在控制台中使用 API 为图片添加标签
本快速入门将引导您完成以下过程:
- 创建带有标签的边界框的图片数据集。
- 使用数据集训练自定义模型。
在本快速入门中,您将使用自定义界面 (UI) 与 AutoML Vision API 进行交互。您还可以使用 AutoML API 完成本快速入门中的所有步骤。如需查看关于如何使用界面或 API 的更多说明,请参阅方法指南。
准备工作
在使用 AutoML Vision Object Detection 之前,您必须先创建 Google Cloud 项目(尚未用于其他任何 AutoML 产品的项目),然后为该项目启用 AutoML Vision Object Detection。
- 登录您的 Google Cloud 账号。如果您是 Google Cloud 新手,请创建一个账号来评估我们的产品在实际场景中的表现。新客户还可获享 $300 赠金,用于运行、测试和部署工作负载。
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
启用 Cloud AutoML and Storage API。
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
启用 Cloud AutoML and Storage API。
Beta 版要求
- 此 Beta 版要求您使用
us-central1作为指定区域。
准备数据集
在本快速入门中,您将使用通过 Open Images Dataset V4 创建的数据集。
此公开可用的沙拉数据集位于 gs://cloud-ml-data/img/openimage/csv/salads_ml_use.csv。
CSV 格式如下:
TRAINING,gs://cloud-ml-data/img/openimage/3/2520/3916261642_0a504acd60_o.jpg,Salad,0.0,0.0954,,,0.977,0.957,, VALIDATION,gs://cloud-ml-data/img/openimage/3/2520/3916261642_0a504acd60_o.jpg,Seafood,0.0154,0.1538,,,1.0,0.802,, TEST,gs://cloud-ml-data/img/openimage/3/2520/3916261642_0a504acd60_o.jpg,Tomato,0.0,0.655,,,0.231,0.839,,

