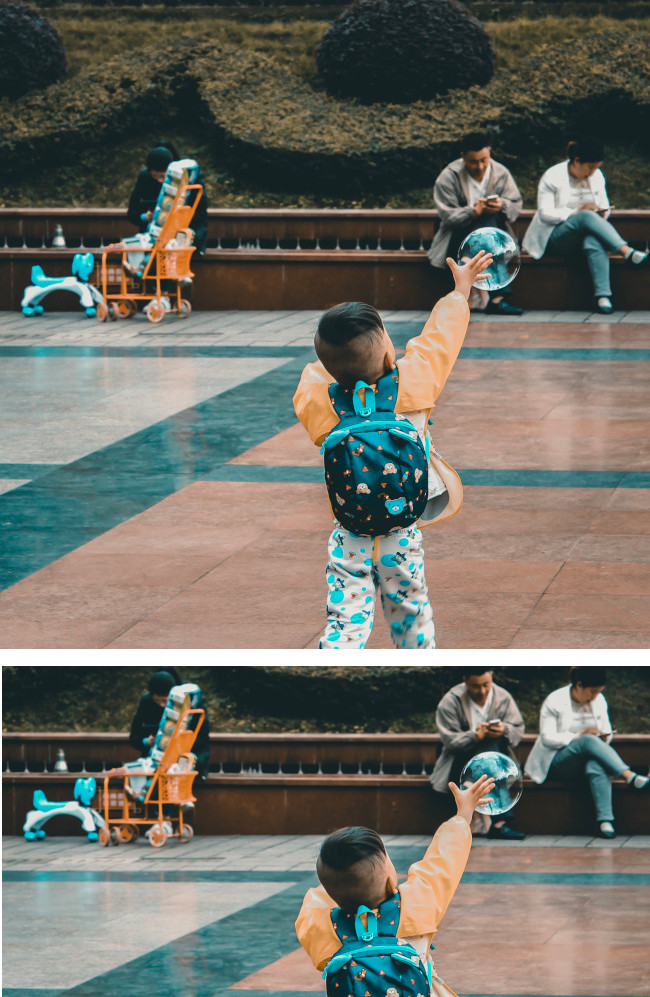Pengenalan karakter optik (OCR) untuk gambar; pengenalan teks dan
konversi menjadi teks berkode mesin. Mengidentifikasi dan mengekstrak teks UTF-8 dalam
gambar.
Gambar: Dioptimalkan untuk sparsearea teks dalam
gambar yang lebih besar.
Response: Menampilkan daftar kata yang diidentifikasi dengan teks,
kotak pembatas, dan textAnnotations, serta struktur
hierarki untuk teks yang terdeteksi
OCR (fullTextAnnotation).
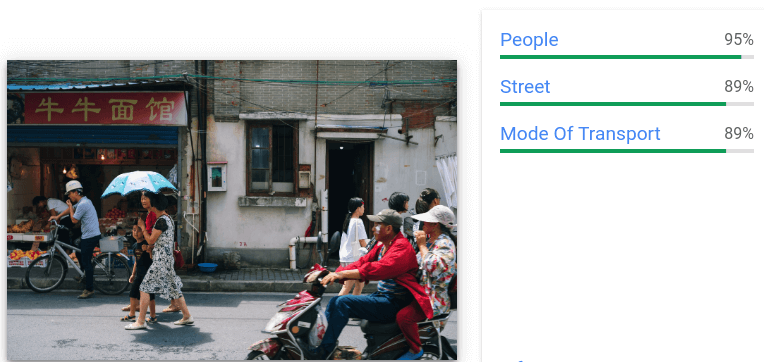
Memberikan anotasi kotak pembatas dan label umum untuk beberapa objek yang dikenali dalam satu gambar.
Untuk setiap objek yang terdeteksi, elemen berikut akan ditampilkan: deskripsi
tekstual, skor keyakinan, dan verteks yang dinormalisasi [0,1] untuk
poligon pembatas di sekitar objek.
Memberikan poligon pembatas untuk gambar yang dipangkas, skor keyakinan, dan fraksi kepentingan region penting ini dalam kaitannya dengan gambar asli untuk setiap permintaan.
Anda dapat memberikan hingga 16 nilai rasio gambar (lebar:tinggi)
untuk satu gambar.
Menyediakan serangkaian konten Web terkait untuk gambar.
Menampilkan informasi berikut:
Entitas web: Entitas (label/deskripsi) yang disimpulkan dari gambar serupa di Web.
Gambar yang cocok sepenuhnya: Daftar URL untuk gambar yang cocok sepenuhnya
dengan ukuran apa pun di Internet.
Gambar cocok yang sebagian: Daftar URL untuk gambar yang
memiliki fitur titik kunci yang sama, seperti versi gambar asli yang dipangkas.
Halaman dengan gambar yang cocok: Daftar Halaman web (diidentifikasi berdasarkan
URL halaman, judul halaman, URL gambar yang cocok) dengan gambar yang memenuhi
persyaratan yang dijelaskan di atas.
Gambar yang serupa secara visual: Daftar URL untuk gambar yang memiliki beberapa fitur dengan gambar asli.
Label perkiraan terbaik: Perkiraan terbaik terkait topik gambar yang diminta, yang disimpulkan dari gambar serupa di Internet.
Menemukan wajah dengan poligon pembatas,
dan mengidentifikasi "struktur" wajah tertentu seperti mata, telinga, hidung, mulut,
dll. beserta nilai keyakinan yang sesuai.
Menampilkan rating kemungkinan untuk emosi
(senang, sedih, marah, kaget) dan properti gambar umum
(kurang pencahayaan, buram, ada penutup kepala).
Rating biasanya dibedakan menjadi
6 nilai berbeda: UNKNOWN, VERY_UNLIKELY,
UNLIKELY, POSSIBLE, LIKELY, or
VERY_LIKELY.
[[["Mudah dipahami","easyToUnderstand","thumb-up"],["Memecahkan masalah saya","solvedMyProblem","thumb-up"],["Lainnya","otherUp","thumb-up"]],[["Sulit dipahami","hardToUnderstand","thumb-down"],["Informasi atau kode contoh salah","incorrectInformationOrSampleCode","thumb-down"],["Informasi/contoh yang saya butuhkan tidak ada","missingTheInformationSamplesINeed","thumb-down"],["Masalah terjemahan","translationIssue","thumb-down"],["Lainnya","otherDown","thumb-down"]],["Terakhir diperbarui pada 2025-09-22 UTC."],[],[],null,[]]