Questo tutorial introduce una soluzione pronta all'uso che utilizza Google Distributed Cloud (solo software) su bare metal e Config Sync per eseguire il deployment di cluster Kubernetes on edge su larga scala. Questo tutorial è rivolto a sviluppatori e operatori della piattaforma. Prima di leggere questo documento, assicurati di conoscere le seguenti tecnologie e concetti:
- Playbook Ansible.
- Deployment a livello perimetrale e relative sfide.
- Come utilizzare un progetto Google Cloud.
- Eseguire il deployment di un'applicazione web containerizzata.
- Interfacce a riga di comando
gcloudekubectl.
In questo tutorial utilizzi le macchine virtuali (VM) Compute Engine per emulare i nodi di cui è stato eseguito il deployment sul confine e un'applicazione point of sale di esempio come carico di lavoro di confine. La versione solo software di Google Distributed Cloud e Config Sync forniscono gestione e controllo centralizzati per il tuo cluster perimetrale. Config Sync recupera dinamicamente le nuove configurazioni da GitHub e applica questi criteri e configurazioni ai tuoi cluster.
Architettura di deployment a livello periferico
Un deployment di edge retail è un buon modo per illustrare l'architettura utilizzata in un tipico deployment di cluster bare metal.
Un negozio di vendita al dettaglio fisico è il punto di interazione più vicino tra un'unità aziendale e il consumatore. I sistemi software all'interno dei negozi devono eseguire i propri carichi di lavoro, ricevere aggiornamenti tempestivi e generare report sulle metriche fondamentali in isolamento dal sistema di gestione centrale dell'azienda. Inoltre, questi sistemi software devono essere progettati in modo da poter essere estesi a più sedi dei negozi in futuro. Sebbene qualsiasi implementazione di cluster bare metal soddisfi tutti questi requisiti per i sistemi software dei negozi, il profilo edge consente un caso d'uso importante: implementazioni in ambienti con risorse hardware limitate, come una vetrina di un negozio di vendita al dettaglio.
Il seguente diagramma mostra un deployment di un cluster bare metal che utilizza il profilo edge in un negozio di vendita al dettaglio:
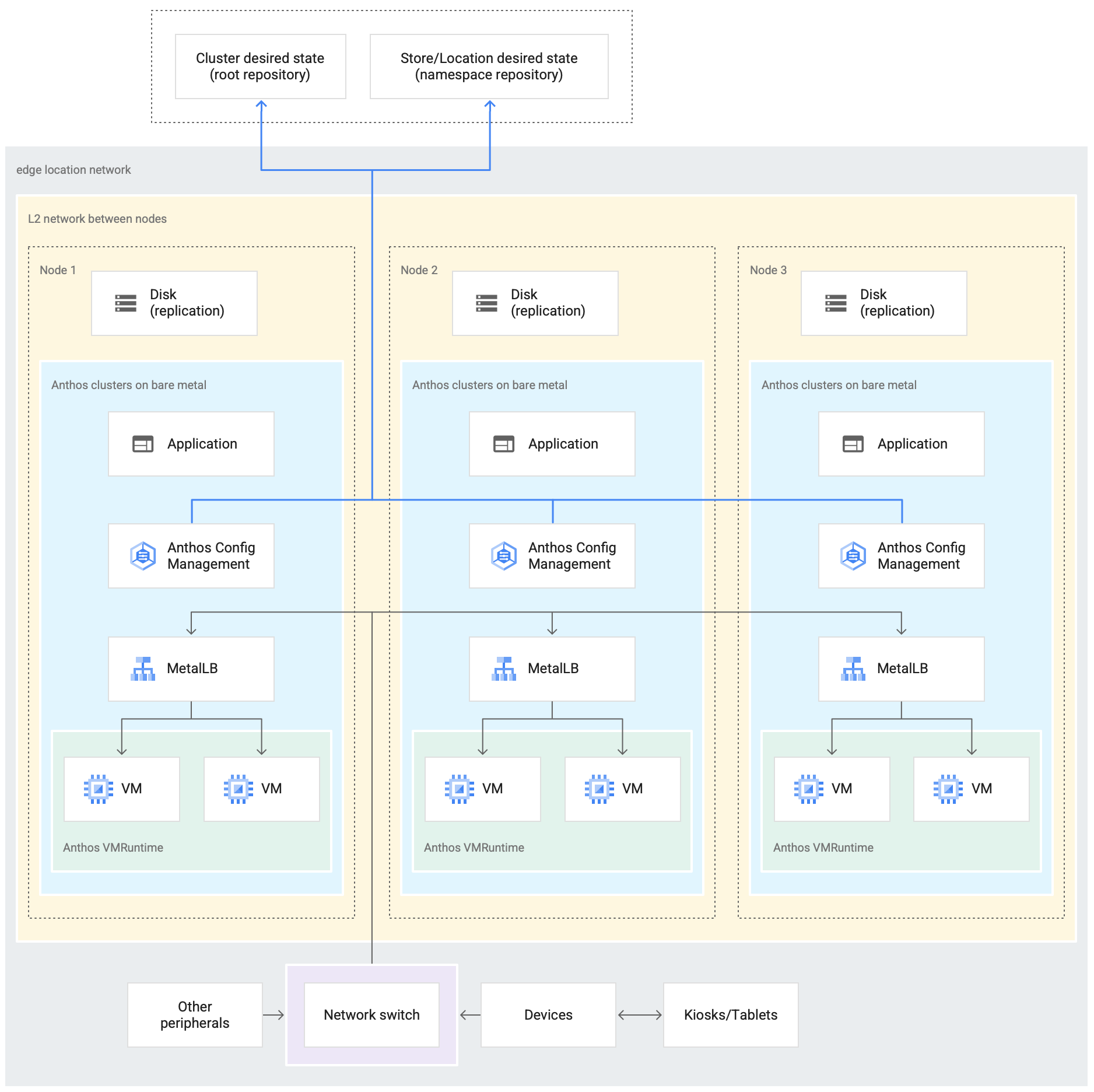
Il diagramma precedente mostra un tipico negozio di vendita al dettaglio fisico. Il negozio dispone di dispositivi intelligenti come lettori di carte, macchine point-of-sale, videocamere e stampanti. Il
magazzino dispone anche di tre dispositivi hardware di calcolo fisico (etichettati Node 1,
Node 2 e Node 3). Tutti questi dispositivi sono collegati a uno switch di rete centralizzato. Pertanto, i tre dispositivi di calcolo sono collegati tra loro tramite una rete di livello 2. I dispositivi di calcolo collegati in rete costituiscono l'infrastruttura bare metal. Il software Google Distributed Cloud viene eseguito all'interno di ciascuno dei tre dispositivi di calcolo. Questi dispositivi dispongono anche di un proprio spazio di archiviazione su disco e sono configurati per la replica dei dati tra di loro per garantire l'alta disponibilità.