3916261642_0a504acd60_o.jpg每行对应一个位于较大图片内的对象,每个对象专门指定为测试数据、训练数据或验证数据。此处包含的三行表示位于同一张图片 (gs://cloud-ml-data/img/openimage/3/2520/3916261642_0a504acd60_o.jpg) 内的三个不同对象。除了具有 Baked goods 或 Cheese 标签的其他行以外,这三行中的每一行具有不同的标签:Salad、Seafood、Tomato。
我们使用左上顶点和右下顶点为每张图片指定边界框:
- (0,0) 对应于左上角最远处的顶点。
- (1,1) 对应于右下角最远处的顶点。
对于上面显示的第一行,具有 Salad 标签的对象的左上顶点的 (x, y) 坐标为 (0.0,0.0954),其右下顶点的坐标为 (0.977,0.957)。
如需详细了解如何设置 CSV 文件格式以及创建有效数据集的最低要求,请参阅准备训练数据。
创建数据集并导入训练图片
-
打开 AutoML Vision Object Detection 界面,然后从标题栏的下拉列表中选择您的项目。
首次打开 AutoML Vision Object Detection 界面时,您需要启用 AutoML API(如果尚未启用)。
- 看到提示时,在弹出式窗口中选择开始使用。
-
您将转到数据集列表页面。通过选择新建数据集来创建新数据集。
为您的数据集输入一个独一无二的名称。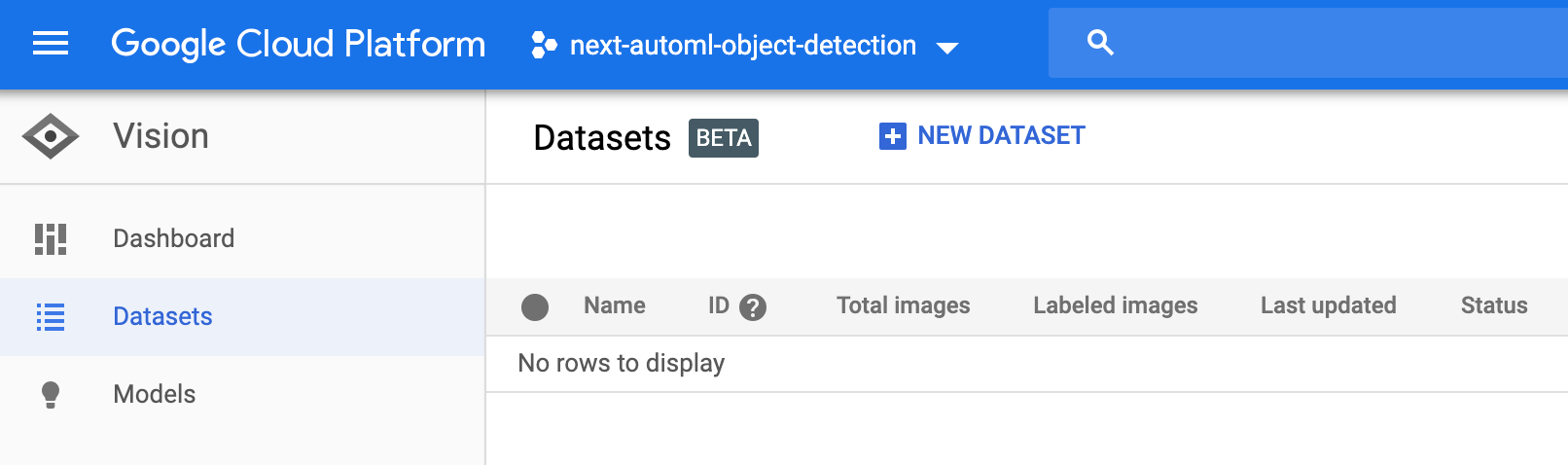
-
在随后出现的窗口中输入要导入的训练数据的位置。
在选择 Cloud Storage 上的 CSV 文件文本框中,输入示例 CSV 文件的路径(系统会自动添加
gs://前缀):cloud-ml-data/img/openimage/csv/salads_ml_use.csv
您也可以选择浏览,然后导航至某个 Google Cloud Storage 存储桶中的 CSV 文件。
此快速入门使用暂存在公共 Google Cloud Storage 存储桶中的示例数据。训练数据是您希望模型学习识别的带边界框注释和对象标签的示例 JPG 图片。要将训练数据导入数据集,请使用指向图片(JPEG、PNG、GIF、BMP 或 ICO)文件的 CSV 文件;请参阅准备训练数据以了解有关格式和图片规格的信息。
