Die Zuverlässigkeit und Qualität Ihrer Hochverfügbarkeits-Patroni-Einrichtung ist entscheidend, um einen kontinuierlichen Datenbankbetrieb aufrechtzuerhalten und Ausfallzeiten zu minimieren. Auf dieser Seite finden Sie einen umfassenden Leitfaden zum Testen Ihres Patroni-Clusters. Dabei werden verschiedene Fehlerszenarien, die Replikationskonsistenz und Failover-Mechanismen behandelt.
Patroni-Einrichtung testen
Stellen Sie eine Verbindung zu einer Ihrer Patroni-Instanzen (
alloydb-patroni1,alloydb-patroni2oderalloydb-patroni3) her und rufen Sie den Patroni-Ordner von AlloyDB Omni auf.cd /alloydb/
Prüfen Sie die Patroni-Logs.
docker compose logs alloydbomni-patroni
Die letzten Einträge sollten Informationen zum Patroni-Knoten enthalten. Die Ausgabe sollte in etwa so aussehen:
alloydbomni-patroni | 2024-06-12 15:10:29,020 INFO: no action. I am (patroni1), the leader with the lock alloydbomni-patroni | 2024-06-12 15:10:39,010 INFO: no action. I am (patroni1), the leader with the lock alloydbomni-patroni | 2024-06-12 15:10:49,007 INFO: no action. I am (patroni1), the leader with the lockStellen Sie eine Verbindung zu einer Instanz her, auf der Linux ausgeführt wird und die eine Netzwerkverbindung zu Ihrer primären Patroni-Instanz
alloydb-patroni1hat, und rufen Sie Informationen zur Instanz ab. Möglicherweise müssen Sie dasjq-Tool installieren, indem Siesudo apt-get install jq -yausführen.curl -s http://alloydb-patroni1:8008/patroni | jq .
Die Ausgabe sollte in etwa so aussehen:
{ "state": "running", "postmaster_start_time": "2024-05-16 14:12:30.031673+00:00", "role": "master", "server_version": 150005, "xlog": { "location": 83886408 }, "timeline": 1, "replication": [ { "usename": "alloydbreplica", "application_name": "patroni2", "client_addr": "10.172.0.40", "state": "streaming", "sync_state": "async", "sync_priority": 0 }, { "usename": "alloydbreplica", "application_name": "patroni3", "client_addr": "10.172.0.41", "state": "streaming", "sync_state": "async", "sync_priority": 0 } ], "dcs_last_seen": 1715870011, "database_system_identifier": "7369600155531440151", "patroni": { "version": "3.3.0", "scope": "my-patroni-cluster", "name": "patroni1" } }
Wenn Sie den Patroni-HTTP-API-Endpunkt auf einem Patroni-Knoten aufrufen, werden verschiedene Details zum Status und zur Konfiguration der von Patroni verwalteten PostgreSQL-Instanz angezeigt, einschließlich Informationen zum Clusterstatus, zum Zeitplan, zu WAL-Informationen und zu Gesundheitschecks, die angeben, ob die Knoten und der Cluster ordnungsgemäß funktionieren.
HAProxy-Einrichtung testen
Rufen Sie auf einem Computer mit einem Browser und Netzwerkverbindung zu Ihrem HAProxy-Knoten die folgende Adresse auf:
http://haproxy:7000. Alternativ können Sie die externe IP-Adresse der HAProxy-Instanz anstelle des Hostnamens verwenden.Es sollte ungefähr so aussehen wie im folgenden Screenshot.
