BigQuery
Utilizza il connettore BigQuery per eseguire operazioni di inserimento, eliminazione, aggiornamento e lettura sui dati di Google BigQuery. Puoi anche eseguire query SQL personalizzate sui dati BigQuery. Puoi utilizzare il connettore BigQuery per integrare i dati di più servizi Google Cloud o di altri servizi di terze parti, come Cloud Storage o Amazon S3.
Prima di iniziare
Nel tuo progetto Google Cloud, esegui le seguenti attività:
- Assicurati che la connettività di rete sia configurata. Per informazioni sui pattern di rete, vedi Connettività di rete.
- Concedi il ruolo IAM roles/connectors.admin all'utente che configura il connettore.
- Concedi il ruolo IAM
roles/bigquery.dataEditoral service account che vuoi utilizzare per il connettore. Se non hai un account di servizio, devi crearne uno. Il connettore e il account di servizio devono appartenere allo stesso progetto. - Attiva i seguenti servizi:
secretmanager.googleapis.com(API Secret Manager)connectors.googleapis.com(API Connectors)
Per capire come abilitare i servizi, consulta Abilitazione dei servizi. Se questi servizi o queste autorizzazioni non sono stati attivati in precedenza per il tuo progetto, ti viene chiesto di attivarli quando configuri il connettore.
Crea una connessione BigQuery
Una connessione è specifica per un'origine dati. Ciò significa che se hai molte origini dati, devi creare una connessione separata per ciascuna. Per creare una connessione:
- Nella console Google Cloud, vai alla pagina Integration Connectors > Connessioni e poi seleziona o crea un progetto Google Cloud.
- Fai clic su + CREA NUOVA per aprire la pagina Crea connessione.
- Nella sezione Località, seleziona una località dall'elenco Regione e poi fai clic su AVANTI.
Per l'elenco di tutte le regioni supportate, consulta Località.
- Nella sezione Dettagli connessione, segui questi passaggi:
- Seleziona BigQuery dall'elenco Connettore.
- Seleziona una versione del connettore dall'elenco Versione del connettore.
- Nel campo Nome connessione, inserisci un nome per l'istanza di connessione. Il nome della connessione può contenere lettere minuscole, numeri o trattini. Il nome deve iniziare con una lettera e terminare con una lettera o un numero e non deve superare i 49 caratteri.
- (Facoltativo) Abilita Cloud Logging,
quindi seleziona un livello di log. Per impostazione predefinita, il livello di log è impostato su
Error. - Service Account: seleziona un account di servizio con i ruoli richiesti.
- (Facoltativo) Configura le impostazioni del nodo di connessione.
- Numero minimo di nodi: inserisci il numero minimo di nodi di connessione.
- Numero massimo di nodi: inserisci il numero massimo di nodi di connessione.
- ID progetto: l'ID del progetto Google Cloud in cui si trovano i dati.
- ID set di dati: l'ID del set di dati BigQuery.
- Per supportare il tipo di dati BigQuery Array, seleziona Supporta tipi di dati nativi. Sono supportati i seguenti tipi di array: Varchar, Int64, Float64, Long, Double, Bool e Timestamp. Gli array nidificati non sono supportati.
- (Facoltativo) Per configurare un server proxy per la connessione, seleziona Usa proxy e inserisci i dettagli del proxy.
-
Proxy Auth Scheme (Schema di autenticazione proxy): seleziona il tipo di autenticazione per l'autenticazione con il server proxy. Sono supportati i seguenti tipi di autenticazione:
- Basic: autenticazione HTTP di base.
- Digest: autenticazione HTTP Digest.
- Utente proxy: un nome utente da utilizzare per l'autenticazione con il server proxy.
- Password proxy: il secret di Secret Manager della password dell'utente.
-
Tipo di SSL proxy: il tipo di SSL da utilizzare per la connessione al server proxy. Sono supportati i seguenti tipi di autenticazione:
- Automatica: impostazione predefinita. Se l'URL è un URL HTTPS, viene utilizzata l'opzione Tunnel. Se l'URL è un URL HTTP, viene utilizzata l'opzione NEVER.