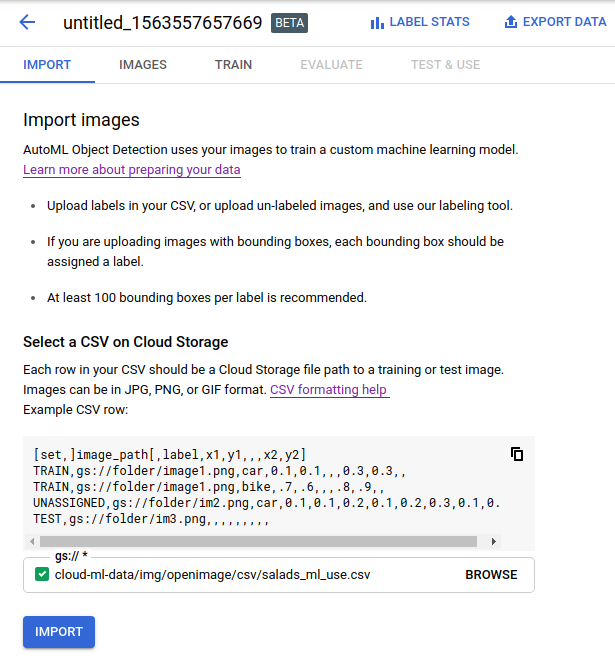
-
选择导入。
您的数据集会在图片导入期间显示
Running:importing images的状态。此过程只需几分钟时间。
成功导入训练数据后,状态列会显示 Success:Creating dataset,界面会显示为数据集生成的 ID(在调用 AutoML API 时使用)以及所导入的项数。

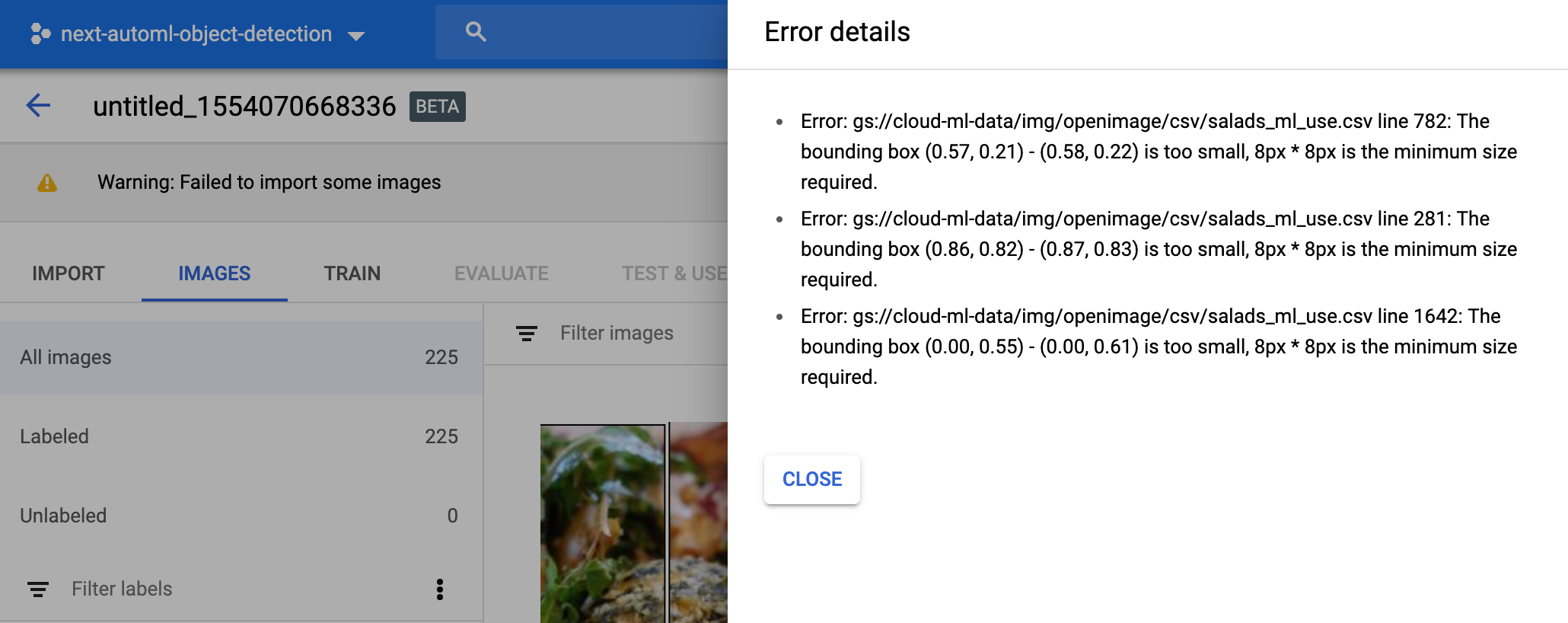
如果在导入图片时出现问题,您会看到 Warning: Importing
images 的状态。选择数据集名称和详细信息可查看导入特定图片时出现的错误。
训练模型
创建数据集并将训练数据导入数据集后,您可以训练自定义模型。
在数据集列表页面中,点击数据集名称。
选择训练标签页。此操作将显示所有标签及其训练集、测试集和验证集分类。
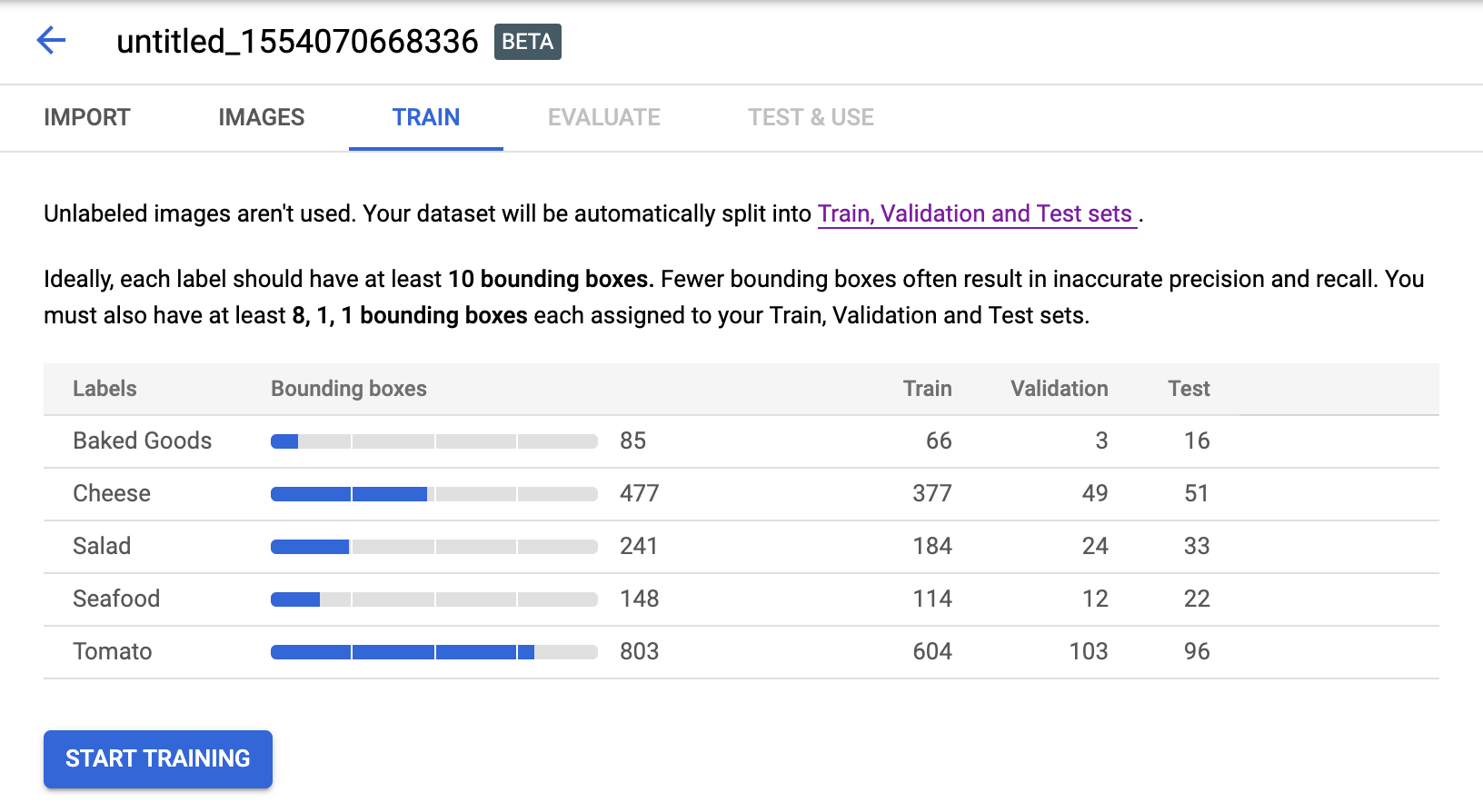
选择开始训练,打开包含训练选项的侧边栏。
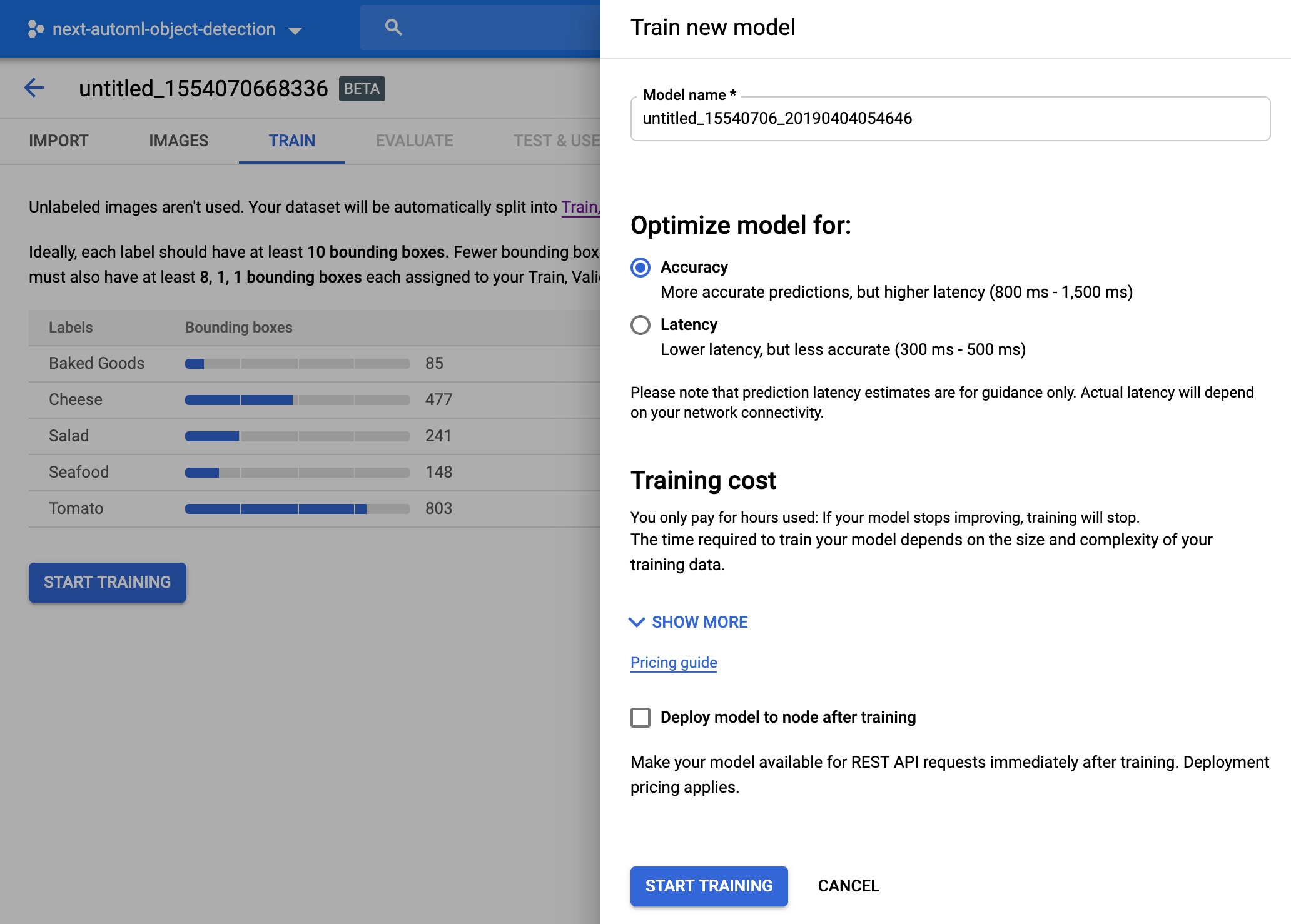