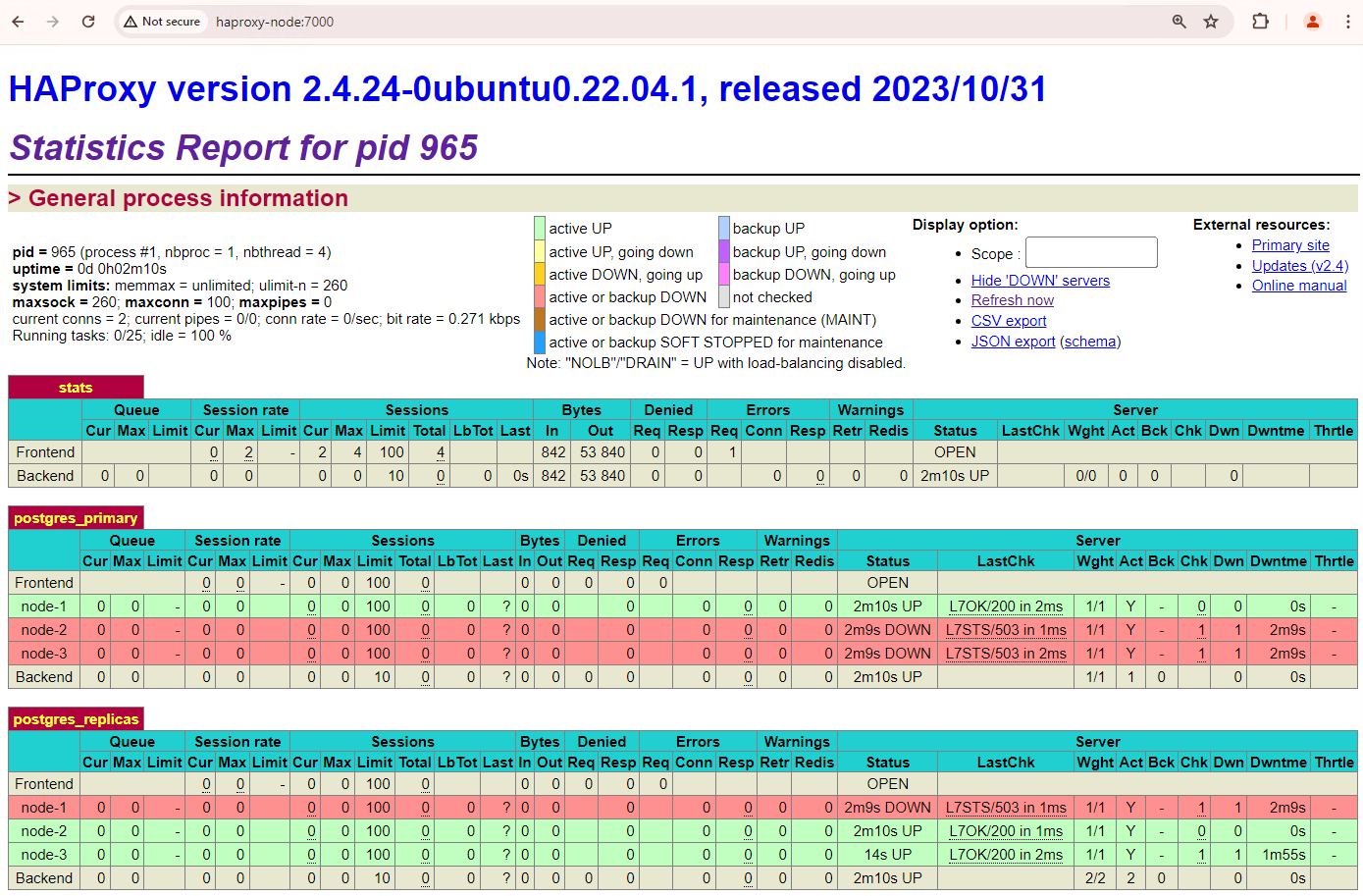
Abbildung 1. HAProxy-Statusseite mit dem Betriebsstatus und der Latenz von Patroni-Knoten
Im HAProxy-Dashboard sehen Sie den Systemstatus und die Latenz des primären Patroni-Knotens
patroni1und der beiden Replikenpatroni2undpatroni3.Sie können Abfragen ausführen, um die Replikationsstatistiken in Ihrem Cluster zu prüfen. Stellen Sie über einen Client wie pgAdmin eine Verbindung über HAProxy zum primären Datenbankserver her und führen Sie die folgende Abfrage aus.
