Wenn Sie den Durchsatz im Zeitverlauf darstellen, während eine andere Variable geändert wird, steigt der Durchsatz in der Regel, bis die Ressourcen erschöpft sind.
Die folgende Abbildung zeigt ein typisches Diagramm zur Durchsatzskalierung. Mit zunehmender Anzahl von Clients steigen Arbeitslast und Durchsatz, bis alle Ressourcen erschöpft sind.
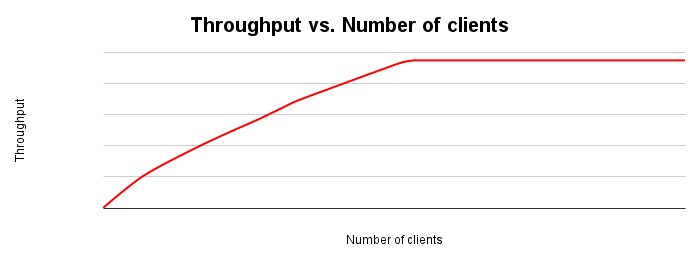
Idealerweise sollte sich der Durchsatz verdoppeln, wenn Sie die Last auf das System verdoppeln. In der Praxis kommt es zu Ressourcenkonflikten, die zu geringeren Durchsatzsteigerungen führen. Irgendwann führt die Erschöpfung oder der Konflikt von Ressourcen dazu, dass der Durchsatz abflacht oder sogar abnimmt. Wenn Sie den Durchsatz optimieren möchten, ist dies ein wichtiger Punkt, da er bestimmt, wo Sie die Anwendung oder das Datenbanksystem optimieren müssen, um den Durchsatz zu verbessern.
Typische Gründe für ein Nachlassen oder Sinken des Durchsatzes sind:
- Erschöpfung der CPU-Ressourcen auf dem Datenbankserver
- Erschöpfung der CPU-Ressourcen auf dem Client, sodass dem Datenbankserver keine weiteren Aufgaben zugewiesen werden
- Konflikt durch Datenbanksperre
- E/A-Wartezeit, wenn die Daten die Größe des Postgres-Pufferpools überschreiten
- E/A-Wartezeit aufgrund der Auslastung der Speicher-Engine
- Engpässe bei der Netzwerkbandbreite beim Zurückgeben von Daten an den Client
Latenz und Durchsatz sind umgekehrt proportional. Mit zunehmender Latenz sinkt der Durchsatz. Das ist intuitiv nachvollziehbar. Wenn sich ein Engpass abzeichnet, dauern Vorgänge länger und das System führt weniger Vorgänge pro Sekunde aus.
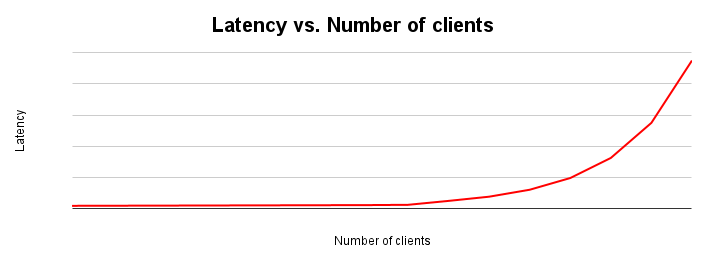
Die Grafik zur Latenzskalierung zeigt, wie sich die Latenz ändert, wenn die Last auf ein System zunimmt. Die Latenz bleibt relativ konstant, bis es aufgrund von Ressourcenkonflikten zu Reibung kommt. Der Wendepunkt dieser Kurve entspricht in der Regel der Abflachung der Durchsatzkurve im Durchsatzskalierungsdiagramm.
Eine weitere nützliche Möglichkeit, die Latenz zu bewerten, ist ein Histogramm. In dieser Darstellung werden Latenzen in Buckets gruppiert und gezählt, wie viele Anfragen in die einzelnen Buckets fallen.
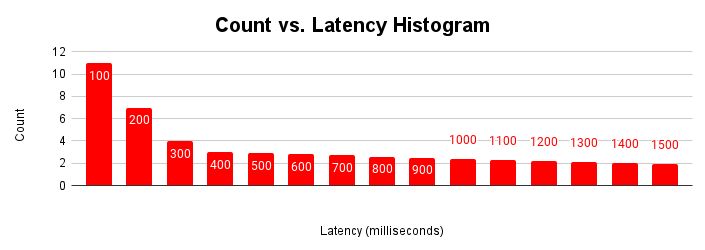
Dieses Latenzhistogramm zeigt, dass die meisten Anfragen weniger als 100 Millisekunden dauern und dass es auch Latenzen von mehr als 100 Millisekunden gibt. Wenn Sie die Ursache für die Anfragen mit längeren Latenzen kennen, können Sie die Schwankungen bei der Anwendungsleistung besser nachvollziehen. Die Ursachen für den Longtail erhöhter Latenzen entsprechen den erhöhten Latenzen im typischen Latenzskalierungsdiagramm und der Abflachung des Durchsatzdiagramms.
Das Latenzhistogramm ist am nützlichsten, wenn eine Anwendung mehrere Modalitäten hat. Eine Modalität ist ein normaler Satz von Betriebsbedingungen. Die Anwendung greift beispielsweise meistens auf Seiten zu, die sich im Puffer-Cache befinden. In den meisten Fällen werden vorhandene Zeilen aktualisiert, es kann aber auch mehrere Modi geben. Manchmal ruft die Anwendung Seiten aus dem Speicher ab, fügt neue Zeilen ein oder es kommt zu Konflikten bei der Sperrung.
Wenn eine Anwendung im Laufe der Zeit auf diese verschiedenen Betriebsmodi trifft, werden diese mehreren Modalitäten im Latenzhistogramm dargestellt.
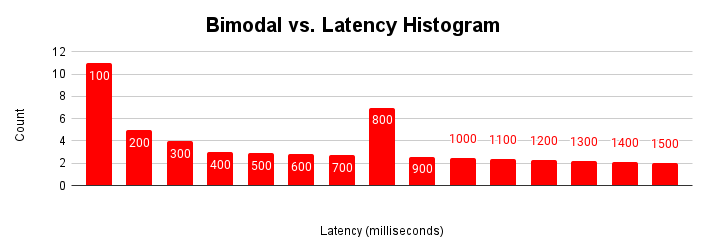
Diese Abbildung zeigt ein typisches bimodales Histogramm, in dem die meisten Anfragen in weniger als 100 Millisekunden bearbeitet werden, es aber einen weiteren Cluster von Anfragen gibt, die 401 bis 500 Millisekunden dauern. Wenn Sie die Ursache für diese zweite Modalität kennen, können Sie die Leistung Ihrer Anwendung verbessern. Es können auch mehr als zwei Modalitäten vorhanden sein.
Die zweite Modalität kann auf normale Datenbankvorgänge, heterogene Infrastruktur und Topologie oder das Verhalten von Anwendungen zurückzuführen sein. Hier einige Beispiele:
- Die meisten Datenzugriffe erfolgen über den PostgreSQL-Pufferpool, einige jedoch über den Speicher.
- Unterschiede bei der Netzwerklatenz für einige Clients zum Datenbankserver
- Anwendungslogik, die je nach Eingabe oder Tageszeit unterschiedliche Vorgänge ausführt
- Sporadischer Sperrenkonflikt
- Spitzen bei Clientaktivitäten