BigQuery
Use o conector do BigQuery para realizar operações de inserção, exclusão, atualização e leitura em dados do Google BigQuery. Também é possível executar consultas SQL personalizadas em dados do BigQuery. É possível usar o conector do BigQuery para integrar dados de vários serviços do Google Cloud ou de terceiros, como o Cloud Storage ou o Amazon S3.
Antes de começar
No seu projeto do Google Cloud, faça o seguinte:
- Verifique se a conectividade de rede está configurada. Para informações sobre padrões de rede, consulte Conectividade de rede.
- Conceda o papel do IAM roles/connectors.admin ao usuário que está configurando o conector.
- Conceda o papel do IAM
roles/bigquery.dataEditorà conta de serviço que você quer usar para o conector. Se você não tiver uma conta de serviço, será necessário criar uma. O conector e a conta de serviço precisam pertencer ao mesmo projeto. - Ative os seguintes serviços:
secretmanager.googleapis.com(API Secret Manager)connectors.googleapis.com(API Connectors)
Para entender como ativar os serviços, consulte Como ativar serviços. Se esses serviços ou permissões não tiverem sido ativados no seu projeto, você precisará ativá-los ao configurar o conector.
Criar uma conexão do BigQuery
Uma conexão é específica a uma fonte de dados. Isso significa que, se você tiver muitas fontes de dados, precisará criar uma conexão separada para cada uma. Para criar uma conexão, faça o seguinte:
- No console do Cloud, acesse a página Integration Connectors > Conexões e selecione ou crie um projeto do Google Cloud.
- Clique em + CRIAR NOVO para abrir a página Criar conexão.
- Na seção Local, selecione uma opção na lista Região e clique em PRÓXIMA.
Para conferir a lista de todas as regiões com suporte, consulte Locais.
- Na seção Detalhes da conexão, faça o seguinte:
- Selecione BigQuery na lista Conector.
- Selecione uma versão do conector na lista Versão do conector.
- No campo Nome da conexão, insira um nome para a instância de conexão. O nome da conexão pode conter letras minúsculas, números ou hífens. O nome precisa começar com uma letra e terminar com uma letra ou um número, e não pode ter mais de 49 caracteres.
- Se quiser, ative o Cloud Logging e selecione um nível de registro. Por padrão, o nível de registro é definido como
Error. - Conta de serviço: selecione uma conta de serviço que tenha os papéis necessários.
- (Opcional) Defina as Configurações do nó de conexão.
- Número mínimo de nós: digite o número mínimo de nós de conexão.
- Número máximo de nós: digite o número máximo de nós de conexão.
- ID do projeto: insira o ID do projeto do Google Cloud em que os dados estão armazenados.
- ID do conjunto de dados: insira o ID do conjunto de dados do BigQuery.
- Para oferecer suporte ao tipo de dados de matriz do BigQuery, selecione Suporte a tipos de dados nativos. Os seguintes tipos de matriz são compatíveis: Varchar, Int64, Float64, Long, Double, Bool e Timestamp. Não é possível usar matrizes aninhadas.
- (Opcional) Para configurar um servidor proxy para a conexão, selecione Usar proxy e insira os detalhes do proxy.
-
Esquema de autenticação de proxy: selecione o tipo de autenticação para autenticar com o servidor proxy. Há compatibilidade com os seguintes tipos de autenticação:
- Básico: autenticação HTTP básica.
- Resumo: autenticação HTTP de resumo.
- Usuário proxy: um nome de usuário a ser usado para autenticar com o servidor proxy.
- Senha de proxy: a chave secreta do Secret Manager da senha do usuário.
-
Tipo de SSL de proxy: o tipo de SSL a ser usado para se conectar ao servidor proxy. Há compatibilidade com os seguintes tipos de autenticação:
- Automático: configuração padrão. Se o URL for HTTPS, a opção Túnel será usada. Se o URL for HTTP, a opção NUNCA será usada.
- Sempre: a conexão será sempre com SSL ativado.
- Nunca: a conexão não está com SSL ativado.
- Túnel: a conexão é feita por um proxy de encapsulamento. O servidor proxy abre uma conexão com o host remoto e o tráfego flui de ida e volta pelo proxy.
- Na seção Servidor proxy, insira os detalhes do servidor proxy.
- Clique em + Adicionar destino.
- Selecione um Tipo de destino.
- Endereço do host: especifique o nome do host ou o endereço IP do destino.
