This article is the third part of a four-part series that discusses how you can predict customer lifetime value (CLV) by using AI Platform (AI Platform) on Google Cloud.
The articles in this series include the following:
- Part 1: Introduction. Introduces CLV and two modeling techniques for predicting CLV.
- Part 2: Training the model. Discusses how to prepare the data and train the models.
- Part 3: Deploying to production (this article). Describes how to deploy the models discussed in Part 2 to a production system.
- Part 4: Using AutoML Tables. Shows how to use AutoML Tables to build and deploy a model.
Installing the code
If you want to follow the process described in this article, you should install the sample code from GitHub.
If you have the gcloud CLI installed, open a terminal window on your computer to run these commands. If you don't have the gcloud CLI installed, open an instance of Cloud Shell.
Clone the sample code repository:
git clone https://github.com/GoogleCloudPlatform/tensorflow-lifetime-value
Follow the installation instructions in the Install and Automation sections of the README file to set up your environment and deploy the solution components. This includes the example dataset and the Cloud Composer environment.
The command examples in the following sections assume you've completed both of these steps.
As part of the installation instructions, you set up variables for your environment as described in the setup section of the README file.
Change the REGION variable to correspond to the Google Cloud region
that's geographically closest to you. For a list of regions, see
Regions and Zones.
Architecture and implementation
The following diagram shows the architecture used in this discussion.

The architecture is split into the following functions:
- Data ingestion: The data is imported into BigQuery.
- Data preparation: The raw data is transformed to become usable by the models.
- Model training: Models are built, trained, and tuned so they can be used to run predictions.
- Prediction serving: Offline predictions are stored and made available at low latency.
- Automation: All of these tasks are executed and managed through Cloud Composer.
Ingesting data
This article series does not discuss a specific way to perform data ingestion. There are many ways for BigQuery to ingest data, including from Pub/Sub, from Cloud Storage, and from BigQuery Data Transfer Service. For more information, see BigQuery for Data Warehouse Practitioners. In the approach described in this series, we use a public dataset. You import this dataset into BigQuery, as described in the sample code in the README file.
Preparing data
To prepare data, you execute queries on BigQuery like the ones shown in Part 2 of this series. In a production architecture, you execute the queries as part of an Apache Airflow directed acyclic graph (DAG). The section on automation later in this document provides more detail about executing queries for data preparation.
Training the model on AI Platform
This section provides an overview of the training part of the architecture.
No matter what type of model you choose, the code shown in this solution is packaged to run on AI Platform (AI Platform), both for training and prediction. AI Platform offers the following benefits:
- You can run it locally or in the cloud in a distributed environment.
- It offers built-in connectivity to other Google products, such as Cloud Storage.
- You can run it by using just a few commands.
- It facilitates hyperparameter tuning.
- It scales with minimum infrastructure changes, if any.
For AI Platform to be able to train and evaluate a model, you need to provide training, evaluation, and test datasets. You create the datasets by running SQL queries like those shown in Part 2 of this series. You then export those datasets from BigQuery tables to Cloud Storage. In the production architecture described in this article, the queries are executed by an Airflow DAG, which is described in more detail in the Automation section below. You can execute the DAG manually as described in the Run DAGs section of the README file.
Serving predictions
Predictions can be created online or offline. But creating predictions is different than serving them. In this CLV context, events such as a customer logging into a website or visiting a retail store are not drastically going to affect that customer's lifetime value. Therefore, predictions can be done offline, even if the results might have to be presented in real time. Offline prediction has the following operational features:
- You can perform the same preprocessing steps for both training and prediction. If training and predicting are preprocessed differently, your predictions might be less accurate. This phenomenon is called training-serving skew.
- You can use the same tools to prepare the data for training and prediction. The approach discussed in this series mainly employs BigQuery to prepare data.
You can use AI Platform to deploy the model and make offline predictions by using a batch job. For prediction, AI Platform facilitates tasks like the following:
- Managing versions.
- Scaling with minimum infrastructure changes.
- Deploying at scale.
- Interacting with other Google Cloud products.
- Providing an SLA.
The batch prediction task uses files that are stored on Cloud Storage
for both input and output. For the DNN model, the following serving function,
defined in task.py, defines the format of the inputs:
The prediction output format is defined in an EstimatorSpec returned by
the Estimator model function in this code from model.py:
Using the predictions
After you've finished creating the models and deploying them, you can use them to perform CLV predictions. The following are common CLV use cases:
- A data specialist can leverage offline predictions when building user segments.
- Your organization can make specific offers in real time, when a customer interacts with your brand online or in a shop.
Analytics with BigQuery
Understanding CLV is key to activations. This article focuses mostly on calculating lifetime value based on previous sales. Sales data usually comes from customer relationship management (CRM) tools, but information about user behavior can have other sources, such as Google Analytics 360.
You should use BigQuery if you are interested in doing any of the following tasks:
- Storing structured data from many sources.
- Automatically transferring data from common SaaS tools such as Google Analytics 360, YouTube, or AdWords.
- Running ad hoc queries, including joins on terabytes of customer data.
- Visualizing your data by using leading business intelligence tools.
In addition to its role as a managed storage and query engine, BigQuery can run machine learning algorithms directly by using BigQuery ML. By loading the CLV value of each customer into BigQuery, you allow data analysts, scientists, and engineers to leverage extra metrics in their tasks. The Airflow DAG discussed in the next section includes a task to load the CLV predictions into BigQuery.
Low-latency serving using Datastore
Predictions made offline can often be reused to provide predictions in real time. For this scenario, prediction freshness is not critical, but getting access to the data at the right time and expediently is.
