Introdução
Imagine que você é o técnico de um time de futebol. Você tem uma grande biblioteca com vídeos das partidas, usada para estudar os pontos fortes e fracos da sua equipe. Compilar em um único vídeo as ações como gols, faltas e pênaltis de muitos jogos é uma ideia incrível. No entanto, há centenas de horas de vídeo para analisar e muitas ações para acompanhar. Assistir a todos os vídeos e marcar manualmente os segmentos para destacar cada ação é um trabalho tedioso e demorado. E você precisa fazer isso para cada campeonato. Não seria mais fácil ensinar um computador a identificar e sinalizar automaticamente essas ações sempre que elas aparecerem em um vídeo?
Por que o machine learning (ML) é a ferramenta certa para esse problema?
 A programação clássica exige que um programador especifique instruções detalhadas que serão seguidas pelo computador. Mas considere o caso de uso de identificar ações específicas
em jogos de futebol. Há tanta variação de cor, ângulo, resolução e
iluminação que exigiria codificação de muitas regras para dizer a uma máquina como
tomar a decisão correta. É difícil imaginar por onde você começaria.
Felizmente, o machine learning está bem preparado para resolver esse problema.
A programação clássica exige que um programador especifique instruções detalhadas que serão seguidas pelo computador. Mas considere o caso de uso de identificar ações específicas
em jogos de futebol. Há tanta variação de cor, ângulo, resolução e
iluminação que exigiria codificação de muitas regras para dizer a uma máquina como
tomar a decisão correta. É difícil imaginar por onde você começaria.
Felizmente, o machine learning está bem preparado para resolver esse problema.
Neste guia, você vê como a classificação do AutoML Video Intelligence resolve esse problema, além de conhecer o fluxo de trabalho da ferramenta e os outros tipos de problemas que ela soluciona.
Como funciona a classificação do AutoML Video Intelligence?
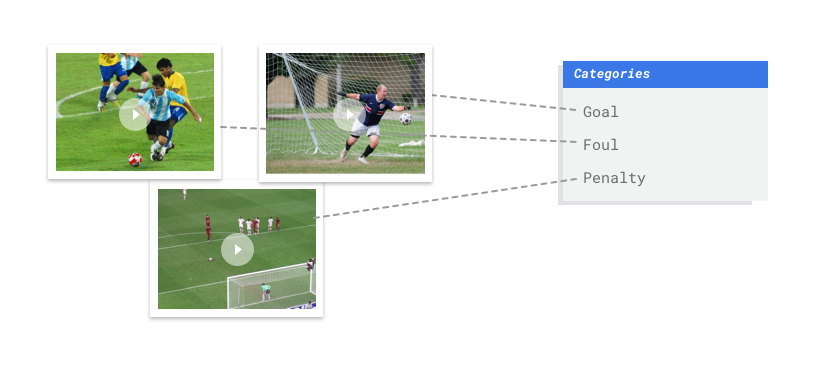
 A classificação AutoML Video Intelligence é uma tarefa de aprendizado supervisionado. Ou seja, você treina, testa e valida o modelo de machine learning com exemplos de vídeos já rotulados. Com um modelo treinado, é possível inserir novos vídeos para o modelo produzir segmentos rotulados. O rótulo é uma "resposta" prevista do modelo. Por exemplo, em um modelo treinado para o caso de uso do futebol, você consegue inserir novos vídeos do esporte e gerar segmentos rotulados que descrevem cenas de ações como "gol", "falta" e assim por diante.
A classificação AutoML Video Intelligence é uma tarefa de aprendizado supervisionado. Ou seja, você treina, testa e valida o modelo de machine learning com exemplos de vídeos já rotulados. Com um modelo treinado, é possível inserir novos vídeos para o modelo produzir segmentos rotulados. O rótulo é uma "resposta" prevista do modelo. Por exemplo, em um modelo treinado para o caso de uso do futebol, você consegue inserir novos vídeos do esporte e gerar segmentos rotulados que descrevem cenas de ações como "gol", "falta" e assim por diante.
Fluxo de trabalho da classificação do AutoML Video Intelligence
A classificação do AutoML Video Intelligence usa um fluxo de trabalho padrão de machine learning:
- Coleta de dados: determine os dados necessários para treinar e testar o modelo com base no resultado pretendido.
- Preparação dos dados: verifique se eles estão formatados e rotulados corretamente.
- Treinamento: defina os parâmetros e crie o modelo.
- Avaliação: analise as métricas do modelo.
- Implantação e previsão: disponibilize o modelo para uso.
Antes de começar a coletar os dados, é preciso pensar no problema que você está tentando resolver. Isso determina os requisitos dos dados.