Il diagramma mostra anche i seguenti componenti chiave che fanno parte di un deployment di cluster bare metal:
Il componente contrassegnato come MetalLB è il bilanciatore del carico in bundle.
Il componente Config Sync consente di sincronizzare lo stato del cluster con i repository di origine. Si tratta di un componente aggiuntivo facoltativo altamente consigliato che richiede installazione e configurazione separate. Per ulteriori informazioni su come configurare Config Sync e sulla diversa nomenclatura, consulta la documentazione di Config Sync.
Il repository principale e il repository dello spazio dei nomi mostrati nella parte superiore del diagramma al di fuori della sede del negozio rappresentano due repository di origine.
Le modifiche al cluster vengono inviate a questi repository di origine centrali. I deployment dei cluster in varie località edge estraggono gli aggiornamenti dai repository di origine. Questo comportamento è rappresentato dalle frecce che collegano i due repository nel diagramma ai componenti di Config Sync all'interno del cluster in esecuzione nei dispositivi.
Un altro componente chiave rappresentato all'interno del cluster è il runtime VM su GDC. Il runtime VM su GDC consente di eseguire carichi di lavoro basati su VM esistenti all'interno del cluster senza la necessità di containerizzazione. La documentazione del runtime VM su GDC spiega come attivarlo ed eseguire il deployment dei carichi di lavoro VM nel cluster.
Il componente contrassegnato come Application indica il software di cui è stato eseguito il deployment nel cluster dal negozio di vendita al dettaglio. L'applicazione point of sale presente nei kiosk di un negozio al dettaglio potrebbe essere un esempio di questo tipo di applicazione.
Le caselle nella parte inferiore del diagramma rappresentano i numerosi dispositivi (come chioschi, tablet o videocamere) all'interno di un negozio di vendita al dettaglio, tutti connessi a un switch di rete centrale. La rete locale all'interno del negozio consente alle applicazioni in esecuzione all'interno del cluster di raggiungere questi dispositivi.
Nella sezione successiva viene mostrata l'emulazione di questo deployment del negozio di vendita al dettaglio inGoogle Cloud utilizzando le VM Compute Engine. Questa emulazione è ciò che utilizzerai nel tutorial che segue per fare esperimenti con un cluster bare metal.
Deployment di Edge simulato in Google Cloud
Il seguente diagramma mostra tutto ciò che hai configurato in Google Cloud in questo tutorial. Questo diagramma è correlato al diagramma del punto vendita della sezione precedente. Questo deployment rappresenta una località edge simulata in cui è implementata l'applicazione point of sale. L'architettura mostra anche un carico di lavoro dell'applicazione di esempio point of sale che utilizzi in questo tutorial. Accedi all'applicazione point of sale all'interno del cluster utilizzando un browser web come kiosk.
