This page explains how to use Cloud Logging and Cloud Monitoring as well as Prometheus and Grafana for logging and monitoring of your Google Distributed Cloud implementation. For a summary of the configuration options available, see Logging and monitoring overview.
Using Cloud Logging and Cloud Monitoring
The following sections explain how to use Cloud Logging and Cloud Monitoring with Google Distributed Cloud clusters.
Monitored resources
Monitored resources are how Google represents resources such as clusters, nodes, Pods, and containers. To learn more, refer to Cloud Monitoring's Monitored resource types documentation.
To query for logs and metrics, you'll need to know at least these resource labels:
project_id: Project ID for the ID of the cluster's logging-monitoring project. You provided this value in thestackdriver.projectIDfield of your cluster configuration file.location: A Google Cloud region where you want to store Cloud Logging logs and Cloud Monitoring metrics. It's a good idea to choose a region that is near your on-premises data center. You provided this value during installation in thestackdriver.clusterLocationfield of your cluster configuration file.cluster_name: Cluster name that you chose when you created the cluster.You can retrieve the
cluster_namevalue for either the admin or the user cluster by inspecting the Stackdriver custom resource:kubectl -n kube-system get stackdrivers stackdriver -o yaml | grep 'clusterName:'
Accessing log data
You can access logs using the Logs Explorer in Google Cloud console. For example, to access a container's logs:
- Open the Logs Explorer in Google Cloud console for your project.
- Find logs for a container by:
- Clicking on the top-left log catalog drop-down box and selecting Kubernetes Container.
- Selecting the cluster name, then the namespace, and then a container from the hierarchy.
Creating dashboards to monitor cluster health
Google Distributed Cloud clusters are, by default, configured to monitor system and container metrics. After you create a cluster (admin or user), a best practice is to create the following dashboards with Cloud Monitoring to let your Google Distributed Cloud operations team monitor cluster health:
- Control plane status dashboard
- Pod status dashboard
- Node status dashboard
- VM health status dashboard
The dashboards are automatically created during admin cluster installation if Cloud Monitoring is enabled.
This section describes how to create these dashboards. For more information about the dashboard creation process described in the following sections, see Managing dashboards by API.
Prerequisites
Your Google Account must have the following permissions to create dashboards:
monitoring.dashboards.createmonitoring.dashboards.deletemonitoring.dashboards.update
You'll have these permissions if your account has one of the following roles. You can check your permissions (in the Google Cloud console):
monitoring.dashboardEditormonitoring.editor- Project
editor - Project
owner
In addition, to use gcloud (gcloud CLI) to create dashboards, your Google Account must have the serviceusage.services.use permission.
Your account will have this permission if it has one of the following roles:
roles/serviceusage.serviceUsageConsumerroles/serviceusage.serviceUsageAdminroles/ownerroles/editor- Project
editor - Project
owner
Create a control plane status dashboard
The Google Distributed Cloud control plane consists of the API server, scheduler, controller manager, and etcd. To monitor the status of the control plane, create a dashboard that monitors the state of these components.
Download the dashboard configuration:
control-plane-status.json.Create a custom dashboard with the configuration file by running the following command:
gcloud monitoring dashboards create --config-from-file=control-plane-status.json
In the Google Cloud console, select Monitoring, or use the following button:
Select Resources > Dashboards and view the dashboard named GKE on-prem control plane status. The control plane status of each user cluster is collected from separate namespaces within the admin cluster. The namespace_name field is the user cluster name.
An service level objective (SLO) threshold of 0.999 is set in each chart.
Optionally create alerting policies.
Click to see a sample dashboard.

