Plate-forme Vertex AI
Innovez plus rapidement grâce à une IA adaptée aux entreprises, optimisée par les modèles Gemini.
Vertex AI est une plate-forme de développement d'IA unifiée et entièrement gérée qui permet de créer et d'utiliser l'IA générative. Accédez à Vertex AI Studio, à Agent Builder et à plus de 200 modèles de fondation, et utilisez-les.
Les nouveaux clients bénéficient d'un maximum de 300 $ de crédits pour essayer Vertex AI et d'autres produits Google Cloud.
Fonctionnalités
Gemini, le modèle multimodal le plus performant de Google
Vertex AI permet d'accéder aux derniers modèles Gemini de Google, y compris Gemini 3. Gemini est capable de comprendre pratiquement n'importe quelle entrée, de combiner différents types d'informations et de générer presque n'importe quel résultat. Envoyez des requêtes et faites des tests dans Vertex AI Studio à l'aide de texte, d'images, de vidéos ou de code. Grâce aux raisonnements avancés et aux fonctionnalités de génération de pointe de Gemini, les développeurs peuvent essayer des exemples de requêtes pour extraire du texte à partir d'images, convertir le texte des images au format JSON, et même générer des réponses sur les images importées pour créer des applications d'IA de nouvelle génération.

Plus de 200 modèles et outils d'IA générative
Faites votre choix parmi la plus grande variété de modèles avec des modèles propriétaires (Gemini, Imagen, Chirp, Veo), tiers (famille de modèles Claude d'Anthropic) et ouverts (Gemma, Llama 3.2) dans Model Garden. Utilisez des extensions pour permettre aux modèles de récupérer des informations en temps réel et de déclencher des actions. Vous pouvez également personnaliser les modèles en fonction de votre cas d'utilisation grâce à différentes options de réglage.
Notre service Gen AI Evaluation Service fournit des outils pensés pour les entreprises afin d'évaluer les modèles d'IA générative de manière objective et en s'appuyant sur les données.
Plate-forme d'IA ouverte et intégrée
Les data scientists peuvent évoluer plus rapidement grâce aux outils Vertex AI Platform dédiés à l'entraînement, au réglage et au déploiement de modèles de ML.
Les notebooks Vertex AI, y compris Colab Enterprise ou Workbench de votre choix, sont intégrés de façon native à BigQuery et offrent une surface unique pour toutes les charges de travail de données et d'IA.
Vertex AI Training et Prediction vous permettent de réduire la durée d'entraînement et de déployer facilement des modèles en production grâce aux frameworks Open Source de votre choix et à une infrastructure d'IA optimisée.
MLOps pour l'IA prédictive et générative
Vertex AI Platform fournit des outils MLOps conçus sur mesure pour que les data scientists et les ingénieurs en ML puissent automatiser, standardiser et gérer les projets de ML.
Les outils modulaires vous aident à collaborer entre les équipes et à améliorer les modèles tout au long du cycle de développement : identifier le meilleur modèle pour un cas d'utilisation avec Vertex AI Evaluation, orchestrer les workflows avec Vertex AI Pipelines, gérer n'importe quel modèle avec Model Registry, diffuser, partager et réutiliser des caractéristiques de ML avec Feature Store et surveiller les modèles pour détecter les décalages et dérives d'entrée.
Créer, faire évoluer et gérer des agents de niveau professionnel
Vertex AI Agent Builder est notre plate-forme ouverte et complète qui permet aux entreprises de créer, de faire évoluer et de gérer rapidement des agents professionnels ancrés dans leurs données. Elle fournit la base full stack et la flexibilité de développement nécessaires pour transformer vos applications et vos workflows en systèmes agentifs puissants et fiables à l'échelle mondiale.
Fonctionnement
Vertex AI propose plusieurs options pour entraîner et déployer des modèles :
- L'IA générative vous donne accès à de grands modèles d'IA générative comme Gemini 3. Vous pouvez ainsi les évaluer, les ajuster et les déployer pour les utiliser dans vos applications optimisées par l'IA.
- Model Garden vous permet de découvrir, de tester, de personnaliser et de déployer Vertex AI, et de sélectionner des modèles et des éléments Open Source (OSS).