- Sempre: la connessione è sempre abilitata per SSL.
- Mai: la connessione non è abilitata per SSL.
- Tunnel: la connessione avviene tramite un proxy di tunneling. Il server proxy apre una connessione all'host remoto e il traffico scorre avanti e indietro attraverso il proxy.
- Nella sezione Server proxy, inserisci i dettagli del server proxy.
- Fai clic su + Aggiungi destinazione.
- Seleziona un Tipo di destinazione.
- Indirizzo host: specifica il nome host o l'indirizzo IP della destinazione.
Se vuoi stabilire una connessione privata al tuo sistema di backend:
- Crea un collegamento del servizio PSC.
- Crea un collegamento dell'endpoint e poi inserisci i dettagli del collegamento dell'endpoint nel campo Indirizzo host.
- Indirizzo host: specifica il nome host o l'indirizzo IP della destinazione.
- Fai clic su AVANTI.
Un nodo è un'unità (o una replica) di una connessione che elabora le transazioni. Sono necessari più nodi per elaborare più transazioni per una connessione e, viceversa, sono necessari meno nodi per elaborare meno transazioni. Per capire in che modo i nodi influiscono sui prezzi dei connettori, consulta Prezzi dei nodi di connessione. Se non inserisci alcun valore, per impostazione predefinita i nodi minimi sono impostati su 2 (per una migliore disponibilità) e i nodi massimi sono impostati su 50.
-
Nella sezione Autenticazione, inserisci i dettagli di autenticazione.
- Seleziona se eseguire l'autenticazione con OAuth 2.0 - Codice di autorizzazione o procedere senza autenticazione.
Per capire come configurare l'autenticazione, consulta Configurare l'autenticazione.
- Fai clic su AVANTI.
- Seleziona se eseguire l'autenticazione con OAuth 2.0 - Codice di autorizzazione o procedere senza autenticazione.
- Rivedi i dettagli della connessione e dell'autenticazione, poi fai clic su Crea.
Configura l'autenticazione
Inserisci i dettagli in base all'autenticazione che vuoi utilizzare.
- Nessuna autenticazione. Seleziona questa opzione se non richiedi l'autenticazione.
- OAuth 2.0 - Codice di autorizzazione: seleziona questa opzione per l'autenticazione utilizzando un flusso di accesso utente basato sul web. Specifica i seguenti dettagli:
- ID client : l'ID client necessario per connettersi al tuo servizio Google di backend.
- Ambiti : un elenco separato da virgole degli ambiti desiderati. Per visualizzare tutti gli ambiti OAuth 2.0 supportati per il servizio Google richiesto, consulta la sezione pertinente nella pagina Ambiti OAuth 2.0 per le API di Google.
- Client secret : seleziona il secret di Secret Manager. Prima di configurare questa autorizzazione, devi aver creato il secret Secret Manager.
- Versione secret : la versione secret di Secret Manager per il client secret.
Per il tipo di autenticazione Authorization code, dopo aver creato la connessione, devi autorizzarla.
Autorizzare la connessione
Se utilizzi OAuth 2.0 - codice di autorizzazione per autenticare la connessione, completa le seguenti attività dopo aver creato la connessione.
- Nella pagina Connessioni,
individua la connessione appena creata.
Tieni presente che lo Stato del nuovo connettore sarà Autorizzazione richiesta.
- Fai clic su Autorizzazione obbligatoria.
Viene visualizzato il riquadro Modifica autorizzazione.
- Copia il valore URI di reindirizzamento nell'applicazione esterna.
- Verifica i dettagli dell'autorizzazione.
- Fai clic su Autorizza.
Se l'autorizzazione va a buon fine, lo stato della connessione verrà impostato su Attivo nella pagina Connessioni.
Nuova autorizzazione per il codice di autorizzazione
Se utilizzi il tipo di autenticazione Authorization code e hai apportato modifiche alla configurazione in BigQuery,
devi riautorizzare la connessione BigQuery. Per autorizzare nuovamente una connessione:
- Fai clic sulla connessione richiesta nella pagina Connessioni.
