Deployment iniziale del modello
Dopo aver creato (addestrato) un modello, devi eseguirne il deployment prima di può effettuare chiamate online (o sincrone) al modello.
Ora puoi anche aggiornare il deployment del modello se hai bisogno di ulteriore capacità di previsione online.
UI web
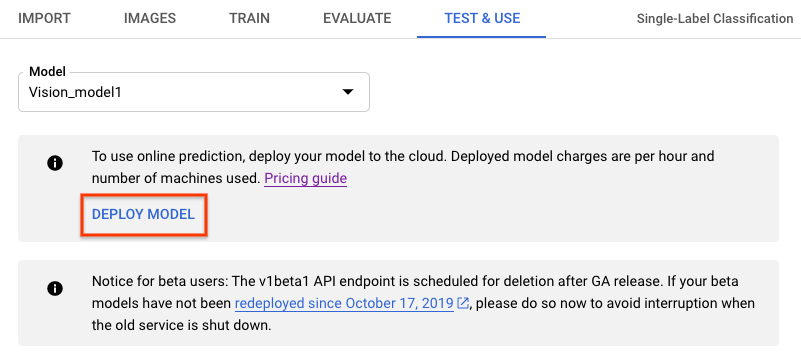
- Vai alla scheda Testa e Usa sotto la barra del titolo.
- Seleziona il pulsante Esegui il deployment del modello. Viene visualizzata una nuova finestra con le opzioni di deployment.
- Nella finestra delle opzioni di deployment appena aperta, specifica il numero di nodi con cui eseguire il deployment.
Ciascun nodo supporta un determinato numero di query di previsione al secondo (QPS).
In genere, un nodo è sufficiente per la maggior parte del traffico sperimentale.
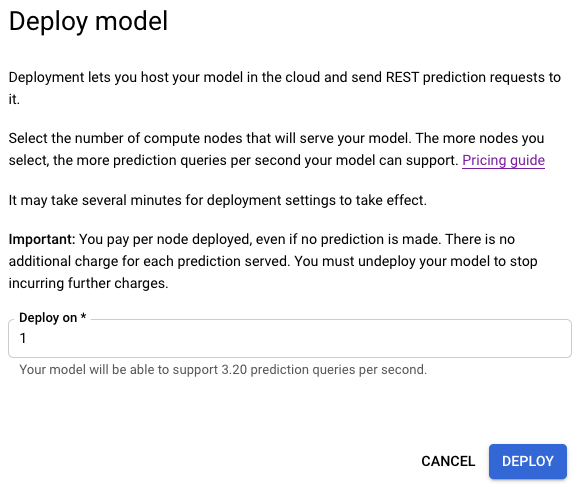
-
Seleziona Esegui il deployment per iniziare il deployment del modello.
- Riceverai un'e-mail al termine dell'operazione di deployment del modello finiture in cui sono finite.
REST
Prima di utilizzare i dati della richiesta, effettua le seguenti sostituzioni:
- project-id: l'ID del tuo progetto Google Cloud.
- model-id: l'ID del modello, dalla
quando hai creato il modello. L'ID è l'ultimo elemento del nome del modello.
Ad esempio:
- nome modello:
projects/project-id/locations/location-id/models/IOD4412217016962778756 - ID modello:
IOD4412217016962778756
- nome modello:
Considerazioni sui campi:
nodeCount- Il numero di nodi su cui eseguire il deployment del modello. Il valore deve essere compreso tra 1 e 100, inclusi su entrambe le estremità. Un nodo è un di una risorsa macchina, in grado di gestire la previsione online query al secondo (QPS) come indicato nellaqps_per_node.
Metodo HTTP e URL:
POST https://automl.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/models/MODEL_ID:deploy
Corpo JSON della richiesta:
{
"imageClassificationModelDeploymentMetadata": {
"nodeCount": 2
}
}
Per inviare la richiesta, scegli una delle seguenti opzioni:
curl
Salva il corpo della richiesta in un file denominato request.json.
ed esegui questo comando:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "x-goog-user-project: project-id" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://automl.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/models/MODEL_ID:deploy"
PowerShell
Salva il corpo della richiesta in un file denominato request.json.
ed esegui questo comando:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred"; "x-goog-user-project" = "project-id" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://automl.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/models/MODEL_ID:deploy" | Select-Object -Expand Content
Dovresti vedere un output simile al seguente. Puoi utilizzare l'ID operazione per ottenere lo stato dell'attività. Per un esempio, vedi Operazioni con operazioni a lunga esecuzione
{
"name": "projects/PROJECT_ID/locations/us-central1/operations/OPERATION_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.automl.v1.OperationMetadata",
"createTime": "2019-08-07T22:00:20.692109Z",
"updateTime": "2019-08-07T22:00:20.692109Z",
"deployModelDetails": {}
}
}
Puoi ottenere lo stato di un'operazione con il metodo HTTP e l'URL seguenti:
GET https://automl.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/operations/OPERATION_ID
Lo stato di un'operazione terminata sarà simile al seguente:
{
"name": "projects/PROJECT_ID/locations/us-central1/operations/OPERATION_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.automl.v1.OperationMetadata",
"createTime": "2019-06-21T16:47:21.704674Z",
"updateTime": "2019-06-21T17:01:00.802505Z",
"deployModelDetails": {}
},
"done": true,
"response": {
"@type": "type.googleapis.com/google.protobuf.Empty"
}
}
Go
Prima di provare questo esempio, segui le istruzioni di configurazione per questa lingua nella Librerie client.
