Implementación inicial del modelo
Después de crear (entrenar) un modelo, debes implementarlo antes de poder realizar llamadas en línea (o síncronas) al modelo.
Ahora puedes actualizar la implementación del modelo si necesitas capacidad adicional de predicción en línea.
IU web
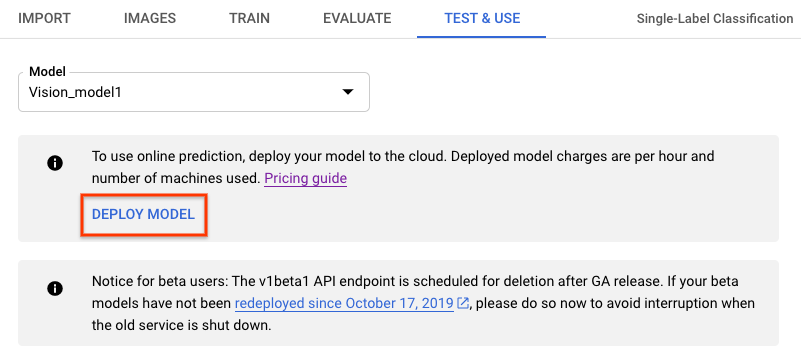
- Navega a la pestaña Test & Use (Probar y usar) debajo de la barra de título.
- Selecciona el botón Implementar modelo (Deploy Model). Se abrirá una nueva ventana de opción de implementación.
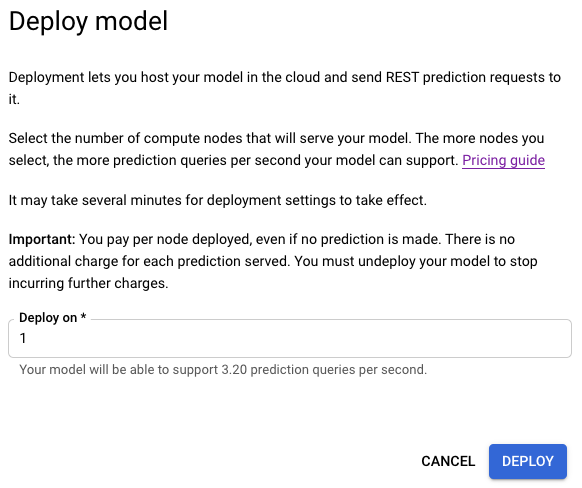
- En la ventana de opción de implementación recién abierta, especifica la cantidad de nodos para implementar.
Cada nodo admite una cierta cantidad de consultas de predicción por segundo (QPS).
Por lo general, un nodo basta para la mayor parte del tráfico experimental.
-
Selecciona Implementar (Deploy) para comenzar la implementación del modelo.

- Cuando la operación de implementación del modelo finalice recibirás un correo electrónico.
REST
Antes de usar cualquiera de los datos de solicitud a continuación, realiza los siguientes reemplazos:
- project-id: El ID del proyecto de GCP.
- model-id: Es el ID del modelo, que se muestra en la respuesta que recibiste cuando lo creaste. El ID es el último elemento del nombre del modelo.
Por ejemplo:
- Nombre del modelo:
projects/project-id/locations/location-id/models/IOD4412217016962778756 - ID del modelo:
IOD4412217016962778756
- Nombre del modelo:
Consideraciones de campo:
nodeCount: Es la cantidad de nodos en los que se implementará el modelo. Debe ser un valor entre 1 y 100, inclusivo en ambos extremos. Un nodo es una abstracción de un recurso de máquina, que puede controlar consultas por segundo (QPS) de predicción en línea como se indica en laqps_per_nodedel modelo.
Método HTTP y URL:
POST https://automl.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/models/MODEL_ID:deploy
Cuerpo JSON de la solicitud:
{
"imageClassificationModelDeploymentMetadata": {
"nodeCount": 2
}
}
Para enviar tu solicitud, elige una de estas opciones:
curl
Guarda el cuerpo de la solicitud en un archivo llamado request.json y ejecuta el siguiente comando:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "x-goog-user-project: project-id" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://automl.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/models/MODEL_ID:deploy"
PowerShell
Guarda el cuerpo de la solicitud en un archivo llamado request.json y ejecuta el siguiente comando:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred"; "x-goog-user-project" = "project-id" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://automl.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/models/MODEL_ID:deploy" | Select-Object -Expand Content
Deberías ver un resultado similar al siguiente. Puedes usar el ID de operación para obtener el estado de la tarea. Para ver un ejemplo, consulta Trabaja con operaciones de larga duración.