Viene visualizzata la pagina dei dettagli della connessione.
- Fai clic su Modifica per modificare i dettagli della connessione.
- Verifica i dettagli di OAuth 2.0 - Codice di autorizzazione nella sezione Autenticazione.
Se necessario, apporta le modifiche necessarie.
- Fai clic su Salva. Viene visualizzata la pagina dei dettagli della connessione.
- Fai clic su Modifica autorizzazione nella sezione Autenticazione. Viene visualizzato il riquadro Autorizza.
- Fai clic su Autorizza.
Se l'autorizzazione va a buon fine, lo stato della connessione verrà impostato su Attiva nella pagina Connessioni.
Utilizzare la connessione BigQuery in un'integrazione
Una volta creata la connessione, questa diventa disponibile sia in Apigee Integration che in Application Integration. Puoi utilizzare la connessione in un'integrazione tramite l'attività Connettori.
- Per capire come creare e utilizzare l'attività Connettori in Apigee Integration, consulta Attività Connettori.
- Per capire come creare e utilizzare l'attività Connettori in Application Integration, vedi Attività Connettori.
Azioni
Questa sezione descrive le azioni disponibili nel connettore BigQuery.
I risultati di tutte le operazioni e le azioni sulle entità
saranno disponibili come risposta JSON nel parametro di risposta connectorOutputPayload
dell'attività Connectors dopo l'esecuzione dell'integrazione.
Azione CancelJob
Questa azione ti consente di annullare un job BigQuery in esecuzione.
La seguente tabella descrive i parametri di input dell'azione CancelJob.
| Nome parametro | Tipo di dati | Descrizione |
|---|---|---|
| JobId | Stringa | L'ID del job che vuoi annullare. Questo campo è obbligatorio. |
| Regione | Stringa | La regione in cui è attualmente in esecuzione il job. Questo non è obbligatorio se il job si trova in una regione degli Stati Uniti o dell'UE. |
Azione GetJob
Questa azione consente di recuperare le informazioni di configurazione e lo stato di esecuzione di un job esistente.
La seguente tabella descrive i parametri di input dell'azione GetJob.
| Nome parametro | Tipo di dati | Descrizione |
|---|---|---|
| JobId | Stringa | L'ID del job per cui vuoi recuperare la configurazione. Questo campo è obbligatorio. |
| Regione | Stringa | La regione in cui è attualmente in esecuzione il job. Questo non è obbligatorio se il job si trova in una regione degli Stati Uniti o dell'UE. |
Azione InsertJob
Questa azione ti consente di inserire un job BigQuery, che può essere selezionato in un secondo momento per recuperare i risultati della query.
La seguente tabella descrive i parametri di input dell'azione InsertJob.
| Nome parametro | Tipo di dati | Descrizione |
|---|---|---|
| Query | Stringa | La query da inviare a BigQuery. Questo campo è obbligatorio. |
| IsDML | Stringa | Deve essere impostato su true se la query è un'istruzione DML o su false
in caso contrario. Il valore predefinito è false. |
| DestinationTable | Stringa | La tabella di destinazione per la query, nel formato DestProjectId:DestDatasetId.DestTable. |
| writeDisposition | Stringa | Specifica come scrivere i dati nella tabella di destinazione, ad esempio troncando i risultati esistenti, aggiungendo i risultati esistenti o scrivendo solo quando la tabella è vuota. Di seguito sono riportati i valori
supportati:
|
| DryRun | Stringa | Specifica se l'esecuzione del job è un dry run. |
| MaximumBytesBilled | Stringa | Specifica il numero massimo di byte che possono essere elaborati dal job. BigQuery annulla il job se tenta di elaborare più byte del valore specificato. |
| Regione | Stringa | Specifica la regione in cui deve essere eseguito il job. |
Azione InsertLoadJob
Questa azione consente di inserire un job di caricamento BigQuery, che aggiunge i dati da Google Cloud Storage a una tabella esistente.
