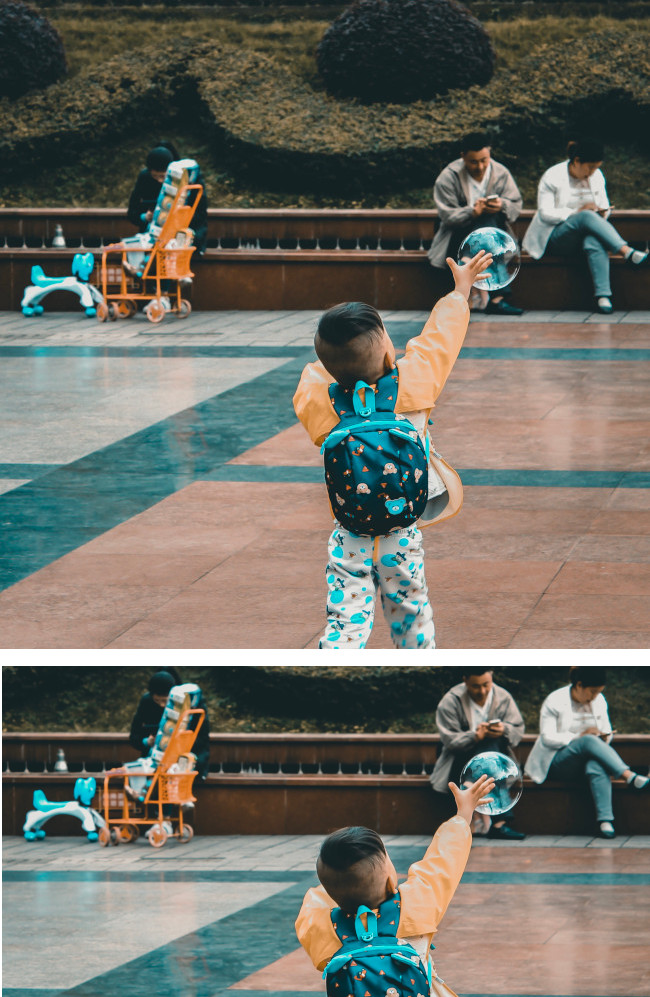Es wird die optische Zeichenerkennung (Optical Character Recognition, OCR) für ein Bild ausgeführt: Texterkennung und ‑konvertierung in maschinencodierten Text. Erkennt und extrahiert UTF-8-Text in einem Bild.
Bilder: Optimiert für kleine Textbereiche in einem größeren Bild.
Antwort: Es werden eine Liste der als Text identifizierten Wörter, die zugehörigen Begrenzungsrahmen und textAnnotations sowie die strukturelle Hierarchie für den von OCR erkannten Text (fullTextAnnotation) zurückgegeben.
Es wird die optische Zeichenerkennung (OCR) für eine Datei (PDF-/TIFF-Format) oder ein Bild mit viel Text durchgeführt: Erkennung des Textes und Konvertierung in maschinencodierten Text.
Dateien: Optimiert für Dokumentdateien (PDF/TIFF).
Bilder: Optimiert für dicht beschriebene Textbereiche in einem Bild (Bilder von Dokumenten) und Bilder, die Handschrift enthalten.
Antwort: Es wird die strukturelle Hierarchie für den per OCR erkannten Text zurückgegeben (fullTextAnnotation).
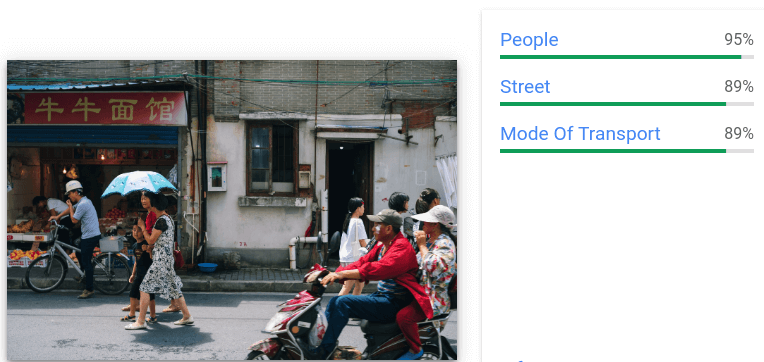
Es werden allgemeine Label- und Begrenzungsrahmen-Annotationen für mehrere Objekte bereitgestellt, die in einem einzelnen Bild erkannt wurden.