Se quiser estabelecer uma conexão privada com seu sistema de back-end, faça o seguinte:
- Crie um anexo do serviço PSC.
- Crie um anexo de endpoint e insira os detalhes dele no campo Endereço do host.
- Endereço do host: especifique o nome do host ou o endereço IP do destino.
- Clique em PRÓXIMA.
Um nó é uma unidade (ou réplica) de uma conexão que processa transações. Mais nós são necessários para processar mais transações para uma conexão e, por outro lado, menos nós são necessários para processar menos transações. Para entender como os nós afetam os preços do conector, consulte Preços dos nós de conexão. Se você não inserir qualquer valor, por padrão, os nós mínimos serão definidos como 2 (para melhor disponibilidade) e os nós máximos serão definidos como 50.
-
Na seção Autenticação, insira os detalhes da autenticação.
- Selecione se quer fazer a autenticação com o código de autorização do OAuth 2.0 ou continuar sem autenticação.
Para entender como configurar a autenticação, consulte Configurar autenticação.
- Clique em PRÓXIMA.
- Selecione se quer fazer a autenticação com o código de autorização do OAuth 2.0 ou continuar sem autenticação.
- Revise os detalhes de conexão e autenticação e clique em Criar.
Configurar a autenticação
Digite os detalhes com base na autenticação que você quer usar.
- Nenhuma autenticação: selecione essa opção se você não precisar de autenticação.
- OAuth 2.0 - Código de autorização: selecione essa opção para autenticar usando um fluxo de login do usuário baseado na Web. Especifique os seguintes detalhes:
- ID do cliente : o ID do cliente necessário para se conectar ao seu serviço do Google de back-end.
- Escopos : uma lista separada por vírgulas dos escopos desejados. Para conferir todos os escopos do OAuth 2.0 compatíveis com o Serviço do Google necessário, consulte a seção relevante na página Escopos do OAuth 2.0 para APIs do Google.
- Chave secreta do cliente: selecione a chave Gerenciador de secrets. É necessário criar a chave secreta do Secret Manager antes de configurar esta autorização.
- Versão do secret: a versão do secret do cliente no Secret Manager.
Para o tipo de autenticação Authorization code, depois de criar a conexão, autorize a conexão.
Autorizar a conexão
Se você usar o OAuth 2.0 (código de autorização) para autenticar a conexão, conclua as seguintes tarefas depois de criar a conexão.
- Na página "Conexões",
localiza a conexão recém-criada.
O Status do novo conector será Autorização necessária.
- Clique em Autorização necessária.
O painel Editar autorização é exibido.
- Copie o valor de URI de redirecionamento para seu aplicativo externo.
- Verifique os detalhes da autorização.
- Clique em Autorizar.
Se a autorização for bem-sucedida, o status da conexão será definido como Ativo na página "Conexões".
Reautorização do código de autorização
Se você estiver usando o tipo de autenticação Authorization code e tiver feito alterações de configuração no BigQuery,
será necessário autorizar novamente a conexão do BigQuery. Para reautorizar uma conexão, siga estas etapas:
- Clique na conexão desejada na página "Conexões".
A página de detalhes da conexão será aberta.
- Clique em Editar para mudar os detalhes da conexão.
- Verifique os detalhes do Código de autorização do OAuth 2.0 na seção Autenticação.
Se necessário, faça as mudanças necessárias.
- Clique em Salvar. Isso leva você à página de detalhes da conexão.
- Clique em Editar autorização na seção Autenticação. O painel Autorizar é exibido.
- Clique em Autorizar.
Se a autorização for concluída, o status da conexão será definido como Ativo na página "Conexões".
Usar a conexão do BigQuery em uma integração
Depois de criar a conexão, ela fica disponível na integração da Apigee e no Application Integration. É possível usar a conexão em uma integração com a tarefa "Conectores".
- Para entender como criar e usar a tarefa "Conectores" na integração da Apigee, consulte Tarefa "Conectores".
- Para entender como criar e usar a tarefa "Conectores" na Application Integration, consulte Tarefa "Conectores".
Ações
Esta seção descreve as ações disponíveis no conector do BigQuery.
Os resultados de todas as operações e ações da entidade
estarão disponíveis como uma resposta JSON no parâmetro de resposta connectorOutputPayload da tarefa Connectors
após a execução da integração.
Ação CancelJob
Essa ação permite cancelar um job do BigQuery em execução.