SELECT pid, usename, application_name, client_addr, state, sync_state FROM pg_stat_replication;Das Diagramm sollte in etwa so aussehen:
patroni2undpatroni3werden vonpatroni1gestreamt.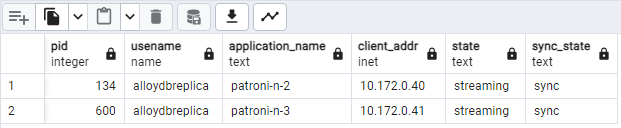
Abbildung 2: pg_stat_replication-Ausgabe mit dem Replikationsstatus der Patroni-Knoten
Automatischen Failover testen
In diesem Abschnitt simulieren wir in Ihrem Cluster mit drei Knoten einen Ausfall des primären Knotens, indem wir den angehängten laufenden Patroni-Container beenden. Sie können entweder den Patroni-Dienst auf dem primären Knoten beenden, um einen Ausfall zu simulieren, oder einige Firewallregeln erzwingen, um die Kommunikation mit diesem Knoten zu beenden.
Rufen Sie auf der primären Patroni-Instanz den Ordner „AlloyDB Omni Patroni“ auf.
cd /alloydb/
Beenden Sie den Container.
docker compose down
Die Ausgabe sollte in etwa so aussehen: Dadurch sollte überprüft werden, ob der Container und das Netzwerk angehalten wurden.
[+] Running 2/2 ✔ Container alloydb-patroni Removed ✔ Network alloydbomni-patroni_default RemovedAktualisieren Sie das HAProxy-Dashboard und sehen Sie sich an, wie das Failover abläuft.
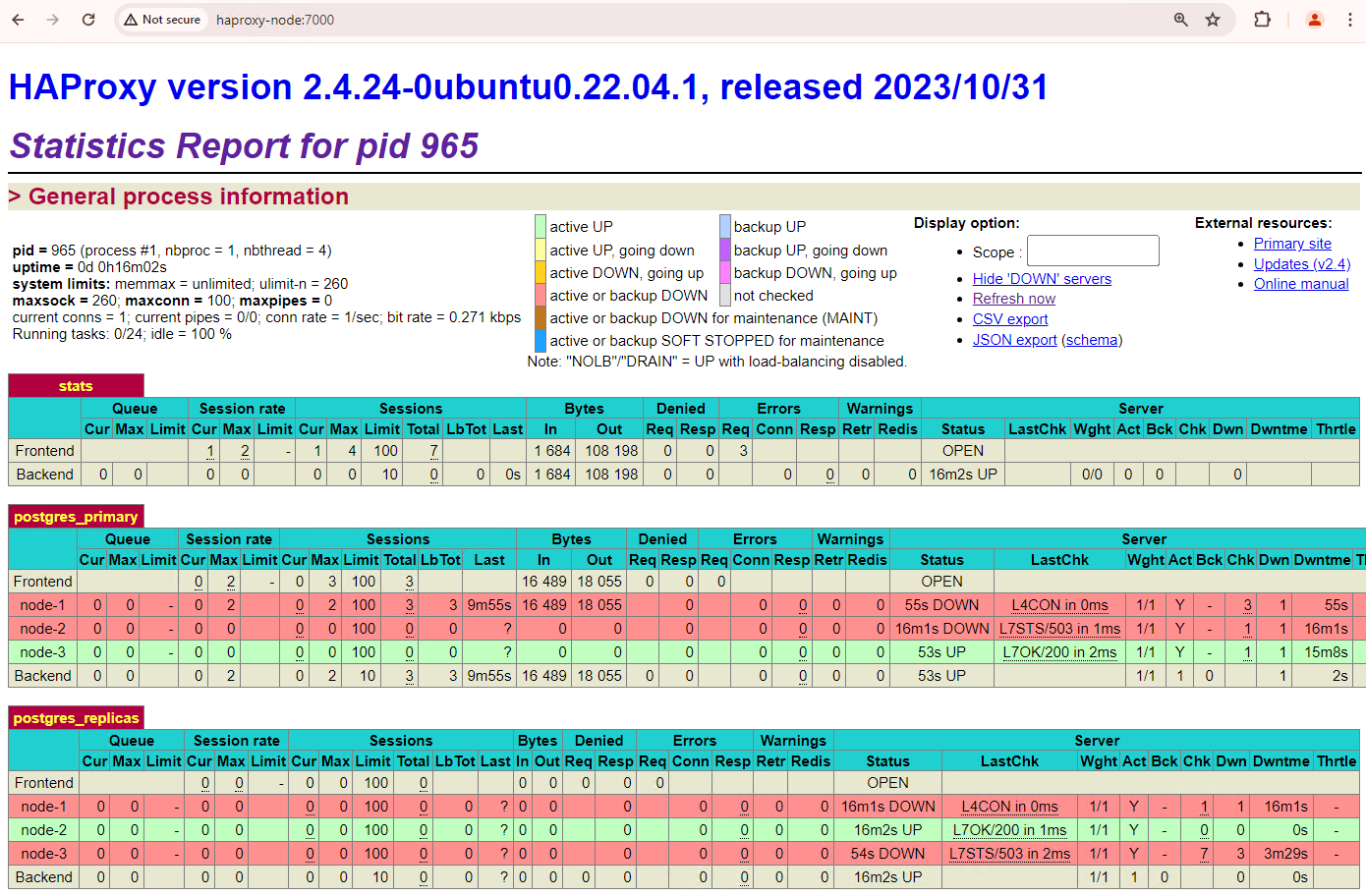
Abbildung 3. HAProxy-Dashboard mit dem Failover vom primären Knoten zum Standby-Knoten
Die Instanz
