ID de la région
Le REGION_ID est un code abrégé que Google attribue en fonction de la région que vous sélectionnez lors de la création de votre application. Le code ne correspond pas à un pays ou une province, même si certains ID de région peuvent ressembler aux codes de pays et de province couramment utilisés. Pour les applications créées après février 2020, REGION_ID.r est inclus dans les URL App Engine. Pour les applications existantes créées avant cette date, l'ID de région est facultatif dans l'URL.
En savoir plus sur les ID de région
Le développement de logiciels est une affaire de compromis et les microservices ne font pas exception. Ce que vous gagnez en déploiement de code et en indépendance opérationnelle, vous le payez en impact sur les performances. Cette section présente certaines pratiques recommandées qui vous permettront de minimiser cet impact.
Transformer les opérations CRUD en microservices
Les microservices sont particulièrement bien adaptés aux entités accessibles via le modèle CRUD (créer, récupérer, mettre à jour, supprimer). Lorsque vous travaillez avec de telles entités, vous n'en utilisez généralement qu'une seule à la fois, par exemple un utilisateur, et vous n'exécutez qu'une seule des actions CRUD à la fois. Par conséquent, vous n'avez besoin que d'un seul appel de microservice pour l'opération. Recherchez les entités associées à des opérations CRUD ainsi qu'à un ensemble de procédés pouvant être employés dans de nombreux domaines de votre application. Ces entités sont parfaitement adaptées aux microservices.
Fournir des API par lot
En plus des API de type CRUD, les API par lot permettent aussi de fournir de bonnes performances de microservice à des groupes d'entités. Par exemple, plutôt que de n'exposer qu'une méthode d'API GET pour récupérer un utilisateur unique, fournissez une API qui regroupe un ensemble d'ID utilisateur et renvoie un dictionnaire des utilisateurs correspondants :
Requête :
/user-service/v1/?userId=ABC123&userId=DEF456&userId=GHI789Réponse :
{
"ABC123": {
"userId": "ABC123",
"firstName": "Jake",
… },
"DEF456": {
"userId": "DEF456",
"firstName": "Sue",
… },
"GHI789": {
"userId": "GHI789",
"firstName": "Ted",
… }
}
Le SDK App Engine est compatible avec de nombreuses API de traitement par lot qui permettent, par exemple, d'extraire des entités de Cloud Datastore en nombre via un seul RPC. La maintenance de ces types d'API de traitement par lot peut donc s'avérer particulièrement intéressante.
Utiliser des requêtes asynchrones
Vous serez souvent amené à interagir avec de nombreux microservices pour composer une réponse.
Par exemple, vous devrez peut-être récupérer les préférences
de l'utilisateur connecté, ainsi que ses informations d'entreprise. Ces données ne sont pas dépendantes les unes des autres et vous pouvez les récupérer en parallèle. La bibliothèque Urlfetch du SDK App Engine accepte les requêtes asynchrones, ce qui vous permet d'appeler des microservices en parallèle.
from google.appengine.api import urlfetch
preferences_rpc = urlfetch.create_rpc()
urlfetch.make_fetch_call(preferences_rpc,
'https://preferences-service-dot-my-app.uc.r.appspot.com/preferences-service/v1/?userId=ABC123')
company_rpc = urlfetch.create_rpc()
urlfetch.make_fetch_call(company_rpc,
'https://company-service-dot-my-app.uc.r.appspot.com/company-service/v3/?companyId=ACME')
### microservice requests are now occurring in parallel
try:
preferences_response = preferences_rpc.get_result() # blocks until response
if preferences_response.status_code == 200:
# deserialize JSON, or whatever is appropriate
else:
# handle error
except urlfetch.DownloadError:
# timeout, or other transient error
try:
company_response = company_rpc.get_result() # blocks until response
if company_response.status_code == 200:
# deserialize JSON, or whatever is appropriate
else:
# handle error
except urlfetch.DownloadError:
# timeout, or other transient error
Le travail en parallèle est souvent contraire aux bonnes pratiques de structure de code.
En effet, dans une application concrète, une classe est généralement utilisée pour regrouper les méthodes de préférence,
et une autre classe pour encapsuler les méthodes de l'entreprise. Il est difficile d'utiliser des appels asynchrones Urlfetch sans rompre cette encapsulation. Le package NDB du SDK App Engine pour Python contient une solution adaptée : les tasklets.
Les tasklets permettent de conserver une bonne encapsulation dans votre code
tout en offrant un mécanisme permettant de réaliser des appels de microservice en parallèle. Notez que les tasklets utilisent des futures au lieu des RPC,
mais l'idée est semblable.