La seguente tabella descrive i parametri di input dell'azione InsertLoadJob.
| Nome parametro | Tipo di dati | Descrizione |
|---|---|---|
| SourceURIs | Stringa | Un elenco separato da spazi di URI Google Cloud Storage. |
| SourceFormat | Stringa | Il formato di origine dei file. Di seguito sono riportati i valori supportati:
|
| DestinationTable | Stringa | La tabella di destinazione per la query, nel formato DestProjectId.DestDatasetId.DestTable. |
| DestinationTableProperties | Stringa | Un oggetto JSON che specifica il nome descrittivo, la descrizione e l'elenco delle etichette della tabella. |
| DestinationTableSchema | Stringa | Un elenco JSON che specifica i campi utilizzati per creare la tabella. |
| DestinationEncryptionConfiguration | Stringa | Un oggetto JSON che specifica le impostazioni di crittografia KMS per la tabella. |
| SchemaUpdateOptions | Stringa | Un elenco JSON che specifica le opzioni da applicare durante l'aggiornamento dello schema della tabella di destinazione. |
| TimePartitioning | Stringa | Un oggetto JSON che specifica il tipo e il campo di partizionamento temporale. |
| RangePartitioning | Stringa | Un oggetto JSON che specifica il campo e i bucket di partizionamento dell'intervallo. |
| Clustering | Stringa | Un oggetto JSON che specifica i campi da utilizzare per il clustering. |
| Rilevamento automatico | Stringa | Specifica se le opzioni e lo schema devono essere determinati automaticamente per i file JSON e CSV. |
| CreateDisposition | Stringa | Specifica se la tabella di destinazione deve essere creata se non esiste già. Di seguito
sono riportati i valori supportati:
|
| writeDisposition | Stringa | Specifica come scrivere i dati nella tabella di destinazione, ad esempio troncando i risultati esistenti,
aggiungendo i risultati esistenti o scrivendo solo quando la tabella è vuota. Di seguito sono riportati i valori supportati:
|
| Regione | Stringa | Specifica la regione in cui deve essere eseguito il job. Sia le risorse Google Cloud Storage sia il set di dati BigQuery devono trovarsi nella stessa regione. |
| DryRun | Stringa | Specifica se l'esecuzione del job è un dry run. Il valore predefinito è false. |
| MaximumBadRecords | Stringa | Specifica il numero di record che possono essere non validi prima che l'intero job venga annullato. Per impostazione predefinita, tutti i record devono essere validi. Il valore predefinito è 0. |
| IgnoreUnknownValues | Stringa | Specifica se i campi sconosciuti devono essere ignorati nel file di input o trattati come errori. Per impostazione predefinita, vengono trattati come errori. Il valore predefinito è false. |
| AvroUseLogicalTypes | Stringa | Specifica se i tipi logici AVRO devono essere utilizzati per convertire i dati AVRO in tipi BigQuery. Il valore
predefinito è true. |
| CSVSkipLeadingRows | Stringa | Specifica il numero di righe da saltare all'inizio dei file CSV. Viene in genere utilizzato per ignorare le righe di intestazione. |
| CSVEncoding | Stringa | Tipo di codifica dei file CSV. Di seguito sono riportati i valori supportati:
|
| CSVNullMarker | Stringa | Se fornita, questa stringa viene utilizzata per i valori NULL all'interno dei file CSV. Per impostazione predefinita, i file CSV non possono utilizzare NULL. |
| CSVFieldDelimiter | Stringa | Il carattere utilizzato per separare le colonne all'interno dei file CSV. Il valore predefinito è una virgola (,). |
| CSVQuote | Stringa | Il carattere utilizzato per i campi tra virgolette nei file CSV. Può essere impostato su vuoto per disattivare la citazione. Il valore predefinito sono le virgolette doppie ("). |
| CSVAllowQuotedNewlines | Stringa | Specifica se i file CSV possono contenere caratteri di fine riga all'interno dei campi tra virgolette. Il valore predefinito è false. |
| CSVAllowJaggedRows | Stringa | Specifica se i file CSV possono contenere campi mancanti. Il valore predefinito è false. |
| DSBackupProjectionFields | Stringa | Un elenco JSON di campi da caricare da un backup di Cloud Datastore. |
| ParquetOptions | Stringa | Un oggetto JSON che specifica le opzioni di importazione specifiche di Parquet. |
| DecimalTargetTypes | Stringa | Un elenco JSON che indica l'ordine di preferenza applicato ai tipi numerici. |
| HivePartitioningOptions | Stringa | Un oggetto JSON che specifica le opzioni di partizionamento lato origine. |
Esegui query SQL personalizzata
Per creare una query personalizzata:
- Segui le istruzioni dettagliate per aggiungere un'attività di connettori.
