Setelah membuat model AutoML Vision Edge dan mengekspornya ke bucket Google Cloud Storage, Anda dapat menggunakan layanan RESTful dengan Model AutoML Vision Edge danImage Docker Penyaluran TF.
Hal yang akan Anda buat
Container Docker dapat membantu Anda men-deploy model edge dengan mudah di perangkat yang berbeda. Anda dapat menjalankan model edge dengan memanggil REST API dari container dengan bahasa apa pun yang Anda inginkan, dengan manfaat tambahan karena tidak perlu menginstal dependensi atau menemukan versi TensorFlow yang tepat.
Dalam tutorial ini, Anda akan memiliki pengalaman langkah demi langkah dalam menjalankan model edge di perangkat menggunakan container Docker.
Secara khusus, tutorial ini akan memandu Anda melalui tiga langkah:
- Mendapatkan container yang telah dibangun sebelumnya.
- Menjalankan container dengan model Edge untuk memulai REST API.
- Membuat prediksi.
Banyak perangkat hanya memiliki CPU, sementara beberapa perangkat mungkin memiliki GPU untuk mendapatkan prediksi yang lebih cepat. Jadi, kami menyediakan tutorial dengan container CPU dan GPU yang telah dibangun sebelumnya.
Tujuan
Dalam panduan pengantar menyeluruh ini, Anda akan menggunakan contoh kode untuk:
- Mendapatkan container Docker.
- Mulai REST API menggunakan container Docker dengan model edge.
- Membuat prediksi untuk mendapatkan hasil yang dianalisis.
Sebelum memulai
Untuk menyelesaikan tutorial ini, Anda harus:
- Latih model Edge yang dapat diekspor. Ikuti panduan memulai model perangkat Edge untuk melatih model Edge.
- Ekspor model AutoML Vision Edge. Model ini akan disalurkan dengan container sebagai REST API.
- Instal Docker. Ini adalah perangkat lunak yang diperlukan untuk menjalankan container Docker.
- (Opsional) Instal Docker dan driver NVIDIA. Ini adalah langkah opsional jika Anda memiliki perangkat dengan GPU dan ingin mendapatkan prediksi yang lebih cepat.
- Menyiapkan image pengujian. Gambar-gambar ini akan dikirim dalam permintaan untuk mendapatkan hasil yang dianalisis.
Detail untuk mengekspor model dan menginstal software yang diperlukan dapat dilihat di bagian berikut.
Ekspor Model AutoML Vision Edge
Setelah melatih model Edge, Anda dapat mengekspornya ke perangkat yang berbeda.
Container mendukung model TensorFlow,
yang bernama saved_model.pb
saat diekspor.
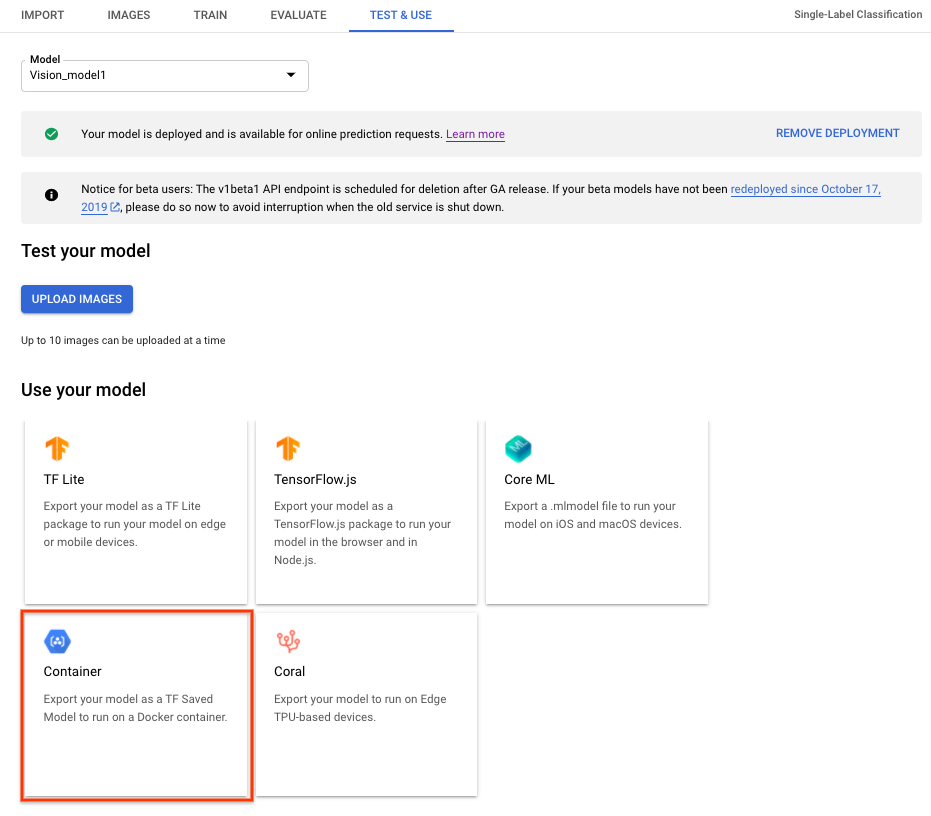
Untuk mengekspor model AutoML Vision Edge untuk container, pilih tab Container di UI, lalu ekspor model ke ${YOUR_MODEL_PATH} di Google Cloud Storage. Model yang diekspor ini akan ditayangkan dengan container sebagai REST API nanti.