- L'entraînement personnalisé vous offre un contrôle total sur le processus d'entraînement, y compris l'utilisation de votre framework de ML préféré, l'écriture de votre propre code d'entraînement et le choix des options de réglage des hyperparamètres.
Vertex AI propose plusieurs options pour entraîner et déployer des modèles :
- L'IA générative vous donne accès à de grands modèles d'IA générative comme Gemini 3. Vous pouvez ainsi les évaluer, les ajuster et les déployer pour les utiliser dans vos applications optimisées par l'IA.
- Model Garden vous permet de découvrir, de tester, de personnaliser et de déployer Vertex AI, et de sélectionner des modèles et des éléments Open Source (OSS).
- L'entraînement personnalisé vous offre un contrôle total sur le processus d'entraînement, y compris l'utilisation de votre framework de ML préféré, l'écriture de votre propre code d'entraînement et le choix des options de réglage des hyperparamètres.
Utilisations courantes
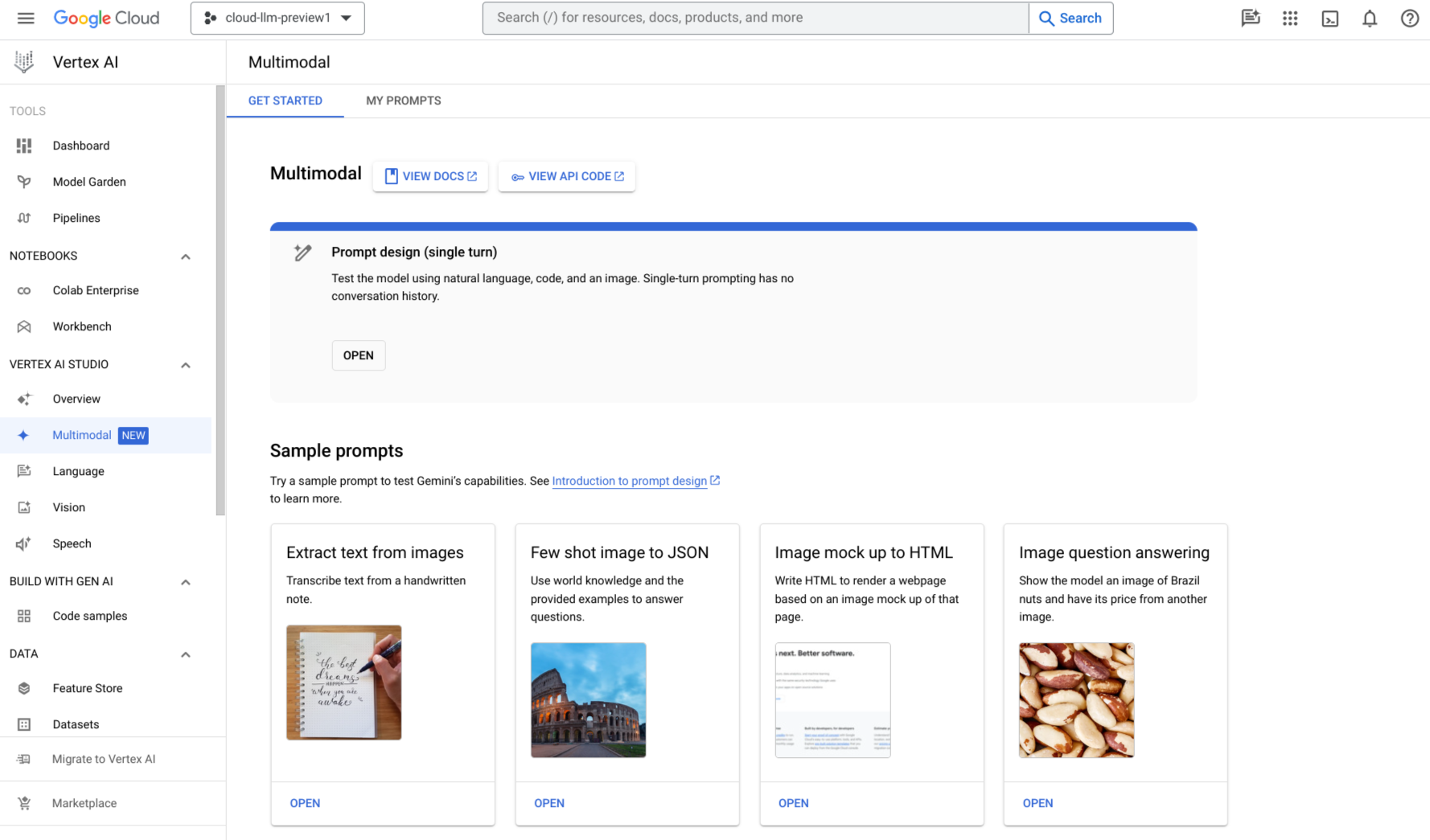
Créer avec les modèle Gemini
Premiers pas avec les modèles multimodaux de Google
Premiers pas avec les modèles multimodaux de Google
Utilisez Vertex AI Studio pour concevoir, tester et gérer des prompts pour les modèles Gemini à l'aide du langage naturel, de code, d'images ou de vidéos. Essayez des exemples de prompts pour extraire du texte à partir d'images ou des maquettes d'images au format HTML. Vous pouvez même générer des réponses concernant les images ou les vidéos importées.