- Quando configuri l'attività del connettore, seleziona Azioni nel tipo di azione che vuoi eseguire.
- Nell'elenco Azione, seleziona Esegui query personalizzata, quindi fai clic su Fine.
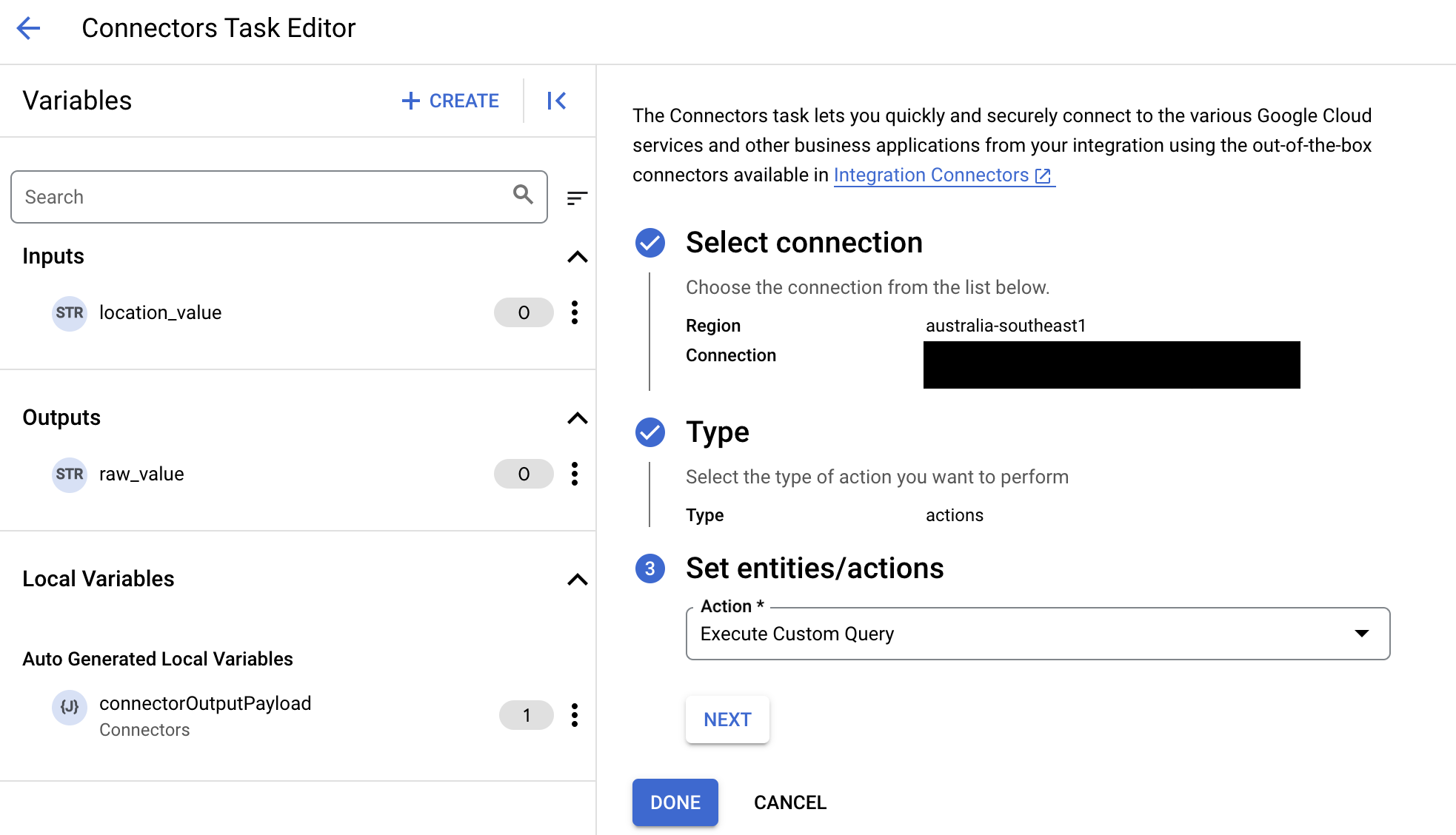
- Espandi la sezione Input attività e segui questi passaggi:
- Nel campo Timeout dopo, inserisci il numero di secondi di attesa prima dell'esecuzione della query.