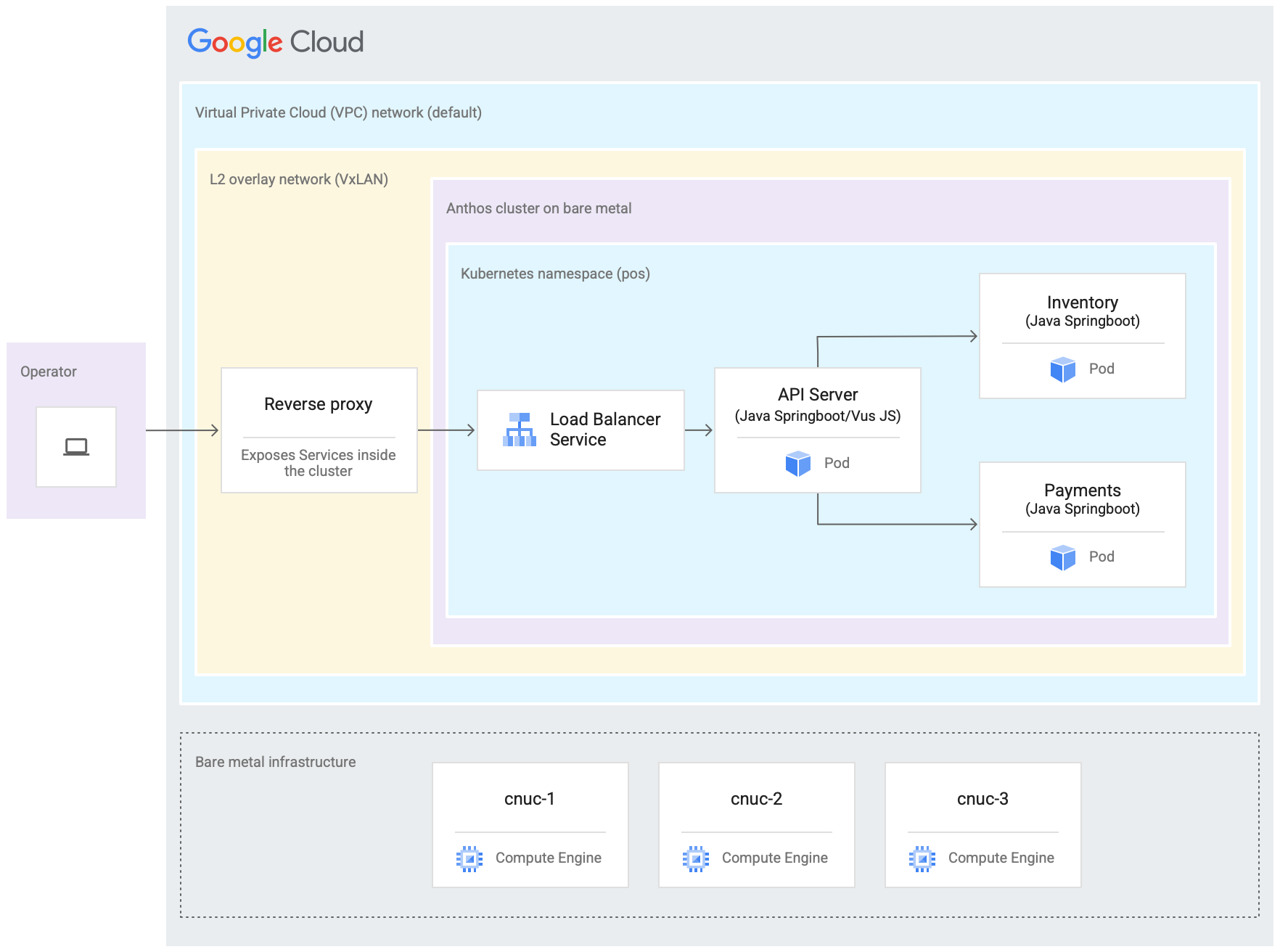
Le tre macchine virtuali (VM) Compute Engine nel diagramma precedente rappresentano l'hardware fisico (o i nodi) in una tipica località edge. Questo hardware verrà collegato a switch di rete per formare l'infrastruttura bare metal. Nel nostro ambiente simulato in Google Cloud, queste VM sono collegate tra loro tramite la rete Virtual Private Cloud (VPC) predefinita nel progetto Google Cloud.
In una tipica installazione di cluster bare metal puoi configurare i tuoi bilanciatori di carico. Tuttavia, per questo tutorial non configura un bilanciatore del carico esterno. Utilizza invece il bilanciatore del carico MetalLB in bundle. Il bilanciatore del carico MetalLB in bundle richiede connettività di rete di livello 2 tra i nodi. Pertanto, la connettività di livello 2 tra le VM Compute Engine viene attivata creando una rete overlay VxLAN sulla rete VPC (Virtual Private Cloud) predefinita.
All'interno del rettangolo etichettato "Rete overlay L2 (VxLAN)" sono mostrati i componenti software in esecuzione all'interno delle tre VM Compute Engine. Questo rettangolo VxLAN include il deployment del cluster, che contiene uno spazio dei nomi Kubernetes all'interno del cluster. Tutti i componenti all'interno di questo spazio dei nomi Kubernetes costituiscono l'applicazione point of sale di cui viene eseguito il deployment nel cluster. L'applicazione point of sale ha tre microservizi: API Server, Inventory e Payments. Tutti questi componenti insieme rappresentano un'"applicazione" mostrata nel diagramma dell'architettura di implementazione di Edge precedente.
Il bilanciatore del carico MetalLB incluso del cluster non può essere raggiunto direttamente dall'esterno delle VM. Il diagramma mostra un proxy inverso NGINX configurato per essere eseguito all'interno delle VM al fine di instradare il traffico in entrata alle VM di Compute Engine al bilanciatore del carico. Si tratta solo di una soluzione alternativa ai fini di questo tutorial, in cui i nodi edge vengono emulati utilizzando le VM di Compute Engine. Google CloudIn una posizione di confine reale, questa operazione può essere eseguita con una configurazione di rete adeguata.