{
"name": "projects/PROJECT_ID/locations/us-central1/operations/OPERATION_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.automl.v1.OperationMetadata",
"createTime": "2019-08-07T22:00:20.692109Z",
"updateTime": "2019-08-07T22:00:20.692109Z",
"deployModelDetails": {}
}
}
Puedes obtener el estado de una operación con el siguiente método HTTP y URL:
GET https://automl.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/operations/OPERATION_ID
El estado de una operación finalizada será similar al siguiente:
{
"name": "projects/PROJECT_ID/locations/us-central1/operations/OPERATION_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.automl.v1.OperationMetadata",
"createTime": "2019-06-21T16:47:21.704674Z",
"updateTime": "2019-06-21T17:01:00.802505Z",
"deployModelDetails": {}
},
"done": true,
"response": {
"@type": "type.googleapis.com/google.protobuf.Empty"
}
}
Go
Antes de probar esta muestra, sigue las instrucciones de configuración para este lenguaje en la página Bibliotecas cliente.
Java
Antes de probar esta muestra, sigue las instrucciones de configuración para este lenguaje en la página Bibliotecas cliente.
Node.js
Antes de probar esta muestra, sigue las instrucciones de configuración para este lenguaje en la página Bibliotecas cliente.
Python
Antes de probar esta muestra, sigue las instrucciones de configuración para este lenguaje en la página Bibliotecas cliente.
Idiomas adicionales
C#: sigue las instrucciones de configuración de C# en la página Bibliotecas cliente y, luego, visita la documentación de referencia de AutoML Vision para .NET.
PHP: sigue las instrucciones de configuración de PHP en la página Bibliotecas cliente y, luego, visita la documentación de referencia de AutoML Vision para PHP.
Ruby: sigue las instrucciones de configuración de Ruby en la página Bibliotecas cliente y, luego, visita la documentación de referencia de AutoML Vision para Ruby.
Actualiza la cantidad de nodos de un modelo
Cuando tengas un modelo implementado y entrenado, podrás actualizar la cantidad de nodos en los que se implementó el modelo para responder a la cantidad específica de tráfico. Por ejemplo, si experimentas una mayor cantidad de consultas por segundo (QPS) de lo esperado, puedes ajustar la cantidad de nodos implementadas para manejar este tráfico.
Puedes cambiar este número de nodo sin tener que anular la implementación del modelo. La actualización de la implementación cambia la cantidad de nodos sin interrumpir el tráfico de predicción entregado.
IU web
En Vision Dashboard, selecciona la pestaña Modelos en la barra de navegación izquierda para mostrar los modelos disponibles.
Para ver los de un proyecto diferente, selecciónalo de la lista desplegable en la parte superior derecha de la barra de título.
- Selecciona el modelo entrenado que implementaste.
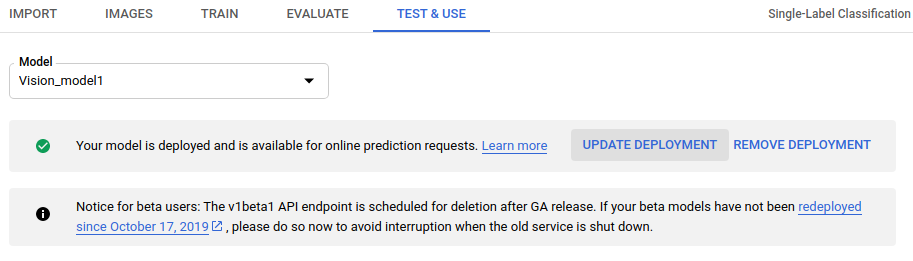
- Selecciona la pestaña Probar y usar, que se encuentra justo debajo de la barra de título.
-
Aparecerá un mensaje en un cuadro en la parte superior de la página que dice “Your model is deployed and is available for online prediction requests” (Tu modelo está implementado y se encuentra disponible para las solicitudes de predicción en línea). Selecciona la opción Update deployment (Actualizar implementación) que se encuentra al costado de este texto.
- En la ventana Actualizar implementación que se abre, selecciona en la lista la nueva cantidad de nodos para implementar tu modelo. La cantidad de nodos muestra sus consultas de predicción por segundo (QPS) estimadas.
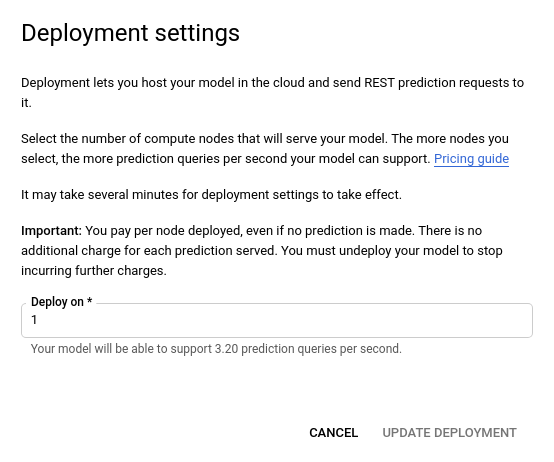
Después de seleccionar la cantidad nueva de nodos de la lista, selecciona Update deployment (Actualizar implementación) para actualizar la cantidad de nodos en la que se implementa el modelo.
