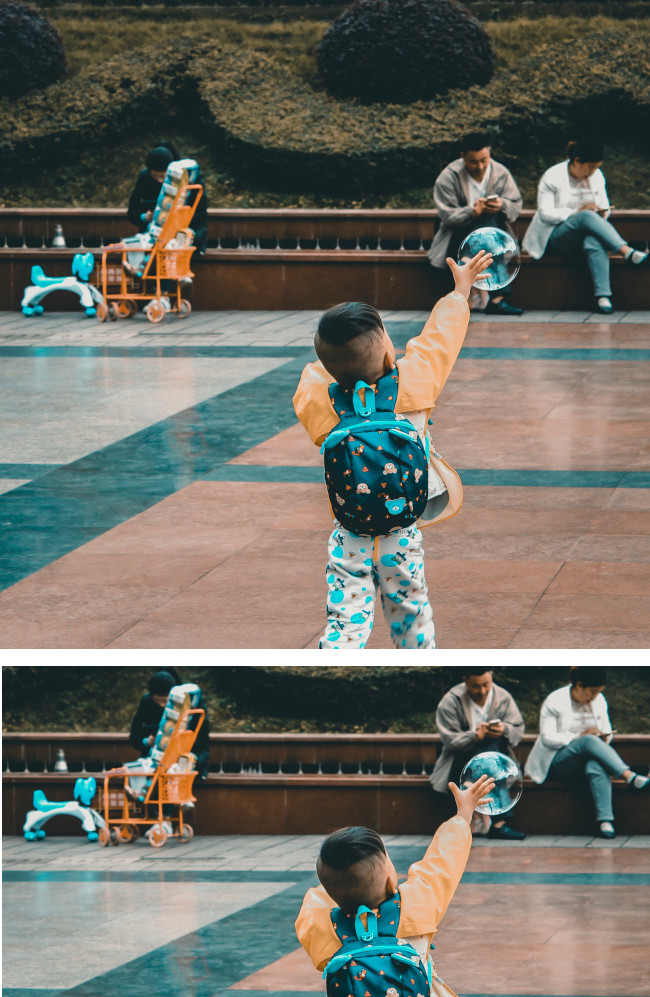Riconoscimento ottico dei caratteri (OCR) per un'immagine; riconoscimento del testo e
conversione in testo codificato automaticamente. Identifica ed estrae il testo UTF-8 in un'immagine.
Immagini: ottimizzate per aree di testo sparse all'interno di un'immagine più grande.
Risposta: restituisce sia un elenco di parole identificate con testo,
riquadri di selezione e textAnnotations, sia la gerarchia
strutturale per il testo rilevato
dall'OCR (fullTextAnnotation).
Riconoscimento ottico dei caratteri (OCR) per un file (PDF/TIFF) o un'immagine di testo ad alta densità; riconoscimento del testo ad alta densità e conversione in testo codificato automaticamente.
File: ottimizzato per i file di documenti (PDF/TIFF).
Immagini: ottimizzate per aree di testo dense in un'immagine
(immagini che sono documenti) e immagini che contengono scrittura a mano libera.
Risposta: restituisce la gerarchia strutturale per il testo rilevato
tramite OCR (fullTextAnnotation).
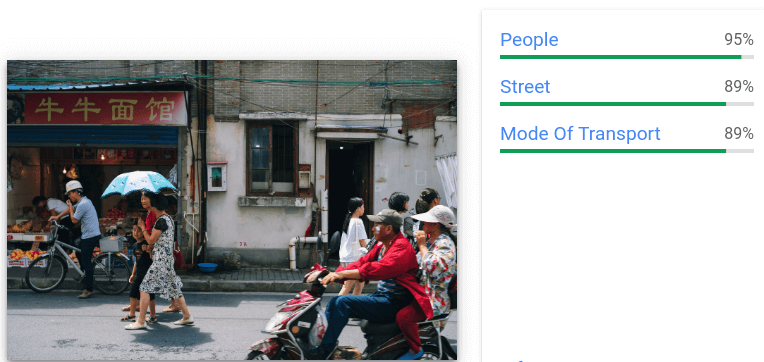
Fornisce annotazioni generali di etichette e riquadro di delimitazione per più oggetti
riconosciuti in una singola immagine.
Per ogni oggetto rilevato vengono restituiti i seguenti elementi: una descrizione
testuale, un punteggio di confidenza e vertici normalizzati [0,1] per
il poligono di delimitazione intorno all'oggetto.
Fornisce un poligono di delimitazione per l'immagine ritagliata, un punteggio di confidenza
e una frazione di importanza di questa regione saliente rispetto all'immagine originale per ogni richiesta.
Puoi fornire fino a 16 valori di proporzioni dell'immagine (larghezza:altezza)
per una singola immagine.
Fornisce una serie di contenuti web correlati a un'immagine.
Restituisce le seguenti informazioni:
Entità web: entità dedotte (etichette/descrizioni) da
immagini simili sul web.
Immagini con corrispondenza esatta: un elenco di URL per immagini con corrispondenza esatta
di qualsiasi dimensione su internet.
Immagini con corrispondenza parziale: un elenco di URL di immagini che
condividono caratteristiche dei punti chiave, ad esempio una versione ritagliata dell'immagine
originale.
Pagine con immagini corrispondenti: un elenco di pagine web (identificate da
URL pagina, titolo della pagina, URL immagine corrispondente) con un'immagine che soddisfa
le condizioni descritte sopra.
Immagini visivamente simili: un elenco di URL di immagini che condividono
alcune caratteristiche con l'immagine originale.
Etichetta della migliore ipotesi: la migliore ipotesi sull'argomento dell'immagine richiesta
dedotta da immagini simili su internet.
Individua i volti con poligoni di delimitazione e identifica punti di riferimento facciali specifici, come occhi, orecchie, naso, bocca e così via, insieme ai valori di confidenza corrispondenti.
Restituisce valutazioni della probabilità di reso per l'emozione
(gioia, tristezza, rabbia, sorpresa) e le proprietà generali dell'immagine
(sottoesposta, sfocata, presenza di copricapo).
Le valutazioni di probabilità sono espresse
come 6 valori diversi: UNKNOWN, VERY_UNLIKELY,
UNLIKELY, POSSIBLE, LIKELY o
VERY_LIKELY.
[[["Facile da capire","easyToUnderstand","thumb-up"],["Il problema è stato risolto","solvedMyProblem","thumb-up"],["Altra","otherUp","thumb-up"]],[["Difficile da capire","hardToUnderstand","thumb-down"],["Informazioni o codice di esempio errati","incorrectInformationOrSampleCode","thumb-down"],["Mancano le informazioni o gli esempi di cui ho bisogno","missingTheInformationSamplesINeed","thumb-down"],["Problema di traduzione","translationIssue","thumb-down"],["Altra","otherDown","thumb-down"]],["Ultimo aggiornamento 2025-09-16 UTC."],[],[],null,[]]