patroni3ist zur neuen primären Instanz geworden undpatroni2ist das einzige verbleibende Replikat. Die vorherige primäre Instanz,patroni1, ist ausgefallen und die Systemdiagnosen für sie schlagen fehl.Patroni führt den Failover durch eine Kombination aus Monitoring, Konsens und automatisierter Orchestrierung aus und verwaltet ihn. Sobald der primäre Knoten seinen Lease nicht innerhalb eines bestimmten Zeitlimits verlängert oder einen Fehler meldet, erkennen die anderen Knoten im Cluster diesen Zustand über das Konsenssystem. Die verbleibenden Knoten koordinieren sich, um das am besten geeignete Replikat auszuwählen, das als neues primäres Replikat festgelegt werden soll. Sobald ein Kandidat ausgewählt wurde, befördert Patroni diesen Knoten zum primären Knoten, indem die erforderlichen Änderungen angewendet werden, z. B. die Aktualisierung der PostgreSQL-Konfiguration und das Wiedergeben aller ausstehenden WAL-Einträge. Anschließend aktualisiert der neue primäre Knoten das Konsenssystem mit seinem Status und die anderen Replikate werden neu konfiguriert, um dem neuen primären Knoten zu folgen. Dazu gehört auch ein Wechsel der Replikationsquelle und gegebenenfalls das Aufholen neuer Transaktionen. HAProxy erkennt den neuen primären Server und leitet Clientverbindungen entsprechend weiter, um Unterbrechungen zu minimieren.