A tabela a seguir descreve os parâmetros de entrada da ação CancelJob.
| Nome do parâmetro | Tipo de dados | Descrição |
|---|---|---|
| JobId | String | O ID do job que você quer cancelar. Este campo é obrigatório. |
| Região | String | A região em que o job está sendo executado. Isso não é necessário se o job for de uma região dos EUA ou da UE. |
Ação GetJob
Essa ação permite recuperar as informações de configuração e o estado de execução de um job atual.
A tabela a seguir descreve os parâmetros de entrada da ação GetJob.
| Nome do parâmetro | Tipo de dados | Descrição |
|---|---|---|
| JobId | String | O ID do job para o qual você quer recuperar a configuração. Este campo é obrigatório. |
| Região | String | A região em que o job está sendo executado. Isso não é necessário se o job for de uma região dos EUA ou da UE. |
Ação InsertJob
Essa ação permite inserir um job do BigQuery, que pode ser selecionado mais tarde para recuperar os resultados da consulta.
A tabela a seguir descreve os parâmetros de entrada da ação InsertJob.
| Nome do parâmetro | Tipo de dados | Descrição |
|---|---|---|
| Consulta | String | A consulta a ser enviada ao BigQuery. Este campo é obrigatório. |
| IsDML | String | Precisa ser definido como true se a consulta for uma instrução DML ou false caso contrário. O valor padrão é false. |
| DestinationTable | String | A tabela de destino da consulta, no formato DestProjectId:DestDatasetId.DestTable. |
| WriteDisposition | String | Especifica como gravar dados na tabela de destino, como truncar resultados atuais, anexar resultados atuais ou gravar apenas quando a tabela estiver vazia. Confira os valores aceitos:
|
| DryRun | String | Especifica se a execução do job é um dry run. |
| MaximumBytesBilled | String | Especifica o número máximo de bytes que podem ser processados pelo job. O BigQuery cancela o job se ele tentar processar mais bytes do que o valor especificado. |
| Região | String | Especifica a região em que o job será executado. |
Ação InsertLoadJob
Essa ação permite inserir um job de carregamento do BigQuery, que adiciona dados do Google Cloud Storage a uma tabela existente.
A tabela a seguir descreve os parâmetros de entrada da ação InsertLoadJob.
| Nome do parâmetro | Tipo de dados | Descrição |
|---|---|---|
| SourceURIs | String | Uma lista de URIs do Google Cloud Storage separada por espaços. |
