Erste Modellbereitstellung
Nachdem Sie ein Modell erstellt (trainiert) haben, müssen Sie das Modell bereitstellen, bevor Sie einen Online- oder synchronen Aufruf an das Modell durchführen können.
Sie können die Modellbereitstellung jetzt auch aktualisieren, falls Sie zusätzliche Onlinevorhersagekapazität benötigen.
Web-UI
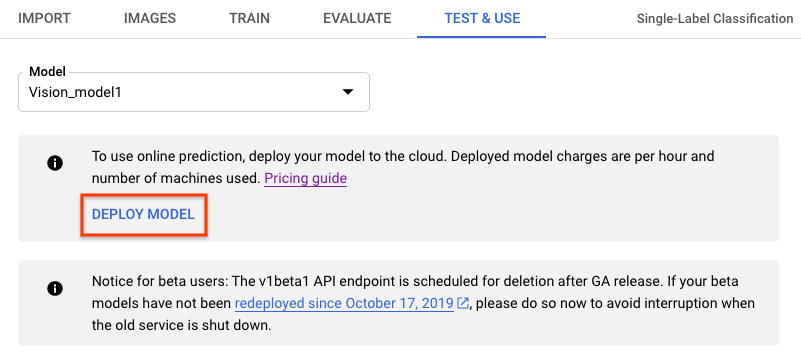
- Wechseln Sie zu dem Tab Test & Use (Test und Nutzung) unterhalb der Titelleiste.
- Klicken Sie auf die Schaltfläche Deploy Model (Modell bereitstellen). Dadurch wird ein neues Fenster mit der Bereitstellungsoption geöffnet.
- Geben Sie im neu geöffneten Fenster der Bereitstellungsoption die Anzahl der Knoten an, mit denen die Bereitstellung erfolgen soll.
Jeder Knoten unterstützt eine bestimmte Anzahl von Vorhersageabfragen pro Sekunde (Queries per Second, QPS).
Ein Knoten ist für die meisten Szenarien mit experimentellem Traffic in der Regel ausreichend.
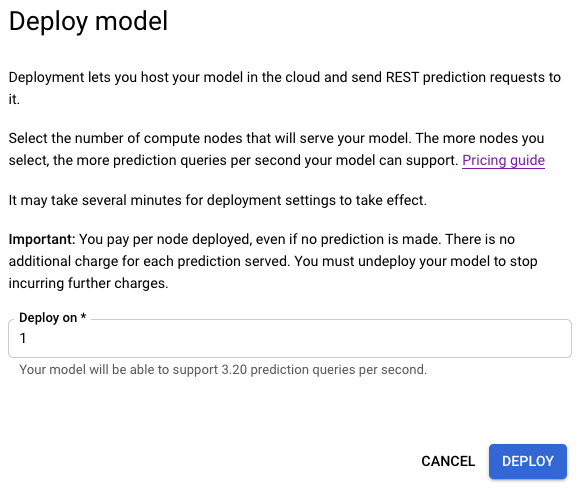
-
Wählen Sie Deploy (Bereitstellen) aus, um mit dem Bereitstellen des Modells zu beginnen.
- Sie erhalten eine E-Mail, sobald die Bereitstellung des Modells abgeschlossen ist.
REST
Ersetzen Sie dabei folgende Werte für die Anfragedaten:
- project-id: die ID Ihres GCP-Projekts.
- model-id: die ID Ihres Modells aus der Antwort beim Erstellen des Modells. Sie ist das letzte Element des Modellnamens.
Beispiel:
- Modellname:
projects/project-id/locations/location-id/models/IOD4412217016962778756 - model id:
IOD4412217016962778756
- Modellname:
Hinweise zu bestimmten Feldern:
nodeCount: die Anzahl der Knoten, auf denen das Modell bereitgestellt werden soll. Der Wert muss zwischen 1 und 100 (beide einschließlich) liegen. Ein Knoten ist eine Abstraktion einer Maschinenressource, die so viele Online-Vorhersageabfragen pro Sekunde (Queries per second, QPS) verarbeiten kann, wie im Modell inqps_per_nodeangegeben.