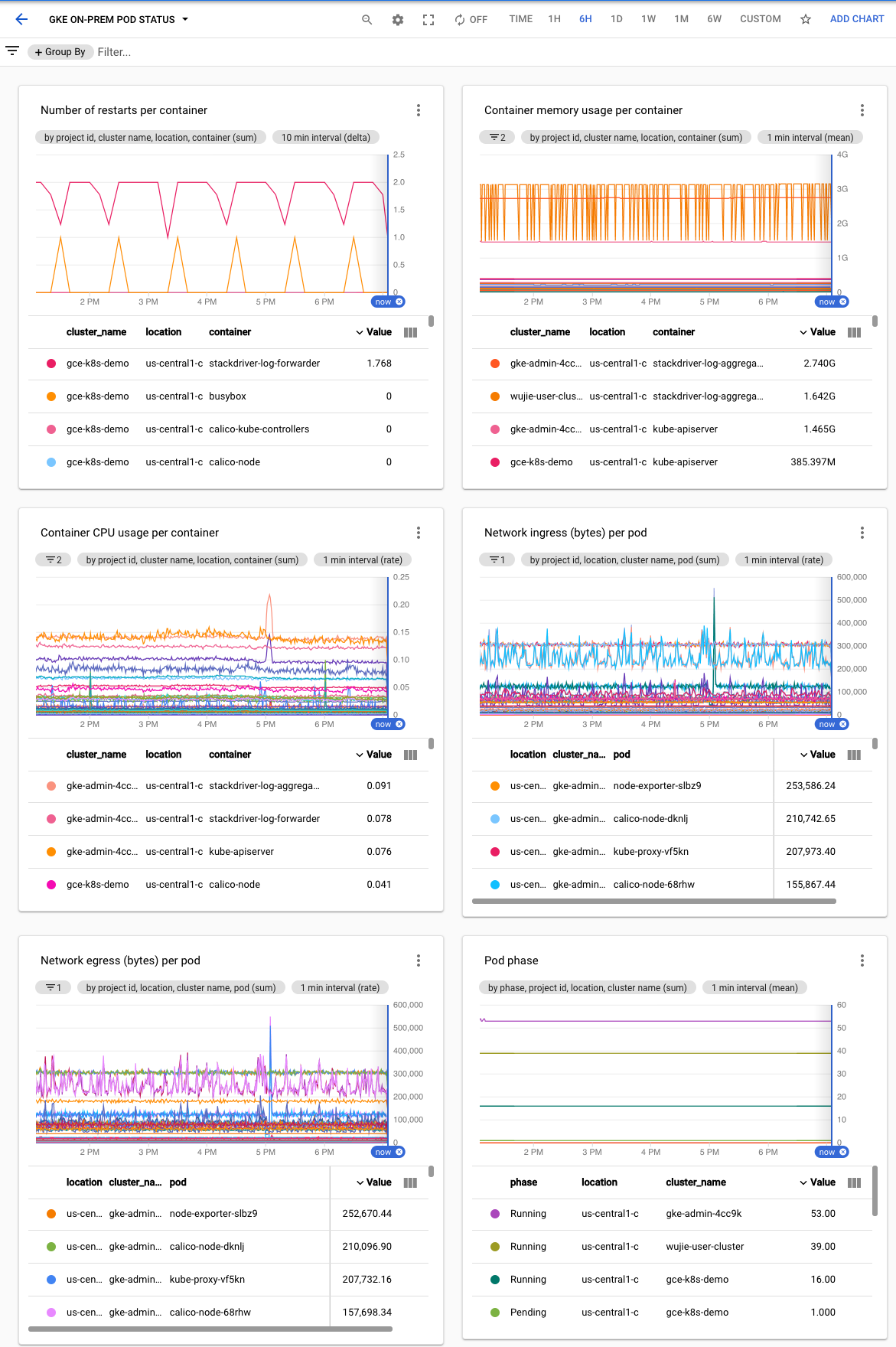
Create a pod status dashboard
To create a dashboard that includes the phase of each Pod, and the restart times and resource usage of each container, perform the following steps.
Download the dashboard configuration:
pod-status.json.Create a custom dashboard with the configuration file by running the following command:
gcloud monitoring dashboards create --config-from-file=pod-status.json
In the Google Cloud console, select Monitoring, or use the following button:
Select Resources > Dashboards and view the dashboard named GKE on-prem pod status.
Optionally create alerting policies.
Click to see a sample dashboard.
Create a node status dashboard
To create an node status dashboard to monitor the node condition, CPU, memory and disk usage, perform the following steps:
Download the dashboard configuration:
node-status.json.Create a custom dashboard with the configuration file by running the following command:
gcloud monitoring dashboards create --config-from-file=node-status.json
In the Google Cloud console, select Monitoring, or use the following button:
Select Resources > Dashboards and view the dashboard named GKE on-prem node status.
Optionally create alerting policies.
Click to see a sample dashboard.

Create a VM health status dashboard
A VM health status dashboard monitors CPU, memory, and disk resource contention signals for VMs in the admin cluster and user clusters.
To create an VM health status dashboard:
Make sure
stackdriver.disableVsphereResourceMetricsis set to false. See User cluster configuration file.Download the dashboard configuration:
vm-health-status.json.Create a custom dashboard with the configuration file by running the following command:
gcloud monitoring dashboards create --config-from-file=vm-health-status.json
In the Google Cloud console, select Monitoring, or use the following button:
Select Resources > Dashboards and view the dashboard named GKE on-prem VM health status.