| SourceFormat | String | O formato de origem dos arquivos. Confira os valores aceitos:
|
| DestinationTable | String | A tabela de destino da consulta, no formato DestProjectId.DestDatasetId.DestTable. |
| DestinationTableProperties | String | Um objeto JSON que especifica o nome amigável, a descrição e a lista de rótulos da tabela. |
| DestinationTableSchema | String | Uma lista JSON que especifica os campos usados para criar a tabela. |
| DestinationEncryptionConfiguration | String | Um objeto JSON que especifica as configurações de criptografia do KMS para a tabela. |
| SchemaUpdateOptions | String | Uma lista JSON que especifica as opções a serem aplicadas ao atualizar o esquema da tabela de destino. |
| TimePartitioning | String | Um objeto JSON que especifica o tipo e o campo de particionamento por tempo. |
| RangePartitioning | String | Um objeto JSON que especifica o campo e os intervalos de particionamento por intervalo. |
| Clustering | String | Um objeto JSON que especifica os campos a serem usados para clustering. |
| Detectar automaticamente | String | Especifica se as opções e o esquema devem ser determinados automaticamente para arquivos JSON e CSV. |
| CreateDisposition | String | Especifica se a tabela de destino precisa ser criada caso ainda não exista. Confira a seguir os valores aceitos:
|
| WriteDisposition | String | Especifica como gravar dados na tabela de destino, como truncar resultados atuais, anexar resultados atuais ou gravar apenas quando a tabela estiver vazia. Confira a seguir os valores aceitos:
|
| Região | String | Especifica a região em que o job será executado. Os recursos do Google Cloud Storage e o conjunto de dados do BigQuery precisam estar na mesma região. |
| DryRun | String | Especifica se a execução do job é um dry run. O valor padrão é false. |
| MaximumBadRecords | String | Especifica o número de registros que podem ser inválidos antes que todo o job seja cancelado. Por padrão, todos os registros precisam ser válidos. O valor padrão é 0. |
| IgnoreUnknownValues | String | Especifica se os campos desconhecidos precisam ser ignorados no arquivo de entrada ou tratados como erros. Por padrão, eles são tratados como erros. O valor padrão é false. |
| AvroUseLogicalTypes | String | Especifica se os tipos lógicos AVRO precisam ser usados para converter dados AVRO em tipos do BigQuery. O valor padrão é true. |