Valore predefinito:
180secondi. - Nel campo Numero massimo di righe, inserisci il numero massimo di righe da restituire dal database.
Valore predefinito:
25. - Per aggiornare la query personalizzata, fai clic su Modifica script personalizzato. Si apre la finestra di dialogo Editor di script.
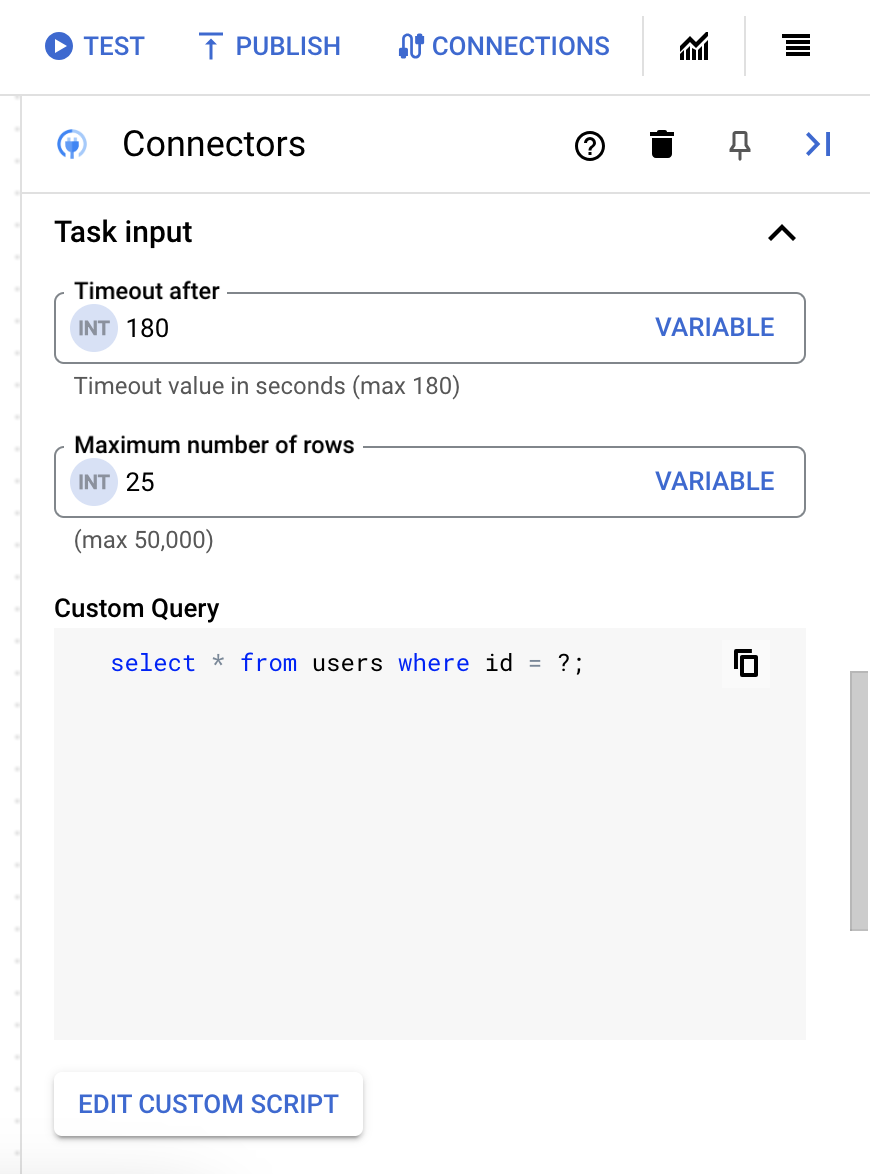
- Nella finestra di dialogo Editor script, inserisci la query SQL e fai clic su Salva.
