Menemukan penyebab error yang muncul saat melatih model atau mendapatkan prediksi di cloud bisa jadi sulit. Halaman ini menjelaskan cara menemukan dan men-debug masalah yang Anda alami di AI Platform Training. Jika Anda mengalami masalah dengan framework machine learning yang digunakan, baca dokumentasi untuk framework machine learning.
Alat command line
ERROR: (gcloud) Invalid choice: 'ai-platform'.Error ini berarti Anda perlu mengupdate gcloud. Untuk mengupdate gcloud, jalankan perintah berikut:
gcloud components updateERROR: (gcloud) unrecognized arguments: --framework=SCIKIT_LEARN.Error ini berarti Anda perlu mengupdate gcloud. Untuk mengupdate gcloud, jalankan perintah berikut:
gcloud components updateERROR: (gcloud) unrecognized arguments: --framework=XGBOOST.Error ini berarti Anda perlu mengupdate gcloud. Untuk mengupdate gcloud, jalankan perintah berikut:
gcloud components updateERROR: (gcloud) Failed to load model: Could not load the model: /tmp/model/0001/model.pkl. '\\x03'. (Error code: 0)Error ini berarti library yang salah digunakan untuk mengekspor model. Untuk memperbaikinya, ekspor ulang model menggunakan library yang benar. Misalnya, ekspor model dalam bentuk
model.pkldengan librarypickledan model dalam bentukmodel.joblibdengan libraryjoblib.ERROR: (gcloud.ai-platform.jobs.submit.prediction) argument --data-format: Invalid choice: 'json'.Error ini berarti Anda menentukan
jsonsebagai nilai tanda--data-formatsaat mengirimkan tugas prediksi batch. Untuk menggunakan format dataJSON, Anda harus memberikantextsebagai nilai flag--data-format.
Versi Python
ERROR: Bad model detected with error: "Failed to load model: Could not load the
model: /tmp/model/0001/model.pkl. unsupported pickle protocol: 3. Please make
sure the model was exported using python 2. Otherwise, please specify the
correct 'python_version' parameter when deploying the model. Currently,
'python_version' accepts 2.7 and 3.5. (Error code: 0)"
Error ini berarti file model yang diekspor dengan Python 3 di-deploy ke resource versi model AI Platform Training dengan setelan Python 2.7.
Untuk mengatasinya:
- Buat resource versi model baru dan tetapkan 'python_version' ke 3.5.
- Deploy file model yang sama ke resource versi model baru.
Perintah virtualenv tidak ditemukan
Jika Anda mendapatkan error ini saat mencoba mengaktifkan virtualenv, salah satu kemungkinan
solusi adalah menambahkan direktori yang berisi virtualenv ke variabel lingkungan
$PATH. Dengan mengubah variabel ini, Anda dapat menggunakan perintah virtualenv
tanpa mengetik jalur file lengkapnya.
Pertama, instal virtualenv dengan menjalankan perintah berikut:
pip install --user --upgrade virtualenv
Penginstal akan meminta Anda untuk mengubah variabel lingkungan
$PATH, dan memberikan jalur ke skrip virtualenv. Di macOS, ini
terlihat mirip dengan
/Users/[YOUR-USERNAME]/Library/Python/[YOUR-PYTHON-VERSION]/bin.
Buka file tempat shell memuat variabel lingkungan. Biasanya, ini adalah
~/.bashrc atau ~/.bash_profile di macOS.
Tambahkan baris berikut, ganti [VALUES-IN-BRACKETS] dengan nilai yang sesuai:
export PATH=$PATH:/Users/[YOUR-USERNAME]/Library/Python/[YOUR-PYTHON-VERSION]/bin
Terakhir, jalankan perintah berikut untuk memuat file .bashrc (atau .bash_profile) yang telah diperbarui:
source ~/.bashrc
Menggunakan log tugas
Tempat pertama yang baik untuk memulai pemecahan masalah adalah log tugas yang diambil oleh Cloud Logging.
Logging untuk berbagai jenis operasi
Pengalaman logging Anda bervariasi menurut jenis operasi seperti yang ditunjukkan di bagian berikut.
