AlloyDB Omni adalah paket software database yang dapat didownload yang memungkinkan Anda men-deploy edisi AlloyDB untuk PostgreSQL yang disederhanakan di lingkungan komputasi Anda sendiri. Portabilitas AlloyDB Omni memungkinkannya berjalan di berbagai lingkungan, termasuk yang berikut:
- Pusat data
- Laptop
- Instance VM berbasis cloud
AlloyDB Omni sangat cocok untuk skenario berikut:
- Anda memerlukan versi PostgreSQL yang skalabel dan berperforma tinggi, tetapi Anda tidak dapat menjalankan database di cloud karena persyaratan peraturan atau kedaulatan data.
- Anda memerlukan database yang terus berjalan meskipun terputus dari internet.
- Anda ingin menempatkan database secara fisik sedekat mungkin dengan pengguna, untuk meminimalkan latensi.
- Anda ingin bermigrasi dari database lama, tetapi tanpa melakukan migrasi cloud penuh.
AlloyDB Omni tidak menyertakan fitur AlloyDB yang mengandalkan operasi dalam Google Cloud. Jika ingin mengupgrade project ke fitur penskalaan, keamanan, dan ketersediaan AlloyDB yang sepenuhnya dikelola, Anda dapat memigrasikan data AlloyDB Omni ke cluster AlloyDB seperti yang dapat Anda lakukan dengan impor data awal lainnya.
Fitur utama
- Server database yang kompatibel dengan PostgreSQL.
- Dukungan untuk AlloyDB AI, serangkaian kemampuan terintegrasi yang terintegrasi dengan AlloyDB, untuk membantu Anda membuat aplikasi AI generatif kelas perusahaan menggunakan data operasional.
- Integrasi dengan Google Cloud ekosistem AI, termasuk Vertex AI Model Garden dan alat AI generatif open source.
- Penasihat indeks yang menganalisis kueri yang sering dijalankan dan merekomendasikan indeks baru untuk performa kueri yang lebih baik.
- Mesin kolom AlloyDB, yang menyimpan data yang sering dikueri dalam format kolom dalam memori untuk performa yang lebih cepat pada business intelligence, pelaporan, dan pemrosesan transaksional serta analitis hybrid (HTAP).
- Pengoptimalan dan peningkatan lainnya pada server PostgreSQL standar, seperti pengelolaan memori otomatis dan autovacuum adaptif untuk data yang sudah tidak berlaku.
Cara kerja AlloyDB Omni
AlloyDB Omni dapat diinstal sebagai server mandiri atau sebagai bagian dari lingkungan Kubernetes.
AlloyDB Omni berjalan dalam penampung Docker yang Anda instal ke lingkungan Anda sendiri. Sebaiknya jalankan AlloDB Omni di sistem Linux dengan penyimpanan SSD dan memori minimal 8 GB per CPU.
Operator AlloyDB Omni Kubernetes adalah ekstensi ke Kubernetes API yang memungkinkan Anda menjalankan AlloyDB Omni di sebagian besar lingkungan Kubernetes yang sesuai dengan CNCF. Untuk informasi selengkapnya, lihat Menginstal AlloyDB Omni di Kubernetes.
Aplikasi Anda terhubung ke dan berkomunikasi dengan penginstalan AlloyDB Omni persis seperti yang dilakukan dengan server database PostgreSQL biasa. Kontrol akses pengguna juga bergantung pada standar PostgreSQL.
Anda dapat mengonfigurasi perilaku AlloyDB Omni menggunakan flag database yang sama dengan yang tersedia untuk AlloyDB.
Arsitektur mesin database AlloyDB Omni di VM
Dokumen ini menjelaskan arsitektur database di AlloyDB Omni dalam penampung. Dokumen ini mengasumsikan bahwa Anda sudah memahami PostgreSQL.
Mesin database melakukan tugas berikut:
- Menerjemahkan kueri dari klien menjadi rencana yang dapat dieksekusi
- Menemukan data yang diperlukan untuk memenuhi kueri
- Melakukan pemfilteran, pengurutan, dan agregasi yang diperlukan
- Menampilkan hasilnya ke klien
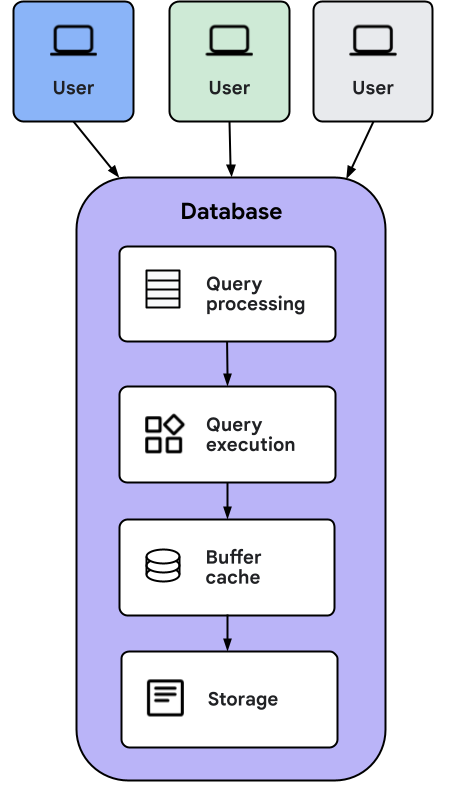
Saat aplikasi klien mengirim kueri ke AlloyDB Omni, tindakan berikut akan terjadi:
- Lapisan pemrosesan kueri mengubah kueri menjadi rencana eksekusi yang masuk ke lapisan eksekusi kueri.