| CSVSkipLeadingRows | String | Especifica quantas linhas ignorar no início dos arquivos CSV. Isso geralmente é usado para ignorar linhas de cabeçalho. |
| CSVEncoding | String | Tipo de codificação dos arquivos CSV. Confira os valores aceitos:
|
| CSVNullMarker | String | Se fornecida, essa string será usada para valores NULL em arquivos CSV. Por padrão, arquivos CSV não podem usar NULL. |
| CSVFieldDelimiter | String | O caractere usado para separar colunas em arquivos CSV. O valor padrão é uma vírgula (,). |
| CSVQuote | String | O caractere usado para campos entre aspas em arquivos CSV. Pode ser definido como vazio para desativar a inclusão de aspas. O valor padrão é aspas duplas ("). |
| CSVAllowQuotedNewlines | String | Especifica se os arquivos CSV podem conter novas linhas dentro de campos entre aspas. O valor padrão é false. |
| CSVAllowJaggedRows | String | Especifica se os arquivos CSV podem conter campos ausentes. O valor padrão é false. |
| DSBackupProjectionFields | String | Uma lista JSON de campos a serem carregados de um backup do Cloud Datastore. |
| ParquetOptions | String | Um objeto JSON que especifica as opções de importação específicas do Parquet. |
| DecimalTargetTypes | String | Uma lista JSON que informa a ordem de preferência aplicada a tipos numéricos. |
| HivePartitioningOptions | String | Um objeto JSON que especifica as opções de particionamento do lado da origem. |
Executar consulta SQL personalizada
Para criar uma consulta salva, siga estas etapas:
- Siga as instruções detalhadas para adicionar uma tarefa de conectores.
- Quando você configurar a tarefa do conector, selecione Ações no tipo de ação que você quer realizar.
- Na lista Ação, selecione Executar consulta personalizada e clique em Concluído.
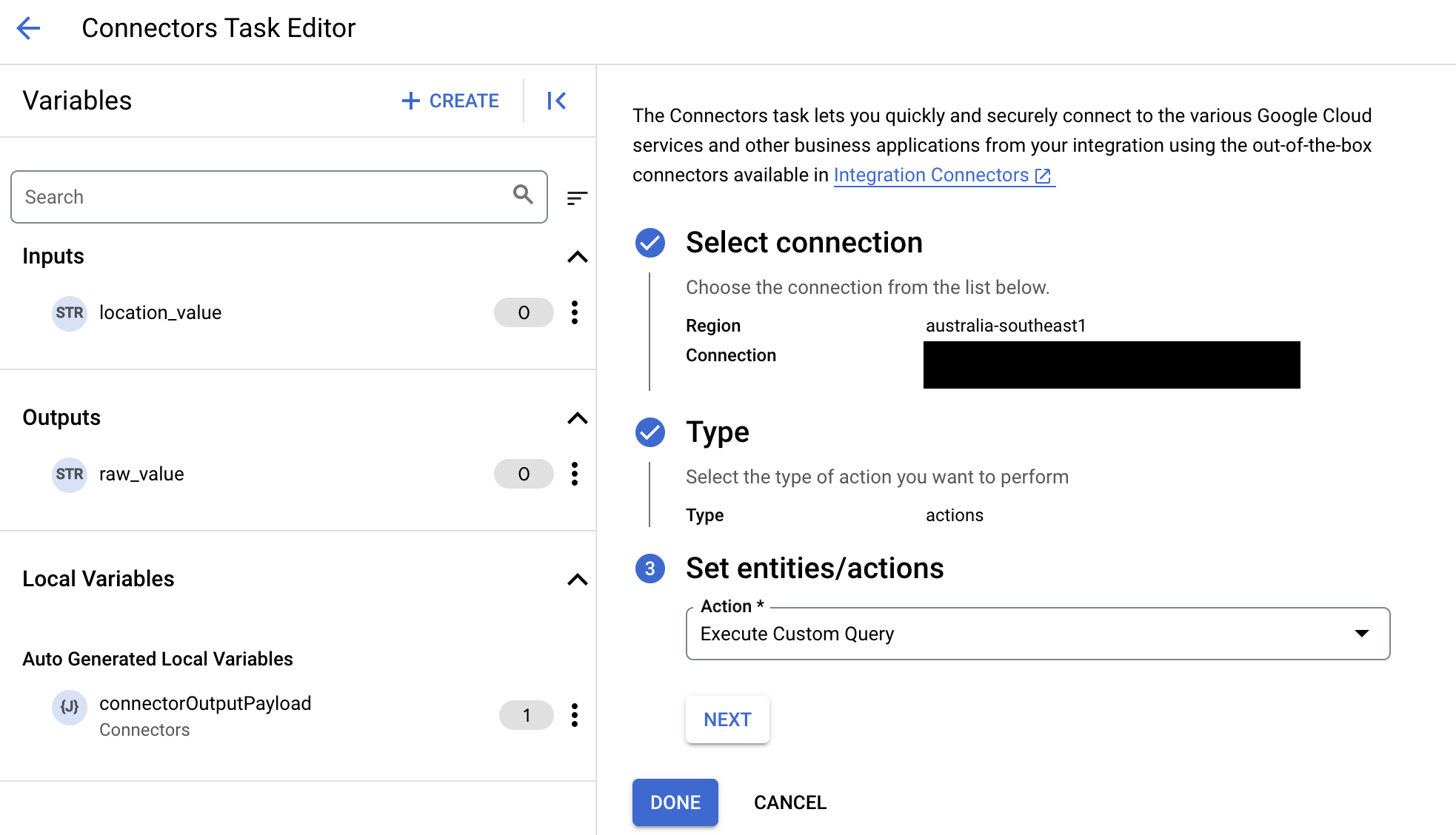
- Expanda a seção Entrada de tarefas e faça o seguinte:
- No campo Tempo limite após, digite o número de segundos de espera até que a consulta seja executada.
Valor padrão:
180segundos - No campo Número máximo de linhas, digite o número máximo de linhas a serem retornadas do banco de dados.
Valor padrão:
25. - Para atualizar a consulta personalizada, clique em Editar script personalizado. A caixa de diálogo Editor de script é aberta.
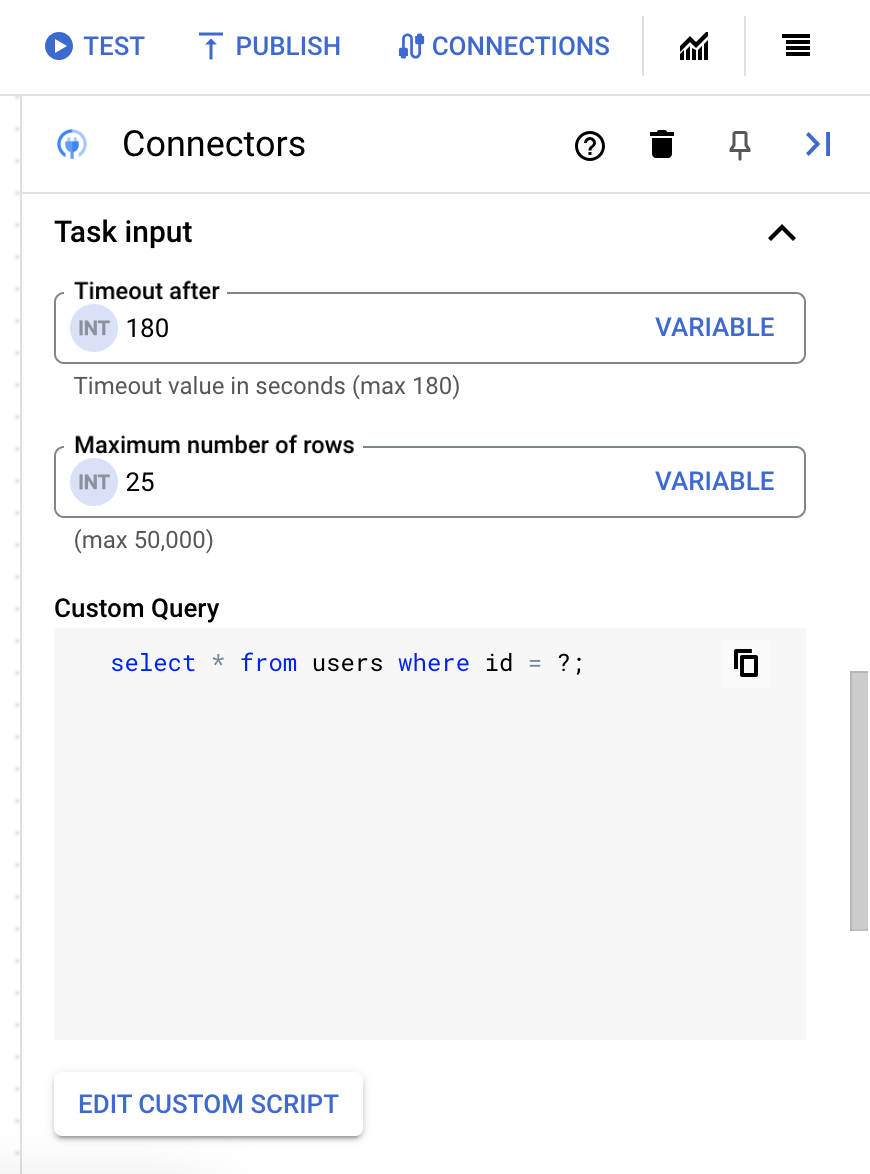
- Na caixa de diálogo Editor de script, insira a consulta SQL e clique em Salvar.