Obiettivi
- Utilizza le VM Compute Engine per emulare un'infrastruttura bare metal in esecuzione in una località edge.
- Utilizza Google Distributed Cloud per creare un cluster nell'infrastruttura edge emulata.
- Connetti e registra il cluster con Google Cloud.
- Esegui il deployment di un carico di lavoro di un'applicazione point of sale di esempio nel cluster.
- Utilizza la console Google Cloud per verificare e monitorare l'applicazione point of sale che opera nella località edge.
- Utilizza Config Sync per aggiornare l'applicazione point of sale in esecuzione sul cluster.
Prima di iniziare
Nella console Google Cloud, nella pagina di selezione del progetto, seleziona o crea un progetto Google Cloud.
Verifica che la fatturazione sia attivata per il tuo progetto Cloud. Scopri come controllare se la fatturazione è attivata in un progetto.
Installa e inizializza Google Cloud CLI.
Crea un fork e clona il repository anthos-samples
Tutti gli script utilizzati in questo tutorial sono archiviati nel repository anthos-samples. La struttura delle cartelle in
/anthos-bm-edge-deployment/acm-config-sink
è organizzata in base alle aspettative di Config Sync.
Clona questo repository nel tuo account GitHub prima di continuare con i passaggi seguenti.
Se non ne hai già uno, crea un account su GitHub.
Crea un token di accesso personale da utilizzare nella configurazione di Config Sync. Questo è necessario per consentire ai componenti Config Sync nel cluster di autenticarsi con il tuo account GitHub quando si tenta di sincronizzare le nuove modifiche.
- Seleziona solo l'ambito
public_repo. - Salva il token di accesso che hai creato in un luogo sicuro per utilizzarlo in un secondo momento.
- Seleziona solo l'ambito
Crea un fork del repository
anthos-samplesnel tuo account GitHub:- Vai al repository anthos-samples.
- Fai clic sull'icona Fork nell'angolo in alto a destra della pagina.
- Fai clic sull'account utente GitHub in cui vuoi creare un fork del repository. Verrà visualizzata automaticamente la pagina con la tua versione del repository
anthos-samplescreata mediante fork.
Apri un terminale nel tuo ambiente locale.
Per clonare il repository creato mediante fork, esegui il comando riportato di seguito, dove GITHUB_USERNAME è il nome utente per il tuo account GitHub:
git clone https://github.com/GITHUB_USERNAME/anthos-samples cd anthos-samples/anthos-bm-edge-deployment
Configura l'ambiente della workstation
Per completare l'implementazione di Edge descritta in questo documento, hai bisogno di una workstation con accesso a internet e con i seguenti strumenti installati:
- Docker
- Strumento dell'interfaccia a riga di comando envsubst (di solito preinstallato su Linux e altri sistemi operativi tipo Unix)
Esegui tutti i comandi del tutorial sulla workstation configurata in questa sezione.
Nella tua workstation, inizializza le variabili di ambiente in una nuova istanza di shell:
export PROJECT_ID="PROJECT_ID" export REGION="us-central1" export ZONE="us-central1-a" # port on the admin Compute Engine instance you use to set up an nginx proxy # this allows to reach the workloads inside the cluster via the VM IP export PROXY_PORT="8082" # should be a multiple of 3 since N/3 clusters are created with each having 3 nodes export GCE_COUNT="3" # url to the fork of: https://github.com/GoogleCloudPlatform/anthos-samples export ROOT_REPO_URL="https://github.com/GITHUB_USERNAME/anthos-samples" # this is the username used to authenticate to your fork of this repository export SCM_TOKEN_USER="GITHUB_USERNAME" # access token created in the earlier step export SCM_TOKEN_TOKEN="ACCESS_TOKEN"Sostituisci i seguenti valori:
- PROJECT_ID: il tuo ID progetto Google Cloud.
- GITHUB_USERNAME: il tuo nome utente GitHub.
- ACCESS_TOKEN: il token di accesso personale che hai creato per il tuo repository GitHub.
Mantieni i valori predefiniti per le altre variabili di ambiente. che sono descritte nelle sezioni che seguono.
Nella tua workstation, inizializza Google Cloud CLI:
gcloud config set project "${PROJECT_ID}" gcloud services enable compute.googleapis.com gcloud config set compute/region "${REGION}" gcloud config set compute/zone "${ZONE}"Nella tua workstation, crea il Google Cloud service account per le istanze Compute Engine. Questo script crea il file della chiave JSON per il nuovo account di servizio in
<REPO_ROOT>/anthos-bm-edge-deployment/build-artifacts/consumer-edge-gsa.json. Configura inoltre il portachiavi e la chiave di Cloud Key Management Service per la crittografia della chiave privata SSH../scripts/create-primary-gsa.shL'esempio seguente è solo una parte dello script. Per visualizzare l'intero script, fai clic su Visualizza su GitHub.
Esegui il provisioning delle istanze Compute Engine
In questa sezione crei le VM Compute Engine in cui verrà installato il software di Google Distributed Cloud. Verifica inoltre la connettività a queste VM prima di procedere alla sezione di installazione.
