Depois de criar um modelo do AutoML Vision Edge e exportá-lo para um bucket do Google Cloud Storage, use os serviços RESTful com os modelos do AutoML Vision Edge e as imagens do Docker do TF Serving.
O que você criará
Com os contêineres do Docker, você implanta modelos do Edge com facilidade em diferentes dispositivos. Para executar modelos do Edge, chame as APIs REST dos contêineres na linguagem que preferir, com a vantagem de não precisar instalar dependências ou encontrar as versões adequadas do TensorFlow.
Este tutorial apresenta um passo a passo da execução de modelos do Edge em dispositivos que usam contêineres do Docker.
Especificamente, isso inclui três etapas:
- Conseguir contêineres pré-criados.
- Executar contêineres com modelos do Edge para iniciar APIs REST.
- Fazer previsões.
Muitos dispositivos têm apenas CPUs, enquanto alguns incluem GPUs para receber previsões mais rápidas. Portanto, são oferecidos tutoriais com contêineres pré-criados de CPU e GPU.
Objetivos
Neste tutorial completo de introdução, você usará exemplos de código para fazer as ações a seguir:
- Conseguir o contêiner do Docker.
- Iniciar APIs REST usando contêineres do Docker com modelos do Edge.
- Fazer previsões para receber os resultados analisados.
Antes de começar
Veja o que é preciso para concluir este tutorial:
- Treinar um modelo do Edge exportável. Siga o Guia de início rápido do modelo de dispositivo do Edge para treinar um modelo do Edge.
- Exportar um modelo do AutoML Vision Edge. O modelo será veiculado com contêineres como APIs REST.
- Instalar o Docker. Esse é o software necessário para executar os contêineres do Docker.
- Instalar o docker e driver NVIDIA. Essa é uma etapa opcional se você tem dispositivos com GPUs e quer receber previsões mais rápidas.
- Preparar imagens de teste. Você enviará essas imagens nas solicitações para receber resultados analisados.
Veja os detalhes sobre como exportar modelos e instalar o software necessário na próxima seção.
Exportar o modelo do AutoML Vision Edge
Depois de treinar um modelo do Edge, será possível exportá-lo para dispositivos diferentes.
Os contêineres são compatíveis com modelos do TensorFlow, que são denominados saved_model.pb na exportação.
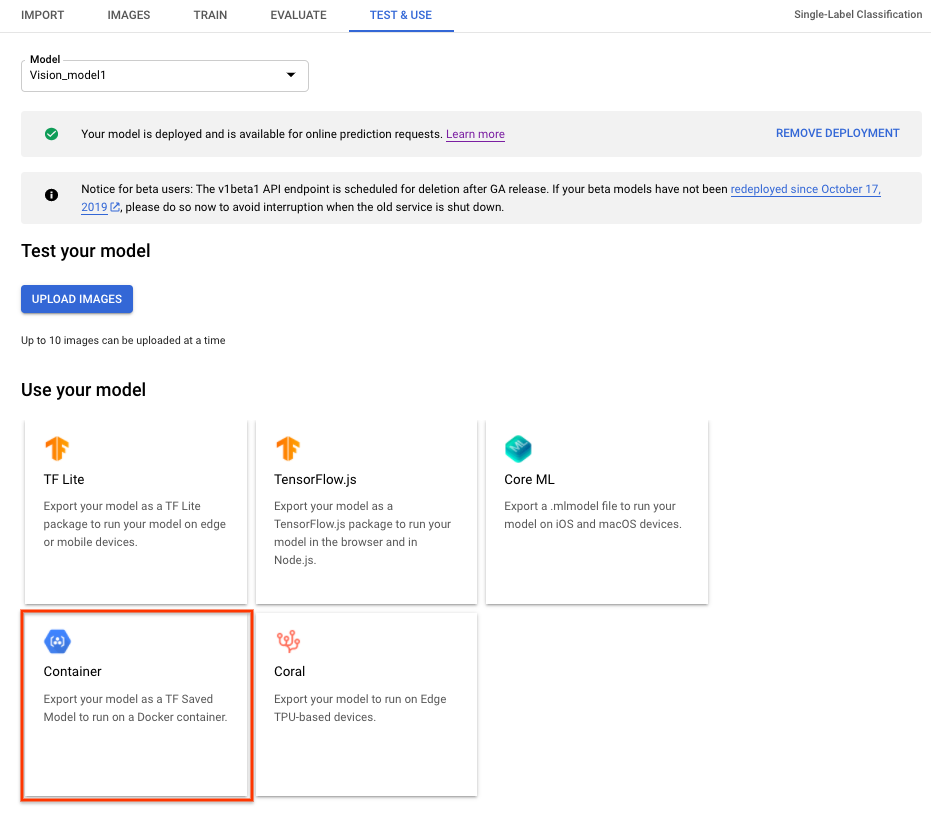
Para exportar um modelo do AutoML Vision Edge para contêineres, selecione a guia Contêiner na IU e exporte o modelo para ${YOUR_MODEL_PATH} no Google Cloud Storage. Esse modelo exportado será exibido com contêineres como APIs REST posteriormente.