- Lapisan eksekusi kueri melakukan operasi yang diperlukan untuk menghitung respons terhadap kueri.
- Selama eksekusi, data dapat dimuat dari cache buffer atau dimuat langsung dari penyimpanan. Jika data dimuat dari penyimpanan, data dari penyimpanan akan disimpan dalam cache untuk penggunaan di masa mendatang.
Resource yang digunakan saat memproses kueri klien mencakup CPU, memori, I/O, jaringan, dan primitif sinkronisasi seperti kunci database. Penyesuaian performa bertujuan untuk mengoptimalkan penggunaan resource selama setiap langkah dalam eksekusi kueri.
Tujuan mesin database yang berperforma tinggi adalah merespons kueri menggunakan resource yang paling sedikit diperlukan. Sasaran ini dimulai dengan model data dan desain kueri yang baik.
- Bagaimana kueri dapat dijawab dengan melihat jumlah data yang paling sedikit?
- Indeks apa yang diperlukan untuk mengurangi ruang penelusuran dan I/O?
- Pengurutan data memerlukan CPU dan, sering kali, akses disk untuk set data besar. Jadi, bagaimana cara menghindari pengurutan data?
Penyimpanan data
AlloyDB Omni menyimpan data dalam halaman berukuran tetap yang disimpan dalam sistem file yang mendasarinya. Saat kueri perlu mengakses data, AlloyDB Omni akan memeriksa kumpulan buffer terlebih dahulu. Jika halaman yang menyimpan data yang diperlukan tidak ditemukan di kumpulan buffer, AlloyDB Omni akan membaca halaman yang diperlukan dari sistem file. Mengakses data dari kumpulan buffer jauh lebih cepat daripada membaca dari sistem file, sehingga memaksimalkan ukuran kumpulan buffer untuk jumlah data yang akan diakses oleh aplikasi adalah faktor yang penting.
Pengelolaan resource
AlloyDB Omni menggunakan pengelolaan memori dinamis untuk memungkinkan kumpulan buffer tumbuh dan menyusut secara dinamis dalam batas yang dikonfigurasi, bergantung pada permintaan memori sistem. Oleh karena itu, Anda tidak perlu menyesuaikan ukuran kumpulan buffer. Saat mendiagnosis masalah performa, metrik pertama yang perlu dipertimbangkan adalah rasio hit buffer pool dan rasio baca untuk melihat apakah aplikasi Anda mendapatkan manfaat dari buffer pool. Jika tidak, hal ini menunjukkan bahwa set data aplikasi tidak sesuai dengan buffer pool, dan Anda dapat mempertimbangkan untuk mengubah ukurannya ke mesin yang lebih besar dengan lebih banyak memori.
Proses pengambilan, pemfilteran, agregasi, pengurutan, dan proyeksi data semuanya memerlukan resource CPU di server database. Untuk mengurangi jumlah resource CPU yang diperlukan untuk proses ini, minimalkan jumlah data yang perlu dimanipulasi. Pantau penggunaan CPU di server database untuk memastikan penggunaan status stabil sekitar 70%. Jumlah ini akan memberikan headroom yang memadai di server untuk lonjakan penggunaan atau perubahan pola akses dari waktu ke waktu. Berjalan dengan penggunaan mendekati 100% akan menyebabkan overhead karena penjadwalan proses dan pengalihan konteks, serta dapat menyebabkan bottleneck di bagian lain sistem. Penggunaan CPU yang tinggi adalah metrik utama lainnya yang dapat digunakan saat membuat keputusan tentang spesifikasi mesin.
Operasi Input/Output Per Detik (IOPS) adalah faktor penting dalam performa aplikasi database -- jumlah operasi input atau output per detik yang dapat dikirimkan perangkat penyimpanan yang mendasarinya ke database. Untuk menghindari batas IOPS penyimpanan database, minimalkan operasi baca dan tulis ke penyimpanan dengan memaksimalkan jumlah data yang dapat muat dalam kumpulan buffer.
Pencadangan data dan pemulihan dari bencana (disaster recovery)
AlloyDB Omni memiliki sistem pencadangan dan pemulihan berkelanjutan yang memungkinkan Anda membuat cluster database baru berdasarkan titik waktu apa pun dalam periode retensi yang dapat disesuaikan. Hal ini memungkinkan Anda memulihkan data dengan cepat dari kecelakaan kehilangan data.
Selain itu, AlloyDB Omni dapat membuat dan menyimpan cadangan lengkap data cluster database Anda, baik secara on-demand maupun sesuai jadwal rutin. Kapan saja, Anda dapat memulihkan dari cadangan ke cluster database AlloyDB Omni yang berisi semua data dari cluster database asli pada saat pembuatan cadangan.
Untuk informasi selengkapnya, lihat Mencadangkan dan memulihkan AlloyDB Omni.
Sebagai metode pemulihan dari bencana lebih lanjut, Anda dapat mencapai replikasi lintas pusat data dengan membuat cluster database sekunder di pusat data terpisah. AlloyDB Omni mengalirkan data secara asinkron dari cluster database utama yang ditetapkan ke setiap cluster sekundernya. Kapan pun diperlukan, Anda dapat mempromosikan cluster database sekunder menjadi cluster database AlloyDB Omni utama.
Untuk informasi selengkapnya, lihat Tentang replikasi lintas pusat data
Dokumentasi untuk AlloyDB Omni versi 15.5.2 dan yang lebih lama
Untuk informasi tentang AlloyDB Omni versi sebelumnya, lihat Rangkaian dokumentasi AlloyDB Omni multi-penampung.