Optionally create alerting policies.
Click to see a sample dashboard.

Configuring Stackdriver component resources
When you create a cluster, Google Distributed Cloud automatically creates a Stackdriver custom resource. You can edit the spec in the custom resource to override the default values for CPU and memory requests and limits for a Stackdriver component, and you can separately override the default storage size and storage class.
Override default values for requests and limits for CPU and memory
To override these defaults, do the following:
Open your Stackdriver custom resource in a command line editor:
kubectl --kubeconfig=KUBECONFIG -n kube-system edit stackdriver stackdriver
where KUBECONFIG is the path to your kubeconfig file for the cluster. This can be either an admin cluster or user cluster.
In the Stackdriver custom resource, add the
resourceAttrOverridefield under thespecsection:resourceAttrOverride: POD_NAME_WITHOUT_RANDOM_SUFFIX/CONTAINER_NAME: LIMITS_OR_REQUESTS: RESOURCE: RESOURCE_QUANTITYNote that the
resourceAttrOverridefield overrides all existing default limits and requests for the component you specify. An example file looks like the following:apiVersion: addons.sigs.k8s.io/v1alpha1 kind: Stackdriver metadata: name: stackdriver namespace: kube-system spec: projectID: my-project clusterName: my-cluster clusterLocation: us-west-1a resourceAttrOverride: stackdriver-prometheus-k8s/prometheus-server: limits: cpu: 500m memory: 3000Mi requests: cpu: 300m memory: 2500MiSave changes and quit your command line editor.
Check the health of your Pods:
kubectl --kubeconfig=KUBECONFIG -n kube-system get pods | grep stackdriver
For example, a healthy Pod looks like the following:
stackdriver-prometheus-k8s-0 2/2 Running 0 5d19h
Check the Pod spec of the component to make sure the resources are set correctly.
kubectl --kubeconfig=KUBECONFIG -n kube-system describe pod POD_NAME
where
POD_NAMEis the name of the Pod you just changed. For example,stackdriver-prometheus-k8s-0The response looks like the following:
Name: stackdriver-prometheus-k8s-0 Namespace: kube-system ... Containers: prometheus-server: Limits: cpu: 500m memory: 3000Mi Requests: cpu: 300m memory: 2500Mi ...
Override storage size defaults
To override these defaults, do the following:
Open your Stackdriver custom resource in a command line editor:
kubectl --kubeconfig=KUBECONFIG -n kube-system edit stackdriver stackdriver
Add the
storageSizeOverridefield under thespecsection. You can use the componentstackdriver-prometheus-k8sorstackdriver-prometheus-app. The section takes this format:storageSizeOverride: STATEFULSET_NAME: SIZE
This example uses the statefulset
stackdriver-prometheus-k8sand size120Gi.apiVersion: addons.sigs.k8s.io/v1alpha1 kind: Stackdriver metadata: name: stackdriver namespace: kube-system spec: projectID: my-project clusterName: my-cluster clusterLocation: us-west-1a storageSizeOverride: stackdriver-prometheus-k8s: 120GiSave, and quit your command line editor.
Check the health of your Pods:
kubectl --kubeconfig=KUBECONFIG -n kube-system get pods | grep stackdriver
For example, a healthy Pod looks like the following:
stackdriver-prometheus-k8s-0 2/2 Running 0 5d19h
Check the Pod spec of the component to make sure the storage size is correctly overridden.
kubectl --kubeconfig=KUBECONFIG -n kube-system describe statefulset STATEFULSET_NAME
The response looks like the following:
Volume Claims: Name: my-statefulset-persistent-volume-claim StorageClass: my-storage-class Labels: Annotations: Capacity: 120Gi Access Modes: [ReadWriteOnce]
Override storage class defaults
Prerequisite
You must first create a StorageClass you want to use.
To override the default storage class for persistent volumes claimed by logging and monitoring components:
Open your Stackdriver custom resource in a command line editor:
kubectl --kubeconfig=KUBECONFIG -n kube-system edit stackdriver stackdriver
where KUBECONFIG is the path to your kubeconfig file for the cluster. This can be either an admin cluster or user cluster.