Para fazer o download do modelo exportado no local, execute o comando a seguir.
Onde:
- ${YOUR_MODEL_PATH}: o local do modelo no Google Cloud Storage (por exemplo,
gs://my-bucket-vcm/models/edge/ICN4245971651915048908/2020-01-20_01-27-14-064_tf-saved-model/) - ${YOUR_LOCAL_MODEL_PATH}: o caminho local em que você quer fazer o download do modelo (por exemplo,
/tmp).
gsutil cp ${YOUR_MODEL_PATH} ${YOUR_LOCAL_MODEL_PATH}/saved_model.pb
Instalar o Docker
O Docker é um software usado para implantar e executar aplicativos em contêineres.
Instale o Docker Community Edition (CE) no seu sistema. Você usará esse recurso para exibir os modelos do Edge como APIs REST.
Instalar o driver NVIDIA e o NVIDIA DOCKER (opcional, somente para GPU)
Alguns dispositivos têm GPUs para fornecer previsões mais rápidas. O contêiner do Docker de GPU é compatível com as GPUs NVIDIA.
Para executar contêineres de GPU, instale o driver NVIDIA e o Docker NVIDIA no sistema.
Como executar inferência de modelo usando a CPU
Esta seção traz instruções detalhadas para executar inferências de modelo usando contêineres de CPU. Você usará o Docker instalado para conseguir e executar o contêiner de CPU e exibir os modelos do Edge exportados como APIs REST. Depois, você enviará solicitações de uma imagem de teste às APIs REST para receber os resultados analisados.
Extrair a imagem do Docker
Primeiro, você usará o Docker para conseguir um contêiner de CPU pré-criado. Esse contêiner já tem o ambiente completo para veicular os modelos do Edge exportados, mas ele ainda não contém nenhum modelo do Edge.
O contêiner de CPU pré-criado é armazenado no Google Container Registry. Antes de solicitar o contêiner, defina uma variável de ambiente no local do contêiner no Google Container Registry:
export CPU_DOCKER_GCR_PATH=gcr.io/cloud-devrel-public-resources/gcloud-container-1.14.0:latest
Depois de definir a variável de ambiente do caminho do Container Registry, execute a seguinte linha de comando para conseguir o contêiner de CPU:
sudo docker pull ${CPU_DOCKER_GCR_PATH}
Executar o contêiner do Docker
Depois de conseguir o contêiner atual, execute esse contêiner de CPU para exibir as inferências de modelo do Edge com as APIs REST.
Antes de iniciar o contêiner de CPU, você precisa definir as variáveis do sistema:
- ${CONTAINER_NAME} - uma string que indica o nome do contêiner quando executado, por exemplo,
CONTAINER_NAME=automl_high_accuracy_model_cpu. - ${PORT} - um número que indica a porta no seu dispositivo para aceitar chamadas de API REST posteriormente, como
PORT=8501.
Depois de definir as variáveis, execute o Docker na linha de comando para exibir as inferências de modelo do Edge com as APIs REST:
sudo docker run --rm --name ${CONTAINER_NAME} -p ${PORT}:8501 -v ${YOUR_MODEL_PATH}:/tmp/mounted_model/0001 -t ${CPU_DOCKER_GCR_PATH}
Depois que o contêiner estiver em execução, as APIs REST estarão prontas para exibição em http://localhost:${PORT}/v1/models/default:predict. Veja
na seção a seguir como enviar solicitações de previsão para esse local.
Enviar uma solicitação de previsão
Agora que o contêiner está sendo executado com êxito, é possível enviar uma solicitação de previsão de uma imagem de teste para as APIs REST.
Linha de comando
O corpo da solicitação da linha de comando contém image_bytes codificados em base64 e uma key
de string para identificar a imagem especificada. Saiba mais
sobre codificação de imagens no tópico
Codificação em base64. Este é o formato do arquivo JSON da solicitação:
/tmp/request.json
{
"instances":
[
{
"image_bytes":
{
"b64": "/9j/7QBEUGhvdG9zaG9...base64-encoded-image-content...fXNWzvDEeYxxxzj/Coa6Bax//Z"
},
"key": "your-chosen-image-key"
}
]
}
Depois de criar um arquivo de solicitação JSON local, você pode enviar sua solicitação de previsão.