Pense no caso de uso

Comece com seu problema: qual é o resultado que você quer alcançar? Quantas classes você precisa prever? A classe é algo que você ensina o modelo a identificar. Ela é representada na saída do modelo como um rótulo. Por exemplo, um modelo de detecção de bolas terá duas classes: "com bola" e "sem bola".
Dependendo das respostas, a classificação do AutoML Video Intelligence cria o modelo necessário para o caso de uso:
Um modelo de classificação binária prevê um resultado binário, ou seja, que tenha duas classes. Use-o nas perguntas do tipo "sim" ou "não". Por exemplo, ao identificar apenas os gols em um jogo de futebol ("Isso é um gol ou não?). Em geral, um problema de classificação binária requer menos dados de vídeo no treinamento do que outros.
Um modelo de classificação multiclasse prevê uma classe entre duas ou mais diferentes. Use-o para categorizar segmentos de vídeo. Por exemplo, ao classificar os segmentos de uma biblioteca de vídeos das Olimpíadas para descobrir qual esporte está sendo mostrado em um determinado momento. A saída fornece segmentos de vídeo com um único rótulo atribuído, como "natação" ou "ginástica".
Um modelo de classificação com vários rótulos prevê uma ou mais classes de várias possíveis. Use-o para rotular várias classes em um único segmento de vídeo. Esse tipo de problema geralmente requer mais dados de treinamento porque a distinção entre muitas classes é mais complexa.
O exemplo anterior do futebol requer um modo de classificação com vários rótulos. Isso acontece porque as classes (ações como gols, faltas etc.) podem ocorrer simultaneamente, o que significa que um único segmento pode exigir vários rótulos.
Uma observação sobre imparcialidade
A imparcialidade é uma das práticas de responsabilidade de IA do Google. O objetivo da imparcialidade é entender e prevenir o tratamento injusto ou preconceituoso de pessoas relacionado a raça, renda, orientação sexual, religião, gênero e outras características historicamente associadas à discriminação e marginalização, sempre que se manifestarem em sistemas algorítmicos ou na tomada de decisões auxiliada por algoritmos. Mais adiante neste guia você verá observações sobre imparcialidade, em que se discute como criar um modelo de machine learning mais justo. Saiba mais
Coletar dados
 Depois de estabelecer o caso de uso, é preciso coletar os dados de vídeo para criar o modelo pretendido. Os dados coletados para treinamento
informam o tipo de problemas que podem ser resolvidos. Quantos vídeos você pode usar? Os vídeos contêm exemplos suficientes para as classes que você quer que seu modelo preveja? Ao coletar os dados do seu vídeo, lembre-se das considerações a seguir.
Depois de estabelecer o caso de uso, é preciso coletar os dados de vídeo para criar o modelo pretendido. Os dados coletados para treinamento
informam o tipo de problemas que podem ser resolvidos. Quantos vídeos você pode usar? Os vídeos contêm exemplos suficientes para as classes que você quer que seu modelo preveja? Ao coletar os dados do seu vídeo, lembre-se das considerações a seguir.
Inclua vídeos suficientes
 Geralmente, quanto mais vídeos de treinamento no conjunto de dados, melhor o resultado. O número de vídeos recomendados também é determinado pel a complexidade do problema que você está tentando resolver. Por exemplo, você precisa de menos dados de vídeo em um problema de classificação binária, que prevê uma classe entre duas opções, do que em um problema com vários rótulos, que prevê uma ou mais classes de muitas delas.
Geralmente, quanto mais vídeos de treinamento no conjunto de dados, melhor o resultado. O número de vídeos recomendados também é determinado pel a complexidade do problema que você está tentando resolver. Por exemplo, você precisa de menos dados de vídeo em um problema de classificação binária, que prevê uma classe entre duas opções, do que em um problema com vários rótulos, que prevê uma ou mais classes de muitas delas.
A complexidade do que você está tentando classificar também indica a quantidade necessária de dados de vídeo. Pense no caso de uso do futebol, em que é criado um modelo para diferenciar cenas de ações. Compare esse caso com um modelo que diferencia espécies de beija-flor. Leve em conta as nuances e as semelhanças na cor, tamanho e forma: você precisa de mais dados de treinamento para que o modelo aprenda a identificar cada espécie com precisão.
Use essas regras como um valor de referência para entender as necessidades básicas de dados de vídeo:
- Tenha 200 exemplos de vídeo por classe se você tiver poucas classes e elas forem diferentes.
- Tenha mais de 1.000 exemplos de vídeo por classe se você tiver mais de 50 classes ou se elas forem parecidas.
