
- 대규모 배포
- 다른 Google Cloud 제품과 상호작용
- SLA 제공
일괄 예측 작업은 입력과 출력 모두 Cloud Storage에 저장된 파일을 사용합니다. DNN 모델의 경우, task.py에 정의된 다음 제공 함수가 입력의 형식을 정의합니다.
예측 출력 형식은 이 코드의 에스티메이터 모델 함수가 model.py에서 반환하는 EstimatorSpec에서 정의됩니다.
예측 사용
모델 생성과 배포를 완료한 후 모델을 사용하여 CLV 예측을 수행할 수 있습니다. 일반적인 CLV 사용 사례는 다음과 같습니다.
- 데이터 전문가는 사용자 세그먼트를 구축할 때 오프라인 예측을 활용할 수 있습니다.
- 고객이 온라인이나 매장에서 브랜드와 상호작용할 때 기업에서 실시간으로 특정 제안을 할 수 있습니다.
BigQuery를 사용한 분석
CLV를 이해하는 것이 활성화의 관건입니다. 이 문서는 주로 이전 판매를 기반으로 평생가치를 계산하는 데 초점을 맞춥니다. 판매 데이터는 일반적으로 고객 관계 관리(CRM) 도구에서 얻지만 사용자 행동에 대한 정보는 Google 애널리틱스 360 같은 다른 소스에서 얻을 수 있습니다.
다음 작업을 수행하는 데 관심이 있다면 BigQuery를 사용해야 합니다.
- 여러 소스의 구조화된 데이터 저장
- Google 애널리틱스 360, YouTube 또는 애드워즈와 같은 일반적인 SaaS 도구의 데이터를 자동으로 전송
- 테라바이트 단위의 고객 데이터 조인을 포함한 임시 쿼리 실행
- 업계를 선도하는 비즈니스 인텔리전스 도구를 사용하여 데이터 시각화.
BigQuery는 관리형 스토리지와 쿼리 엔진의 역할 외에도 BigQuery ML을 사용하여 머신러닝 알고리즘을 직접 실행할 수 있습니다. 각 고객의 CLV 값을 BigQuery에 로드하면 데이터 분석가, 과학자, 엔지니어가 작업에서 추가 측정항목을 활용할 수 있습니다. 다음 섹션에서 설명하는 Airflow DAG에는 CLV 예측을 BigQuery에 로드하는 작업이 포함되어 있습니다.
Datastore를 사용한 짧은 지연 시간 제공
종종 오프라인 예측을 실시간 예측 제공에 재사용할 수 있습니다. 이 시나리오에서는 최신 예측이 중요한 것이 아니라 적절한 때에 편리하게 데이터에 액세스하는 것이 중요합니다.
실시간 제공을 위해 오프라인 예측을 저장한다는 것은 고객이 취하는 행동이 곧바로 고객의 CLV를 바꾸지 않는다는 것을 뜻합니다. 다만 이 CLV에 신속히 액세스하는 것이 중요합니다. 예를 들어 회사에서는 고객이 웹사이트를 이용하거나 헬프 데스크에 질문을 하거나 매장에서 물건을 구매할 때 신속하게 대응하려 할 수 있습니다. 이러한 상황에서 빠른 대응은 고객 관계를 개선시키는 효과가 있습니다. 따라서 속도가 빠른 데이터베이스에 예측 출력을 저장하여 프런트엔드에게 안전한 쿼리를 제공하는 것이 성공의 관건입니다.
수십만 명의 개별 고객이 있다고 가정해 보겠습니다. 다음과 같은 이유로 Datastore가 좋은 선택이 될 것입니다.
- NoSQL 문서 데이터베이스를 지원합니다.
- 키(고객 ID)를 사용하여 데이터에 빠르게 액세스할 수 있을 뿐 아니라 SQL 쿼리도 가능합니다.
- REST API를 통해 액세스할 수 있습니다.
- 즉시 사용할 수 있습니다. 즉, 설정 오버헤드가 없습니다.
- 자동으로 확장됩니다.
CSV 데이터 세트를 직접 Datastore에 로드할 수 있는 방법이 없기 때문에 이 솔루션에서는 자바스크립트 템플릿과 함께 Dialogflow에서 Apache Beam을 사용하여 CLV 예측을 Datastore에 로드합니다. 자바스크립트 템플릿의 다음 코드 스니펫은 그 방법을 보여 줍니다.
데이터가 Datastore에 있으면 다음과 같이 데이터와 상호작용하는 방법을 선택할 수 있습니다.
- 앱에서 Datastore 클라이언트 라이브러리 사용
- Cloud Endpoints 또는 Apigee API Platform을 사용하여 API 엔드포인트 빌드
- 서버리스 작업에 Cloud Run 함수 사용
솔루션 자동화
첫 번째 사전 처리, 학습, 예측 단계를 실행하기 위해 데이터 작업을 시작할 때는 지금까지 설명한 단계를 사용합니다. 하지만 여전히 자동화와 오류 관리가 필요하기 때문에 플랫폼은 아직 프로덕션 준비가 되지 않았습니다.
일부 스크립팅이 단계들을 결합하는 데 도움이 될 수 있습니다. 하지만 워크플로 관리자를 사용하여 단계들을 자동화하는 것이 가장 좋습니다. Apache Airflow는 널리 사용되는 워크플로 관리 도구이며, Cloud Composer를 사용하여 Google Cloud에서 관리형 Airflow 파이프라인을 실행할 수 있습니다.
