Después de crear (entrenar) un modelo y de implementarlo, puedes realizar solicitudes de predicción en línea (o síncronas) en él.
Ejemplo de predicción en línea (individual)
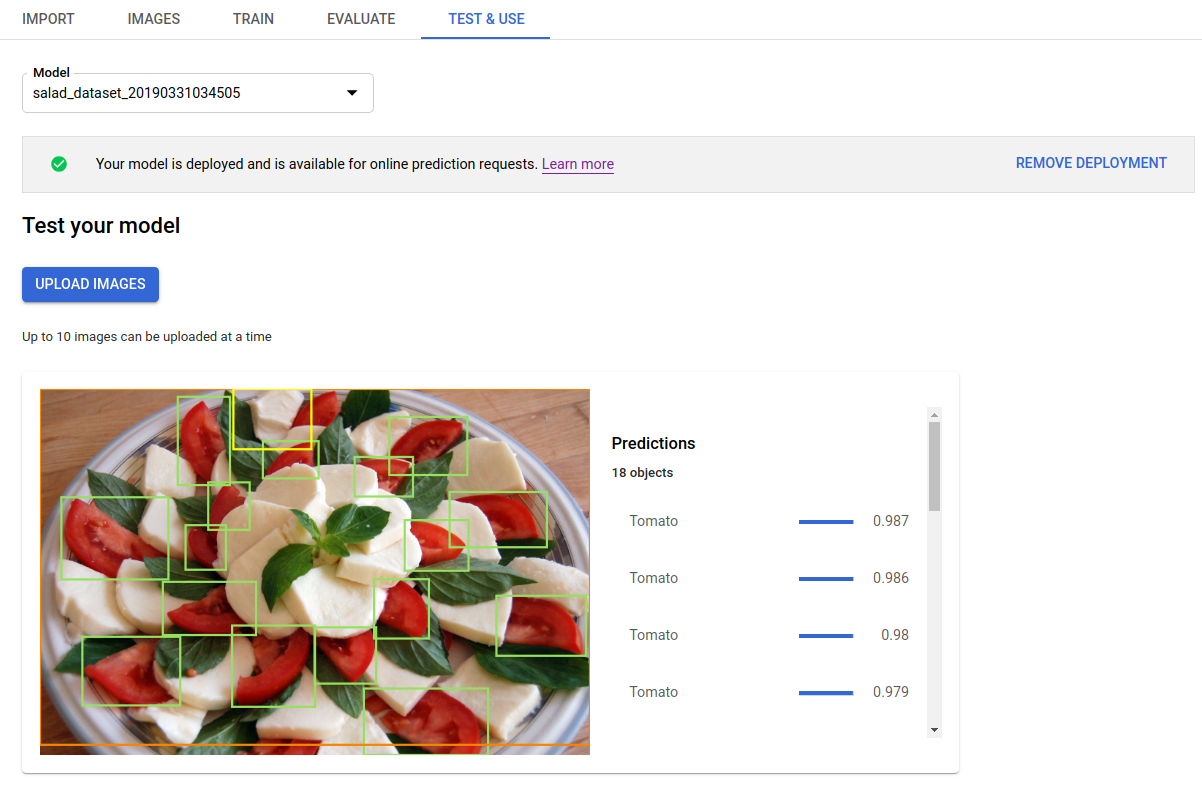
Después de implementar el modelo entrenado, puedes solicitar una predicción para una imagen con el método predict o usar la IU a fin de obtener anotaciones de predicción. El método predict aplica etiquetas a los cuadros de límite de objetos de la imagen.
Tu modelo generará cargos mientras esté implementado. Luego de hacer predicciones con tu modelo entrenado, puedes anular su implementación si ya no deseas que se generen cargos por el uso de hosting del modelo.
IU web
Abre la IU de la detección de objetos de Cloud AutoML Vision y haz clic en la pestaña Modelos (el ícono de la bombilla) en la barra de navegación izquierda para ver los modelos disponibles.
Para ver los de un proyecto diferente, selecciónalo de la lista desplegable en la parte superior derecha de la barra de título.
Haz clic en la fila del modelo que deseas usar para etiquetar tus imágenes.
Si el modelo aún no se implementó, haz clic en Implementar modelo para implementarlo ahora.
Se deben implementar los modelos para usar las predicciones en línea. La implementación de modelos genera costos. Para obtener más información, consulta la página Precios.
Haz clic en la pestaña Test & Use (Prueba y uso) que se encuentra debajo de la barra de título.