Storing offline prediction for real-time serving means that the actions that a customer takes won't change their CLV right away. However, getting access to that CLV quickly is important. For example, your company might want to react quickly when a customer uses your website, asks your helpdesk a question, or checks out through your point of sale. In cases like these, a rapid response can improve your customer relationship. Therefore, storing your prediction output in a fast database and making secure queries available to your frontend are keys to success.
Let's assume that you have hundreds of thousands of unique customers. Datastore is a good option for the following reasons:
- It supports NoSQL document databases.
- It provides quick access to data by using a key (customer ID), but also enables SQL queries.
- It's accessible through a REST API.
- It's ready to use, which means that there's no setup overhead.
- It scales automatically.
Because there is no way to directly load a CSV dataset to Datastore, in this solution we use Apache Beam on Dialogflow with a JavaScript template to load the CLV predictions into Datastore. The following code snippet from the JavaScript template shows how:
When your data is in Datastore, you can choose how you want to interact with it, which can include:
- Using the Datastore Client Libraries from your app.
- Building an API endpoint by using Cloud Endpoints or Apigee API Platform.
- Using Cloud Run functions for serverless tasks.
Automating the solution
You use the steps described so far when you're getting started with the data in order to run the first preprocessing, training, and prediction steps. But your platform is not ready for production yet, because you still need automation and failure management.
Some scripting can help glue the steps together. However, it's a best practice to automate the steps by using a workflow manager. Apache Airflow is a popular workflow management tool, and you can use Cloud Composer to run a managed Airflow pipeline on Google Cloud.
Airflow works with directed acyclic graphs (DAGs), which allow you to specify each task and how it relates to other tasks. In the approach described in this series, you run the following steps:
- Create BigQuery data sets.
- Load the public dataset from Cloud Storage to BigQuery.
- Clean the data from a BigQuery table and write it to a new BigQuery table.
- Create features based on data in one BigQuery table and write them to another BigQuery table.
- If the model is a deep neural network (DNN), split the data into a training set and evaluation set within BigQuery.
- Export the datasets to Cloud Storage and make them available to AI Platform.
- Have AI Platform periodically train the model.
- Deploy the updated model to AI Platform.
- Periodically run a batch prediction on new data.
- Save the predictions that are already saved in Cloud Storage to Datastore and BigQuery.
Setting up Cloud Composer
For information about how to set up Cloud Composer, see the instructions in the GitHub repository README file.
Directed acyclic graphs for this solution
This solution uses two DAGs. The first DAG covers steps 1 through 8 of the sequence listed earlier:
The following diagram shows the Cloud Composer/Airflow UI, which summarizes steps 1 to 8 of the Airflow DAG steps.
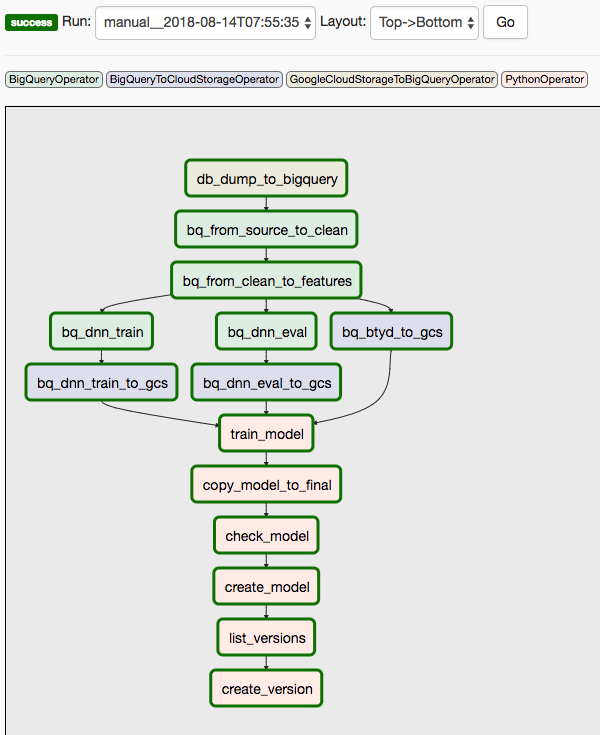
The second DAG covers steps 9 and 10.
The following diagram summarizes steps 9 and 10 of the Airflow DAG process.
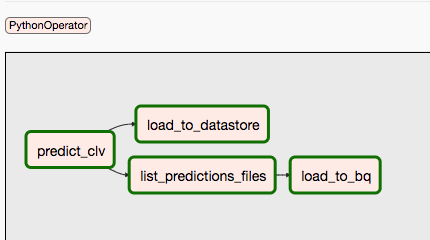
The DAGs are separated because predictions and training might happen independently and on a different schedule. For example, you might do the following:
- Predict data for new or existing customers daily.
- Retrain the model weekly to incorporate new data, or trigger it after a specific number of new transactions are received.
To trigger the first DAG manually, you can run the command from the Run Dags section of the README file in Cloud Shell or by using the gcloud CLI.
The conf parameter passes variables to different parts of the automation. For
example, in the following SQL query used to extract features from the cleaned
data, the variables are used to parameterize the FROM clause:
You can trigger the second DAG by using a similar command. For more details, see the README file in the GitHub repository.
What's next
- Run the full example in the GitHub repository.
- Incorporate new features into the CLV model by using some of the following:
- Clickstream data, which can help you predict CLV for customers for whom you have no historical data.
- Product departments and categories that can add some extra context and that might help the neural network.
- New features that you create by using the same inputs that are used in this solution. Examples could be sales trends for the final weeks or months before the threshold date.
- Read Part 4: Use AutoML Tables for the model.
- Learn about other predictive forecasting solutions.
- Explore reference architectures, diagrams, and best practices about Google Cloud. Take a look at our Cloud Architecture Center.