Log pelatihan
Semua tugas pelatihan Anda dicatat ke dalam log. Log menyertakan peristiwa dari layanan pelatihan dan dari aplikasi pelatihan Anda. Anda dapat menempatkan peristiwa logging di aplikasi dengan library Python standar (misalnya, logging). AI Platform Training merekam semua pesan logging dari aplikasi Anda. Semua pesan yang dikirim ke stderr akan otomatis dicatat dalam entri tugas Anda di Cloud Logging.
Log prediksi batch
Semua tugas prediksi batch Anda dicatat ke dalam log.
Log prediksi online
Permintaan prediksi online Anda tidak menghasilkan log secara default. Anda dapat mengaktifkan Cloud Logging saat membuat resource model:
gcloud
Sertakan flag --enable-logging saat Anda menjalankan
gcloud ai-platform models create.
Python
Tetapkan onlinePredictionLogging ke True di
resource Model yang Anda gunakan
untuk panggilan ke
projects.models.create.
Menemukan log
Log tugas Anda berisi semua peristiwa untuk operasi Anda, termasuk peristiwa dari semua proses di cluster saat Anda menggunakan pelatihan terdistribusi. Jika Anda menjalankan tugas pelatihan terdistribusi, log tingkat tugas akan dilaporkan untuk proses pekerja master. Langkah pertama pemecahan masalah error biasanya adalah memeriksa log untuk proses tersebut, memfilter peristiwa yang dicatat ke dalam log untuk proses lain di cluster Anda. Contoh di bagian ini menunjukkan pemfilteran tersebut.
Anda dapat memfilter log dari command line atau di bagian Cloud Logging di Konsol Google Cloud. Dalam kedua kasus tersebut, gunakan nilai metadata ini dalam filter Anda sesuai kebutuhan:
| Item metadata | Filter untuk menampilkan item yang... |
|---|---|
| resource.type | Sama dengan "cloud_ml_job". |
| resource.labels.job_id | Sama dengan nama tugas Anda. |
| resource.labels.task_name | Sama dengan "master-replica-0" untuk hanya membaca entri log untuk pekerja master Anda. |
| tingkat keseriusan, | Lebih besar dari atau sama dengan ERROR untuk hanya membaca entri log yang sesuai dengan kondisi error. |
Command Line
Gunakan gcloud beta logging read untuk membuat kueri yang memenuhi kebutuhan Anda. Berikut beberapa contohnya:
Setiap contoh bergantung pada variabel lingkungan ini:
PROJECT="my-project-name"
JOB="my_job_name"
Anda dapat memasukkan literal string sebagai gantinya jika mau.
Untuk mencetak log tugas ke layar:
gcloud ai-platform jobs stream-logs $JOB
Lihat semua opsi untuk gcloud ai-platform jobs stream-logs.
Untuk mencetak log bagi pekerja master ke layar:
gcloud beta logging read --project=${PROJECT} "resource.type=\"ml_job\" and resource.labels.job_id=${JOB} and resource.labels.task_name=\"master-replica-0\""
Untuk hanya mencetak error yang dicatat ke dalam log untuk pekerja master ke layar:
gcloud beta logging read --project=${PROJECT} "resource.type=\"ml_job\" and resource.labels.job_id=${JOB} and resource.labels.task_name=\"master-replica-0\" and severity>=ERROR"
Contoh sebelumnya mewakili kasus pemfilteran yang paling umum untuk log dari tugas pelatihan AI Platform Training Anda. Cloud Logging menyediakan banyak opsi pemfilteran yang canggih dan dapat Anda gunakan jika perlu menyaring penelusuran. Dokumentasi pemfilteran lanjutan menjelaskan opsi tersebut secara mendetail.
Konsol
Buka halaman Jobs AI Platform Training di konsol Google Cloud.
Pilih tugas yang gagal dari daftar di halaman Tugas untuk melihat detailnya.

- Klik Lihat log untuk membuka Cloud Logging.
