AlloyDB Omni is a downloadable database software package that lets you deploy a streamlined version of AlloyDB for PostgreSQL in your own computing environment. AlloyDB Omni and the fully-managed AlloyDB for PostgreSQL service on Google Cloud share the same core components. AlloyDB for PostgreSQL uses a cloud-native storage layer that optimizes WAL performance, while AlloyDB Omni uses the same standard file system interface used by PostgreSQL.
The portability of AlloyDB Omni lets you run it in many environments, including the following:
- Data centers
- Laptops
- Cloud-based VM instances
AlloyDB Omni use cases
AlloyDB Omni is well-suited to the following scenarios:
- You need a scalable and performant version of PostgreSQL, but you can't run a database in the cloud due to regulatory or data sovereignty requirements.
- You need a database that keeps running even when it's disconnected from the internet.
- To minimize latency, you want to locate your database as geographically close as possible to your users.
- You would like a way to migrate away from a legacy database, but without committing to a full cloud migration.
AlloyDB Omni doesn't include AlloyDB for PostgreSQL features that rely on operation in Google Cloud. If you want to upgrade your project to the fully managed scaling, security, and availability features of AlloyDB for PostgreSQL, you can migrate your AlloyDB Omni data into an AlloyDB for PostgreSQL cluster just as you can with any other initial data import.
Key features
- A PostgreSQL-compatible database server.
- Support for AlloyDB AI, which helps you build enterprise-grade generative AI applications using your operational data.
- Integrations with the Google Cloud AI ecosystem including the Vertex AI Model Garden and open source generative AI tools.
Support for autopilot features from AlloyDB for PostgreSQL in Google Cloud that lets AlloyDB Omni self-manage and self-tune.
For example, AlloyDB Omni supports automatic memory management and adaptive autovacuum of stale data.
An index advisor that analyzes frequently run queries and recommends new indexes for better query performance.
The AlloyDB Omni columnar engine, which keeps frequently queried data in an in-memory columnar format for faster performance on business intelligence, reporting, and hybrid transactional and analytical processing (HTAP) workloads.
In our performance tests, transactional workloads in AlloyDB Omni are more than 2X faster, and analytical queries are up to 100X faster, than standard PostgreSQL.
How AlloyDB Omni works
You can install AlloyDB Omni as a standalone server or as part of a Kubernetes environment.
AlloyDB Omni runs in a Docker container that you install onto your own environment. We recommend that you run AlloyDB Omni on a Linux system with SSD storage and at least 8GB of memory per CPU.
The AlloyDB Omni Kubernetes operator is an extension to the Kubernetes API that lets you run AlloyDB Omni in most CNCF-compliant Kubernetes environments. For more information, see Install AlloyDB Omni on Kubernetes.
Your applications connect to and communicate with your AlloyDB Omni installation, just like applications connect to and communicate with a standard PostgreSQL database server. User access control relies on PostgreSQL standards, as well.
From logging to vacuuming to the columnar engine, you can configure the database behavior of AlloyDB Omni using database flags.
Advantages of running AlloyDB Omni as a container
Google distributes AlloyDB Omni as a container that you can run with container runtimes such as Docker and Podman. Operationally, containers present the following advantages:
- Transparent dependency management: All necessary dependencies are bundled in the container and tested by Google to ensure that they are fully compatible with AlloyDB Omni.
- Portability: You can expect AlloyDB Omni to operate consistently across environments.
- Security isolation: You choose what the AlloyDB Omni container has access to on the host machine.
- Resource management: You can define the amount of compute resources that you want the AlloyDB Omni container to use.
- Seamless patching and upgrades: To patch a container, you only need to replace the existing image with a new one.
Data backup and disaster recovery
AlloyDB Omni features a continuous backup and recovery system that lets you create a new database cluster based on any point in time within an adjustable retention period. This lets you recover quickly from data-loss accidents.
In addition, AlloyDB Omni can create and store complete backups of your database cluster's data, either on demand or on a regular schedule. At any time, you can restore from a backup to an AlloyDB Omni database cluster that contains all the data from the original database cluster at the moment of the backup's creation.
