评估模型
训练完模型后,AutoML Video Intelligence 对象跟踪会使用测试集中的内容来评估新模型的质量和准确率。
AutoML Video Intelligence 对象跟踪提供了一组总体评估指标以及针对每个类别标签的评估指标;前者指示模型的整体表现,后者指示模型在该标签上的表现。
IoU:Intersection over Union,一种在对象跟踪中使用的指标,作用是测量视频帧中对象实例的预测边界框与实际边界框的重叠度。预测的边界框值与实际的边界框值越接近,交集和 IoU 值越大。
AuPRC:精确率/召回率曲线下的面积,亦称为“平均精确率”。通常介于 0.5 和 1.0 之间。数值越高,表示模型越准确。
置信度阈值曲线显示不同的置信度阈值对精确率、召回率、真正例率和假正例率有何影响。请了解精确率和召回率的关系。
您可利用这些数据来评估您的模型的就绪情况。如果 AUC 得分低,或者精确率和召回率得分低,这可能表明您的模型需要额外的训练数据或者模型标签不一致。如果 AUC 得分非常高,并且精确率和召回率也很完美,这可能表明数据过于简单,模型可能无法有效泛化。
获取模型评估值
网页界面
-
在 AutoML Video 对象跟踪界面中打开模型页面。
-
点击待评估模型所在的行。
-
点击评估标签。
如果该模型已完成训练,则 AutoML Video Object Tracking 会显示其评估指标。
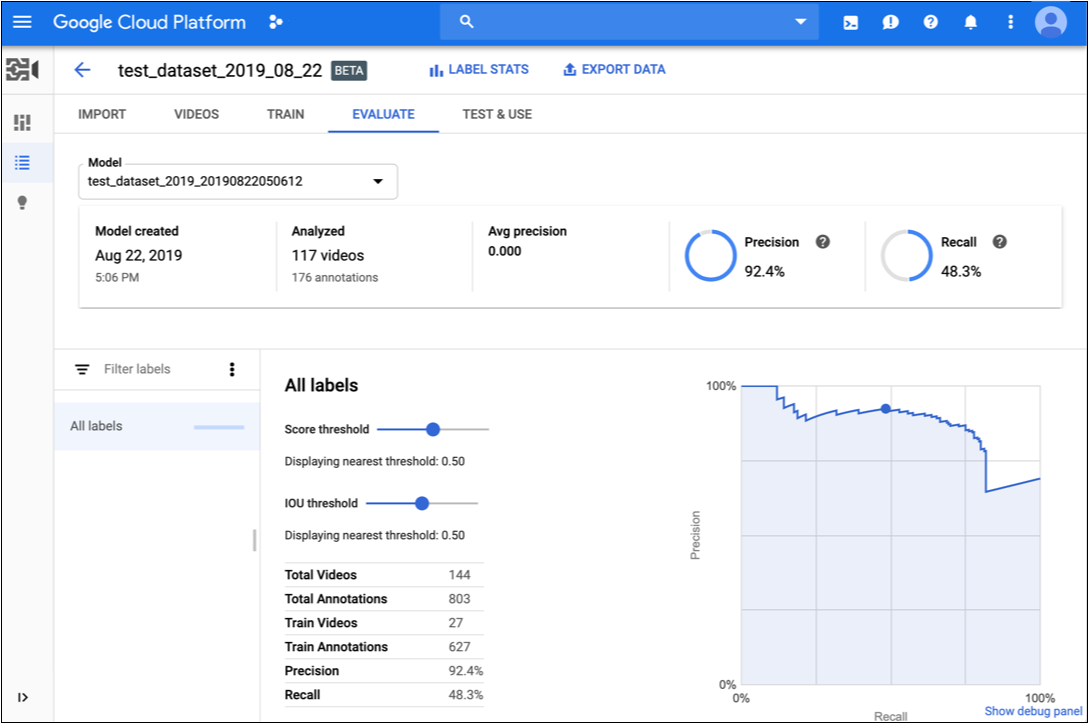
- 如需查看特定标签的指标,请从页面下部的标签列表中选择标签名称。
REST
在使用任何请求数据之前,请先进行以下替换:
- model-id:将替换为模型的标识符
- project-number:您项目的编号
- location-id:在其中添加注解的 Cloud 区域。支持的云区域为:
us-east1、us-west1、europe-west1、asia-east1。如果未指定区域,系统将根据视频文件位置确定区域。
HTTP 方法和网址:
GET https://automl.googleapis.com/v1beta1/projects/project-number/locations/location-id/models/model-id:modelEvaluations
如需发送请求,请选择以下方式之一:
curl
执行以下命令:
curl -X GET \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "x-goog-user-project: project-number" \
"https://automl.googleapis.com/v1beta1/projects/project-number/locations/location-id/models/model-id:modelEvaluations"
PowerShell
执行以下命令:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred"; "x-goog-user-project" = "project-number" }
Invoke-WebRequest `
-Method GET `
-Headers $headers `
-Uri "https://automl.googleapis.com/v1beta1/projects/project-number/locations/location-id/models/model-id:modelEvaluations" | Select-Object -Expand Content
8703337066443674578。
Java
如需向 AutoML Video Object Tracking 进行身份验证,请设置应用默认凭据。如需了解详情,请参阅为本地开发环境设置身份验证。
Node.js
如需向 AutoML Video Object Tracking 进行身份验证,请设置应用默认凭据。如需了解详情,请参阅为本地开发环境设置身份验证。
Python
如需向 AutoML Video Object Tracking 进行身份验证,请设置应用默认凭据。如需了解详情,请参阅为本地开发环境设置身份验证。
迭代模型
如果您对质量水平不满意,则可以重新执行前述步骤以提高质量:
- 您可能需要添加不同类型的视频(例如更宽的角度、更高或更低的分辨率、不同的视角)。
- 如果您没有足够多的训练视频,请考虑完全移除相应标签。
- 请记住,机器无法读取您的标签名称;对于机器而言,这只是一串随机的字母。如果您有一个名为“door”的标签和另一个名为“door_with_knob”的标签,那么除了您提供给它的视频以外,机器无法厘清二者的细微差别。
- 用更多的真正例和真负例示例来扩充您的数据。 那些接近决策边界的示例尤为重要。
一旦进行了更改,请训练并评估新模型,直到达到足够高的质量水平为止。