Java
Prima di provare questo esempio, segui le istruzioni di configurazione per questa lingua nella Librerie client.
Node.js
Prima di provare questo esempio, segui le istruzioni di configurazione per questa lingua nella Librerie client.
Python
Prima di provare questo esempio, segui le istruzioni di configurazione per questa lingua nella Librerie client.
Linguaggi aggiuntivi
C#: Segui le Istruzioni per la configurazione di C# Nella pagina delle librerie client e poi visita Documentazione di riferimento di AutoML Vision per .NET.
PHP Segui le Istruzioni per la configurazione dei file PHP Nella pagina delle librerie client e poi visita Documentazione di riferimento di AutoML Vision per PHP.
Rubino: Segui le Istruzioni per la configurazione di Ruby Nella pagina delle librerie client e poi visita Documentazione di riferimento di AutoML Vision per Ruby.
Aggiornamento del numero di nodi di un modello
Una volta eseguito il deployment del modello addestrato, puoi aggiornare il numero di nodi su cui viene eseguito il deployment del modello per rispondere alla quantità specifica di traffico. Ad esempio, se quando il numero di query al secondo (QPS) è maggiore del previsto. Puoi regolare le query al secondo di nodo per gestire il traffico.
Puoi modificare questo numero di nodo senza prima avere per annullare il deployment del modello. L'aggiornamento del deployment modifica il numero di nodi senza interrompendo il traffico di previsione gestito.
UI web
In Vision Dashboard seleziona la scheda Modelli nel riquadro di navigazione a sinistra barra per visualizzare i modelli disponibili.
Per visualizzare i modelli di un altro progetto, seleziona il progetto dal nell'elenco a discesa in alto a destra della barra del titolo.
- Seleziona il modello addestrato di cui hai eseguito il deployment.
- Seleziona il pulsante Testa e Usa Tab appena sotto la barra del titolo.
-
Viene visualizzato un messaggio nella parte superiore della pagina con il messaggio: del modello è stato eseguito ed è disponibile per le richieste di previsione online". Seleziona l'opzione Aggiorna deployment a lato di questo testo.
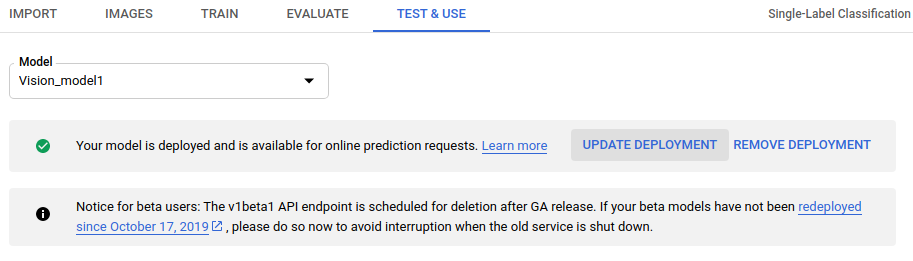
- Nella finestra Aggiorna deployment che si apre, seleziona il nuovo numero di nodo
su cui eseguire il deployment del modello dall'elenco. I numeri dei nodi mostrano la stima
query di previsione al secondo (QPS).
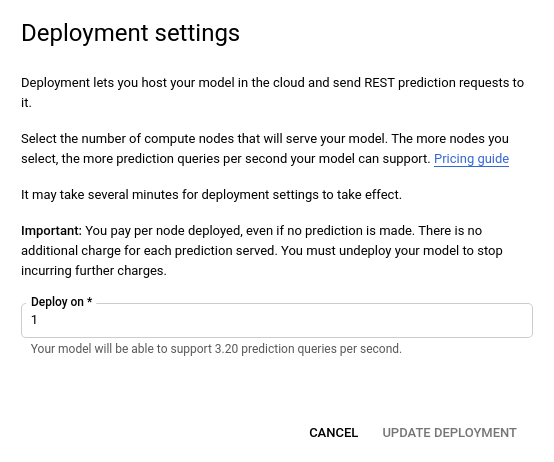
Dopo aver selezionato un nuovo numero di nodo dall'elenco, seleziona Aggiorna il deployment per aggiornare il numero di nodo in cui viene eseguito il deployment del modello.