Untuk mendownload model yang diekspor secara lokal, jalankan perintah berikut.
Dengan keterangan:
- ${YOUR_MODEL_PATH} - Lokasi model di Google Cloud Storage (misalnya,
gs://my-bucket-vcm/models/edge/ICN4245971651915048908/2020-01-20_01-27-14-064_tf-saved-model/) - ${YOUR_LOCAL_MODEL_PATH} - Jalur lokal
tempat Anda ingin mendownload model (misalnya,
/tmp).
gsutil cp ${YOUR_MODEL_PATH} ${YOUR_LOCAL_MODEL_PATH}/saved_model.pb
Instal Docker
Docker adalah software yang digunakan untuk men-deploy dan menjalankan aplikasi di dalam container.
Instal Docker Community Edition (CE) di sistem Anda. Anda akan menggunakannya untuk menyalurkan model Edge sebagai REST API.
Menginstal Driver NVIDIA dan NVIDIA DOCKER (opsional - khusus untuk GPU)
Beberapa perangkat memiliki GPU untuk memberikan prediksi yang lebih cepat. Container Docker GPU disediakan untuk mendukung GPU NVIDIA.
Untuk menjalankan container GPU, Anda harus menginstal driver NVIDIA dan NVIDIA Docker di sistem Anda.
Menjalankan inferensi model menggunakan CPU
Bagian ini memberikan petunjuk langkah demi langkah untuk menjalankan inferensi model menggunakan container CPU. Anda akan menggunakan Docker yang terinstal untuk mendapatkan dan menjalankan container CPU guna menyalurkan model Edge yang diekspor sebagai REST API, lalu mengirim permintaan gambar pengujian ke REST API untuk mendapatkan hasil yang dianalisis.
Mengambil image Docker
Pertama, Anda akan menggunakan Docker untuk mendapatkan container CPU yang telah dibangun sebelumnya. CPU container yang telah dibangun sebelumnya sudah memiliki keseluruhan lingkungan untuk menyalurkan model Edge yang diekspor, yang belum berisi model Edge apa pun.
Container CPU yang telah dibangun sebelumnya disimpan di Google Container Registry. Sebelum meminta container, tetapkan variabel lingkungan untuk lokasi container di Google Container Registry:
export CPU_DOCKER_GCR_PATH=gcr.io/cloud-devrel-public-resources/gcloud-container-1.14.0:latest
Setelah menetapkan variabel lingkungan untuk jalur Container Registry, jalankan command line berikut untuk mendapatkan container CPU:
sudo docker pull ${CPU_DOCKER_GCR_PATH}
Menjalankan container Docker
Setelah mendapatkan container yang ada, Anda akan menjalankan container CPU ini untuk menayangkan inferensi model Edge dengan REST API.
Sebelum memulai container CPU, Anda harus menetapkan variabel sistem:
- ${CONTAINER_NAME} - String yang menunjukkan nama container saat
dijalankan, misalnya
CONTAINER_NAME=automl_high_accuracy_model_cpu. - ${PORT} - Nomor yang menunjukkan port di perangkat Anda untuk menerima
panggilan REST API nanti, seperti
PORT=8501.
Setelah menetapkan variabel, jalankan Docker di command line untuk menyalurkan inferensi model Edge dengan REST API:
sudo docker run --rm --name ${CONTAINER_NAME} -p ${PORT}:8501 -v ${YOUR_MODEL_PATH}:/tmp/mounted_model/0001 -t ${CPU_DOCKER_GCR_PATH}
Setelah container berhasil berjalan, REST API siap
disalurkan di http://localhost:${PORT}/v1/models/default:predict. Bagian
berikut menjelaskan cara mengirim permintaan prediksi ke lokasi ini.
Mengirim permintaan prediksi
Setelah container berhasil berjalan, Anda dapat mengirim permintaan prediksi pada gambar pengujian ke REST API.
Command-line
Isi permintaan command line berisi berenkode base64 image_bytes dan string key
untuk mengidentifikasi gambar yang diberikan. Lihat topik
Encoding Base64 untuk mengetahui
informasi selengkapnya tentang encoding gambar. Format file JSON yang diminta adalah sebagai berikut:
/tmp/request.json
{
"instances":
[
{
"image_bytes":
{
"b64": "/9j/7QBEUGhvdG9zaG9...base64-encoded-image-content...fXNWzvDEeYxxxzj/Coa6Bax//Z"
},
"key": "your-chosen-image-key"
}
]
}
Setelah membuat file permintaan JSON lokal, Anda dapat mengirim permintaan prediksi.