Vous pouvez également commencer à tester Gemini sur Vertex AI avec une clé API.
Accédez aux modèles Gemini via l'API Gemini dans Google Cloud Vertex AI
- Python
- JavaScript
- Java
- Accéder
- Curl
Tutoriels, guides de démarrage rapide et ateliers
Premiers pas avec les modèles multimodaux de Google
Premiers pas avec les modèles multimodaux de Google
Utilisez Vertex AI Studio pour concevoir, tester et gérer des prompts pour les modèles Gemini à l'aide du langage naturel, de code, d'images ou de vidéos. Essayez des exemples de prompts pour extraire du texte à partir d'images ou des maquettes d'images au format HTML. Vous pouvez même générer des réponses concernant les images ou les vidéos importées.
Vous pouvez également commencer à tester Gemini sur Vertex AI avec une clé API.
Exemple de code
Accédez aux modèles Gemini via l'API Gemini dans Google Cloud Vertex AI
- Python
- JavaScript
- Java
- Accéder
- Curl
Agents et applications d'IA
Exploiter des fonctionnalités d'IA avancées avec Vertex AI
Exploiter des fonctionnalités d'IA avancées avec Vertex AI
Créez des agents et des applications d'IA générative prêts pour la production sur une plate-forme qui évolue selon vos besoins. Notre plate-forme de développement d'IA, Vertex AI, fournit un environnement sécurisé pour développer et déployer des modèles et des applications d'IA.
Pour les développeurs, Vertex AI reste notre plate-forme avancée qui permet de créer, de personnaliser et d'affiner des agents sophistiqués à l'aide de frameworks tels que Agent Development Kit (ADK).
Lancez-vous avec cet atelier de programmation et créez votre première application d'IA dès aujourd'hui
Tutoriels, guides de démarrage rapide et ateliers
Exploiter des fonctionnalités d'IA avancées avec Vertex AI
Exploiter des fonctionnalités d'IA avancées avec Vertex AI
Créez des agents et des applications d'IA générative prêts pour la production sur une plate-forme qui évolue selon vos besoins. Notre plate-forme de développement d'IA, Vertex AI, fournit un environnement sécurisé pour développer et déployer des modèles et des applications d'IA.
Pour les développeurs, Vertex AI reste notre plate-forme avancée qui permet de créer, de personnaliser et d'affiner des agents sophistiqués à l'aide de frameworks tels que Agent Development Kit (ADK).
Lancez-vous avec cet atelier de programmation et créez votre première application d'IA dès aujourd'hui
Extraire, synthétiser et classer les données
Utiliser l'IA générative pour la synthèse, la classification et l'extraction
Utiliser l'IA générative pour la synthèse, la classification et l'extraction
Découvrez comment créer des requêtes textuelles pour gérer un nombre illimité de tâches grâce à la compatibilité de Vertex AI avec l'IA générative. Certaines des tâches les plus courantes sont la classification, la synthèse et l'extraction. Gemini sur Vertex AI vous permet de concevoir des prompts avec flexibilité en termes de structure et de format.