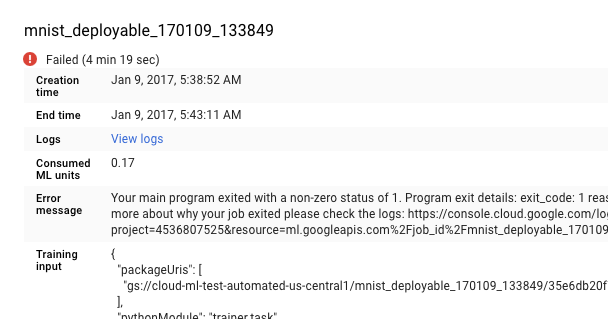
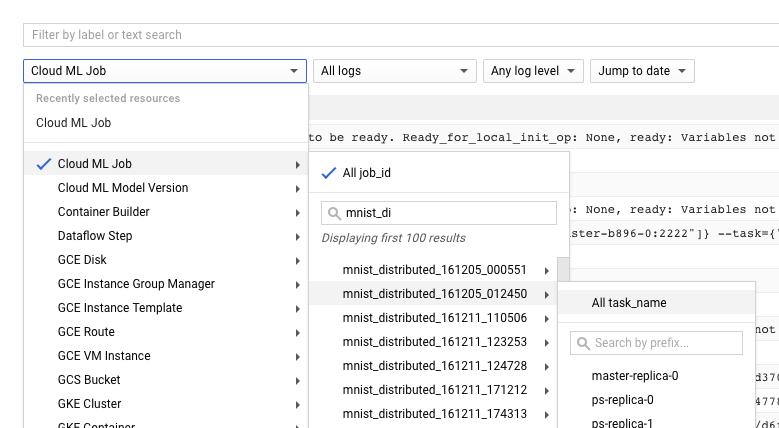
Anda juga dapat langsung membuka Cloud Logging, tetapi Anda memiliki langkah tambahan untuk menemukan tugas:
- Luaskan pemilih aset.
- Luaskan Tugas Cloud ML dalam daftar resource.
- Temukan nama tugas Anda dalam daftar job_id (Anda dapat memasukkan beberapa huruf pertama nama tugas di kotak penelusuran untuk mempersempit tugas yang ditampilkan).
- Luaskan entri tugas dan pilih
master-replica-0dari daftar tugas.
Mendapatkan informasi dari log
Setelah menemukan log yang tepat untuk tugas Anda dan memfilternya ke master-replica-0, Anda dapat memeriksa peristiwa yang dicatat dalam log untuk menemukan sumber masalah. Hal ini melibatkan prosedur proses debug Python standar, tetapi hal-hal berikut
perlu diingat:
- Peristiwa memiliki beberapa tingkat keparahan. Anda dapat memfilter untuk melihat peristiwa dari tingkat tertentu, seperti error, atau error dan peringatan.
- Masalah yang menyebabkan pelatih Anda keluar dengan kondisi error yang tidak dapat dipulihkan (kode return > 0) dicatat ke dalam log sebagai pengecualian yang didahului oleh pelacakan stack:
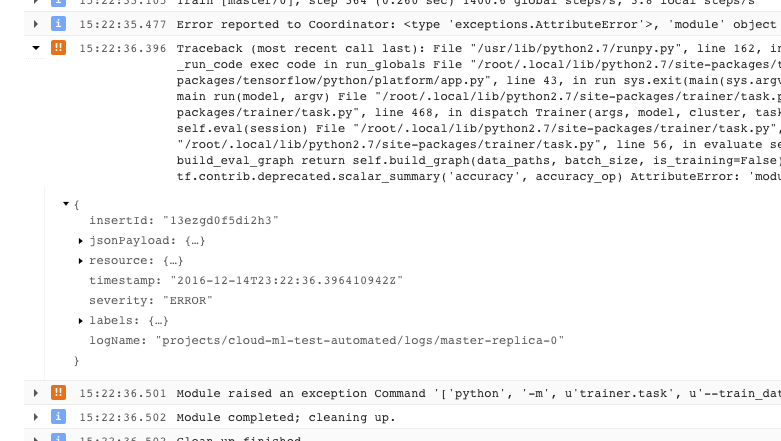
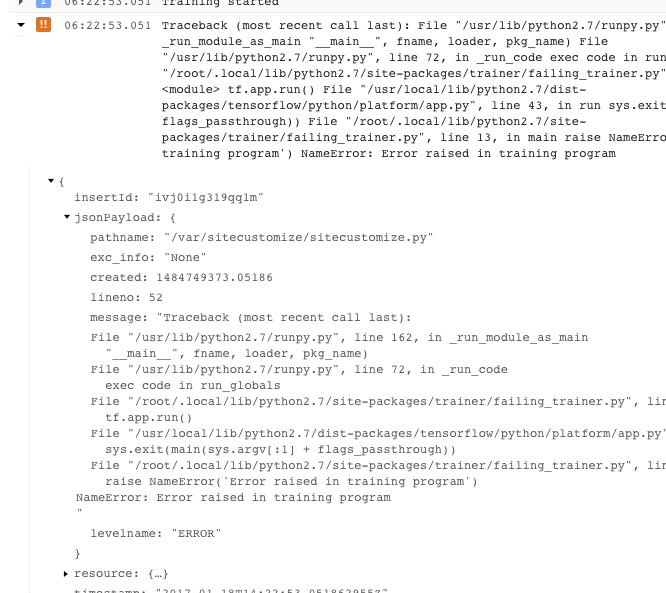
- Anda bisa mendapatkan informasi selengkapnya dengan meluaskan objek dalam pesan JSON yang dicatat ke dalam log (ditunjukkan dengan panah yang menghadap ke kanan dan konten yang tercantum sebagai {...}). Misalnya, Anda dapat meluaskan jsonPayload untuk melihat pelacakan tumpukan dalam bentuk yang lebih mudah dibaca daripada yang diberikan dalam deskripsi error utama:
- Beberapa error menampilkan instance error yang dapat dicoba ulang. Error ini biasanya tidak menyertakan pelacakan tumpukan dan dapat lebih sulit didiagnosis.
Mengoptimalkan logging
Layanan pelatihan AI Platform Training secara otomatis mencatat peristiwa berikut:
- Informasi status internal untuk layanan.
- Pesan yang dikirim aplikasi pelatih Anda ke
stderr. - Output teks yang dikirim aplikasi pelatih Anda ke
stdout.
Anda dapat mempermudah pemecahan masalah error di aplikasi pelatih dengan mengikuti praktik pemrograman yang baik:
- Kirim pesan yang bermakna ke stderr (misalnya, dengan logging).
- Menampilkan pengecualian yang paling logis dan deskriptif saat terjadi masalah.
- Tambahkan string deskriptif ke objek pengecualian Anda.
Dokumentasi Python memberikan informasi selengkapnya tentang pengecualian.
Pelatihan pemecahan masalah
Bagian ini menjelaskan konsep dan kondisi error yang berlaku untuk tugas pelatihan.
Memahami kode hasil aplikasi pelatihan
Tugas pelatihan Anda di cloud dikontrol oleh program utama yang berjalan di proses pekerja master cluster pelatihan Anda:
- Jika Anda melakukan pelatihan dalam satu proses (non-terdistribusi), Anda hanya memiliki satu pekerja, yaitu master.
- Program utama Anda adalah fungsi
__main__dari aplikasi pelatihan TensorFlow. - Layanan pelatihan AI Platform Training menjalankan aplikasi pelatih Anda hingga berhasil diselesaikan atau mengalami error yang tidak dapat dipulihkan. Artinya, proses dapat dimulai ulang jika terjadi error yang dapat dicoba ulang.
Layanan pelatihan mengelola proses Anda. Fungsi ini menangani keluarnya program sesuai dengan kode return dari proses pekerja master Anda:
| Kode status | Arti | Respons AI Platform Training |
|---|---|---|
| 0 | Penyelesaian yang berhasil | Mematikan dan melepaskan resource tugas. |
| 1 - 128 | Error yang tidak dapat dipulihkan | Mengakhiri tugas dan mencatat error ke dalam log. |
Anda tidak perlu melakukan apa pun secara khusus terkait kode return fungsi
__main__. Python otomatis menampilkan nol jika berhasil diselesaikan,
dan menampilkan kode positif saat menemukan pengecualian yang tidak ditangani. Jika Anda
terbiasa menetapkan kode return tertentu ke objek pengecualian (praktik yang valid tetapi tidak umum), hal ini tidak akan mengganggu
tugas AI Platform Training, selama Anda mengikuti pola dalam tabel
di atas. Meskipun demikian, kode klien biasanya tidak menunjukkan error yang dapat dicoba ulang secara langsung—error tersebut berasal dari lingkungan operasi.
Menangani kondisi error tertentu
Bagian ini memberikan panduan tentang beberapa kondisi error yang diketahui memengaruhi beberapa pengguna.