HTTP-Methode und URL:
POST https://automl.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/models/MODEL_ID:deploy
JSON-Text der Anfrage:
{
"imageClassificationModelDeploymentMetadata": {
"nodeCount": 2
}
}
Wenn Sie die Anfrage senden möchten, wählen Sie eine der folgenden Optionen aus:
curl
Speichern Sie den Anfragetext in einer Datei mit dem Namen request.json und führen Sie den folgenden Befehl aus:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "x-goog-user-project: project-id" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://automl.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/models/MODEL_ID:deploy"
PowerShell
Speichern Sie den Anfragetext in einer Datei mit dem Namen request.json und führen Sie den folgenden Befehl aus:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred"; "x-goog-user-project" = "project-id" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://automl.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/models/MODEL_ID:deploy" | Select-Object -Expand Content
Die Ausgabe sieht in etwa so aus: Sie können den Status der Aufgabe anhand der Vorgangs-ID abrufen. Ein Beispiel finden Sie unter Mit lang andauernden Vorgängen arbeiten.
{
"name": "projects/PROJECT_ID/locations/us-central1/operations/OPERATION_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.automl.v1.OperationMetadata",
"createTime": "2019-08-07T22:00:20.692109Z",
"updateTime": "2019-08-07T22:00:20.692109Z",
"deployModelDetails": {}
}
}
Sie können den Status eines Vorgangs mit der folgenden HTTP-Methode und URL abrufen:
GET https://automl.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/operations/OPERATION_ID
Der Status eines abgeschlossenen Vorgangs sieht ungefähr so aus:
{
"name": "projects/PROJECT_ID/locations/us-central1/operations/OPERATION_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.automl.v1.OperationMetadata",
"createTime": "2019-06-21T16:47:21.704674Z",
"updateTime": "2019-06-21T17:01:00.802505Z",
"deployModelDetails": {}
},
"done": true,
"response": {
"@type": "type.googleapis.com/google.protobuf.Empty"
}
}
Go
Bevor Sie dieses Beispiel ausprobieren, folgen Sie der Einrichtungsanleitung für diese Sprache auf der Seite Clientbibliotheken.
Java
Bevor Sie dieses Beispiel ausprobieren, folgen Sie der Einrichtungsanleitung für diese Sprache auf der Seite Clientbibliotheken.
Node.js
Bevor Sie dieses Beispiel ausprobieren, folgen Sie der Einrichtungsanleitung für diese Sprache auf der Seite Clientbibliotheken.
Python
Bevor Sie dieses Beispiel ausprobieren, folgen Sie der Einrichtungsanleitung für diese Sprache auf der Seite Clientbibliotheken.
Weitere Sprachen
C#: Folgen Sie der Anleitung zur Einrichtung von C# auf der Seite der Clientbibliotheken und rufen Sie dann die AutoML Vision-Referenzdokumentation für .NET auf.
PHP Folgen Sie der Anleitung zur Einrichtung von PHP auf der Seite der Clientbibliotheken und rufen Sie dann die AutoML Vision-Referenzdokumentation für PHP auf.
Ruby: Folgen Sie der Anleitung zur Einrichtung von Ruby auf der Seite der Clientbibliotheken und rufen Sie dann die AutoML Vision-Referenzdokumentation für Ruby auf.
Knotenzahl eines Modells aktualisieren
Sobald ein bereitgestelltes Modell trainiert ist, können Sie die Anzahl der Knoten aktualisieren, auf denen das Modell bereitgestellt wird. So können Sie auf die spezifische Menge an Traffic reagieren. Wenn beispielsweise eine höhere Anzahl von Abfragen pro Sekunde als erwartet auftritt, können Sie die bereitgestellte Anzahl an Knoten anpassen, um diesen Traffic zu verarbeiten.
Sie können die Anzahl der Knoten ändern, ohne erst das Modell zurücksetzen zu müssen. Wenn Sie die Bereitstellung aktualisieren, ändert sich die Knotenanzahl, ohne dass der bereitgestellte Vorhersage-Traffic unterbrochen wird.
Web-UI
Öffnen Sie Vision Dashboardund wählen Sie in der linken Navigationsleiste den Tab Modelle aus, um die verfügbaren Modelle aufzurufen.
