When optimizing an application's performance, consider its NDB use. For example, if an application reads a value that isn't in cache, that read takes a while. You might be able to speed up your application by performing Datastore actions in parallel with other things, or performing a few Datastore actions in parallel with each other.
The NDB Client Library provides many asynchronous ("async") functions.
Each of these functions
lets an application send a request to the Datastore. The function returns
immediately, returning a
Future
object. The application can do other things while the Datastore handles
the request.
After the Datastore handles the request, the application can get the results
from the Future object.
Introduction
Suppose that one of your application's request handlers needs to use NDB to write something, perhaps to record the request. It also needs to carry out some other NDB operations, perhaps to fetch some data.
By replacing the call to put() with a call to its
async equivalent put_async(), the application
can do other things right away instead of blocking on put().
This allows the other NDB functions and template rendering to happen while the Datastore writes the data. The application doesn't block on the Datastore until it gets data from the Datastore.
In this example, it's a little silly to call future.get_result:
the application never uses the result from NDB. That code is
just in there to make sure that the request handler doesn't exit before
the NDB put finishes; if the request handler exits too early,
the put might never happen. As a convenience, you can decorate the request
handler with @ndb.toplevel. This tells the handler not
to exit until its asynchronous requests have finished. This in turn lets you
send off the request and not worry about the result.
You can specify a whole WSGIApplication as
ndb.toplevel. This makes sure that each of the
WSGIApplication's handlers waits for all async
requests before returning.
(It does not "toplevel" all the WSGIApplication's handlers.)
Using a toplevel application is more convenient than
all its handler functions. But if a handler method uses yield,
that method still needs to be wrapped in another decorator,
@ndb.synctasklet; otherwise, it will stop executing at
the yield and not finish.
Using Async APIs and Futures
Almost every synchronous NDB function has an _async counterpart. For
example, put() has put_async().
The async function's arguments are always the same as those of the
synchronous version.
The return value of an async method is always either a
Future or (for "multi" functions) a list of
Futures.
A Future is an object that maintains state for an operation
that has been initiated but may not yet have completed; all async
APIs return one or more Futures.
You can call the Future's get_result()
function to ask it for the result of its operation;
the Future then blocks, if necessary, until the result is available,
and then gives it to you.
get_result() returns the value that would be returned
by the synchronous version of the API.
Note:
If you've used Futures in certain other programming languages, you might think
you can use a Future as a result directly. That doesn't work here.
Those languages use
implicit futures; NDB uses explicit futures.
Call get_result() to get an NDB Future's
result.
What if the operation raises an exception? That depends on when the
exception occurs. If NDB notices a problem when making a request
(perhaps an argument of the wrong type), the _async()
method raises an exception. But if the exception is detected by, say,
the Datastore server, the _async() method returns a
Future, and the exception will be raised when your application
calls its get_result(). Don't worry too much about this, it
all ends up behaving quite natural; perhaps the biggest difference is
that if a traceback gets printed, you'll see some pieces of the low-level
asynchronous machinery exposed.
For example, suppose you are writing a guestbook application. If the user is logged in, you want to present a page showing the most recent guestbook posts. This page should also show the user their nickname. The application needs two kinds of information: the logged-in user's account information and the contents of the guestbook posts. The "synchronous" version of this application might look like:
There are two independent I/O actions here: getting the
Account entity and fetching recent Guestbook
entities. Using the synchronous API, these happen one after the other;
we wait to receive the account information before fetching the
guestbook entities. But the application doesn't need the account
information right away. We can take advantage of this and use async APIs:
This version of the code first creates two Futures
(acct_future and recent_entries_future),
and then waits for them. The server works on both requests in parallel.
Each _async() function call creates a Future object
and sends a request to the Datastore server. The server can start
working on the request right away. The server responses may come back
in any arbitrary order; the Future object link responses to their
corresponding requests.