Resource sudah terlampaui
Permintaan GPU dan resource komputasi di region us-central1 tinggi.
Anda mungkin mendapatkan pesan error di log tugas yang bertuliskan: Resources are
insufficient in region: <region>. Please try a different region..
Untuk mengatasinya, coba gunakan region lain atau coba lagi nanti.
Pelatih berjalan selamanya tanpa membuat progres apa pun
Beberapa situasi dapat menyebabkan aplikasi pelatih Anda berjalan terus-menerus tanpa membuat progres pada tugas pelatihan. Hal ini mungkin disebabkan oleh panggilan pemblokiran yang menunggu resource yang tidak pernah tersedia. Anda dapat mengurangi masalah ini dengan mengonfigurasi interval waktu tunggu di pelatih.
Mengonfigurasi interval waktu tunggu untuk pelatih
Anda dapat menetapkan waktu tunggu, dalam milidetik, saat membuat sesi, atau saat menjalankan langkah grafik:
Tetapkan interval waktu tunggu yang diinginkan menggunakan parameter config saat Anda membuat objek Session:
sess = tf.Session(config=tf.ConfigProto(operation_timeout_in_ms=500))Tetapkan interval waktu tunggu yang diinginkan untuk satu panggilan ke Session.run dengan menggunakan parameter options:
v = session.run(fetches, options=tf.RunOptions(timeout_in_ms=500))
Lihat dokumentasi Sesi TensorFlow untuk informasi selengkapnya.
Program keluar dengan kode -9
Jika Anda mendapatkan kode keluar -9 secara konsisten, aplikasi pelatih Anda mungkin menggunakan lebih banyak memori daripada yang dialokasikan untuk prosesnya. Perbaiki error ini dengan mengurangi penggunaan memori, menggunakan jenis mesin dengan lebih banyak memori, atau keduanya.
- Periksa aplikasi grafik dan pelatih Anda untuk menemukan operasi yang menggunakan lebih banyak memori daripada yang diperkirakan. Penggunaan memori dipengaruhi oleh kompleksitas data Anda, dan kompleksitas operasi dalam grafik komputasi Anda.
- Meningkatkan memori yang dialokasikan untuk tugas Anda mungkin memerlukan beberapa keahlian:
- Jika menggunakan tingkat skala yang ditentukan, Anda tidak dapat meningkatkan alokasi memori per mesin tanpa menambahkan lebih banyak mesin ke campuran. Anda harus beralih ke tingkat KUSTOM dan menentukan jenis mesin di cluster sendiri.
- Konfigurasi yang tepat dari setiap jenis mesin yang ditentukan dapat berubah, tetapi Anda dapat membuat beberapa perbandingan kasar. Anda akan menemukan tabel perbandingan jenis mesin di halaman konsep pelatihan.
- Saat menguji jenis mesin untuk alokasi memori yang sesuai, Anda mungkin ingin menggunakan satu mesin, atau cluster dengan ukuran yang dikurangi, untuk meminimalkan tagihan yang timbul.
Program keluar dengan kode -15
Biasanya, kode keluar -15 menunjukkan pemeliharaan oleh sistem. Ini adalah error yang dapat dicoba lagi, sehingga proses Anda akan dimulai ulang secara otomatis.
Tugas diantrekan dalam waktu lama
Jika Status tugas pelatihan
adalah QUEUED untuk jangka waktu yang lama, Anda mungkin telah melampaui
kuota permintaan tugas.
AI Platform Training memulai tugas pelatihan berdasarkan waktu pembuatan tugas, menggunakan aturan first-in, first-out. Jika tugas Anda diantrekan, biasanya berarti semua kuota project digunakan oleh tugas lain yang dikirimkan sebelum tugas Anda atau tugas pertama dalam antrean meminta lebih banyak unit ML/GPU daripada kuota yang tersedia.
Alasan tugas telah diantrekan dicatat dalam log pelatihan. Telusuri log untuk menemukan pesan yang mirip dengan:
This job is number 2 in the queue and requires
4.000000 ML units and 0 GPUs. The project is using 4.000000 ML units out of 4
allowed and 0 GPUs out of 10 allowed.Pesan ini menjelaskan posisi tugas Anda saat ini dalam antrean, serta penggunaan dan kuota project saat ini.