Puoi utilizzare un punto interrogativo (?) in un'istruzione SQL per rappresentare un singolo parametro che deve essere specificato nell'elenco parametri di ricerca. Ad esempio, la seguente query SQL seleziona tutte le righe della tabella
Employeesche corrispondono ai valori specificati per la colonnaLastName:SELECT * FROM Employees where LastName=?
- Se hai utilizzato punti interrogativi nella query SQL, devi aggiungere il parametro facendo clic su + Aggiungi nome parametro per ogni punto interrogativo. Durante l'esecuzione dell'integrazione, questi parametri sostituiscono in sequenza i punti interrogativi (?) nella query SQL. Ad esempio, se hai aggiunto tre punti interrogativi (?), devi aggiungere tre parametri in ordine di sequenza.
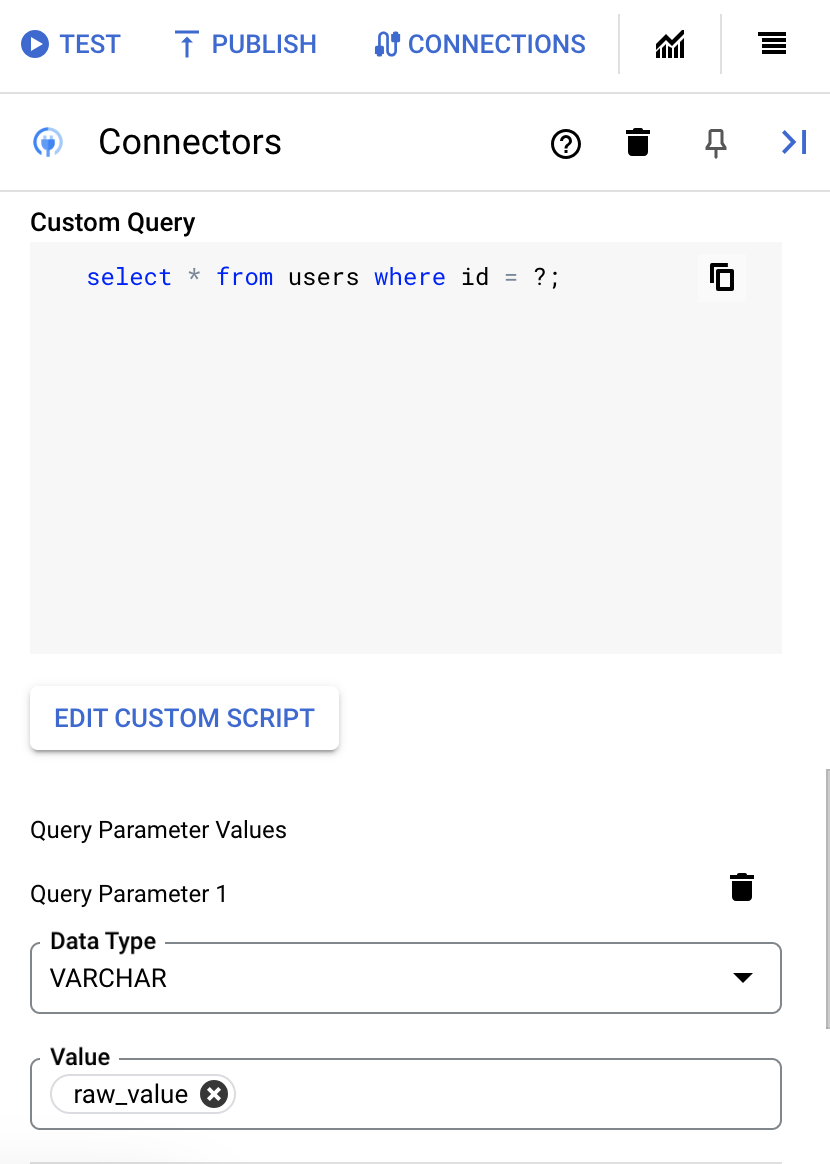
Per aggiungere parametri di ricerca:
- Nell'elenco Tipo, seleziona il tipo di dati del parametro.