Stellen Sie über einen Client wie pgAdmin eine Verbindung über HAProxy zum Datenbankserver her und prüfen Sie die Replikationsstatistiken in Ihrem Cluster nach dem Failover.
SELECT pid, usename, application_name, client_addr, state, sync_state FROM pg_stat_replication;Es sollte in etwa so aussehen wie das folgende Diagramm, das zeigt, dass derzeit nur
patroni2gestreamt wird.
Abbildung 4: pg_stat_replication-Ausgabe mit dem Replikationsstatus der Patroni-Knoten nach dem Failover
Ihr Cluster mit drei Knoten kann noch einen Ausfall verkraften. Wenn Sie den aktuellen primären Knoten
patroni3beenden, wird ein weiterer Failover ausgeführt.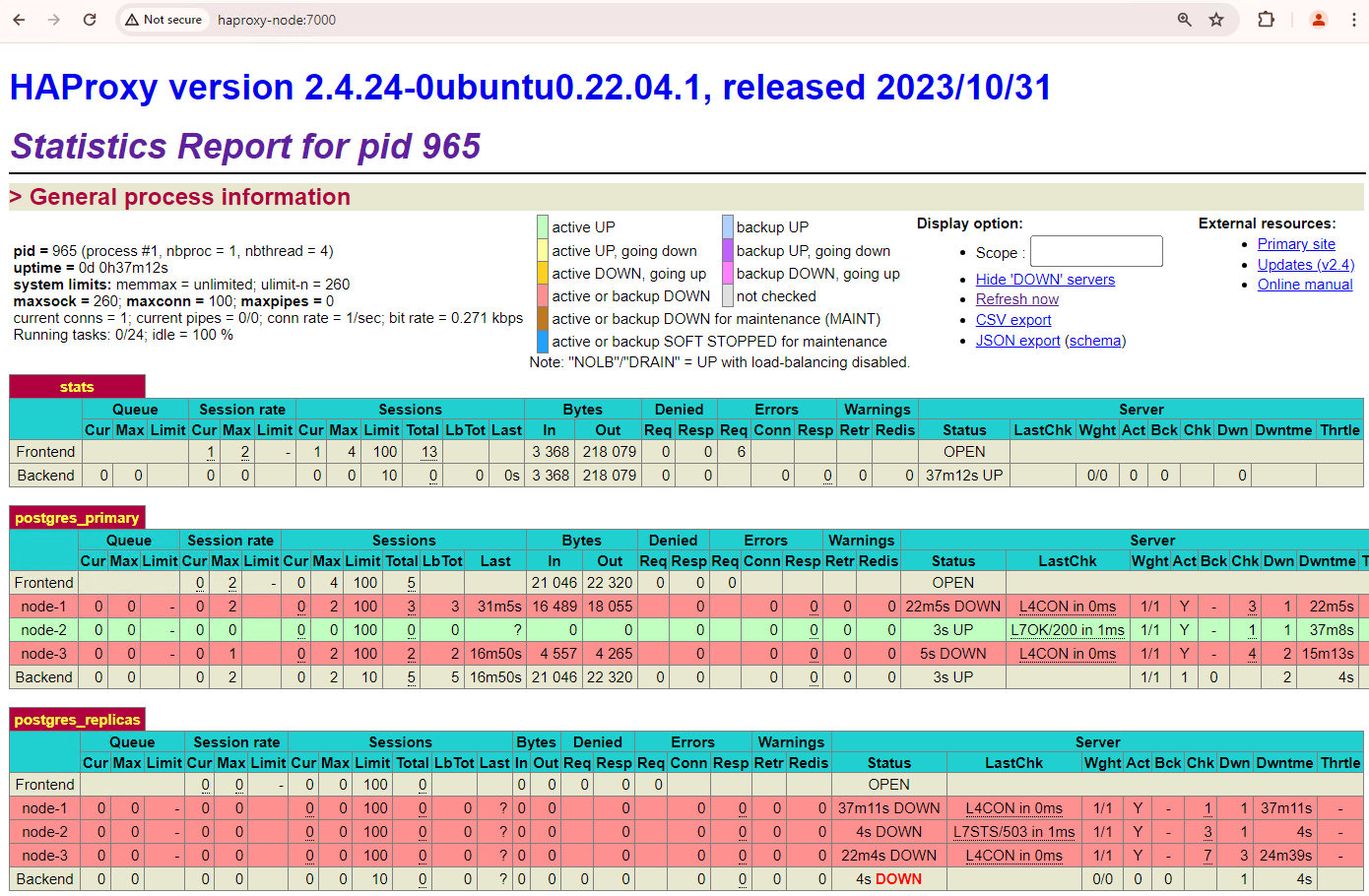
Abbildung 5. HAProxy-Dashboard mit dem Failover vom primären Knoten
patroni3zum Standby-Knotenpatroni2
Fallback-Überlegungen
Der Fallback ist der Prozess, bei dem der vorherige Quellknoten nach einem Failover reaktiviert wird. Ein automatischer Failover wird in einem Hochverfügbarkeits-Datenbankcluster aufgrund mehrerer kritischer Probleme in der Regel nicht empfohlen, z. B. unvollständige Wiederherstellung, das Risiko von Split-Brain-Szenarien und Replikationsverzögerungen.
Wenn Sie in Ihrem Patroni-Cluster die beiden Knoten starten, mit denen Sie einen Ausfall simuliert haben, werden sie dem Cluster als Standby-Replikate wieder beitreten.