Perhatikan bahwa alasan hanya akan dicatat ke dalam log untuk sepuluh tugas pertama dalam antrean yang diurutkan berdasarkan waktu pembuatan tugas.
Jika Anda secara rutin memerlukan lebih dari jumlah permintaan yang dialokasikan, Anda dapat meminta penambahan kuota. Hubungi dukungan jika Anda memiliki paket dukungan premium. Atau, Anda dapat mengirim permintaan melalui email ke Masukan Pelatihan AI Platform .
Melebihi kuota
Jika Anda mendapatkan error dengan pesan seperti "Kegagalan kuota untuk project_number:...", Anda mungkin telah melampaui salah satu kuota resource. Anda dapat memantau konsumsi resource dan meminta peningkatan di halaman kuota AI Platform Training di API Manager konsol.
Jalur penyimpanan tidak valid
Jika tugas Anda keluar dengan pesan error yang menyertakan "Pemulihan dipanggil dengan jalur penyimpanan yang tidak valid gs://...", Anda mungkin menggunakan bucket Google Cloud Storage yang tidak dikonfigurasi dengan benar.
Buka halaman Browser Google Cloud Storage di konsol Google Cloud.
Periksa Default storage class untuk bucket yang Anda gunakan:
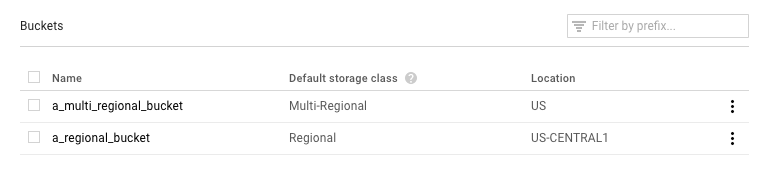
- Seharusnya Regional. Jika demikian, berarti ada masalah lain. Coba jalankan lagi tugas Anda.
- Jika Multi-Regional, Anda harus mengubahnya menjadi Regional, atau memindahkan materi pelatihan ke bucket lain. Untuk yang pertama, temukan petunjuk untuk mengubah class penyimpanan bucket dalam dokumentasi Cloud Storage.
Pelatih keluar dengan AbortedError
Error ini dapat terjadi jika Anda menjalankan pelatih yang menggunakan TensorFlow Supervisor untuk mengelola tugas terdistribusi. TensorFlow terkadang menampilkan pengecualian AbortedError dalam situasi saat Anda tidak boleh menghentikan seluruh tugas. Anda dapat menangkap pengecualian tersebut di pelatih dan meresponsnya dengan sesuai. Perhatikan bahwa TensorFlow Supervisor tidak didukung di pelatih yang Anda jalankan dengan AI Platform Training.
Memecahkan masalah prediksi
Bagian ini mengumpulkan beberapa masalah umum yang terjadi saat mendapatkan prediksi.
Menangani kondisi tertentu untuk prediksi online
Bagian ini memberikan panduan tentang beberapa kondisi error prediksi online yang diketahui memengaruhi beberapa pengguna.
Prediksi memerlukan waktu terlalu lama untuk diselesaikan (30-180 detik)
Penyebab paling umum dari prediksi online yang lambat adalah penskalaan node pemrosesan dari nol. Jika model Anda memiliki permintaan prediksi reguler yang dibuat terhadapnya, sistem akan mempertahankan satu atau beberapa node agar siap menayangkan prediksi. Jika model Anda belum menayangkan prediksi dalam waktu lama, layanan akan "memperkecil skala" menjadi nol node yang siap. Permintaan prediksi berikutnya setelah penskalaan ke bawah tersebut akan memerlukan waktu jauh lebih lama untuk ditampilkan daripada biasanya karena layanan harus menyediakan node untuk menanganinya.
Kode status HTTP
Saat terjadi error dengan permintaan prediksi online, Anda biasanya akan mendapatkan kode status HTTP dari layanan. Berikut adalah beberapa kode yang biasa ditemui dan maknanya dalam konteks prediksi online:
- 429 - Kehabisan Memori
Node pemrosesan kehabisan memori saat menjalankan model Anda. Saat ini, tidak ada cara untuk meningkatkan memori yang dialokasikan ke node prediksi. Anda dapat mencoba hal-hal berikut untuk menjalankan model:
- Kurangi ukuran model dengan:
- Menggunakan variabel yang kurang akurat.
