AlloyDB Omni 是一个可下载的数据库软件包,可让您在自己的计算环境中部署精简版 AlloyDB for PostgreSQL。由于 AlloyDB Omni 的可移植性,它可以在各种环境中运行,包括:
- 数据中心
- 笔记本电脑
- 基于云端的虚拟机实例
AlloyDB Omni 非常适合以下场景:
- 您需要可扩缩且高性能的 PostgreSQL 版本,但由于法规或数据主权要求,您无法在云端运行数据库。
- 您需要一个即使断开互联网连接也能继续运行的数据库。
- 您希望将数据库的实际位置尽可能靠近用户,以最大限度地缩短延迟时间。
- 您希望找到一种方法,从旧版数据库迁移,但不必完全迁移到云端。
AlloyDB Omni 不包含依赖于 Google Cloud中操作的 AlloyDB 功能。如果您想将项目升级到 AlloyDB 的全代管式扩缩、安全和可用性功能,可以将 AlloyDB Omni 数据迁移到 AlloyDB 集群,就像使用任何其他初始数据导入一样。
主要特性
- 与 PostgreSQL 兼容的数据库服务器。
- 支持 AlloyDB AI,这是一组内置于 AlloyDB 中的集成功能,可帮助您使用运营数据构建企业级生成式 AI 应用。
- 与 Google Cloud AI 生态系统(包括 Vertex AI Model Garden 和开源生成式 AI 工具)集成。
- 索引顾问,可分析经常运行的查询并推荐新索引,以提升查询性能。
- AlloyDB 列式引擎,该引擎能够以内存中列式格式保存频繁查询的数据,从而加快商业智能、报告以及混合事务和分析处理 (HTAP) 工作负载的速度。
- 与标准 PostgreSQL 服务器相比,其他优化和增强功能,例如自动内存管理和对过时数据的自适应自动执行真空。
AlloyDB Omni 的运作方式
AlloyDB Omni 可以作为独立服务器安装,也可以作为 Kubernetes 环境的一部分安装。
AlloyDB Omni 在您安装到自己的环境的 Docker 容器中运行。我们建议在具有 SSD 存储空间且每个 CPU 至少有 8GB 内存的 Linux 系统上运行 AlloyDB Omni。
AlloyDB Omni Kubernetes operator 是 Kubernetes API 的扩展,可让您在大多数符合 CNCF 标准的 Kubernetes 环境中运行 AlloyDB Omni。如需了解详情,请参阅在 Kubernetes 上安装 AlloyDB Omni。
您的应用与 AlloyDB Omni 安装连接并进行通信的方式与与普通 PostgreSQL 数据库服务器进行连接和通信的方式完全相同。用户访问权限控制也依赖于 PostgreSQL 标准。
您可以使用适用于 AlloyDB 的相同数据库标志配置 AlloyDB Omni 的行为。
虚拟机上 AlloyDB Omni 的数据库引擎架构
本文档介绍了容器中 AlloyDB Omni 的数据库架构。本文档假定您熟悉 PostgreSQL。
数据库引擎执行以下任务:
- 将客户端的查询转换为可执行计划
- 查找满足查询所需的数据
- 执行任何必要的过滤、排序和汇总
- 将结果返回给客户端
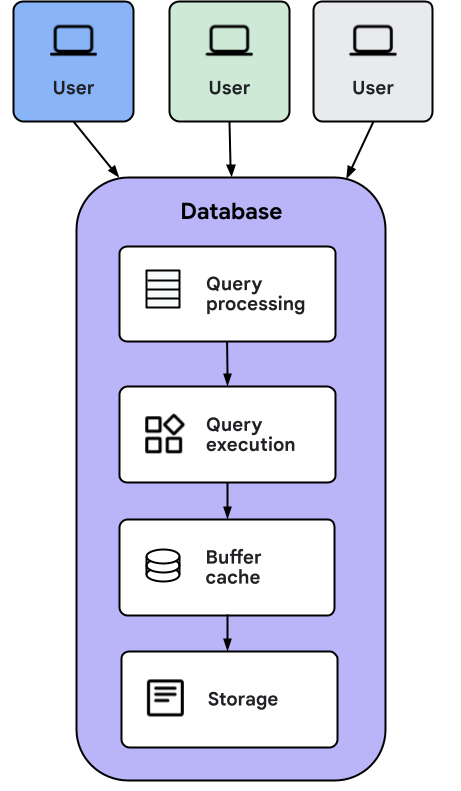
当客户端应用向 AlloyDB Omni 发送查询时,会发生以下操作:
- 查询处理层会将查询转换为传递给查询执行层的执行计划。
- 查询执行层会执行计算查询响应所需的操作。
- 在执行期间,数据可以从缓冲区缓存加载,也可以直接从存储空间加载。如果从存储空间加载数据,则存储空间中的数据会存储在缓存中以供日后使用。
处理客户端查询时使用的资源包括 CPU、内存、I/O、网络以及数据库锁等同步基元。性能调优旨在优化查询执行过程中的每个步骤的资源利用率。
高性能数据库引擎的目标是使用最少的资源响应查询。要实现这一目标,首先要有一个良好的数据模型和查询设计。
- 如何在查看最少数据量的情况下回答查询?