Talvez a quantidade de dados de vídeo necessária seja maior do que a atual. É possível conseguir mais vídeos por meio de um fornecedor terceirizado. Por exemplo, compre ou consiga mais vídeos de futebol se você não tiver o suficiente para o modelo identificador de ações.
Distribua vídeos igualmente entre as classes
Forneça um número similar de exemplos de treinamento para cada classe. O motivo é simples: imagine que 80% do conjunto de dados de treinamento sejam vídeos de futebol com tiros de meta, mas apenas 20% deles retratem faltas ou cobranças de pênalti. Com uma distribuição tão desigual de classes, é mais provável que o modelo preveja que uma determinada ação é um gol. Isso é parecido com criar um teste de múltipla escolha em que 80% das respostas corretas são “C”: o modelo mais aprimorado descobrirá rapidamente que “C” é um bom palpite na maioria das vezes.

Talvez não seja possível fornecer um número igual de vídeos para cada classe. Os exemplos imparciais e de alta qualidade também podem ser complicados em algumas classes. Basta seguir uma proporção de 1:10: se a maior classe tiver 10.000 vídeos, a menor terá pelo menos 1.000.
Capture variações
Os dados de vídeo precisam capturar a diversidade do espaço do seu problema. Quanto mais exemplos diversos um modelo vê durante o treinamento, mais imediatamente ele pode generalizar para exemplos novos ou menos comuns. Pense no modelo de classificação de ações de futebol: você precisa incluir vídeos com vários ângulos de filmagem, horários de dia e à noite e muitas jogadas. Expor o modelo a dados variados melhora a capacidade dele de distinguir uma ação da outra.
Relacione os dados ao resultado pretendido

Encontre vídeos de treinamento que sejam visualmente semelhantes aos que você planeja inserir no modelo de predição. Por exemplo, se todos os vídeos de treinamento foram filmados no inverno ou à noite, os padrões de iluminação e cores nesses ambientes afetarão o modelo. Se você usá-lo para testar vídeos filmados no verão ou à luz do dia, talvez não receba predições precisas.
Considere estes outros fatores: * Resolução do vídeo * Quadros por segundo * Ângulo de filmagem * Plano de fundo
Preparação dos dados

Depois de coletar os vídeos que você quer incluir no conjunto de dados, verifique se eles contêm caixas delimitadoras com rótulos para que o modelo saiba o que procurar.
Por que meus vídeos precisam de caixas delimitadoras e rótulos?
Sabe como um modelo da classificação do AutoML Video Intelligence aprende a identificar padrões? Essa é a função das caixas delimitadoras e rótulos durante o treinamento. Pense no exemplo do futebol: cada vídeo precisa conter caixas delimitadoras ao redor das cenas de ações. As caixas também precisam de rótulos como "gol", "falta" e "pênalti" atribuídos a elas. Caso contrário, o modelo não saberá o que procurar. Desenhar caixas e atribuir rótulos aos exemplos de vídeos pode demorar. Se necessário, use um serviço de rotulagem para terceirizar o trabalho.
Treinamento do modelo
Depois que os dados de vídeo do treinamento estiverem prontos, será possível criar um modelo de machine learning. Use o mesmo conjunto de dados para criar modelos diferentes, mesmo que eles tenham tipos de problemas distintos.
Um dos benefícios da classificação do AutoML Video Intelligence é que os parâmetros padrão guiam você para um modelo de machine learning confiável. No entanto, talvez você precise ajustá-los dependendo da qualidade dos dados e do resultado pretendido. Exemplo:
- Tipo de predição (o nível de granularidade em que os vídeos são processados)
- Taxa de quadros
- Resolução
Avaliar o modelo
 Após o treinamento do modelo, você receberá um resumo do desempenho dele. As métricas de avaliação são baseadas no desempenho do modelo em relação a uma fração do conjunto de dados (o conjunto de dados de validação). Há algumas métricas e conceitos importantes a serem considerados ao determinar se o modelo está pronto para ser usado em dados reais.
Após o treinamento do modelo, você receberá um resumo do desempenho dele. As métricas de avaliação são baseadas no desempenho do modelo em relação a uma fração do conjunto de dados (o conjunto de dados de validação). Há algumas métricas e conceitos importantes a serem considerados ao determinar se o modelo está pronto para ser usado em dados reais.
Limite de pontuação
Como um modelo de machine learning sabe quando um gol é realmente um gol? A cada predição, é atribuída uma pontuação de confiança: uma avaliação numérica da certeza do modelo de que um determinado segmento de vídeo contém uma classe. O limite de pontuação é o número que determina quando uma certa pontuação é convertida em "sim" ou "não". Ou seja, o valor em que o modelo diz "sim, esse número de confiança é alto o suficiente para concluir que o segmento de vídeo contém um gol".