Gunakan perintah berikut untuk mengirim permintaan prediksi:
curl -X POST -d @/tmp/request.json http://localhost:${PORT}/v1/models/default:predict
Tanggapan
Anda akan melihat output yang mirip dengan berikut ini:
{
"predictions": [
{
"labels": ["Good", "Bad"],
"scores": [0.665018, 0.334982]
}
]
}
Python
Untuk mengetahui informasi selengkapnya, lihat AutoML Vision Python dokumentasi referensi API.
Untuk melakukan autentikasi ke AutoML Vision, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, baca Menyiapkan autentikasi untuk lingkungan pengembangan lokal.
Menjalankan Inferensi Model Menggunakan Container GPU (opsional)
Bagian ini menunjukkan cara menjalankan inferensi model menggunakan container GPU. Proses ini sangat mirip dengan menjalankan inferensi model menggunakan CPU. Perbedaan utamanya adalah jalur container GPU dan cara memulai container GPU.
Mengambil image Docker
Pertama, Anda akan menggunakan Docker untuk mendapatkan container GPU yang telah dibangun sebelumnya. Container GPU telah dibangun sebelumnya sudah memiliki lingkungan untuk menyalurkan model Edge yang diekspor dengan GPU, yang belum berisi model Edge, atau driver apapun.
Container CPU yang telah dibangun sebelumnya disimpan di Google Container Registry. Sebelum meminta container, tetapkan variabel lingkungan untuk lokasi container di Google Container Registry:
export GPU_DOCKER_GCR_PATH=gcr.io/cloud-devrel-public-resources/gcloud-container-1.14.0-gpu:latest
Jalankan command line berikut untuk mendapatkan container GPU:
sudo docker pull ${GPU_DOCKER_GCR_PATH}
Menjalankan container Docker
Langkah ini akan menjalankan container GPU untuk menyalurkan inferensi model Edge dengan REST API. Anda harus menginstal driver dan docker NVIDIA seperti yang disebutkan di atas. Anda juga harus menetapkan variabel sistem berikut ini:
- ${CONTAINER_NAME} - String yang menunjukkan nama container saat
dijalankan, misalnya
CONTAINER_NAME=automl_high_accuracy_model_gpu. - ${PORT} - Nomor yang menunjukkan port di perangkat Anda untuk menerima
panggilan REST API nanti, seperti
PORT=8502.
Setelah menetapkan variabel, jalankan Docker di command line untuk menyalurkan inferensi model Edge dengan REST API:
sudo docker run --runtime=nvidia --rm --name "${CONTAINER_NAME}" -v \
${YOUR_MODEL_PATH}:/tmp/mounted_model/0001 -p \
${PORT}:8501 -t ${GPU_DOCKER_GCR_PATH}
Setelah container berhasil berjalan, REST API siap
ditayangkan di http://localhost:${PORT}/v1/models/default:predict. Bagian
berikut menjelaskan cara mengirim permintaan prediksi ke lokasi ini.
Mengirim permintaan prediksi
Setelah container berhasil berjalan, Anda dapat mengirim permintaan prediksi pada gambar pengujian ke REST API.
Command-line
Isi permintaan command line berisi berenkode base64 image_bytes dan string key
untuk mengidentifikasi gambar yang diberikan. Lihat topik
Encoding Base64 untuk mengetahui
informasi selengkapnya tentang encoding gambar. Format file JSON yang diminta adalah sebagai berikut:
/tmp/request.json
{
"instances":
[
{
"image_bytes":
{
"b64": "/9j/7QBEUGhvdG9zaG9...base64-encoded-image-content...fXNWzvDEeYxxxzj/Coa6Bax//Z"
},
"key": "your-chosen-image-key"
}
]
}
Setelah membuat file permintaan JSON lokal, Anda dapat mengirim permintaan prediksi.
Gunakan perintah berikut untuk mengirim permintaan prediksi:
curl -X POST -d @/tmp/request.json http://localhost:${PORT}/v1/models/default:predict
Tanggapan
Anda akan melihat output yang mirip dengan berikut ini:
{
"predictions": [
{
"labels": ["Good", "Bad"],
"scores": [0.665018, 0.334982]
}
]
}
Python
Untuk mengetahui informasi selengkapnya, lihat AutoML Vision Python dokumentasi referensi API.
Untuk melakukan autentikasi ke AutoML Vision, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, baca Menyiapkan autentikasi untuk lingkungan pengembangan lokal.
Ringkasan
Dalam tutorial ini, Anda telah mempelajari cara menjalankan model Edge menggunakan container Docker CPU atau GPU. Sekarang Anda dapat men-deploy solusi berbasis container ini di lebih banyak perangkat.
Apa Selanjutnya
- Pelajari lebih lanjut tentang TensorFlow secara umum dengan dokumentasi Memulai TensorFlow.
- Pelajari lebih lanjut tentang TensorFlow Serving.
- Pelajari cara menggunakan TensorFlow Serving dengan Kubernetes.