As a further method of disaster recovery, you can achieve cross data center replication by creating secondary database clusters in separate data centers. AlloyDB Omni asynchronously streams data from a designated primary database cluster to each of its secondary clusters. Whenever needed, you can promote a secondary database cluster into a primary AlloyDB Omni database cluster.
AlloyDB Omni VM components
AlloyDB Omni on VM consists of two sets of architecture components: PostgreSQL components with AlloyDB for PostgreSQL enhancements and AlloyDB for PostgreSQL components. The following diagram outlines both sets of components, what infrastructure layer they reside in on a VM or server, and related features you can expect for each component.
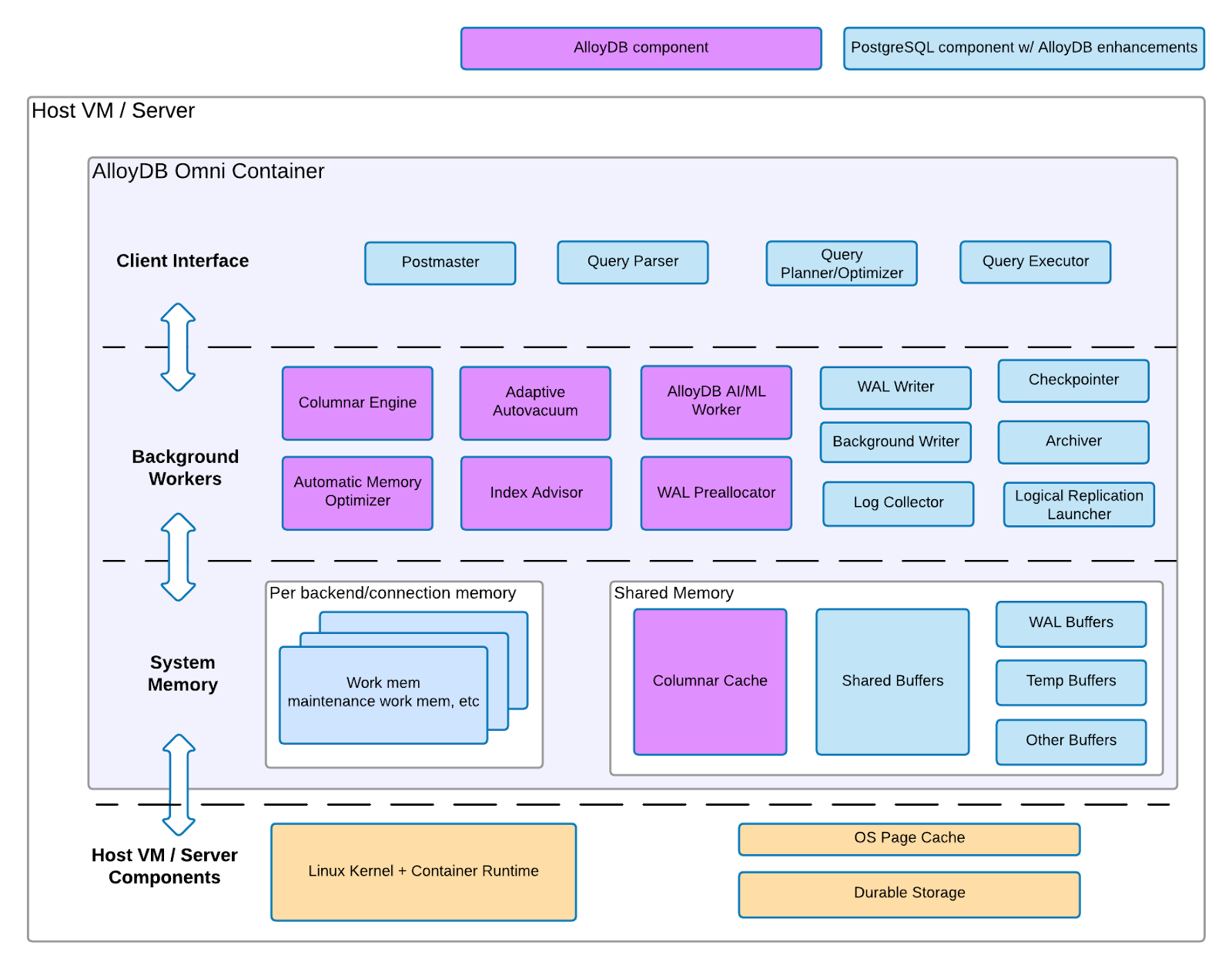
Figure 1. AlloyDB Omni architecture
Database engine
This document describes the database architecture in AlloyDB Omni in a container. This document assumes that you're familiar with PostgreSQL.