- Nel campo Valore, inserisci il valore del parametro.
- Per aggiungere più parametri, fai clic su + Aggiungi parametro di query.
L'azione Esegui query personalizzata non supporta le variabili array.
- Nel campo Timeout dopo, inserisci il numero di secondi di attesa prima dell'esecuzione della query.
Utilizzare Terraform per creare connessioni
Puoi utilizzare la risorsa Terraform per creare una nuova connessione.
Per scoprire come applicare o rimuovere una configurazione Terraform, consulta Comandi Terraform di base.
Per visualizzare un template Terraform di esempio per la creazione di connessioni, consulta template di esempio.
Quando crei questa connessione utilizzando Terraform, devi impostare le seguenti variabili nel file di configurazione Terraform:
| Nome parametro | Tipo di dati | Obbligatorio | Descrizione |
|---|---|---|---|
| project_id | STRING | Vero | L'ID del progetto contenente il set di dati BigQuery. Ad esempio, myproject. |
| dataset_id | STRING | Falso | ID del set di dati BigQuery senza il nome del progetto. Ad esempio, mydataset. |
| proxy_enabled | BOOLEANO | Falso | Seleziona questa casella di controllo per configurare un server proxy per la connessione. |
| proxy_auth_scheme | ENUM | Falso | Il tipo di autenticazione da utilizzare per l'autenticazione al proxy ProxyServer. I valori supportati sono: BASIC, DIGEST, NONE |
| proxy_user | STRING | Falso | Un nome utente da utilizzare per l'autenticazione al proxy ProxyServer. |
| proxy_password | SECRET | Falso | Una password da utilizzare per l'autenticazione al proxy ProxyServer. |
| proxy_ssltype | ENUM | Falso | Il tipo di SSL da utilizzare per la connessione al proxy ProxyServer. I valori supportati sono: AUTO, ALWAYS, NEVER, TUNNEL |
Limitazioni di sistema
Il connettore BigQuery può elaborare un massimo di 8 transazioni al secondo, per nodo e limita qualsiasi transazione oltre questo limite. Per impostazione predefinita, Integration Connectors alloca due nodi (per una migliore disponibilità) per una connessione.
Per informazioni sui limiti applicabili a Integration Connectors, vedi Limiti.
Tipi di dati supportati
Di seguito sono riportati i tipi di dati supportati per questo connettore:
- ARRAY
- BIGINT
- BINARY
- BIT
- BOOLEANO
- CHAR
- DATA
- DECIMALE
- DOUBLE
- FLOAT
- INTEGER
- LONGN VARCHAR
- LONG VARCHAR
- NCHAR
- NUMERIC
- NVARCHAR
- REAL
- SMALL INT
- TEMPO
- TIMESTAMP
- TINY INT
- VARBINARY
- VARCHAR
Limitazioni note
-
Il connettore BigQuery non supporta la chiave primaria in una tabella BigQuery. Ciò significa che non puoi eseguire le operazioni di recupero, aggiornamento ed eliminazione delle entità utilizzando un
entityId. In alternativa, puoi utilizzare la clausola di filtro per filtrare i record in base a un ID. -
Quando recuperi i dati per la prima volta, potresti riscontrare una latenza iniziale di circa 6 secondi. A causa della memorizzazione nella cache, non si verifica alcuna latenza per le richieste successive. Questa latenza può ripresentarsi alla scadenza della cache.
Ricevere assistenza dalla community Google Cloud
Puoi pubblicare le tue domande e discutere di questo connettore nella community di Google Cloud nei forum di Cloud.
Passaggi successivi
- Scopri come sospendere e ripristinare una connessione.
- Scopri come monitorare l'utilizzo dei connettori.
- Scopri come visualizzare i log dei connettori.