Wenn Sie die Modelle für ein anderes Projekt ansehen möchten, wählen Sie das Projekt in der Drop-down-Liste rechts oben in der Titelleiste aus.
- Wählen Sie Ihr trainiertes Modell aus.
- Wählen Sie den Tab Test und Nutzung direkt unter der Titelleiste aus.
-
Oben auf der Seite wird in einem Feld eine Nachricht mit dem Text „Ihr Modell wurde bereitgestellt und ist für Online-Vorhersageanfragen verfügbar” angezeigt. Wählen Sie neben dem Text die Option Deployment aktualisieren aus.
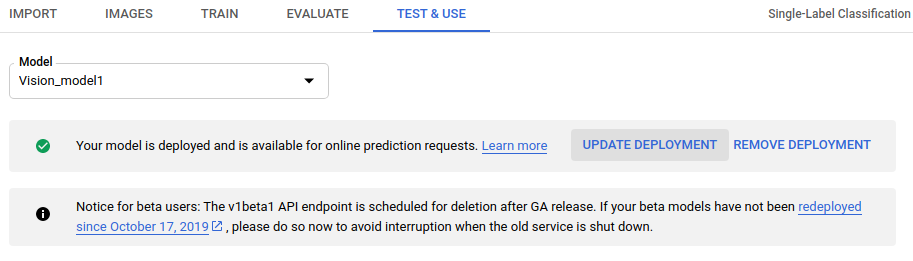
- Wählen Sie im angezeigten Fenster Deployment aktualisieren aus der Liste die neue Knotennummer aus, auf der das Modell bereitgestellt werden soll. Mit den Knotennummern wird die Anzahl der geschätzten Vorhersageabfragen pro Sekunde angegeben.
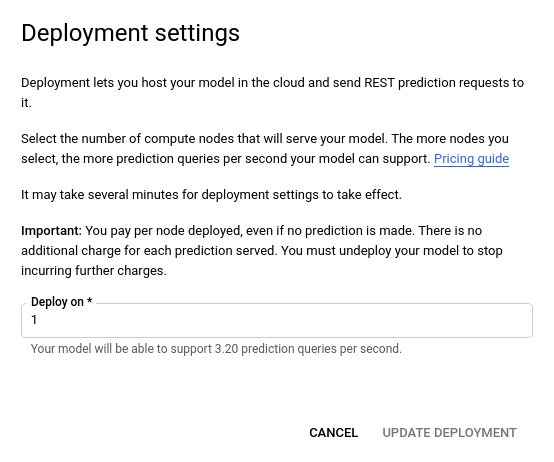
Wenn Sie eine neue Knotennummer aus der Liste ausgewählt haben, wählen Sie Deployment aktualisieren aus, um die Knotennummer zu aktualisieren, auf der das Modell bereitgestellt wird.
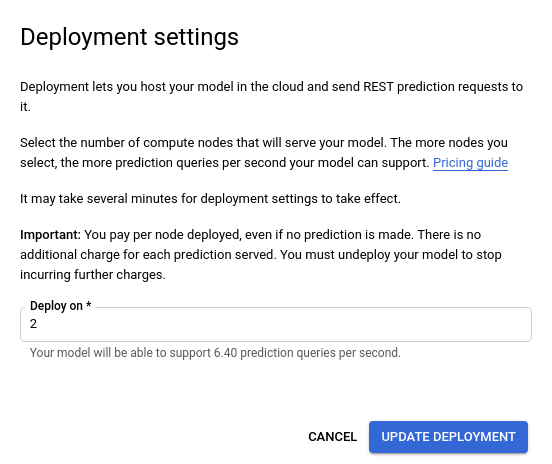
- Es wird wieder das Fenster Test und Nutzung aufgerufen, in dem jetzt das Textfeld „Modell wird bereitgestellt” angezeigt wird.
Wenn Ihr Modell erfolgreich auf der neuen Knotennummer bereitgestellt wurde, erhalten Sie eine E-Mail an die mit Ihrem Projekt verknüpfte Adresse.