Tutoriels, guides de démarrage rapide et ateliers
Utiliser l'IA générative pour la synthèse, la classification et l'extraction
Utiliser l'IA générative pour la synthèse, la classification et l'extraction
Découvrez comment créer des requêtes textuelles pour gérer un nombre illimité de tâches grâce à la compatibilité de Vertex AI avec l'IA générative. Certaines des tâches les plus courantes sont la classification, la synthèse et l'extraction. Gemini sur Vertex AI vous permet de concevoir des prompts avec flexibilité en termes de structure et de format.
Entraînez des modèles de ML personnalisés
Présentation et documentation de l'entraînement ML personnalisé
Présentation et documentation de l'entraînement ML personnalisé
Découvrez le workflow d'entraînement personnalisé dans Vertex AI, les avantages de l'entraînement personnalisé et les différentes options d'entraînement disponibles. Cette page détaille également chaque étape du workflow d'entraînement de ML, de la préparation des données aux prédictions.
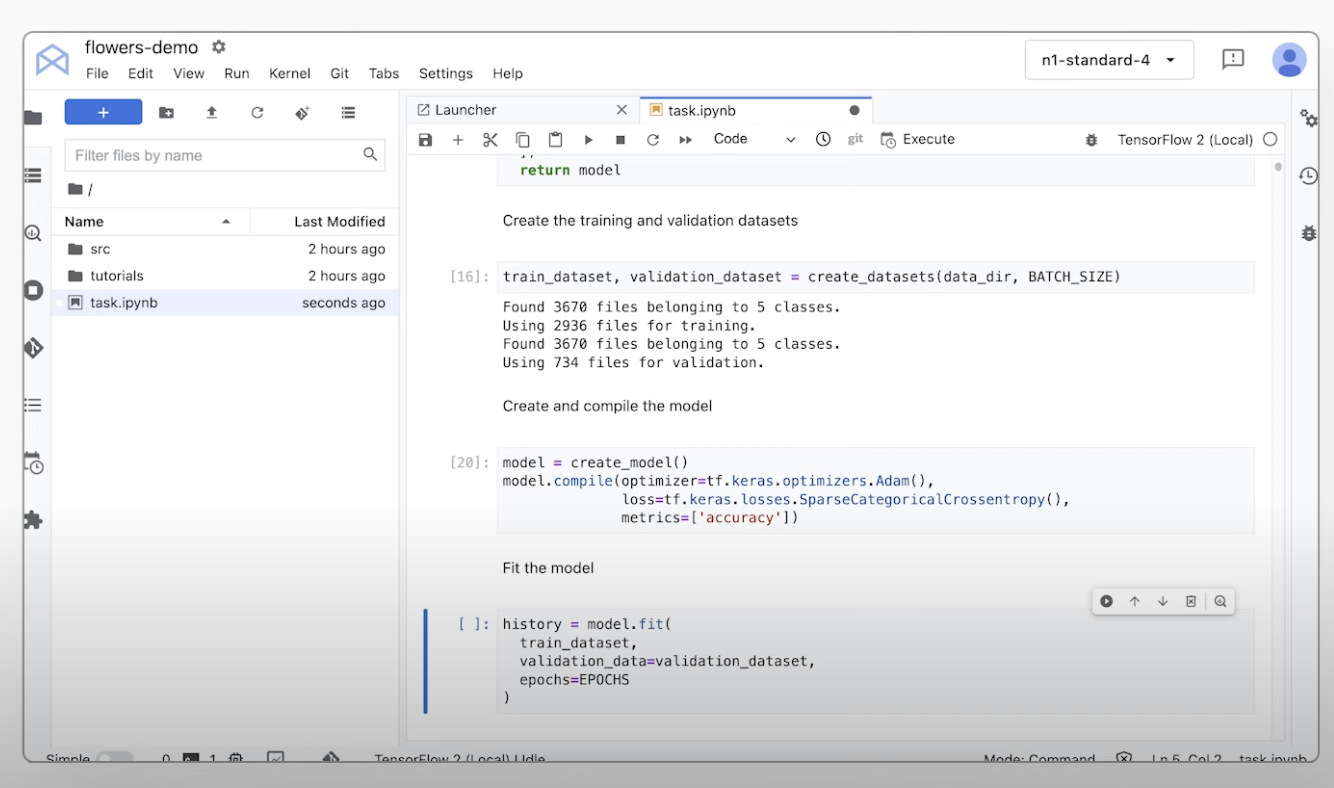
Regardez un tutoriel vidéo sur la procédure à suivre pour entraîner des modèles personnalisés sur Vertex AI.