- 需要哪些索引才能缩减搜索空间和 I/O?
- 对数据进行排序需要 CPU,对于大型数据集,通常还需要访问磁盘,那么如何避免对数据进行排序?
数据存储
AlloyDB Omni 会将数据存储在存储在底层文件系统中的固定大小的页面中。当查询需要访问数据时,AlloyDB Omni 会先检查缓冲区。如果缓冲区中找不到包含所需数据的页面,AlloyDB Omni 会从文件系统读取所需的页面。从缓冲区池访问数据的速度比从文件系统读取数据的速度要快得多,因此,根据应用将要访问的数据量尽可能扩大缓冲区池的大小是一项重要因素。
资源管理
AlloyDB Omni 使用动态内存管理,让缓冲区池能够根据系统的内存需求,在配置的边界内动态扩大和缩小。因此,无需调整缓冲区池大小。在诊断性能问题时,首先要考虑的两个指标是缓冲区命中率和读取率,以了解您的应用是否在受益于缓冲区。如果没有,则表示应用的数据集无法放入缓冲区,您可以考虑调整大小,改用内存更大的机器。
检索、过滤、汇总、排序和投影数据的过程都需要数据库服务器上的 CPU 资源。为了减少此过程所需的 CPU 资源量,请尽量减少需要处理的数据量。监控数据库服务器上的 CPU 利用率,确保稳定状态利用率约为 70%。此数量可为服务器留出足够的余量,以应对利用率激增或访问模式随时间推移而发生变化的情况。由于进程调度和上下文切换,在接近 100% 的利用率下运行会产生开销,并且可能会在系统的其他部分造成瓶颈。在制定机器规格决策时,高 CPU 利用率是另一个关键指标。
每秒输入/输出操作数 (IOPS) 是数据库应用性能的重要因素,表示底层存储设备每秒可向数据库提交的输入或输出操作次数。为避免达到数据库存储空间的 IOPS 限制,请尽可能增加缓冲区中可容纳的数据量,从而最大限度地减少对存储空间的读写。
数据备份和灾难恢复
AlloyDB Omni 采用连续备份和恢复系统,可让您根据可调整的保留期限内的任意时间点创建新的数据库集群。这样,您就可以快速从数据丢失事故中恢复。
此外,AlloyDB Omni 还可以按需或定期创建和存储数据库集群数据的完整备份。您可以随时从备份恢复到 AlloyDB Omni 数据库集群,该集群包含创建备份时原始数据库集群中的所有数据。
如需了解详情,请参阅备份和恢复 AlloyDB Omni。
作为灾难恢复的进一步方法,您可以在不同的数据中心创建次要数据库集群,以实现跨数据中心复制。AlloyDB Omni 会将数据从指定的主数据库集群异步流式传输到其每个辅助集群。您可以根据需要将次要数据库集群提升为主 AlloyDB Omni 数据库集群。
如需了解详情,请参阅跨数据中心复制简介
AlloyDB Omni 版本 15.5.2 及更低版本的文档
如需了解旧版 AlloyDB Omni,请参阅多容器 AlloyDB Omni 文档集。