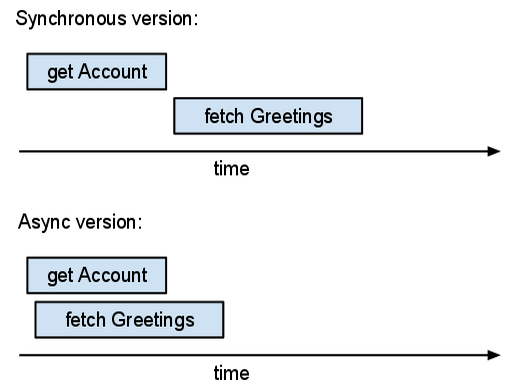
The total (real) time spent in the async version is roughly equal to the maximum time across the operations. The total time spent in the synchronous version exceeds the sum of the operation times. If you can run more operations in parallel, then async operations help more.
To see how long your application's queries take or how many I/O operations it does per request, consider using Appstats. This tool can show charts similar to the drawing above based on instrumentation of a live app.
Using Tasklets
An NDB tasklet is a piece of code that might run concurrently with
other code. If you write a tasklet, your application can use it much like
it uses an async NDB function: it calls the tasklet, which returns a
Future; later, calling the Future's
get_result() method gets the result.
Tasklets are a way to write concurrent functions without
threads; tasklets are executed by an event loop and can suspend
themselves blocking for I/O or some other operation using a yield
statement. The notion of a blocking operation is abstracted into the
Future
class, but a tasklet may also yield an
RPC in order to wait for that RPC to complete.
When the tasklet has a result, it raises an
ndb.Return exception; NDB then associates the result
with the previously-yielded Future.
When you write an NDB tasklet, you use yield and
raise in an unusual way. Thus, if you look for examples of
how to use these, you probably will not find code like an NDB tasklet.
To turn a function into an NDB tasklet:
- decorate the function with
@ndb.tasklet, - replace all synchronous datastore calls with
yields of asynchronous datastore calls, - make the function "return" its return value with
raise ndb.Return(retval)(not necessary if the function doesn't return anything).
An application can use tasklets for finer control over asynchronous APIs. As an example, consider the following schema:
...
When displaying a message, it makes sense to show the author's nickname. The "synchronous" way to fetch the data to show a list of messages might look like this:
Unfortunately, this approach is inefficient. If you looked at it in
Appstats,
you would see that the "Get" requests are in series. You might see
the following "staircase" pattern.
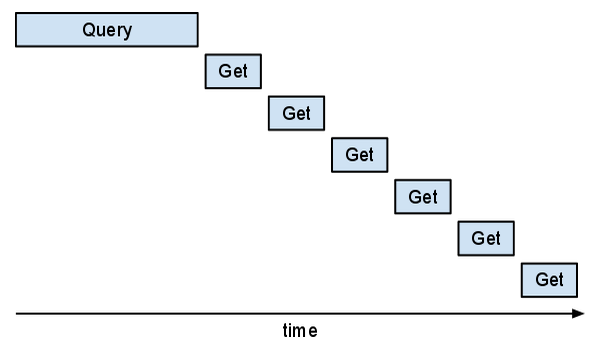
This part of the program would be faster if those "Gets" could overlap.
You might rewrite the code to use get_async, but it is
tricky to keep track of which async requests and messages belong together.
The application can define its own "async" function by making it a tasklet. This allows you to organize the code in a less confusing way.
Furthermore, instead of using
acct = key.get() or
acct = key.get_async().get_result(),
the function should use
acct = yield key.get_async().
This yield tells NDB that this is a good place to suspend this
tasklet and let other tasklets run.
Decorating a generator function with @ndb.tasklet
makes the function return a Future instead of a
generator object. Within the tasklet, any yield of a
Future waits for and returns the Future's result.
For example:
Take note that although get_async() returns a
Future, the tasklet framework causes the yield
expression to return the Future's result to variable
acct.
The map() calls callback() several times.
But the yield ..._async() in callback()
lets NDB's scheduler send off many async requests before waiting for
any of them to finish.