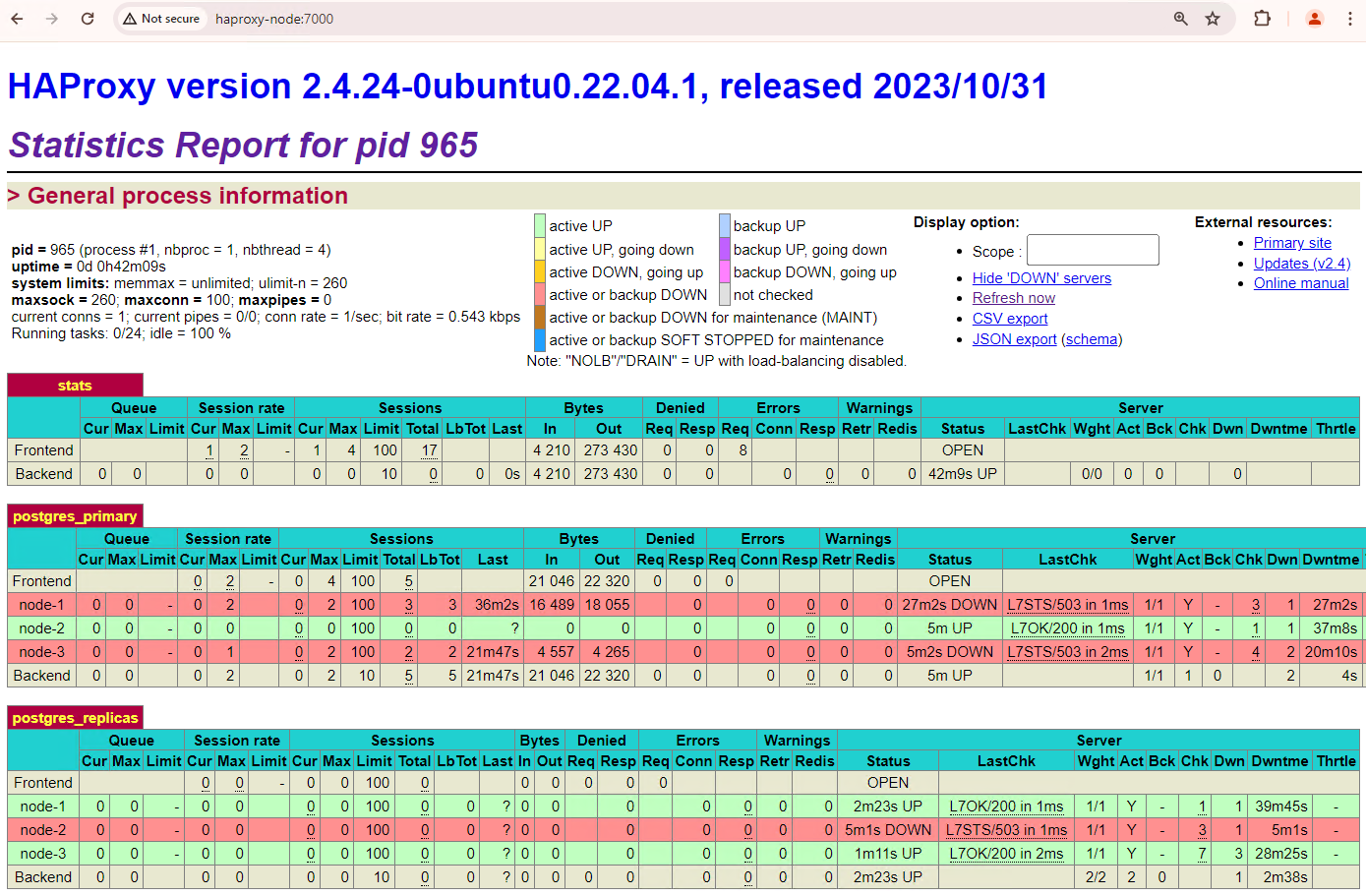
Abbildung 6. HAProxy-Dashboard mit der Wiederherstellung von patroni1 und patroni3 als Standby-Knoten
Jetzt werden patroni1 und patroni3 von der aktuellen primären Instanz patroni2 repliziert.

Abbildung 7: pg_stat_replication-Ausgabe mit dem Replikationsstatus der Patroni-Knoten nach dem Fallback
Wenn Sie manuell zum ursprünglichen primären Knoten zurückkehren möchten, können Sie dies über die Befehlszeile patronictl tun. Wenn Sie den manuellen Fallback auswählen, können Sie einen zuverlässigeren, konsistenteren und gründlich geprüften Wiederherstellungsprozess sicherstellen und so die Integrität und Verfügbarkeit Ihrer Datenbanksysteme aufrechterhalten.