Nella tua workstation, crea le chiavi SSH utilizzate per la comunicazione tra le istanze Compute Engine:
ssh-keygen -f ./build-artifacts/consumer-edge-machineCrittografa la chiave privata SSH utilizzando Cloud Key Management Service:
gcloud kms encrypt \ --key gdc-ssh-key \ --keyring gdc-ce-keyring \ --location global \ --plaintext-file build-artifacts/consumer-edge-machine \ --ciphertext-file build-artifacts/consumer-edge-machine.encryptedGenera il file di configurazione dell'ambiente
.envrce esegui il commit. Dopo aver creato il file.envrc, controlla che le variabili di ambiente siano state sostituite con i valori corretti.envsubst < templates/envrc-template.sh > .envrc source .envrcDi seguito è riportato un esempio di file
.envrcgenerato sostituendo le variabili di ambiente nel filetemplates/envrc-template.sh. Nota che le righe aggiornate sono evidenziate:Crea le istanze Compute Engine:
./scripts/cloud/create-cloud-gce-baseline.sh -c "$GCE_COUNT" | \ tee ./build-artifacts/gce-info
Installa un cluster bare metal con Ansible
Lo script utilizzato in questa guida crea cluster in gruppi di tre
istanze Compute Engine. Il numero di cluster creati è controllato dalla variabile di ambiente GCE_COUNT. Ad esempio, imposti la variabile di ambiente GCE_COUNT su 6 per creare due cluster con ciascuna 3 istanze VM.
Per impostazione predefinita, la variabile di ambiente GCE_COUNT è impostata su 3. Pertanto, in questa
guida verrà creato un cluster con 3 istanze Compute Engine. Le istanze VM
vengono denominate con un prefisso cnuc- seguito da un numero. La prima istanza VM di ogni cluster funge da workstation di amministrazione da cui viene attivata l'installazione. Al cluster viene assegnato lo stesso nome della VM della stazione di lavoro dell'amministratore (ad es. cnuc-1, cnuc-4, cnuc-7).
Il playbook Ansible esegue le seguenti operazioni:
- Configura le istanze Compute Engine con gli strumenti necessari, come
docker,bmctl,gcloudenomos. - Installa un cluster bare metal nelle istanze Compute Engine configurate.
- Viene creato un cluster autonomo denominato
cnuc-1. - Registra il cluster
cnuc-1con Google Cloud. - Installa Config Sync nel cluster
cnuc-1. - Configura Config Sync per la sincronizzazione con le configurazioni del cluster situate
in
anthos-bm-edge-deployment/acm-config-sinknel repository sottoposto a fork. - Genera il file
Login tokenper il cluster.
Per configurare e avviare la procedura di installazione, svolgi i seguenti passaggi:
Nella tua workstation, crea l'immagine Docker utilizzata per l'installazione. Questa immagine contiene tutti gli strumenti necessari per la procedura di installazione, come Ansible, Python e Google Cloud CLI.
gcloud builds submit --config docker-build/cloudbuild.yaml docker-build/Quando la compilazione viene eseguita correttamente, viene generato un output simile al seguente:
... latest: digest: sha256:99ded20d221a0b2bcd8edf3372c8b1f85d6c1737988b240dd28ea1291f8b151a size: 4498 DONE ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- ID CREATE_TIME DURATION SOURCE IMAGES STATUS 2238baa2-1f41-440e-a157-c65900b7666b 2022-08-17T19:28:57+00:00 6M53S gs://my_project_cloudbuild/source/1660764535.808019-69238d8c870044f0b4b2bde77a16111d.tgz gcr.io/my_project/consumer-edge-install (+1 more) SUCCESSGenera il file di inventario Ansible dal modello:
envsubst < templates/inventory-cloud-example.yaml > inventory/gcp.yamlEsegui lo script di installazione che avvia un container Docker dall'immagine costruita in precedenza. Lo script utilizza internamente Docker per generare il contenitore con un montaggio del volume nella directory di lavoro corrente. Al termine del completamento di questo script, devi trovarti all'interno del contenitore Docker che è stato creato. Attiva l'installazione di Ansible dall'interno di questo contenitore.