输入自定义模型的名称或接受默认名称。在此面板中,您还可以选择模型优化(针对延迟或准确率)。
选中 训练完成后将模型部署到节点以选择启用自动部署。否则,系统将提示您在训练后手动部署模型,然后才能进行预测。
选择开始训练。

训练模型可能需要几个小时才能完成。示例的训练时间通常约为 1 小时。
成功训练模型后,我们会向您注册程序时使用的电子邮件地址发送一封邮件。
评估自定义模型
训练完模型后,AutoML Vision Object Detection 会评估新模型的质量和准确率。要查看模型的评估指标,请执行以下操作:
打开 AutoML Vision Object Detection 界面,然后点击左侧导航栏中的模型标签页(带有灯泡图标)。
点击要评估的模型的名称。
如果需要,请点击标题栏正下方的评估标签。
如果模型训练完毕,AutoML Vision Object Detection 会显示其评估指标。它提供了模型整体及每个对象标签在不同得分和交并比 (IoU) 阈值时的精确率和召回率得分。 要查看特定对象标签的指标,请从“过滤条件标签”列表中选择该标签。
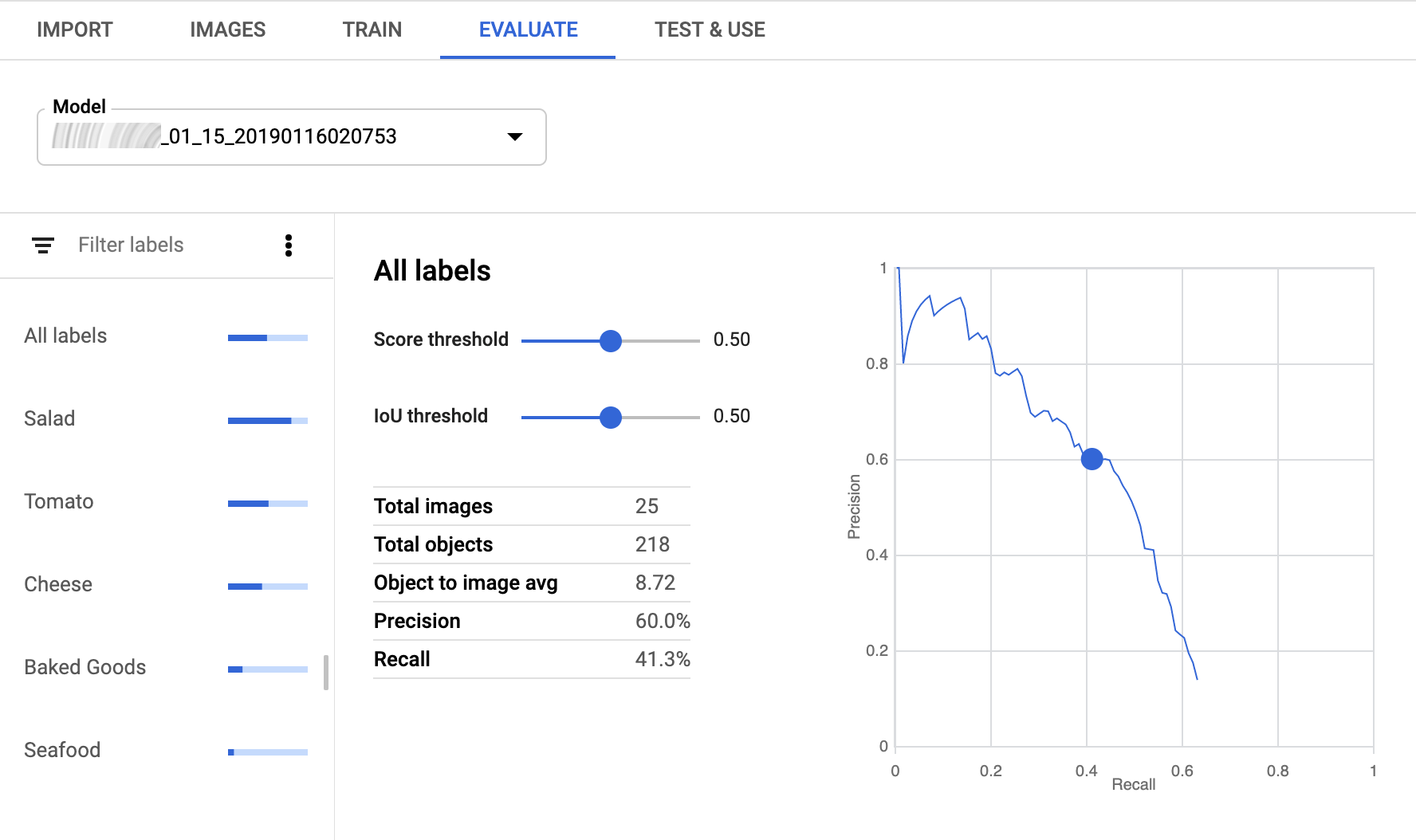