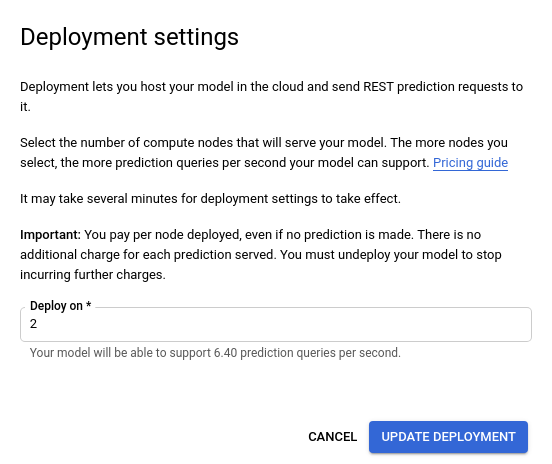
- Tornerai alla sezione Test & Usa la finestra in cui vedi il testo
che ora mostra "Deployment del modello in corso...".
Dopo aver eseguito il deployment del modello sul nuovo numero di nodo, riceverà un'email all'indirizzo associato al tuo progetto.
REST
Lo stesso metodo che usi inizialmente per eseguire il deployment di un modello viene usato anche per modificare il numero di nodo del modello di cui è stato eseguito il deployment.Prima di utilizzare i dati della richiesta, effettua le seguenti sostituzioni:
- project-id: l'ID del tuo progetto Google Cloud.
- model-id: l'ID del modello, dalla
quando hai creato il modello. L'ID è l'ultimo elemento del nome del modello.
Ad esempio:
- nome modello:
projects/project-id/locations/location-id/models/IOD4412217016962778756 - ID modello:
IOD4412217016962778756
- nome modello:
Considerazioni sui campi:
nodeCount- Il numero di nodi su cui eseguire il deployment del modello. Il valore deve essere compreso tra 1 e 100, inclusi su entrambe le estremità. Un nodo è un di una risorsa macchina, in grado di gestire la previsione online query al secondo (QPS) come indicato nellaqps_per_node.
Metodo HTTP e URL:
POST https://automl.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/models/MODEL_ID:deploy
Corpo JSON della richiesta:
{
"imageClassificationModelDeploymentMetadata": {
"nodeCount": 2
}
}
Per inviare la richiesta, scegli una delle seguenti opzioni:
curl
Salva il corpo della richiesta in un file denominato request.json.
ed esegui questo comando:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "x-goog-user-project: project-id" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://automl.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/models/MODEL_ID:deploy"
PowerShell
Salva il corpo della richiesta in un file denominato request.json.
ed esegui questo comando:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred"; "x-goog-user-project" = "project-id" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://automl.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/models/MODEL_ID:deploy" | Select-Object -Expand Content
Dovresti vedere un output simile al seguente. Puoi utilizzare l'ID operazione per ottenere lo stato dell'attività. Per un esempio, vedi Operazioni con operazioni a lunga esecuzione
{
"name": "projects/PROJECT_ID/locations/us-central1/operations/OPERATION_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.automl.v1.OperationMetadata",
"createTime": "2019-08-07T22:00:20.692109Z",
"updateTime": "2019-08-07T22:00:20.692109Z",
"deployModelDetails": {}
}
}
Puoi ottenere lo stato di un'operazione con il metodo HTTP e l'URL seguenti:
GET https://automl.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/operations/OPERATION_ID
Lo stato di un'operazione terminata sarà simile al seguente:
{
"name": "projects/PROJECT_ID/locations/us-central1/operations/OPERATION_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.automl.v1.OperationMetadata",
"createTime": "2019-06-21T16:47:21.704674Z",
"updateTime": "2019-06-21T17:01:00.802505Z",
"deployModelDetails": {}
},
"done": true,
"response": {
"@type": "type.googleapis.com/google.protobuf.Empty"
}
}
Go
Prima di provare questo esempio, segui le istruzioni di configurazione per questa lingua nella Librerie client.
Java
Prima di provare questo esempio, segui le istruzioni di configurazione per questa lingua nella Librerie client.
Node.js
Prima di provare questo esempio, segui le istruzioni di configurazione per questa lingua nella Librerie client.
Python
Prima di provare questo esempio, segui le istruzioni di configurazione per questa lingua nella Librerie client.
Linguaggi aggiuntivi
C#: Segui le Istruzioni per la configurazione di C# Nella pagina delle librerie client e poi visita Documentazione di riferimento di AutoML Vision per .NET.
PHP Segui le Istruzioni per la configurazione dei file PHP Nella pagina delle librerie client e poi visita Documentazione di riferimento di AutoML Vision per PHP.
Rubino: Segui le Istruzioni per la configurazione di Ruby Nella pagina delle librerie client e poi visita Documentazione di riferimento di AutoML Vision per Ruby.