./install.shQuando lo script viene eseguito correttamente, produce un output simile al seguente:
... Check the values above and if correct, do you want to proceed? (y/N): y Starting the installation Pulling docker install image... ============================== Starting the docker container. You will need to run the following 2 commands (cut-copy-paste) ============================== 1: ./scripts/health-check.sh 2: ansible-playbook all-full-install.yaml -i inventory 3: Type 'exit' to exit the Docker shell after installation ============================== Thank you for using the quick helper script! (you are now inside the Docker shell)All'interno del contenitore Docker, verifica l'accesso alle istanze Compute Engine:
./scripts/health-check.shQuando lo script viene eseguito correttamente, produce un output simile al seguente:
... cnuc-2 | SUCCESS => {"ansible_facts": {"discovered_interpreter_python": "/usr/bin/python3"},"changed": false,"ping": "pong"} cnuc-3 | SUCCESS => {"ansible_facts": {"discovered_interpreter_python": "/usr/bin/python3"},"changed": false,"ping": "pong"} cnuc-1 | SUCCESS => {"ansible_facts": {"discovered_interpreter_python": "/usr/bin/python3"},"changed": false,"ping": "pong"}All'interno del contenitore Docker, esegui il playbook Ansible per l'installazione di un cluster bare metal sulle istanze Compute Engine:
Al termine, vedrai il
Login Tokenper il cluster stampato sullo schermo.ansible-playbook all-full-install.yaml -i inventory | tee ./build-artifacts/ansible-run.logSe l'installazione viene eseguita correttamente, viene generato un output come il seguente:
... TASK [abm-login-token : Display login token] ************************************************************************** ok: [cnuc-1] => { "msg": "eyJhbGciOiJSUzI1NiIsImtpZCI6Imk2X3duZ3BzckQyWmszb09sZHFMN0FoWU9mV1kzOWNGZzMyb0x2WlMyalkifQ.eymljZS1hY2NvdW iZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZWNyZXQubmFtZSI6ImVkZ2Etc2EtdG9rZW4tc2R4MmQiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2Nvd 4CwanGlof6s-fbu8" } skipping: [cnuc-2] skipping: [cnuc-3] PLAY RECAP *********************************************************************************************************** cnuc-1 : ok=205 changed=156 unreachable=0 failed=0 skipped=48 rescued=0 ignored=12 cnuc-2 : ok=128 changed=99 unreachable=0 failed=0 skipped=108 rescued=0 ignored=2 cnuc-3 : ok=128 changed=99 unreachable=0 failed=0 skipped=108 rescued=0 ignored=2
Accedi al cluster nella console Google Cloud
Al termine dell'esecuzione del playbook Ansible, viene installato un cluster autonomo all'interno delle VM Compute Engine. Questo cluster è registrato anche inGoogle Cloudutilizzando l'agente Connect. Tuttavia, per visualizzare i dettagli su questo cluster, devi accedere al cluster dalla console Google Cloud.
Per accedere al cluster, completa i seguenti passaggi:
Copia il token dall'output del playbook Ansible nella sezione precedente.
Nella console Google Cloud, vai alla pagina Cluster Kubernetes e utilizza il token copiato per accedere al cluster
cnuc-1.Vai alla pagina dei cluster Kubernetes
- Nell'elenco dei cluster, fai clic su Azioni accanto al cluster
cnuc-1e poi su Accedi. - Seleziona Token e incolla il token copiato.
- Fai clic su Accedi.
- Nell'elenco dei cluster, fai clic su Azioni accanto al cluster
- Nella console Google Cloud, vai alla pagina Configurazione nella sezione Funzionalità.
Nella scheda Pacchetti, controlla la colonna Stato sincronizzazione nella tabella del cluster.
Verifica che lo stato sia Sincronizzato. Uno stato Sincronizzato indica che
Config Sync
ha sincronizzato correttamente le configurazioni di GitHub con il cluster distribuito, cnuc-1.
Configurare un proxy per il traffico esterno
Il cluster installato nei passaggi precedenti utilizza un bilanciatore del carico integrato chiamato
MetalLB. Questo servizio di bilanciatore del carico è accessibile solo tramite un indirizzo IP Virtual Private Cloud (VPC). Per instradare il traffico in entrata tramite l'IP esterno al bilanciatore del carico in bundle, configura un servizio di proxy inverso nell'host di amministrazione (cnuc-1). Questo servizio di proxy inverso ti consente di raggiungere il server API dell'applicazione point of sale tramite l'IP esterno dell'host di amministrazione (cnuc-1).
Gli script di installazione nei passaggi precedenti hanno installato NGINX negli host di amministrazione insieme a un file di configurazione di esempio. Aggiorna questo file per utilizzare l'indirizzo IP del servizio bilanciatore del carico e riavvia NGINX.
Sulla workstation, utilizza SSH per accedere alla workstation di amministrazione:
ssh -F ./build-artifacts/ssh-config abm-admin@cnuc-1Dalla stazione di lavoro di amministrazione, configura il proxy inverso NGINX per instradare il traffico al servizio di bilanciamento del carico del server API. Ottieni l'indirizzo IP del servizio Kubernetes di tipo bilanciatore del carico:
ABM_INTERNAL_IP=$(kubectl get services api-server-lb -n pos | awk '{print $4}' | tail -n 1)Aggiorna il file di configurazione del modello con l'indirizzo IP recuperato:
sudo sh -c "sed 's/<K8_LB_IP>/${ABM_INTERNAL_IP}/g' \ /etc/nginx/nginx.conf.template > /etc/nginx/nginx.conf"Riavvia NGINX per assicurarti che la nuova configurazione venga applicata:
sudo systemctl restart nginxControlla e verifica lo stato dei report del server NGINX "attivo (in esecuzione)":
sudo systemctl status nginxQuando NGINX è in esecuzione correttamente, produce un output simile all'esempio riportato di seguito:
● nginx.service - A high performance web server and a reverse proxy server Loaded: loaded (/lib/systemd/system/nginx.service; enabled; vendor preset: enabled) Active: active (running) since Fri 2021-09-17 02:41:01 UTC; 2s ago Docs: man:nginx(8) Process: 92571 ExecStartPre=/usr/sbin/nginx -t -q -g daemon on; master_process on; (code=exited, status=0/SUCCESS) Process: 92572 ExecStart=/usr/sbin/nginx -g daemon on; master_process on; (code=exited, status=0/SUCCESS) Main PID: 92573 (nginx) Tasks: 17 (limit: 72331) Memory: 13.2M CGroup: /system.slice/nginx.service ├─92573 nginx: master process /usr/sbin/nginx -g daemon on; master_process on; ├─92574 nginx: worker process ├─92575 nginx: worker process ├─92577 nginx: .... ... ...Esci dalla sessione SSH nella workstation di amministrazione:
exitEsci dalla sessione di shell nel container Docker. Dopo aver chiuso l'istanza di amministrazione, sei ancora all'interno del container Docker utilizzato per l'installazione:
exit
Accedere all'applicazione point of sale
Con la configurazione del proxy esterno puoi accedere all'applicazione in esecuzione all'interno del cluster. Per accedere all'applicazione di punto di vendita di esempio, completa i seguenti passaggi.