精确率和召回率用于衡量模型捕获信息的情况以及丢失的信息量。精确率表示在使用特定标签注释的所有对象中,实际有多少对象应分配给该标签。召回率表示在应被确定为特定实体的所有对象中,实际有多少对象分配给了该实体。
您可利用这些数据来评估模型的就绪情况:
- 低精确率或召回率得分可能表明您的模型需要额外的训练数据。
- 完美的精确率和召回率可能表明数据过于简单,模型可能无法有效泛化。
使用自定义模型
成功训练模型后,您可以使用它来通过自定义模型识别带有边界框和标签的图片中的对象。选择测试和使用标签页。
如果您没有选择启用自动部署,则系统会提示您先部署模型,然后才能进行预测。
手动部署模型
AutoML Vision 要求您先部署训练好的模型,然后才能向其发送预测请求。
- 在测试和使用标签页中,从模型名称下方的横幅中选择部署模型选项,以手动部署模型。
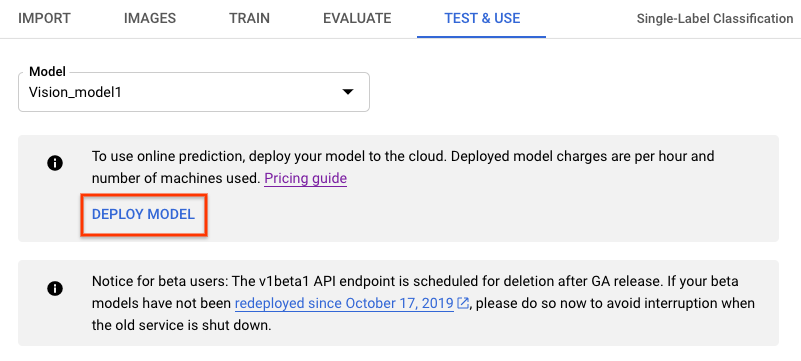
选择部署模型后,系统会打开模型部署选项窗口
- 在模型部署选项窗口中,您可以选择要在其中部署模型的节点数,以及查看每秒可用的预测查询次数 (QPS)。
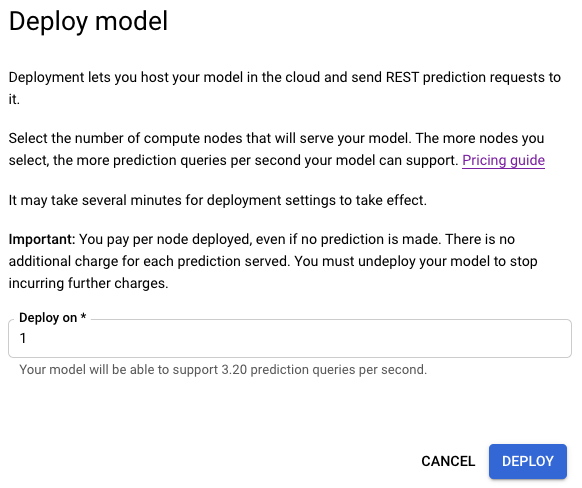
- 选择部署以开始部署模型。
