Este documento descreve como interpretar os resultados de desempenho no AlloyDB Omni em uma VM. Este documento pressupõe que você já conhece o PostgreSQL.
Quando você gera um gráfico da capacidade ao longo do tempo à medida que outra variável é modificada, normalmente a capacidade aumenta até chegar a um ponto de esgotamento de recursos.
A figura a seguir mostra um gráfico de dimensionamento de throughput típico. À medida que o número de clientes aumenta, a carga de trabalho e o throughput aumentam até que todos os recursos sejam esgotados.
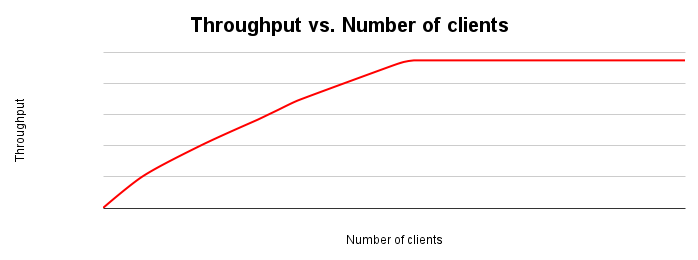
O ideal é que, ao dobrar a carga no sistema, a capacidade também dobre. Na prática, haverá contenção de recursos que leva a aumentos menores de throughput. Em algum momento, o esgotamento ou a contenção de recursos fará com que a taxa de transferência seja nivelada ou até diminua. Se você está otimizando a capacidade, esse é um ponto-chave a ser identificado, porque ele direciona seus esforços para onde ajustar o aplicativo ou o sistema de banco de dados para melhorar a capacidade.
As razões típicas para a redução ou queda da taxa de transferência incluem:
- Esgotamento de recursos de CPU no servidor do banco de dados
- O esgotamento de recursos da CPU no cliente para que o servidor de banco de dados não receba mais trabalho
- Contenção de bloqueio de banco de dados
- Tempo de espera de E/S quando os dados excedem o tamanho do pool de buffers do Postgres
- Tempo de espera de E/S devido à utilização do mecanismo de armazenamento
- Engulhos de largura de banda da rede ao retornar dados para o cliente
A latência e a capacidade de processamento são inversamente proporcionais. À medida que a latência aumenta, a capacidade diminui. Isso faz sentido intuitivamente. À medida que um gargalo começa a se formar, as operações começam a levar mais tempo e o sistema realiza menos operações por segundo.
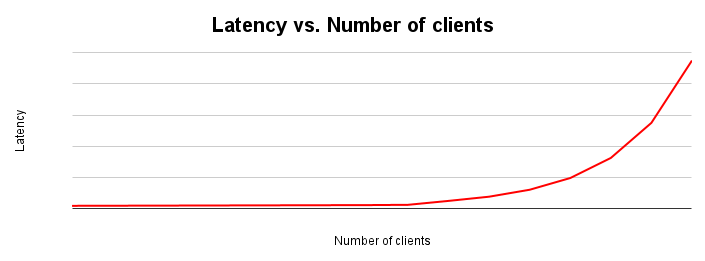
O gráfico de dimensionamento de latência mostra como a latência muda à medida que a carga em um sistema aumenta. A latência permanece relativamente constante até que ocorra uma fricção devido à disputa de recursos. O ponto de inflexão dessa curva geralmente corresponde ao achatamento da curva de throughput no gráfico de escalonamento de throughput.
Outra maneira útil de avaliar a latência é como um histograma. Nessa representação, agrupamos as latências em buckets e contamos quantas solicitações se enquadram em cada um deles.
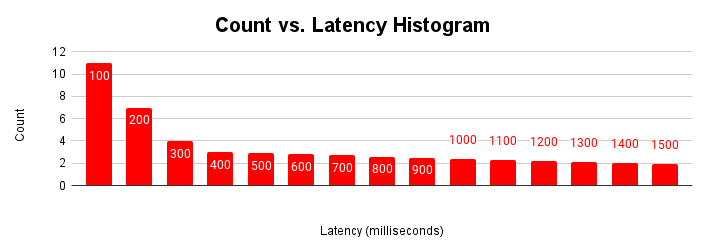
Esse histograma de latência mostra que a maioria das solicitações tem menos de 100 milissegundos e latências maiores que 100 milissegundos. Entender a causa das solicitações com latências mais longas pode ajudar a explicar as variações de desempenho do aplicativo. As causas da cauda longa de latências aumentadas correspondem às latências aumentadas observadas no gráfico de escalonamento de latência típico e ao achatamento do gráfico de throughput.
O histograma de latência é mais útil quando há várias modalidades em um aplicativo. Uma modalidade é um conjunto normal de condições operacionais. Por exemplo, na maioria das vezes, o aplicativo acessa páginas que estão no buffer de cache. Na maioria das vezes, o aplicativo está atualizando linhas existentes. No entanto, pode haver vários modos. Às vezes, o aplicativo está recuperando páginas do armazenamento, inserindo novas linhas ou apresentando contenção de bloqueio.
Quando um aplicativo encontra esses diferentes modos de operação ao longo do tempo, o histograma de latência mostra essas várias modalidades.
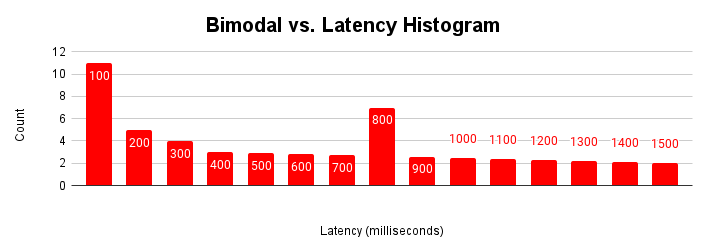
Esta figura mostra um histograma bimodal típico em que a maioria das solicitações é atendida em menos de 100 milissegundos, mas há outro cluster de solicitações que leva de 401 a 500 milissegundos. Entender a causa dessa segunda modalidade pode ajudar a melhorar o desempenho do seu aplicativo. Também pode haver mais de duas modalidades.
A segunda modalidade pode ser devido a operações normais do banco de dados, infraestrutura e topologia heterogêneas ou comportamento do aplicativo. Confira alguns exemplos:
- A maioria dos acessos de dados é do pool de buffer do PostgreSQL, mas alguns vêm do armazenamento
- Diferenças nas latências de rede para alguns clientes no servidor do banco de dados
- A lógica do aplicativo que executa operações diferentes dependendo da entrada ou do horário do dia
- Contenção de bloqueio ocasional
- Picos na atividade do cliente