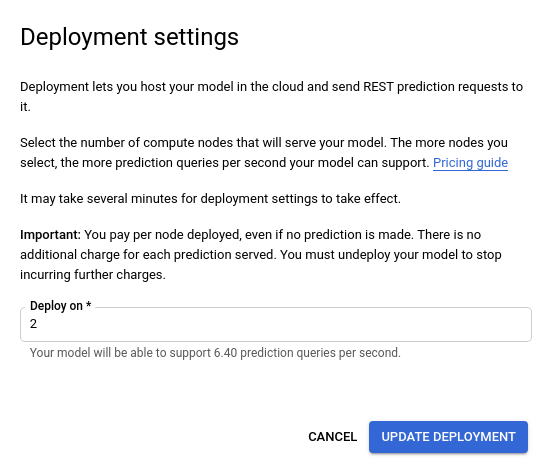
- Se te redirigirá a la ventana Test & Use (Prueba y Uso), en la que verás el cuadro de texto que muestra “Deploying model…” (Implementando modelo…).
Una vez que el modelo se implemente con éxito con la cantidad nueva de nodos, recibirás un correo electrónico en la dirección asociada a tu proyecto.
REST
El mismo método que usas en un principio para implementar un modelo también se usa a fin de cambiar la cantidad de nodos del modelo implementado.Antes de usar cualquiera de los datos de solicitud a continuación, realiza los siguientes reemplazos:
- project-id: El ID del proyecto de GCP.
- model-id: Es el ID del modelo, que se muestra en la respuesta que recibiste cuando lo creaste. El ID es el último elemento del nombre del modelo.
Por ejemplo:
- Nombre del modelo:
projects/project-id/locations/location-id/models/IOD4412217016962778756 - ID del modelo:
IOD4412217016962778756
- Nombre del modelo:
Consideraciones de campo:
nodeCount: Es la cantidad de nodos en los que se implementará el modelo. Debe ser un valor entre 1 y 100, inclusivo en ambos extremos. Un nodo es una abstracción de un recurso de máquina, que puede controlar consultas por segundo (QPS) de predicción en línea como se indica en laqps_per_nodedel modelo.
Método HTTP y URL:
POST https://automl.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/models/MODEL_ID:deploy
Cuerpo JSON de la solicitud:
{
"imageClassificationModelDeploymentMetadata": {
"nodeCount": 2
}
}
Para enviar tu solicitud, elige una de estas opciones:
curl
Guarda el cuerpo de la solicitud en un archivo llamado request.json y ejecuta el siguiente comando:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "x-goog-user-project: project-id" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://automl.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/models/MODEL_ID:deploy"
PowerShell
Guarda el cuerpo de la solicitud en un archivo llamado request.json y ejecuta el siguiente comando:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred"; "x-goog-user-project" = "project-id" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://automl.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/models/MODEL_ID:deploy" | Select-Object -Expand Content
Deberías ver un resultado similar al siguiente. Puedes usar el ID de operación para obtener el estado de la tarea. Para ver un ejemplo, consulta Trabaja con operaciones de larga duración.
{
"name": "projects/PROJECT_ID/locations/us-central1/operations/OPERATION_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.automl.v1.OperationMetadata",
"createTime": "2019-08-07T22:00:20.692109Z",
"updateTime": "2019-08-07T22:00:20.692109Z",
"deployModelDetails": {}
}
}
Puedes obtener el estado de una operación con el siguiente método HTTP y URL:
GET https://automl.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/operations/OPERATION_ID
El estado de una operación finalizada será similar al siguiente:
{
"name": "projects/PROJECT_ID/locations/us-central1/operations/OPERATION_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.automl.v1.OperationMetadata",
"createTime": "2019-06-21T16:47:21.704674Z",
"updateTime": "2019-06-21T17:01:00.802505Z",
"deployModelDetails": {}
},
"done": true,
"response": {
"@type": "type.googleapis.com/google.protobuf.Empty"
}
}
Go
Antes de probar esta muestra, sigue las instrucciones de configuración para este lenguaje en la página Bibliotecas cliente.
Java
Antes de probar esta muestra, sigue las instrucciones de configuración para este lenguaje en la página Bibliotecas cliente.
Node.js
Antes de probar esta muestra, sigue las instrucciones de configuración para este lenguaje en la página Bibliotecas cliente.
Python
Antes de probar esta muestra, sigue las instrucciones de configuración para este lenguaje en la página Bibliotecas cliente.
Idiomas adicionales
C#: sigue las instrucciones de configuración de C# en la página Bibliotecas cliente y, luego, visita la documentación de referencia de AutoML Vision para .NET.
PHP: sigue las instrucciones de configuración de PHP en la página Bibliotecas cliente y, luego, visita la documentación de referencia de AutoML Vision para PHP.
Ruby: sigue las instrucciones de configuración de Ruby en la página Bibliotecas cliente y, luego, visita la documentación de referencia de AutoML Vision para Ruby.