Add the
storageClassNamefield under thespecsection:storageClassName: STORAGECLASS_NAME
Note that the
storageClassNamefield overrides the existing default storage class, and applies to all logging and monitoring components with persistent volumes claimed. An example file looks like the following:apiVersion: addons.sigs.k8s.io/v1alpha1 kind: Stackdriver metadata: name: stackdriver namespace: kube-system spec: projectID: my-project clusterName: my-cluster clusterLocation: us-west-1a proxyConfigSecretName: my-secret-name enableVPC:
optimizedMetrics: true storageClassName: my-storage-class Save changes.
Check the health of your Pods:
kubectl --kubeconfig=KUBECONFIG -n kube-system get pods | grep stackdriver
For example, a healthy Pod looks like the following:
stackdriver-prometheus-k8s-0 1/1 Running 0 5d19h
Check the Pod spec of a component to make sure the storage class is set correctly.
kubectl --kubeconfig=KUBECONFIG -n kube-system describe statefulset STATEFULSET_NAME
For example, using the stateful set
stackdriver-prometheus-k8s, the response looks like the following:Volume Claims: Name: stackdriver-prometheus-data StorageClass: my-storage-class Labels: Annotations: Capacity: 120Gi Access Modes: [ReadWriteOnce]
Accessing metrics data
You can choose from over 1,500 metrics by using Metrics Explorer. To access Metrics Explorer, do the following:
In the Google Cloud console, select Monitoring, or use the following button:
Select Resources > Metrics Explorer.
Accessing Monitoring metadata
Metadata is used indirectly via metrics. When you filter for metrics in
Monitoring Metrics Explorer, you see options to filter metrics by
metadata.systemLabels and metadata.userLabels. System labels are labels such
as node name and Service name for Pods. User labels are labels assigned to Pods
in the Kubernetes YAML files in the "metadata" section of the Pod specification.
Default Cloud Monitoring quota limits
Google Distributed Cloud monitoring has a default limit of 6000 API calls per minute for each project. If you exceed this limit, your metrics may not be displayed. If you need a higher monitoring limit, request a quota adjustment.
Known issue: Cloud Monitoring error condition
(Issue ID 159761921)
Under certain conditions, the default Cloud Monitoring pod,
deployed by default in each new cluster, can become unresponsive.
When clusters are upgraded, for example, storage data can become
corrupted when pods in statefulset/prometheus-stackdriver-k8s are restarted.
Specifically, monitoring pod stackdriver-prometheus-k8s-0 can be
caught in a loop when corrupted data prevents prometheus-stackdriver-sidecar
writing to the cluster storage PersistentVolume.
You can manually diagnose and recover the error following the steps below.
Diagnosing the Cloud Monitoring failure
When the monitoring pod has failed, the logs will report the following:
{"log":"level=warn ts=2020-04-08T22:15:44.557Z caller=queue_manager.go:534 component=queue_manager msg=\"Unrecoverable error sending samples to remote storage\" err=\"rpc error: code = InvalidArgument desc = One or more TimeSeries could not be written: One or more points were written more frequently than the maximum sampling period configured for the metric.: timeSeries[0-114]; Unknown metric: kubernetes.io/anthos/scheduler_pending_pods: timeSeries[196-198]\"\n","stream":"stderr","time":"2020-04-08T22:15:44.558246866Z"}
{"log":"level=info ts=2020-04-08T22:15:44.656Z caller=queue_manager.go:229 component=queue_manager msg=\"Remote storage stopped.\"\n","stream":"stderr","time":"2020-04-08T22:15:44.656798666Z"}
{"log":"level=error ts=2020-04-08T22:15:44.663Z caller=main.go:603 err=\"corruption after 29032448 bytes: unexpected non-zero byte in padded page\"\n","stream":"stderr","time":"2020-04-08T22:15:44.663707748Z"}
{"log":"level=info ts=2020-04-08T22:15:44.663Z caller=main.go:605 msg=\"See you next time!\"\n","stream":"stderr","time":"2020-04-08T22:15:44.664000941Z"}
Recovering from the Cloud Monitoring error
To recover Cloud Monitoring manually:
Stop cluster monitoring. Scale down the
stackdriveroperator to prevent monitoring reconciliation:kubectl --kubeconfig /ADMIN_CLUSTER_KUBCONFIG --namespace kube-system scale deployment stackdriver-operator --replicas 0
Delete the monitoring pipeline workloads:
kubectl --kubeconfig /ADMIN_CLUSTER_KUBCONFIG --namespace kube-system delete statefulset stackdriver-prometheus-k8s
Delete the monitoring pipeline PersistentVolumeClaims (PVCs):
kubectl --kubeconfig /ADMIN_CLUSTER_KUBCONFIG --namespace kube-system delete pvc -l app=stackdriver-prometheus-k8s
Restart cluster monitoring. Scale up the stackdriver operator to reinstall a new monitoring pipeline and resume reconciliation:
kubectl --kubeconfig /ADMIN_CLUSTER_KUBCONFIG --namespace kube-system scale deployment stackdriver-operator --replicas=1
Prometheus and Grafana
The following sections explain how to use Prometheus and Grafana with Google Distributed Cloud clusters.