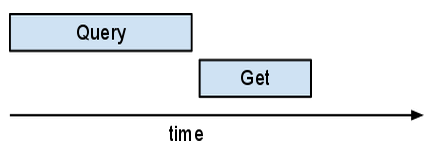
If you look at this in Appstats, you might be surprised to see that these multiple Gets don't just overlap—they all go through in the same request. NDB implements an "autobatcher." The autobatcher bundles multiple requests up in a single batch RPC to the server; it does this in such a way that as long as there is more work to do (another callback may run) it collects keys. As soon as one of the results is needed, the autobatcher sends the batch RPC. Unlike most requests, queries are not "batched".
When a tasklet runs, it gets its default namespace from whatever the default was when the tasklet was spawned, or whatever the tasklet changed it to while running. In other words, the default namespace is not associated with or stored in the Context, and changing the default namespace in one tasklet does not affect the default namespace in other tasklets, except those spawned by it.
Tasklets, Parallel Queries, Parallel Yield
You can use tasklets so that multiple queries fetch records at the same time. For example, suppose your application has a page that displays the contents of a shopping cart and a list of special offers. The schema might look like this:
A "synchronous" function that gets shopping cart items and special offers might look like the following:
This example uses queries to fetch lists of cart items and offers; it then
fetches details about the inventory items with get_multi().
(This function doesn't use
the return value of get_multi() directly. It calls
get_multi() to fetch all the inventory details into the
cache so that they can be read quickly later.) get_multi
combines many Gets into one request. But the query fetches happen one after
the other. To make those fetches happen at the same time, overlap the two queries:
The get_multi()
call is still separate: it depends on the query results, so you
can't combine it with the queries.
Suppose this application sometimes needs the cart, sometimes the offers, and sometimes both. You want to organize your code so that there's a function to get the cart and a function to get the offers. If your application calls these functions together, ideally their queries could "overlap." To do this, make these functions tasklets:
That yield x, y is important
but easy to overlook. If that were two separate yield
statements, they would happen in series. But yielding a tuple
of tasklets is a parallel yield: the tasklets can run in parallel
and the yield waits for all of them to finish and returns
the results. (In some programming languages, this is known as a
barrier.)
If you turn one piece of code into a tasklet, you will probably want to
do more soon. If you notice "synchronous" code that could run in parallel
with a tasklet, it's probably a good idea to make it a tasklet, too.
Then you can parallelize it with a parallel yield.
If you write a request function (a webapp2 request
function, a Django view function, etc.) to be a tasklet,
it won't do what you want: it yields but then stops
running. In this situation, you want to decorate the function with
@ndb.synctasklet.
@ndb.synctasklet is like @ndb.tasklet but
altered to call get_result() on the tasklet.
This turns your tasklet into a function
that returns its result in the usual way.
Query Iterators in Tasklets
To iterate over query results in a tasklet, use the following pattern:
This is the tasklet-friendly equivalent of the following:
The three bold lines in the first version are the tasklet-friendly
equivalent of the single bold line in the second version.
Tasklets can only be suspended at a yield keyword.
The yield-less for loop doesn't let other tasklets run.
You might wonder why this code uses a query iterator at all instead of
fetching all the entities using qry.fetch_async().
The application might have so many entities that they don't fit in RAM.
Perhaps you're looking for an entity and can stop iterating once you
find it; but you can't express your search criteria with just the query
language. You might use an iterator to load entities to check, then
break out of the loop when you find what you want.
Async Urlfetch with NDB
An NDB Context has an asynchronous
urlfetch() function that parallelizes nicely with NDB tasklets, for example:
The URL Fetch service has its own asynchronous request API. It's fine, but not always easy to use with NDB tasklets.
Using Asynchronous Transactions
Transactions may also be done asynchronously. You can pass an existing function
to ndb.transaction_async(), or use the
@ndb.transactional_async decorator.
Like the other async functions, this will return an NDB Future:
Transactions also work with tasklets. For example, we could change our
update_counter code to yield while waiting on blocking
RPCs:
Using Future.wait_any()
Sometimes you want to make multiple asynchronous requests
and return whenever the first one completes.
You can do this using the ndb.Future.wait_any() class method:
Unfortunately, there is no convenient way to turn this into a tasklet;
a parallel yield waits for all Futures to
complete—including those you don't want to wait for.