Für jedes erkannte Objekt werden die folgenden Elemente zurückgegeben: eine Textbeschreibung, ein Konfidenzwert und normalisierte Eckpunkte [0,1] für das Begrenzungspolygon um das Objekt.
Es wird für jede Anforderung ein Begrenzungspolygon für das zugeschnittene Bild, ein Konfidenzwert und ein Wichtigkeitsbruch für den jeweiligen auffälligen Bereich in Bezug auf das Originalbild bereitgestellt.
Sie können bis zu 16 Bildverhältniswerte (Breite:Höhe) für ein einzelnes Bild angeben.
Es wird eine Reihe ähnlicher Webinhalte für ein Bild bereitgestellt.
Es werden die folgenden Informationen zurückgegeben:
Webentitäten: Abgeleitete Entitäten (Labels/Beschreibungen) aus ähnlichen Bildern im Web.
Bilder mit vollständiger Übereinstimmung: Eine Liste von URLs für Internetbilder beliebiger Größe mit vollständiger Übereinstimmung.
Teilweise übereinstimmende Bilder: Eine Liste von URLs für Bilder, die identische Hauptmerkmale haben, zum Beispiel dass es sich um eine zugeschnittene Version des Originalbildes handelt.
Seiten mit übereinstimmenden Bildern: Eine Liste von Webseiten (durch Seiten-URL, Seitentitel und URL des übereinstimmenden Bildes identifiziert) mit einem Bild, das die oben beschriebenen Bedingungen erfüllt.
Optisch ähnliche Bilder: Eine Liste von URLs für Bilder, die einige Merkmale des Originalbildes haben.
Wahrscheinlichstes Label: Eine Schätzung des wahrscheinlichsten Themas des angeforderten Bildes, die aus ähnlichen Bildern im Internet abgeleitet wurde.
Es werden Wahrscheinlichkeitsbewertungen für die folgenden Kategorien anstößiger Inhalte bereitgestellt: adult, spoof, medical, violence und racy.
Die Wahrscheinlichkeitsbewertungen werden mit sechs verschiedenen Werten angegeben: UNKNOWN, VERY_UNLIKELY, UNLIKELY, POSSIBLE, LIKELY und VERY_LIKELY.
Gesichter werden mit Begrenzungspolygonen gekennzeichnet und es werden bestimmte Gesichtsmerkmale wie Augen, Ohren, Nase, Mund usw. zusammen mit den zugehörigen Konfidenzwerten erkannt.
Es werden Wahrscheinlichkeitsbewertungen für Gefühle (Freude, Trauer, Wut, Überraschung) und allgemeine Bildattribute (unterbelichtet, verschwommen, Kopfbedeckung vorhanden) zurückgegeben.
Die Wahrscheinlichkeitsbewertungen werden mit sechs verschiedenen Werten angegeben: UNKNOWN, VERY_UNLIKELY, UNLIKELY, POSSIBLE, LIKELY und VERY_LIKELY.
[[["Leicht verständlich","easyToUnderstand","thumb-up"],["Mein Problem wurde gelöst","solvedMyProblem","thumb-up"],["Sonstiges","otherUp","thumb-up"]],[["Schwer verständlich","hardToUnderstand","thumb-down"],["Informationen oder Beispielcode falsch","incorrectInformationOrSampleCode","thumb-down"],["Benötigte Informationen/Beispiele nicht gefunden","missingTheInformationSamplesINeed","thumb-down"],["Problem mit der Übersetzung","translationIssue","thumb-down"],["Sonstiges","otherDown","thumb-down"]],["Zuletzt aktualisiert: 2025-09-17 (UTC)."],[],[],null,[]]