É possível usar um ponto de interrogação (?) em uma instrução SQL para representar um único parâmetro que precisa ser especificado na lista de parâmetros de consulta. Por exemplo, a seguinte consulta SQL seleciona todas as linhas da tabela
Employeesque correspondem aos valores especificados na colunaLastName:SELECT * FROM Employees where LastName=?
- Se você usou pontos de interrogação na consulta SQL, adicione o parâmetro clicando em + Adicionar nome do parâmetro para cada ponto de interrogação. Ao executar a integração, esses parâmetros substituem os pontos de interrogação (?) na consulta SQL sequencialmente. Por exemplo, se você tiver adicionado três pontos de interrogação (?), deverá adicionar três parâmetros em ordem de sequência.
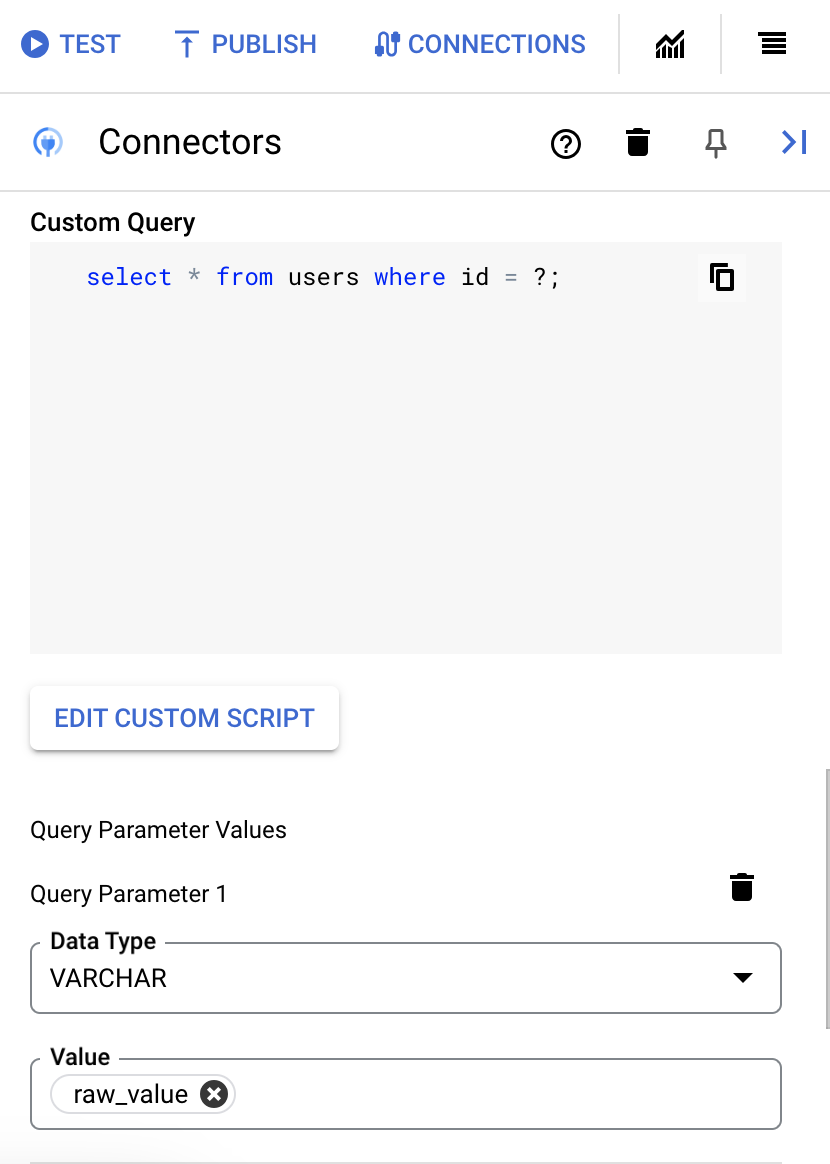
Para adicionar parâmetros de consulta, faça o seguinte:
- Na lista Tipo, selecione o tipo de dados do parâmetro.