Tutoriels, guides de démarrage rapide et ateliers
Présentation et documentation de l'entraînement ML personnalisé
Présentation et documentation de l'entraînement ML personnalisé
Découvrez le workflow d'entraînement personnalisé dans Vertex AI, les avantages de l'entraînement personnalisé et les différentes options d'entraînement disponibles. Cette page détaille également chaque étape du workflow d'entraînement de ML, de la préparation des données aux prédictions.
Regardez un tutoriel vidéo sur la procédure à suivre pour entraîner des modèles personnalisés sur Vertex AI.
Déployer un modèle pour une utilisation en production
Effectuer des déploiements pour les prédictions par lot ou en ligne
Effectuer des déploiements pour les prédictions par lot ou en ligne
Lorsque vous êtes prêt à utiliser votre modèle pour résoudre un problème concret, enregistrez-le dans Vertex AI Model Registry et utilisez le service de prédiction Vertex AI pour effectuer des prédictions par lot et en ligne.
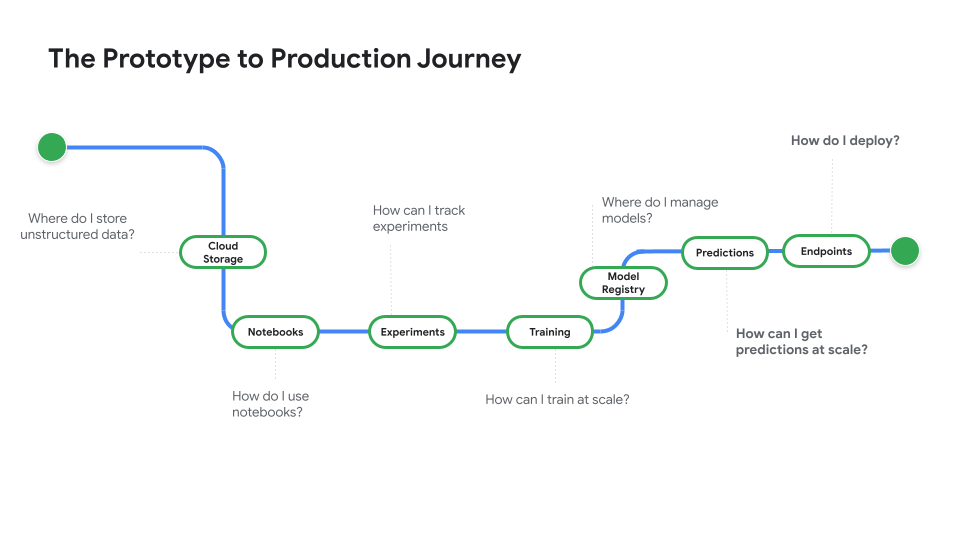
Regardez Du prototype à la production, une série de vidéos qui vous fait passer du code du notebook au modèle déployé.
Tutoriels, guides de démarrage rapide et ateliers
Effectuer des déploiements pour les prédictions par lot ou en ligne
Effectuer des déploiements pour les prédictions par lot ou en ligne
Lorsque vous êtes prêt à utiliser votre modèle pour résoudre un problème concret, enregistrez-le dans Vertex AI Model Registry et utilisez le service de prédiction Vertex AI pour effectuer des prédictions par lot et en ligne.
Regardez Du prototype à la production, une série de vidéos qui vous fait passer du code du notebook au modèle déployé.