Sulla workstation, ottieni l'indirizzo IP esterno dell'istanza Compute Engine di amministrazione e accedi all'interfaccia utente dell'applicazione point of sale:
EXTERNAL_IP=$(gcloud compute instances list \ --project ${PROJECT_ID} \ --filter="name:cnuc-1" \ --format="get(networkInterfaces[0].accessConfigs[0].natIP)") echo "Point the browser to: ${EXTERNAL_IP}:${PROXY_PORT}"Quando gli script vengono eseguiti correttamente, producono un output simile al seguente:
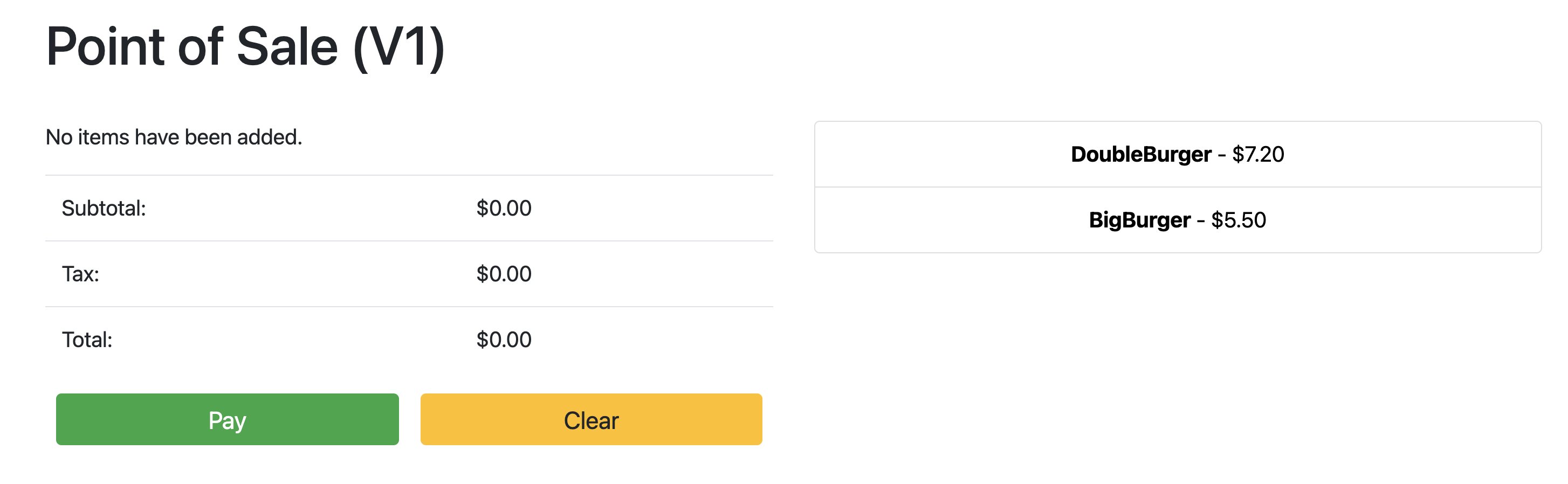
Point the browser to: 34.134.194.84:8082Apri il browser web e vai all'indirizzo IP mostrato nell'output del comando precedente. Puoi accedere e testare l'applicazione punto di vendita di esempio, come mostrato nello screenshot di esempio seguente:
Utilizzare la sincronizzazione della configurazione per aggiornare il server API
L'applicazione di esempio può essere sottoposta ad upgrade a una versione più recente aggiornando i file di configurazione nel repository principale. Config Sync rileva gli aggiornamenti e apporta automaticamente le modifiche al cluster. In questo esempio, il repository principale è il repository anthos-samples che hai clonato all'inizio di questa guida. Per scoprire in che modo l'applicazione point of sale di esempio può eseguire un deployment di upgrade a una versione più recente, completa i seguenti passaggi.
Nella tua workstation, aggiorna il campo
imageper modificare la versione del server API dav1av2. La configurazione YAML per il deployment si trova nel file inanthos-bm-edge-deployment/acm-config-sink/namespaces/pos/api-server.yaml.Aggiungi, esegui il commit e il push delle modifiche nel repository creato con fork:
git add acm-config-sink/namespaces/pos/api-server.yaml git commit -m "chore: updated api-server version to v2" git pushNella console Google Cloud, vai alla pagina Config Sync (Sincronizzazione configurazione) per controllare lo stato della specifica di configurazione. Verifica che lo stato sia Sincronizzato.