Utiliser le chemin le plus court
Selon la manière dont vous appelez Urlfetch, les infrastructures et les routes utilisées seront différentes. Pour utiliser la route la plus performante, tenez compte des recommandations suivantes :
- Plutôt qu'un domaine personnalisé, utilisez
REGION_ID.r.appspot.com. - Un domaine personnalisé entraîne l'utilisation d'une autre route lors du routage via l'infrastructure Google. Étant donné que vos appels de microservices sont internes, il est facile d'obtenir de meilleures performances si vous utilisez
https://PROJECT_ID.REGION_ID.r.appspot.com. - Définissez
follow_redirectssurFalse. - Définissez
follow_redirects=Falsede façon explicite lorsque vous appelezUrlfetch. Vous éviterez ainsi de solliciter un service plus lourd conçu pour suivre les redirections. Les points de terminaison de votre API n'ont pas besoin de rediriger les clients car il s'agit de vos propres microservices. Ils ne devraient renvoyer que des réponses HTTP 200, 400 et 500. - Privilégiez les services d'un seul projet plutôt que sur plusieurs projets
- Lorsque vous créez une application basée sur des microservices, l'utilisation de plusieurs projets est souvent justifiée. Cependant, si les performances sont votre objectif principal, il est préférable d'utiliser les services d'un seul projet. Les services d'un projet sont hébergés dans le même centre de données et, même si le débit du réseau inter-datacenter de Google est excellent, les appels locaux sont plus rapides.
Éviter les communications excessives pendant l'application des mesures de sécurité
Les mécanismes de sécurité qui impliquent de nombreuses communications dans les deux sens pour authentifier l'API appelante nuisent aux performances. Par exemple, si votre microservice doit valider un ticket provenant de votre application en rappelant celle-ci, vous avez engagé plusieurs allers-retours pour obtenir les données.
La mise en œuvre d'un protocole OAuth2 permet d'amortir ce coût au fil du temps grâce à l'utilisation de jetons d'actualisation et à la mise en cache d'un jeton d'accès entre les appels Urlfetch. Cependant, si le jeton d'accès en cache est stocké dans memcache, vous devrez solliciter une surcharge du cache pour le récupérer. Pour éviter cette surcharge, vous pouvez mettre en cache le jeton d'accès dans la mémoire de l'instance, mais l'activité OAuth2 se poursuivra à la même fréquence, puisque chaque nouvelle instance négocie un jeton d'accès. N'oubliez pas que les instances App Engine sont fréquemment démarrées et arrêtées. Certaines combinaisons de memcache et cache d'instance
peuvent atténuer le problème, mais votre solution
n'en sera que plus complexe.
Une autre approche intéressante consiste à partager un jeton secret entre microservices transmis, par exemple, sous forme d'en-tête HTTP personnalisé. Dans cette approche, chaque microservice peut être doté d'un jeton unique pour chaque appelant. En règle générale, les clés secrètes partagées sont à éviter dans les stratégies de sécurité. Toutefois, étant donné que tous les microservices se trouvent dans la même application, le risque est faible comparé aux avantages en matière de performances. Dans le cas d'une clé secrète partagée, il suffit que le microservice compare une chaîne de caractères de la clé secrète entrante avec un dictionnaire vraisemblablement en mémoire, et le protocole de sécurité appliqué est très léger.
Si tous les microservices sont sur App Engine, vous pouvez également inspecter l'en-tête X-Appengine-Inbound-Appid entrant.
Cet en-tête est ajouté par l'infrastructure Urlfetch lors de l'envoi d'une requête à un autre projet App Engine et ne peut pas être défini par une partie externe. Selon vos exigences de sécurité, votre protocole pourrait être appliqué au niveau de l'en-tête entrant lorsqu'il est inspecté par vos microservices.
Tracer les requêtes de microservice
À mesure que vous développez votre application basée sur des microservices, vous commencez à accumuler du temps système en raison des appels Urlfetch successifs. Lorsque cela se produit, vous pouvez utiliser Cloud Trace pour comprendre quels appels sont passés et où se situe la surcharge. Il est important de noter que Cloud Trace permet aussi d'identifier les endroits où des microservices indépendants sont appelés en série. Vous pouvez ainsi refactoriser votre code pour exécuter ces extractions en parallèle.
L'utilisation de plusieurs services au sein d'un même projet permet d'accéder à une fonctionnalité de Cloud Trace particulièrement utile. À mesure que les appels entre microservices sont passés dans votre projet, Cloud Trace les regroupe en un seul graphique permettant de visualiser la requête de bout en bout sous la forme d'une trace unique.