REST
Die Methode, mit der Sie anfänglich ein Modell bereitstellen, wird auch zum Ändern der Knotennummer des bereitgestellten Modells verwendet.Ersetzen Sie diese Werte in den folgenden Anfragedaten:
- project-id: die ID Ihres GCP-Projekts.
- model-id: die ID Ihres Modells aus der Antwort beim Erstellen des Modells. Sie ist das letzte Element des Modellnamens.
Beispiel:
- Modellname:
projects/project-id/locations/location-id/models/IOD4412217016962778756 - model id:
IOD4412217016962778756
- Modellname:
Hinweise zu bestimmten Feldern:
nodeCount: die Anzahl der Knoten, auf denen das Modell bereitgestellt werden soll. Der Wert muss zwischen 1 und 100 (beide einschließlich) liegen. Ein Knoten ist eine Abstraktion einer Maschinenressource, die so viele Online-Vorhersageabfragen pro Sekunde (Queries per second, QPS) verarbeiten kann, wie im Modell inqps_per_nodeangegeben.
HTTP-Methode und URL:
POST https://automl.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/models/MODEL_ID:deploy
JSON-Text der Anfrage:
{
"imageClassificationModelDeploymentMetadata": {
"nodeCount": 2
}
}
Wenn Sie die Anfrage senden möchten, wählen Sie eine der folgenden Optionen aus:
curl
Speichern Sie den Anfragetext in einer Datei mit dem Namen request.json und führen Sie den folgenden Befehl aus:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "x-goog-user-project: project-id" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://automl.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/models/MODEL_ID:deploy"
PowerShell
Speichern Sie den Anfragetext in einer Datei mit dem Namen request.json und führen Sie den folgenden Befehl aus:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred"; "x-goog-user-project" = "project-id" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://automl.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/models/MODEL_ID:deploy" | Select-Object -Expand Content
Die Ausgabe sieht in etwa so aus: Sie können den Status der Aufgabe anhand der Vorgangs-ID abrufen. Ein Beispiel finden Sie unter Mit lang andauernden Vorgängen arbeiten.
{
"name": "projects/PROJECT_ID/locations/us-central1/operations/OPERATION_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.automl.v1.OperationMetadata",
"createTime": "2019-08-07T22:00:20.692109Z",
"updateTime": "2019-08-07T22:00:20.692109Z",
"deployModelDetails": {}
}
}
Sie können den Status eines Vorgangs mit der folgenden HTTP-Methode und URL abrufen:
GET https://automl.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/operations/OPERATION_ID
Der Status eines abgeschlossenen Vorgangs sieht ungefähr so aus:
{
"name": "projects/PROJECT_ID/locations/us-central1/operations/OPERATION_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.automl.v1.OperationMetadata",
"createTime": "2019-06-21T16:47:21.704674Z",
"updateTime": "2019-06-21T17:01:00.802505Z",
"deployModelDetails": {}
},
"done": true,
"response": {
"@type": "type.googleapis.com/google.protobuf.Empty"
}
}
Go
Bevor Sie dieses Beispiel ausprobieren, folgen Sie der Einrichtungsanleitung für diese Sprache auf der Seite Clientbibliotheken.
Java
Bevor Sie dieses Beispiel ausprobieren, folgen Sie der Einrichtungsanleitung für diese Sprache auf der Seite Clientbibliotheken.
Node.js
Bevor Sie dieses Beispiel ausprobieren, folgen Sie der Einrichtungsanleitung für diese Sprache auf der Seite Clientbibliotheken.
Python
Bevor Sie dieses Beispiel ausprobieren, folgen Sie der Einrichtungsanleitung für diese Sprache auf der Seite Clientbibliotheken.
Weitere Sprachen
C#: Folgen Sie der Anleitung zur Einrichtung von C# auf der Seite der Clientbibliotheken und rufen Sie dann die AutoML Vision-Referenzdokumentation für .NET auf.
PHP Folgen Sie der Anleitung zur Einrichtung von PHP auf der Seite der Clientbibliotheken und rufen Sie dann die AutoML Vision-Referenzdokumentation für PHP auf.
Ruby: Folgen Sie der Anleitung zur Einrichtung von Ruby auf der Seite der Clientbibliotheken und rufen Sie dann die AutoML Vision-Referenzdokumentation für Ruby auf.