A database engine performs the following tasks:
- Translates a query from a client into an executable plan
- Finds the data necessary to satisfy the query
- Performs any necessary filtering, ordering, and aggregation
- Returns the results to the client
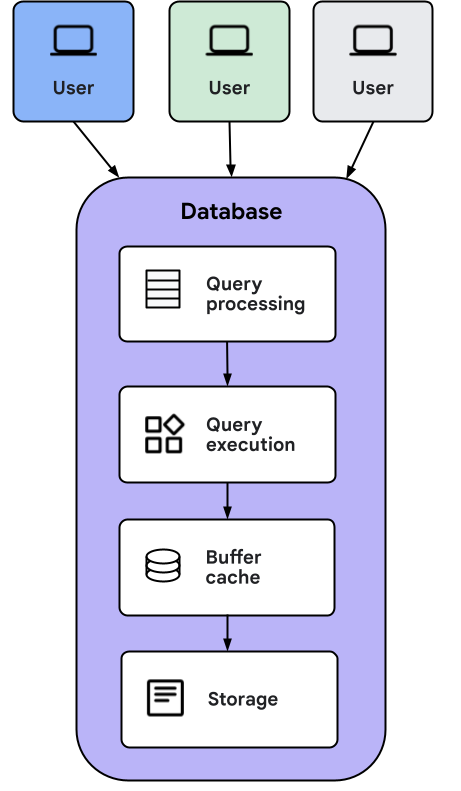
When the client application sends a query to AlloyDB Omni, the following actions occurs:
- The query processing layer turns the query into an execution plan that goes to the query execution layer.
- The query execution layer performs the operations needed to compute the response to the query.
- During execution, data could be loaded from the buffer cache or loaded directly from storage. If the data is loaded from storage, the data from storage is stored in the cache for future uses.
Resources used when processing the client's query include CPU, memory, I/O, network, and synchronization primitives like database locks. Performance tuning aims to optimize resource utilization during each of the steps in query execution.
The goal of a performant database engine is to respond to a query using the fewest resources required. This goal starts with a good data model and query design.
- How can queries be answered while looking at the least amount of data?
- What indexes are needed to reduce the search space and I/O?
- Sorting data requires CPU and, often, disk access for large data sets, so how can sorting data be avoided?
Data storage
AlloyDB Omni stores data in fixed size pages that are stored in the underlying file system. When a query needs to access data, AlloyDB Omni first checks the buffer pool. If the page(s) that hold the required data are not found in the buffer pool, then AlloyDB Omni reads the required page(s) from the file system. Accessing data from the buffer pool is significantly faster than reading from the file system, and therefore maximizing the size of the buffer pool for the amount of data that will be accessed by an application is an important factor.
Resource management
AlloyDB Omni uses dynamic memory management to let the buffer pool grow and shrink dynamically within configured bounds depending on the memory demands of the system. Therefore, there is no need to tune the buffer pool size. When diagnosing performance issues, the first metrics to consider are the buffer pool hit rate and the read rate to see if your application is getting the benefit of the buffer pool. If not, that indicates that the application's dataset does not fit in the buffer pool, and you could consider resizing to a larger machine with more memory.