Tarification
| Fonctionnement des tarifs de Vertex AI | Payez les outils Vertex AI ainsi que les ressources de stockage, de calcul et cloud que vous utilisez. Les nouveaux clients bénéficient de 300 $ de crédits pour essayer Vertex AI et d'autres produits Google Cloud. | |
|---|---|---|
| Outils et utilisation | Description | Prix |
IA générative | Modèle Imagen pour la génération d'images Basé sur la saisie d'image ou de caractères, ou sur la tarification d'un entraînement personnalisé. | À partir de 0,0001 $ |
Génération de texte, de chat et de code Tous les 1 000 caractères d'entrée (requête) et tous les 1 000 caractères de sortie (réponse). | À partir de 0,0001 $ pour 1 000 caractères | |
Modèles entraînés personnalisés | Entraînement de modèle personnalisé En fonction du type de machine utilisé par heure, la région et des accélérateurs utilisés. Obtenez une estimation via le service commercial ou notre simulateur de coût. | Contacter le service commercial |
Notebooks Vertex AI | Ressources de calcul et de stockage Basés sur les mêmes tarifs que Compute Engine et Cloud Storage. | Consulter les produits |
Frais de gestion Outre l'utilisation des ressources ci-dessus, des frais de gestion s'appliquent en fonction de la région, des instances, des notebooks et des notebooks gérés utilisés. Voir les détails | Voir les détails | |
Vertex AI Pipelines | Frais d'exécution et frais supplémentaires En fonction des tarifs d'exécution, des ressources utilisées et des éventuels frais de service supplémentaires. | À partir de 0,03 $ par exécution de pipeline |
Vertex AI Vector Search | Coûts de diffusion et de compilation En fonction de la taille de vos données, du nombre de requêtes par seconde (RPS) que vous souhaitez exécuter et du nombre de nœuds que vous utilisez. Voir un exemple | Consulter un exemple |
Consultez le détail des tarifs de l'ensemble des fonctionnalités et services Vertex AI.
Fonctionnement des tarifs de Vertex AI
Payez les outils Vertex AI ainsi que les ressources de stockage, de calcul et cloud que vous utilisez. Les nouveaux clients bénéficient de 300 $ de crédits pour essayer Vertex AI et d'autres produits Google Cloud.
IA générative
Modèle Imagen pour la génération d'images
Basé sur la saisie d'image ou de caractères, ou sur la tarification d'un entraînement personnalisé.
Starting at
0,0001 $
Génération de texte, de chat et de code
Tous les 1 000 caractères d'entrée (requête) et tous les 1 000 caractères de sortie (réponse).
Starting at
0,0001 $
pour 1 000 caractères
Modèles entraînés personnalisés
Entraînement de modèle personnalisé
En fonction du type de machine utilisé par heure, la région et des accélérateurs utilisés. Obtenez une estimation via le service commercial ou notre simulateur de coût.
Contacter le service commercial
Notebooks Vertex AI
Ressources de calcul et de stockage
Basés sur les mêmes tarifs que Compute Engine et Cloud Storage.
Consulter les produits
Frais de gestion
Outre l'utilisation des ressources ci-dessus, des frais de gestion s'appliquent en fonction de la région, des instances, des notebooks et des notebooks gérés utilisés. Voir les détails
Voir les détails
Vertex AI Pipelines
Frais d'exécution et frais supplémentaires
En fonction des tarifs d'exécution, des ressources utilisées et des éventuels frais de service supplémentaires.
Starting at
0,03 $
par exécution de pipeline
Vertex AI Vector Search
Coûts de diffusion et de compilation
En fonction de la taille de vos données, du nombre de requêtes par seconde (RPS) que vous souhaitez exécuter et du nombre de nœuds que vous utilisez. Voir un exemple
Consulter un exemple
Consultez le détail des tarifs de l'ensemble des fonctionnalités et services Vertex AI.
Commencer votre démonstration de faisabilité
Cas d'utilisation métier
Exploitez tout le potentiel de l'IA générative

"La précision de la solution d'IA générative de Google Cloud et l'aspect pratique de Vertex AI Platform nous donnent la confiance dont nous avions besoin pour mettre en œuvre cette technologie de pointe au cœur de nos activités et atteindre notre objectif à long terme : un temps de réponse de zéro minute."
Abdol Moabery, CEO de GA Telesis
Contenu associé
Rapports d'analystes
Google figure parmi les leaders du marché dans le rapport IDC MarketScape sur les logiciels de modèles de fondation pour le cycle de vie de l’IA générative à l’échelle mondiale de 2025. Télécharger le rapport
Google figure parmi les leaders du marché dans le rapport The Forrester Wave™ sur les modèles de fondation d'IA pour le langage au 2e trimestre 2024 Lire le rapport
Google figure parmi les leaders du marché dans le rapport "The Forrester Wave™: AI/ML Platforms" (Plates-formes d'IA/de ML) du 3e trimestre 2024. Lire le rapport