Enabling Prometheus and Grafana
Starting in Google Distributed Cloud version 1.2, you can choose whether to enable or disable Prometheus and Grafana. In new user clusters, Prometheus and Grafana are disabled by default.
Your user cluster has a Monitoring object named
monitoring-sample. Open the object for editing:kubectl --kubeconfig [USER_CLUSTER_KUBECONFIG] edit \ monitoring monitoring-sample --namespace kube-system
where [USER_CLUSTER_KUBECONFIG] is the kubeconfig file for your user cluster.
To enable Prometheus and Grafana, set
enablePrometheustotrue. To disable Prometheus and Grafana, setenablePrometheustofalse:apiVersion: addons.k8s.io/v1alpha1 kind: Monitoring metadata: labels: k8s-app: monitoring-operator name: monitoring-sample namespace: kube-system spec: channel: stable ... enablePrometheus: true
Save your changes by closing the editing session.
Known issue
In user clusters, Prometheus and Grafana get automatically disabled during upgrade. However, the configuration and metrics data are not lost.
To work around this issue, after the upgrade, open monitoring-sample for
editing and set enablePrometheus to true.
Accessing monitoring metrics from Grafana dashboards
Grafana displays metrics gathered from your clusters. To view these metrics, you need to access Grafana's dashboards:
Get the name of the Grafana Pod running in a user cluster's
kube-systemnamespace:kubectl --kubeconfig [USER_CLUSTER_KUBECONFIG] -n kube-system get pods
where [USER_CLUSTER_KUBECONFIG] is the user cluster's kubeconfig file.
The Grafana Pod has an HTTP server listening on TCP localhost port 3000. Forward a local port to port 3000 in the Pod, so that you can view Grafana's dashboards from a web browser.
For example, suppose the name of the Pod is
grafana-0. To forward port 50000 to port 3000 in the Pod, enter this command::kubectl --kubeconfig [USER_CLUSTER_KUBECONFIG] -n kube-system port-forward grafana-0 50000:3000
From a web browser, navigate to
http://localhost:50000.On the login page, enter
adminfor username and password.If login is successful, you will see a prompt to change the password. After you have changed the default password, the user cluster's Grafana Home Dashboard should load.
To access other dashboards, click the Home drop-down menu in the top-left corner of the page.
For an example of using Grafana, see Create a Grafana dashboard.
Accessing alerts
Prometheus Alertmanager collects alerts from the Prometheus server. You can view these alerts in a Grafana dashboard. To view the alerts, you need to access the dashboard:
The container in the
alertmanager-0Pod listens on TCP port 9093. Forward a local port to port 9093 in the Pod:kubectl --kubeconfig [USER_CLUSTER_KUBECONFIG] port-forward \ -n kube-system alertmanager-0 50001:9093
From a web browser, navigate to
http://localhost:50001.
Changing Prometheus Alertmanager configuration
You can change Prometheus Alertmanager's default configuration by editing your
user cluster's monitoring.yaml file. You should do this if you want to direct
alerts to a specific destination, rather than keep them in the dashboard. You
can learn how to configure Alertmanager in Prometheus'
Configuration documentation.
To change the Alertmanager configuration, perform the following steps:
Make a copy of the user cluster's
monitoring.yamlmanifest file:kubectl --kubeconfig [USER_CLUSTER_KUBECONFIG] -n kube-system \ get monitoring monitoring-sample -o yaml > monitoring.yaml
To configure Alertmanager, make changes to the fields under
spec.alertmanager.yml. When you're finished, save the changed manifest.Apply the manifest to your cluster:
kubectl apply --kubeconfig [USER_CLUSTER_KUBECONIFG] -f monitoring.yaml
Scaling Prometheus resources
The default monitoring configuration supports up to five nodes. For larger clusters, you can adjust the Prometheus Server resources. The recommendation is 50m cores of CPU and 500Mi of memory per cluster node. Make sure that your cluster contains two nodes, each with sufficient resources to fit Prometheus. For more information, refer to Resizing a user cluster.