The process of retrieving, filtering, aggregating, sorting, and projecting data all require CPU resources on the database server. To reduce the amount of CPU resources required for this process, minimize the amount of data that needs to be manipulated. Monitor the CPU utilization on the database server to ensure the steady state utilization is around 70%. This amount leaves sufficient headroom on the server for spikes in utilization or changes in access patterns over time. Running at closer to 100% utilization introduces overhead due to process scheduling and context switching and might create bottlenecks in other parts of the system. High CPU utilization is another key metric to use when making decisions about machine specifications.
Input/Output Operations Per Second (IOPS) is an important factor in database application performance -- how many input or output operations per second can the underlying storage device deliver to the database. To avoid hitting the IOPS limits of database storage, minimize reads and writes to storage by maximizing the amount of data that can fit in the buffer pool.
Columnar engine
The columnar engine accelerates SQL query processing of scans, joins, and aggregates by providing the following components:
In-memory column store: Contains table and materialized-view data for selected columns in a column-oriented format. By default, the column store consumes 1GB of available memory. To change the amount of memory usable by the column store, set the
google_columnar_engine.memory_size_in_mbparameter in thepostgresql.confused by your AlloyDB Omni instance.Columnar query planner and execution engine: Supports the use of the column store in queries.
Automatic memory management
The automatic memory manager continuously monitors and optimizes memory
consumption across an entire AlloyDB Omni instance. When you run
your workloads, this module adjusts the shared buffer cache size based on memory
pressure. By default, the automatic memory manager sets the upper limit to 80%
of system memory and allocates 10% of system memory for the shared buffer cache.
To change the upper limit for the size of the shared buffer cache, set the
shared_buffers parameter in the postgresql.conf used by your
AlloyDB Omni instance.
Adaptive autovacuum
Adaptive autovacuum analyzes operations based on the workload of the database, and automatically adjusts the frequency of vacuuming. This automatic adjustment helps the database run at peak performance, even as the workload changes, without interference from the vacuum process.
Adaptive autovacuum uses the following factors to determine the frequency and intensity of vacuuming operations:
- Size of the database
- Number of dead tuples in the database
- Age of the data in the database
- Number of transactions per second versus estimated vacuum speed
Adaptive autovacuum provides the following benefits:
- Dynamic vacuum resource management: Instead of using a fixed cost limit,
AlloyDB Omni uses real-time resource statistics to adjust the
vacuum workers. When the system is busy, the vacuum process and associated
resource utilization are throttled. If enough memory is available,
additional memory is allocated for
maintenance_work_memto reduce end-to-end vacuum time. - Dynamic XID Throttling: Automatically and continuously monitors the
progress of vacuuming and the speed of transaction ID consumption. If a risk
of transaction ID wraparound is detected, AlloyDB Omni
slows down transactions to throttle ID consumption. Also,
AlloyDB Omni allocates more resources to the vacuum workers
to process the tables blocking the advancing and releasing of transaction
ID space. During this process, the overall transactions per second are
reduced until the transaction IDs are in a safe zone (observable as
sessions waiting on
AdaptiveVacuumNewXidDelay). When the transaction ID age increases, the vacuum workers are dynamically increased. - Efficient vacuuming for larger tables: The default PostgreSQL logic
used to decide when to vacuum a table is based on table-specific statistics
stored in
pg_stat_all_tables, which contains the dead tuple ratio. This logic works for small tables, but it may not work efficiently for larger, frequently updated tables. AlloyDB Omni provides an updated scan mechanism that helps trigger autovacuum more often. This scan mechanism scans chunks of large tables and removes dead tuples more efficiently than the default PostgreSQL logic. - Log warning messages: In AlloyDB Omni, vacuum blockers, such as long-running transactions or prepared transactions or replication slots that lose their targets, are detected and warnings are registered in the PostgreSQL logs so that you can address problems in a timely manner.
AI/ML worker
In AlloyDB Omni, the AI/ML background worker provides all of the
capabilities necessary for calling Vertex AI models directly from the
database. The AI/ML worker runs as a process called omni ml worker.
What's next
- Choose an AlloyDB Omni deployment environment.
- Get started with AlloyDB Omni for Kubernetes.
- Get started with AlloyDB Omni for containers