Haz clic en Subir imágenes (Upload images) para subir las imágenes que deseas etiquetar.
REST
Para probar la predicción, primero debes implementar tu modelo alojado en Cloud.
Antes de usar cualquiera de los datos de solicitud a continuación, realiza los siguientes reemplazos:
- project-id: El ID del proyecto de GCP.
- model-id: Es el ID del modelo, que se muestra en la respuesta que recibiste cuando lo creaste. El ID es el último elemento del nombre del modelo.
Por ejemplo:
- Nombre del modelo:
projects/project-id/locations/location-id/models/IOD4412217016962778756 - ID del modelo:
IOD4412217016962778756
- Nombre del modelo:
- base64-encoded-image: Es la representación en Base64 (string ASCII) de los datos de la imagen binaria. Esta string debería ser similar a la siguiente:
/9j/4QAYRXhpZgAA...9tAVx/zDQDlGxn//2Q==. Para obtener más información, consulta el tema Codifica en Base64.
Consideraciones específicas del campo:
scoreThreshold: Es un valor de 0 a 1. Solo se mostrarán los valores que tengan umbrales de puntuación de este valor como mínimo. El valor predeterminado es 0.5.maxBoundingBoxCount: Es el número más alto (límite superior) de cuadros de límite que se mostrarán en una respuesta. El valor predeterminado es 100 y el máximo es 500. Este valor está sujeto a restricciones de recursos y puede estar limitado por el servidor.
Método HTTP y URL:
POST https://automl.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/models/MODEL_ID:predict
Cuerpo JSON de la solicitud:
{
"payload": {
"image": {
"imageBytes": "BASE64_ENCODED_IMAGE"
}
},
"params": {
"scoreThreshold": "0.5",
"maxBoundingBoxCount": "100"
}
}
Para enviar tu solicitud, elige una de estas opciones:
curl
Guarda el cuerpo de la solicitud en un archivo llamado request.json y ejecuta el siguiente comando:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "x-goog-user-project: project-id" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://automl.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/models/MODEL_ID:predict"
PowerShell
Guarda el cuerpo de la solicitud en un archivo llamado request.json y ejecuta el siguiente comando:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred"; "x-goog-user-project" = "project-id" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://automl.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/models/MODEL_ID:predict" | Select-Object -Expand Content
El resultado se muestra en formato JSON. Las predicciones del modelo de detección de objetos de AutoML Vision se encuentran en el campo payload:
- El
boundingBoxde un objeto se especifica mediante vértices opuestos en diagonal. displayNamees la etiqueta del objeto que predijo el modelo de detección de objetos de AutoML Vision.scorerepresenta un nivel de confianza que la etiqueta especificada aplica a la imagen. Va de0(sin confianza) a1(confianza alta).
{
"payload": [
{
"imageObjectDetection": {
"boundingBox": {
"normalizedVertices": [
{
"x": 0.034553755,
"y": 0.015524037
},
{
"x": 0.941527,
"y": 0.9912563
}
]
},
"score": 0.9997793
},
"displayName": "Salad"
},
{
"imageObjectDetection": {
"boundingBox": {
"normalizedVertices": [
{
"x": 0.11737197,
"y": 0.7098793
},
{
"x": 0.510878,
"y": 0.87987
}
]
},
"score": 0.63219965
},
"displayName": "Tomato"
}
]
}
Go
Antes de probar esta muestra, sigue las instrucciones de configuración para este lenguaje en la página Bibliotecas cliente.
Java
Antes de probar esta muestra, sigue las instrucciones de configuración para este lenguaje en la página Bibliotecas cliente.
Node.js
Antes de probar esta muestra, sigue las instrucciones de configuración para este lenguaje en la página Bibliotecas cliente.
Python
Antes de probar esta muestra, sigue las instrucciones de configuración para este lenguaje en la página Bibliotecas cliente.
Idiomas adicionales
C#: sigue las instrucciones de configuración de C# en la página Bibliotecas cliente y, luego, visita la documentación de referencia de la detección de objetos de AutoML Vision para .NET.
PHP: sigue las instrucciones de configuración de PHP en la página Bibliotecas cliente y, luego, visita la documentación de referencia de detección de objetos de AutoML Vision para PHP.
Ruby: sigue las instrucciones de configuración de Ruby en la página Bibliotecas cliente y, luego, visita la documentación de referencia de detección de objetos de AutoML Vision para Ruby.