Use este comando para enviar a solicitação de previsão:
curl -X POST -d @/tmp/request.json http://localhost:${PORT}/v1/models/default:predict
Resposta
A resposta será semelhante a esta:
{
"predictions": [
{
"labels": ["Good", "Bad"],
"scores": [0.665018, 0.334982]
}
]
}
Python
Para mais informações, consulte a documentação de referência da API da AutoML VisionPython.
Para autenticar no AutoML Vision, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
Executar a inferência de modelo usando contêineres de GPU (opcional)
Veja nesta seção como executar inferências de modelo usando contêineres de GPU. Esse processo é muito semelhante à execução de inferência de modelo usando uma CPU. As principais diferenças são o caminho do contêiner de GPU e como você inicia esse tipo de contêiner.
Extrair a imagem do Docker
Primeiro, você usará o Docker para conseguir um contêiner de GPU pré-criado. Esse contêiner já tem o ambiente para veicular os modelos do Edge exportados com GPUs, mas ainda não contém nenhum modelo do Edge ou os drivers.
O contêiner de CPU pré-criado é armazenado no Google Container Registry. Antes de solicitar o contêiner, defina uma variável de ambiente no local do contêiner no Google Container Registry:
export GPU_DOCKER_GCR_PATH=gcr.io/cloud-devrel-public-resources/gcloud-container-1.14.0-gpu:latest
Execute a linha de comando a seguir para conseguir o contêiner de GPU:
sudo docker pull ${GPU_DOCKER_GCR_PATH}
Executar o contêiner do Docker
Nesta etapa, o contêiner de GPU será executado para exibir as inferências de modelo do Edge com as APIs REST. É necessário instalar o driver e o docker NVIDIA, conforme mencionado acima. Você também precisa definir as variáveis de sistema a seguir:
- ${CONTAINER_NAME} - uma string que indica o nome do contêiner quando executado, por exemplo,
CONTAINER_NAME=automl_high_accuracy_model_gpu. - ${PORT} - um número que indica a porta no seu dispositivo para aceitar chamadas de API REST posteriormente, como
PORT=8502.
Depois de definir as variáveis, execute o Docker na linha de comando para exibir as inferências de modelo do Edge com as APIs REST:
sudo docker run --runtime=nvidia --rm --name "${CONTAINER_NAME}" -v \
${YOUR_MODEL_PATH}:/tmp/mounted_model/0001 -p \
${PORT}:8501 -t ${GPU_DOCKER_GCR_PATH}
Depois que o contêiner estiver em execução, as APIs REST estarão prontas para exibição em http://localhost:${PORT}/v1/models/default:predict. Veja
na seção a seguir como enviar solicitações de previsão para esse local.
Enviar uma solicitação de previsão
Agora que o contêiner está sendo executado com êxito, é possível enviar uma solicitação de previsão de uma imagem de teste para as APIs REST.
Linha de comando
O corpo da solicitação da linha de comando contém image_bytes codificados em base64 e uma key
de string para identificar a imagem especificada. Saiba mais
sobre codificação de imagens no tópico
Codificação em base64. Este é o formato do arquivo JSON da solicitação:
/tmp/request.json
{
"instances":
[
{
"image_bytes":
{
"b64": "/9j/7QBEUGhvdG9zaG9...base64-encoded-image-content...fXNWzvDEeYxxxzj/Coa6Bax//Z"
},
"key": "your-chosen-image-key"
}
]
}
Depois de criar um arquivo de solicitação JSON local, você pode enviar sua solicitação de previsão.
Use este comando para enviar a solicitação de previsão:
curl -X POST -d @/tmp/request.json http://localhost:${PORT}/v1/models/default:predict
Resposta
A resposta será semelhante a esta:
{
"predictions": [
{
"labels": ["Good", "Bad"],
"scores": [0.665018, 0.334982]
}
]
}
Python
Para mais informações, consulte a documentação de referência da API da AutoML VisionPython.
Para autenticar no AutoML Vision, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
Resumo
Neste tutorial, você viu como executar modelos do Edge usando contêineres do Docker de CPU ou GPU. Agora você pode implantar em outros dispositivos essa solução baseada em contêineres.
A seguir
- Saiba mais sobre o TensorFlow, em geral, na documentação de primeiros passos (em inglês) do produto.
- Saiba mais sobre o Tensorflow Serving (em inglês).
- Saiba como usar o TensorFlow Serving com o Kubernetes (em inglês).