To change Prometheus Server resources, perform the following steps:
Make a copy of the user cluster's
monitoring.yamlmanifest file:kubectl --kubeconfig [USER_CLUSTER_KUBECONFIG] -n kube-system get monitoring monitoring-sample -o yaml > monitoring.yaml
To override resources, make changes to the fields under
spec.resourceOverride. When you're finished, save the changed manifest. Example:spec: resourceOverride: - component: Prometheus resources: requests: cpu: 300m memory: 3000Mi limits: cpu: 300m memory: 3000MiApply the manifest to your cluster:
kubectl --kubeconfig [USER_CLUSTER_KUBECONFIG] apply -f monitoring.yaml
Create a Grafana dashboard
You've deployed an application that exposes a metric, verified that the metric is exposed, and verified that Prometheus scrapes the metric. Now you can add the application-level metric to a custom Grafana dashboard.
To create a Grafana dashboard, perform the following steps:
- If necessary, gain access to Grafana.
- From the Home Dashboard, click the Home drop-down menu in the top-left corner of the page.
- From the right-side menu, click New dashboard.
- From the New panel section, click Graph. An empty graph dashboard appears.
- Click Panel title, then click Edit. The bottom Graph panel opens to the Metrics tab.
- From the Data Source drop-down menu, select user. Click Add
query, and enter
fooin the search field. - Click the Back to dashboard button in the top-right corner of the screen. Your dashboard is displayed.
- To save the dashboard, click Save dashboard in the top-right corner of the screen. Choose a name for the dashboard, then click Save.
Disabling in-cluster monitoring
To disable in-cluster monitoring, revert the changes made to the
monitoring-sample object:
Open the
monitoring-sampleobject for editing:kubectl --kubeconfig USER_CLUSTER_KUBECONFIG edit \ monitoring monitoring-sample --namespace kube-system
Replace USER_CLUSTER_KUBECONFIG with the kubeconfig file for your user cluster.
To disable Prometheus and Grafana, set
enablePrometheustofalse:apiVersion: addons.k8s.io/v1alpha1 kind: Monitoring metadata: labels: k8s-app: monitoring-operator name: monitoring-sample namespace: kube-system spec: channel: stable ... enablePrometheus: falseSave your changes by closing the editing session.
Confirm that the
prometheus-0,prometheus-1andgrafana-0statefulsets have been deleted:kubectl --kubeconfig USER_CLUSTER_KUBECONFIG get pods --namespace kube-system
Example: Adding application-level metrics to a Grafana dashboard
The following sections walk you through adding metrics for an application. In this section, you complete the following tasks:
- Deploy an example application that exposes a metric called
foo. - Verify that Prometheus exposes and scrapes the metric.
- Create a custom Grafana dashboard.
Deploy the example application
The example application runs in a single Pod. The Pod's container exposes a
metric, foo, with a constant value of 40.
Create the following Pod manifest, pro-pod.yaml:
apiVersion: v1
kind: Pod
metadata:
name: prometheus-example
annotations:
prometheus.io/scrape: 'true'
prometheus.io/port: '8080'
prometheus.io/path: '/metrics'
spec:
containers:
- image: registry.k8s.io/prometheus-dummy-exporter:v0.1.0
name: prometheus-example
command:
- /bin/sh
- -c
- ./prometheus_dummy_exporter --metric-name=foo --metric-value=40 --port=8080
Then apply the Pod manifest to your user cluster:
kubectl --kubeconfig [USER_CLUSTER_KUBECONFIG] apply -f pro-pod.yaml
Verify that the metric is exposed and scraped
The container in the
prometheus-examplepod listens on TCP port 8080. Forward a local port to port 8080 in the Pod:kubectl --kubeconfig [USER_CLUSTER_KUBECONFIG] port-forward prometheus-example 50002:8080
To verify that the application exposes the metric, run the following command:
curl localhost:50002/metrics | grep fooThe command returns the following output:
# HELP foo Custom metric # TYPE foo gauge foo 40
The container in the
prometheus-0Pod listens on TCP port 9090. Forward a local port to port 9090 in the Pod:kubectl --kubeconfig [USER_CLUSTER_KUBECONFIG] port-forward prometheus-0 50003:9090
To verify that Prometheus is scraping the metric, navigate to http://localhost:50003/targets, which should take you to the
prometheus-0Pod under theprometheus-io-podstarget group.To view metrics in Prometheus, navigate to http://localhost:50003/graph. From the search field, enter
foo, then click Execute. The page should display the metric.