- 模型部署完成后,您会收到电子邮件通知。
进行预测
模型部署完毕后,请在测试和使用页面上指示测试图片的路径(例如,保存在本地的此图片)。AutoML Vision 使用模型分析图片,并在图片中显示带有标签的对象及其边界框。
{kind=link}
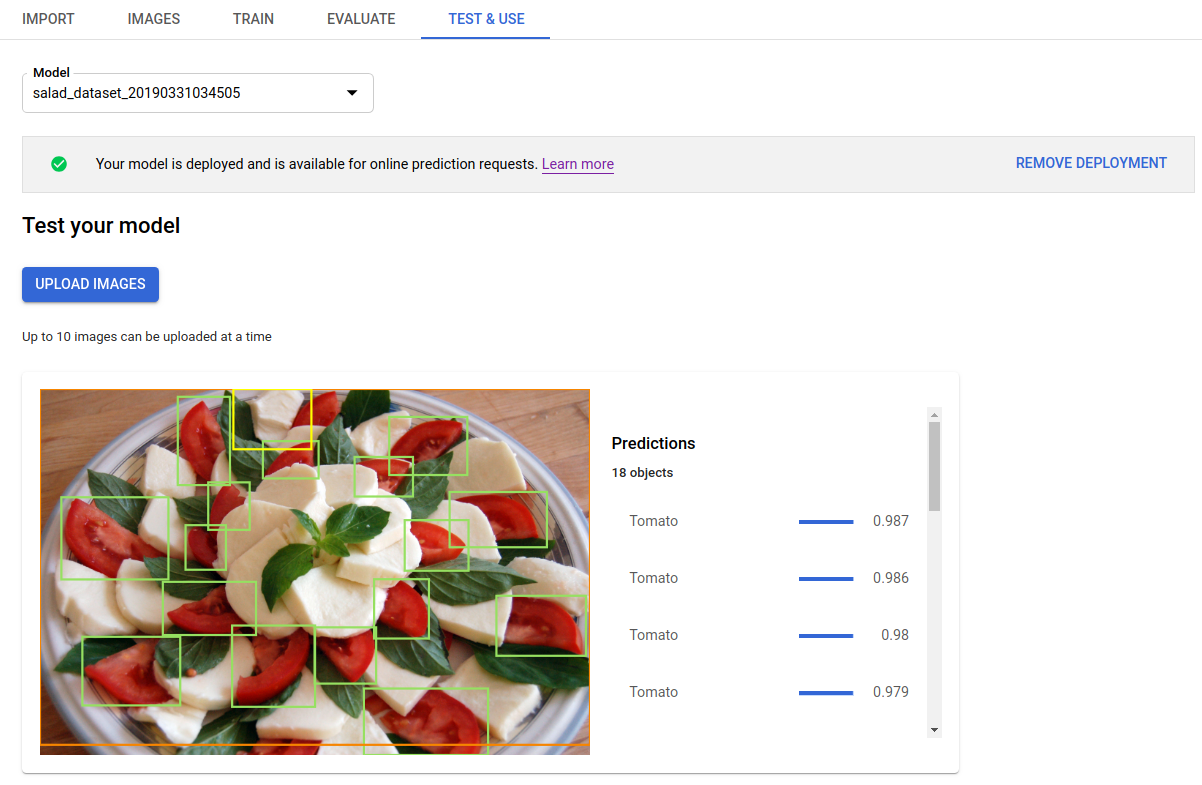
清理
为避免因本页中使用的资源导致您的 Google Cloud 账号产生费用,请按照以下步骤操作。
如果您不再需要您的自定义模型或数据集,可以将其删除。
为避免产生不必要的 Google Cloud Platform 费用,请使用 GCP Console 删除您不需要的项目。
取消部署模型
模型部署后即会产生费用。
- 选择标题栏正下方的测试和使用标签页。
- 从模型名称下方的横幅中选择移除部署,以打开取消部署选项窗口。
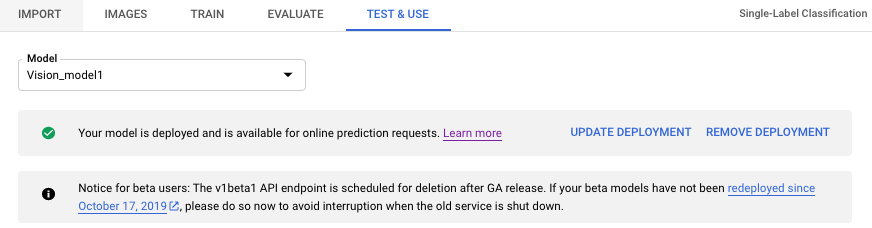
- 选择移除部署以取消部署模型。
- 模型取消部署完成后,您会收到电子邮件通知。
删除项目(可选)
为避免产生不必要的 Google Cloud Platform 费用,请使用 Google Cloud 控制台删除您不需要的项目。