Airflow는 각각의 작업을 지정하고, 서로 다른 작업과 어떤 관계에 있는지를 지정할 수 있는 Directed Acyclic Graph(DAG)와 호환됩니다. 이 시리즈에서 설명한 방식에서는 다음 단계를 실행합니다.
- BigQuery 데이터 세트를 만듭니다.
- Cloud Storage에서 BigQuery로 공개 데이터 세트를 로드합니다.
- BigQuery 테이블에서 데이터를 정리하고 새 BigQuery 테이블에 이 데이터를 씁니다.
- BigQuery 테이블 하나에서 데이터에 기반한 특성을 만들어 다른 BigQuery 테이블에 씁니다.
- 모델이 심층신경망(DNN)인 경우 BigQuery 내에서 데이터를 학습 세트와 평가 세트로 나눕니다.
- 데이터 세트를 Cloud Storage로 내보내고 AI Platform에 제공합니다.
- AI Platform이 주기적으로 모델을 학습시키도록 합니다.
- 업데이트된 모델을 AI Platform에 배포합니다.
- 새 데이터에서 주기적으로 일괄 예측을 실행합니다.
- 이미 Cloud Storage에 저장된 예측을 Datastore와 BigQuery에 저장합니다.
Cloud Composer 설정
Cloud Composer 설정 방법은 GitHub 저장소 리드미 파일의 안내를 참조하세요.
이 솔루션을 위한 DAG(Directed Acyclic Graph)
이 솔루션은 두 개의 DAG를 사용합니다. 첫 번째 DAG는 앞서 나열한 시퀀스의 1~8단계를 다룹니다.
다음 다이어그램은 Cloud Composer/Airflow UI를 보여 주며, Airflow DAG 단계의 1~8단계를 요약합니다.
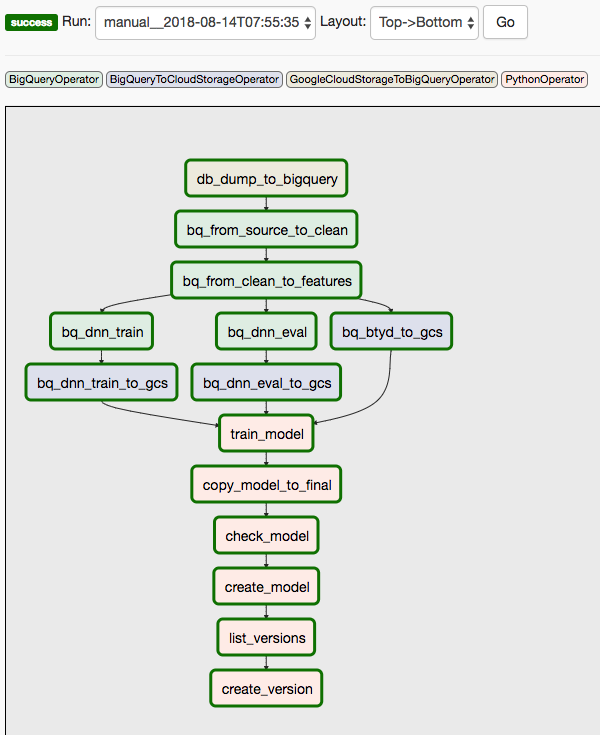
두 번째 DAG는 9단계와 10단계를 다룹니다.
다음 다이어그램은 Airflow DAG 프로세스의 9단계와 10단계를 요약합니다.
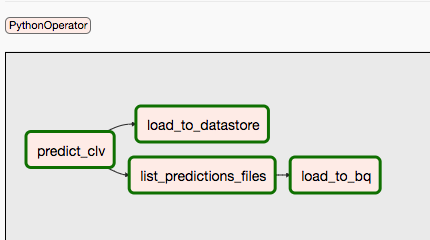
DAG가 분리되어 있는 것은 예측과 학습이 독립적으로, 다른 일정에 따라 이루어질 수 있기 때문입니다. 예를 들어 다음과 같이 할 수 있습니다.
- 신규 고객 또는 기존 고객에 대한 데이터를 매일 예측
- 매주 모델을 다시 학습시켜 새로운 데이터를 통합하거나, 특정한 수의 트랜잭션을 수신한 후에 재학습을 트리거
먼저 DAG를 수동으로 트리거하려면 Cloud Shell의 리드미 파일에 있는 DAG 실행 섹션에서 명령어를 실행하거나 gcloud CLI를 사용하여 명령어를 실행합니다.
conf 매개변수는 자동화의 서로 다른 부분에 변수를 전달합니다. 예를 들어 정리된 데이터에서 특성을 추출하는 데 사용되는 다음 SQL 쿼리에서는 FROM 절을 매개변수화하는 데 변수가 사용됩니다.
비슷한 명령을 사용하여 두 번째 DAG를 트리거할 수 있습니다. 자세한 내용은 GitHub 저장소의 README 파일을 참조하세요.
다음 단계
- GitHub 저장소에서 전체 예 실행하기
- 다음을 사용하여 새 특성을 CLV 모델에 통합하기
- 이전 데이터가 없는 고객의 CLV를 예측하는 데 도움이 되는 클릭 스트림 데이터
- 일부 컨텍스트를 추가할 수 있고 신경망에 도움이 되는 제품 부서 및 카테고리
- 이 솔루션에서 사용되는 것과 동일한 입력을 사용하여 만드는 새 특성. (예: 기준일 전 마지막 주 또는 달의 판매 추세)
- 4부: 모델에 AutoML Tables 사용 읽기
- 다른 예측 솔루션 알아보기
- Google Cloud에 대한 참조 아키텍처, 다이어그램, 권장사항 살펴보기. Cloud 아키텍처 센터 살펴보기