- No campo Valor, insira o valor do parâmetro.
- Para adicionar vários parâmetros, clique em + Adicionar parâmetro de consulta.
A ação Executar consulta personalizada não é compatível com variáveis de matriz.
- No campo Tempo limite após, digite o número de segundos de espera até que a consulta seja executada.
Usar o Terraform para criar conexões
Use o recurso do Terraform para criar uma conexão.
Para saber como aplicar ou remover uma configuração do Terraform, consulte Comandos básicos do Terraform.
Para conferir um modelo de exemplo do Terraform para criação de conexão, consulte modelo de exemplo.
Ao criar essa conexão usando o Terraform, defina as seguintes variáveis no arquivo de configuração do Terraform:
| Nome do parâmetro | Tipo de dados | Obrigatório | Descrição |
|---|---|---|---|
| project_id | STRING | Verdadeiro | O ID do projeto que contém o conjunto de dados do BigQuery, por exemplo, myproject. |
| dataset_id | STRING | Falso | ID do conjunto de dados do BigQuery sem o nome do projeto. Por exemplo, mydataset. |
| proxy_enabled | BOOLEAN | Falso | Marque esta caixa de seleção para configurar um servidor proxy para a conexão. |
| proxy_auth_scheme | ENUM | Falso | O tipo de autenticação a ser usado para autenticar o proxy ProxyServer. Os valores aceitos são: BASIC, DIGEST, NONE |
| proxy_user | STRING | Falso | Um nome de usuário a ser usado para autenticar no proxy ProxyServer. |
| proxy_password | SECRET | Falso | Uma senha a ser usada para autenticar no proxy ProxyServer. |
| proxy_ssltype | ENUM | Falso | O tipo de SSL a ser usado ao se conectar ao proxy ProxyServer. Os valores aceitos são: AUTO, ALWAYS, NEVER, TUNNEL |
Limitações do sistema
O conector do BigQuery pode processar no máximo oito transações por segundo, por nó, e limita qualquer transação além desse limite. Por padrão, o Integration Connectors aloca dois nós (para melhor disponibilidade) para uma conexão.
Para informações sobre os limites aplicáveis aos Integration Connectors, consulte Limites.
Tipos de dados compatíveis
Estes são os tipos de dados compatíveis com esse conector:
- ARRAY
- BIGINT
- Binário
- BIT
- BOOLEAN
- CHAR
- DATE
- DECIMAL
- DOUBLE
- FLOAT
- INTEGER
- LONGN VARCHAR
- LONG VARCHAR
- NCHAR
- NUMERIC
- NVARCHAR
- REAL
- SMALL INT
- TIME
- TIMESTAMP
- TINY INT
- VARBINARY
- VARCHAR
Limitações conhecidas
-
O conector do BigQuery não oferece suporte à chave primária em uma tabela do BigQuery. Isso significa que não é possível realizar as operações de entidade Get, Update e Delete usando um
entityId. Como alternativa, use a cláusula de filtro para filtrar registros com base em um ID. -
Ao buscar dados pela primeira vez, você pode ter uma latência inicial de cerca de seis segundos. Devido ao cache, não há latência para solicitações subsequentes. Essa latência pode ocorrer novamente quando o cache expirar.
Receber ajuda da comunidade do Google Cloud
Poste suas dúvidas e converse sobre esse conector na comunidade do Google Cloud em Fóruns do Cloud.
A seguir
- Entenda como suspender e retomar uma conexão.
- Entenda como monitorar o uso do conector.
- Saiba como ver os registros do conector.