- Mengkuantitatifkan data kontinu Anda.
- Mengurangi ukuran fitur input lainnya (misalnya, menggunakan ukuran kosakata yang lebih kecil).
- Kirim permintaan lagi dengan batch instance yang lebih kecil.
- Kurangi ukuran model dengan:
- 429 - Terlalu banyak permintaan yang tertunda
Model Anda mendapatkan lebih banyak permintaan daripada yang dapat ditanganinya. Jika Anda menggunakan penskalaan otomatis, permintaan akan diterima lebih cepat daripada kemampuan sistem untuk melakukan penskalaan.
Dengan penskalaan otomatis, Anda dapat mencoba mengirim ulang permintaan dengan backoff eksponensial. Tindakan ini dapat memberi sistem waktu untuk menyesuaikan.
- 429 - Kuota
Project Google Cloud Platform Anda dibatasi hingga 10.000 permintaan setiap 100 detik (sekitar 100 per detik). Jika Anda mendapatkan error ini dalam lonjakan sementara, Anda sering dapat mencoba lagi dengan backoff eksponensial untuk memproses semua permintaan tepat waktu. Jika Anda terus mendapatkan kode ini, Anda dapat meminta peningkatan kuota. Lihat halaman kuota untuk mengetahui detail selengkapnya.
- 503 - Sistem kami mendeteksi adanya traffic yang tidak biasa dari jaringan komputer Anda
Rasio permintaan yang diterima model Anda dari satu IP sangat tinggi sehingga sistem mencurigai serangan denial of service. Hentikan pengiriman permintaan selama satu menit, lalu lanjutkan pengiriman dengan kecepatan yang lebih rendah.
- 500 - Tidak dapat memuat model
Sistem mengalami masalah saat memuat model Anda. Coba langkah-langkah berikut:
- Pastikan bahwa pelatih Anda mengekspor model yang tepat.
- Coba prediksi pengujian dengan perintah
gcloud ai-platform local predict. - Ekspor model Anda lagi dan coba lagi.
Error pemformatan untuk permintaan prediksi
Semua pesan ini berkaitan dengan input prediksi Anda.
- "JSON kosong atau salah format/tidak valid dalam isi permintaan"
- Layanan tidak dapat mengurai JSON dalam permintaan Anda atau permintaan Anda kosong. Periksa pesan Anda untuk menemukan error atau kelalaian yang membatalkan JSON.
- "Kolom 'instance' tidak ada dalam isi permintaan"
- Isi permintaan Anda tidak mengikuti format yang benar. Ini harus berupa objek JSON dengan satu kunci bernama
"instances"yang berisi daftar dengan semua instance input Anda. - Error encoding JSON saat membuat permintaan
Permintaan Anda menyertakan data yang dienkode base64, tetapi tidak dalam format JSON yang tepat. Setiap string yang dienkode base64 harus direpresentasikan oleh objek dengan satu kunci bernama
"b64". Contoh:{"b64": "an_encoded_string"}Error base64 lainnya terjadi saat Anda memiliki data biner yang tidak dienkode base64. Enkode data Anda dan format sebagai berikut:
{"b64": base64.b64encode(binary_data)}Lihat informasi selengkapnya tentang memformat dan mengenkode data biner.
Prediksi di cloud memerlukan waktu lebih lama daripada di desktop
Prediksi online dirancang untuk menjadi layanan skalabel yang dengan cepat menayangkan permintaan prediksi dengan rasio tinggi. Layanan dioptimalkan untuk performa gabungan di semua permintaan penayangan. Penekanan pada skalabilitas mengarah pada karakteristik performa yang berbeda dibandingkan dengan menghasilkan sejumlah kecil prediksi di mesin lokal Anda.
Langkah selanjutnya
- Dapatkan dukungan.
- Pelajari lebih lanjut model error Google API,
terutama kode error kanonis yang ditentukan dalam
google.rpc.Codedan detail error standar yang ditentukan dalam google/rpc/error_details.proto. - Pelajari cara memantau tugas pelatihan.
- Lihat FAQ dan pemecahan masalah Cloud TPU untuk mendapatkan bantuan dalam mendiagnosis dan memecahkan masalah saat menjalankan AI Platform Training dengan Cloud TPU.