Nella console Google Cloud, vai alla pagina Carichi di lavoro Kubernetes Engine per verificare che il deployment sia aggiornato.
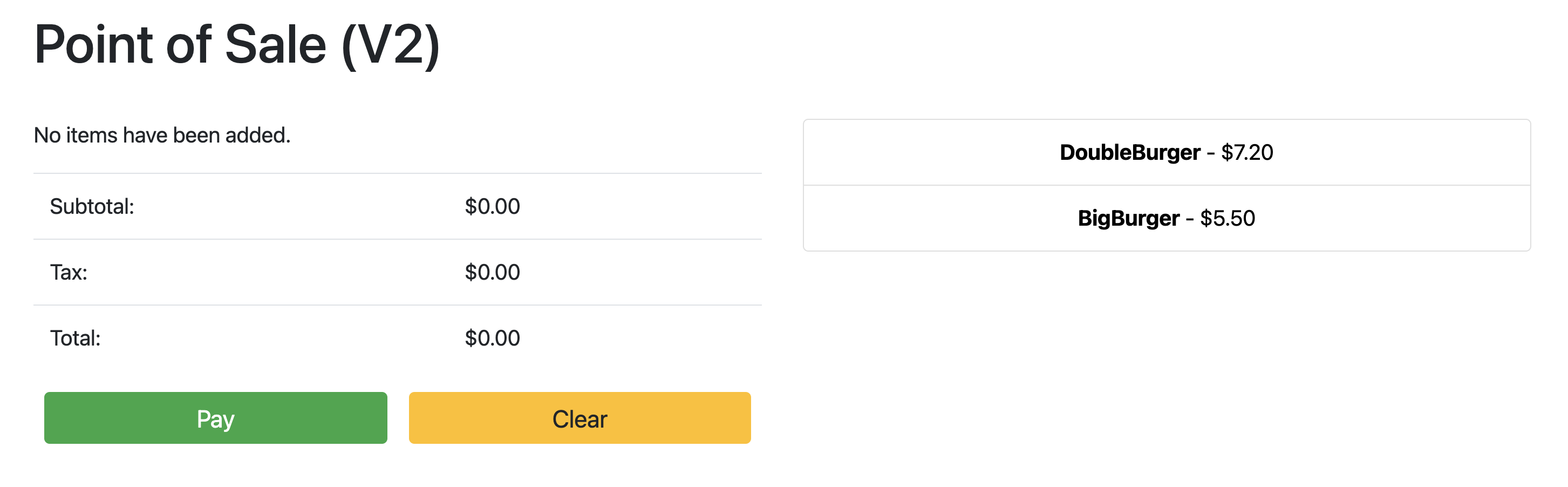
Quando lo stato del deployment è OK, indirizza il browser all'indirizzo IP indicato nella sezione precedente per visualizzare l'applicazione point of sale. Tieni presente che la versione nel titolo mostra "V2", a indicare che la modifica dell'applicazione è stata implementata, come mostrato nello screenshot di esempio seguente:
Per visualizzare le modifiche, potrebbe essere necessario eseguire un aggiornamento forzato della scheda del browser.
Esegui la pulizia
Per evitare addebiti Google Cloud non necessari, elimina le risorse utilizzate per questa guida al termine. Puoi eliminare queste risorse manualmente o eliminare il progetto Google Cloud, eliminando così anche tutte le risorse. Inoltre, ti consigliamo di ripulire le modifiche apportate nella tua workstation locale:
Workstation locale
Per annullare le modifiche apportate dagli script di installazione, devono essere aggiornati i seguenti file.
- Rimuovi gli indirizzi IP delle VM Compute Engine aggiunti al file
/etc/hosts. - Rimuovi la configurazione SSH per
cnuc-*nel file~/.ssh/config. - Rimuovi le impronte delle VM Compute Engine dal file
~/.ssh/known_hosts.
Elimina progetto
Se hai creato un progetto dedicato per questa procedura, elimina il progetto Google Cloud dalla console Google Cloud.
Manuale
Se hai utilizzato un progetto esistente per questa procedura, segui questi passaggi:
- Annullare la registrazione di tutti i cluster Kubernetes con un nome preceduto da
cnuc-. - Elimina tutte le VM Compute Engine con un nome preceduto da
cnuc-. - Elimina il bucket Cloud Storage con un nome preceduto da
abm-edge-boot. - Elimina le regole firewall
allow-pod-ingresseallow-pod-egress. - Elimina il secret di Secret Manager
install-pub-key.
Passaggi successivi
Puoi espandere questa guida aggiungendo un'altra località di confine. Se imposti la variabile di ambiente GCE_COUNT su 6 ed esegui di nuovo gli stessi passaggi delle sezioni precedenti, vengono create tre nuove istanze Compute Engine (cnuc-4, cnuc-5, cnuc-6) e un nuovo cluster autonomo denominato cnuc-4.
Puoi anche provare ad aggiornare le configurazioni dei cluster nel repository sottoposto a fork per applicare in modo selettivo versioni diverse dell'applicazione point of sale ai due cluster cnuc-1 e cnuc-4 utilizzando ClusterSelectors.
Per informazioni dettagliate sui singoli passaggi di questa guida e sugli script coinvolti, consulta il repository anthos-samples.