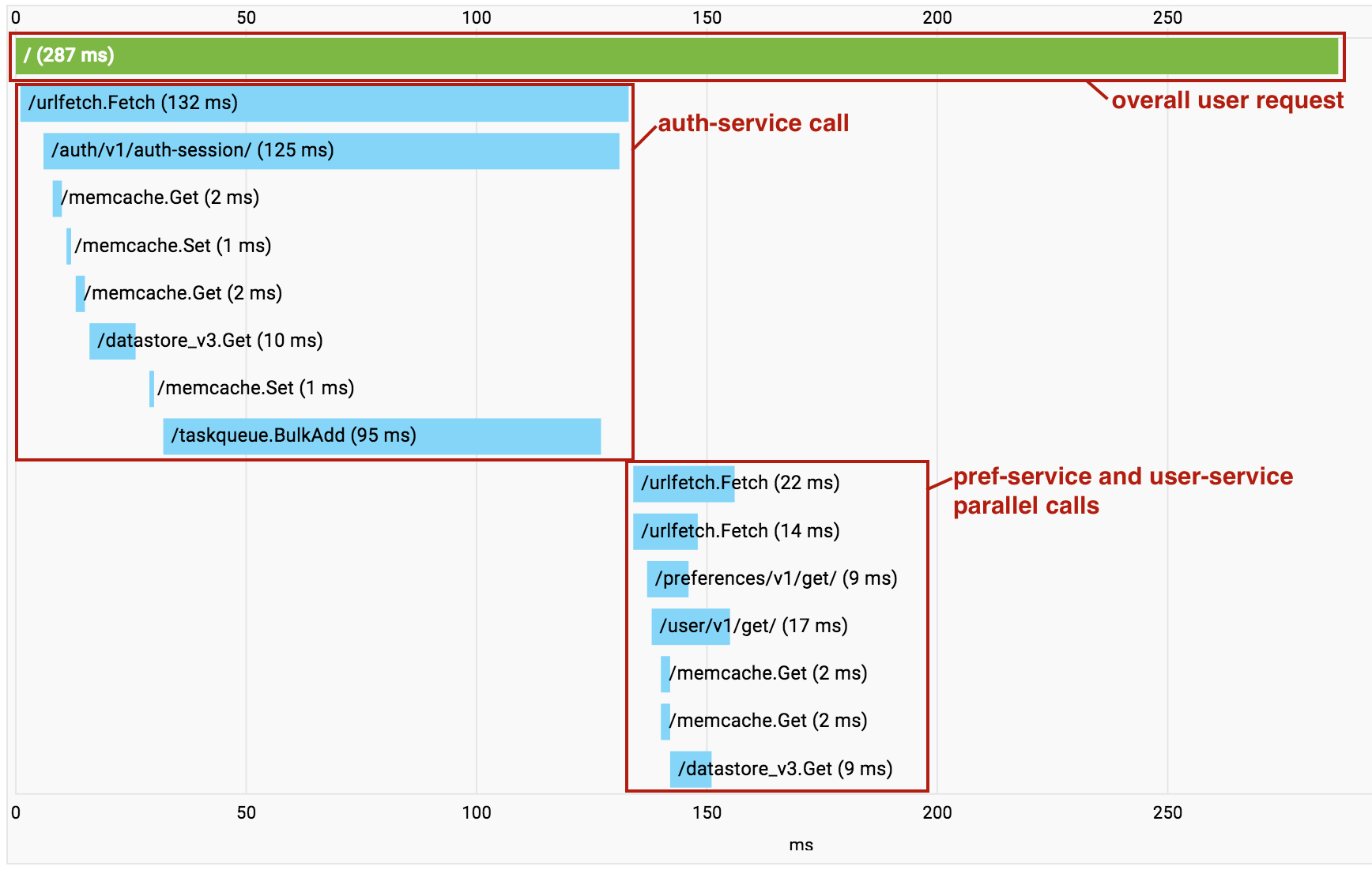
Notez que dans l'exemple ci-dessus, les appels à pref-service et à user-service sont effectués en parallèle à l'aide d'une requête Urlfetch asynchrone, de sorte que les RPC apparaissent brouillés dans la visualisation.
Cependant, cela reste un outil précieux pour diagnostiquer la latence.
Étapes suivantes
- Consultez une présentation de l'architecture de microservices sur App Engine.
- Apprenez à créer et nommer des environnements de développement, de test, de contrôle qualité, de préproduction et de production avec des microservices dans App Engine
- Découvrez les bonnes pratiques de conception d'API pour la communication entre microservices.
- Découvrez comment migrer une application monolithique existante vers une application dotée de microservices.