Se o limite de pontuação for baixo, o modelo correrá o risco de rotular incorretamente os segmentos de vídeo. Por isso, o limite precisa se basear nos casos de uso. Imagine um caso de uso médico como o diagnóstico de câncer. As consequências da rotulagem incorreta são piores do que em vídeos esportivos. No diagnóstico de câncer, um limite de pontuação mais alto é o adequado.
Resultados da predição
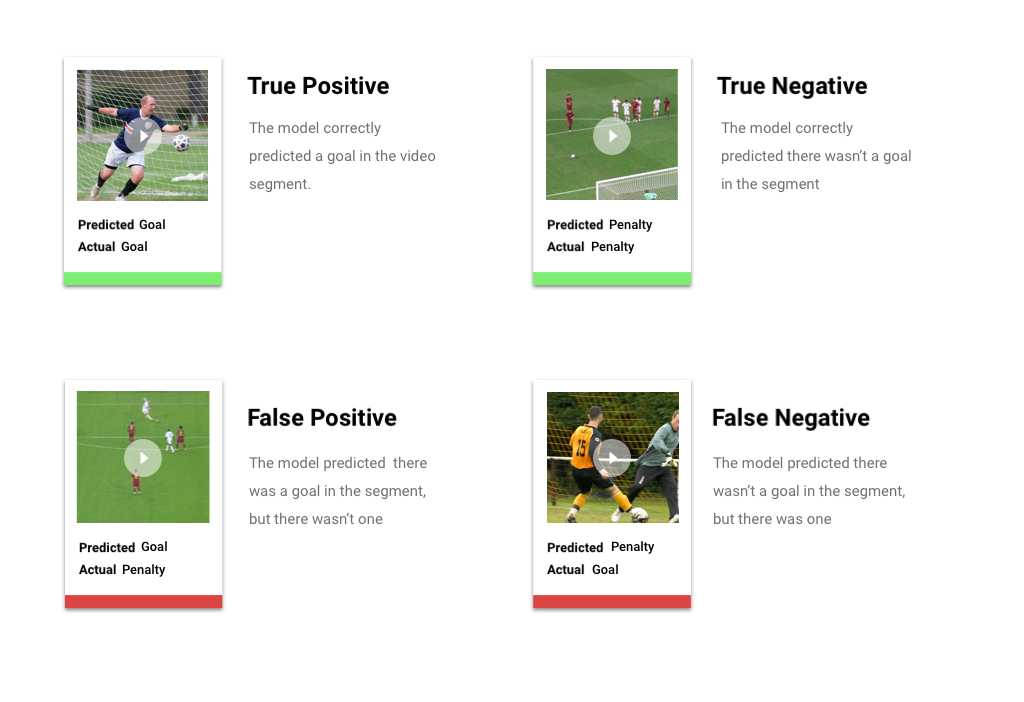
Depois de aplicar o limite de pontuação, as predições feitas pelo modelo são colocadas em uma de quatro categorias. Para entendê-las, vamos imaginar que você criou um modelo para detectar se um determinado segmento contém um gol. Nesse exemplo, um gol é a classe positiva ou o que o modelo está tentando prever.
- Verdadeiro positivo: o modelo prevê corretamente a classe positiva, ou seja, um gol no segmento de vídeo.
- Falso positivo: o modelo prevê incorretamente a classe positiva. Um gol é encontrado no segmento, mas essa ação não estava lá.
- Verdadeiro negativo: o modelo prevê corretamente a classe negativa, ou seja, que não havia um gol no segmento.
- Falso negativo: o modelo prevê incorretamente uma classe negativa. Ele mostra que não tinha um gol no segmento quando realmente havia.
Precisão e recall
Com as métricas de precisão e recall, é possível entender o desempenho do modelo na captura de informações e o quanto ele não está considerando. Saiba mais sobre precisão e recall.
- A precisão é a fração das predições positivas que estava correta. De todas as predições rotuladas como "gol", qual fração realmente continha um?
- O recall é a fração de todas as predições positivas que foi realmente identificada. De todos os gols identificados, qual era a fração?
Dependendo do caso de uso, talvez seja preciso otimizar a precisão ou o recall. Veja os exemplos a seguir:
Caso de uso: informações particulares em vídeos
Imagine que você esteja criando um software que detecta automaticamente informações confidenciais em um vídeo e as desfoca. Os resultados falsos podem incluir o seguinte:
- Um falso positivo identifica algo que não precisa ser desfocado, mas que é censurado mesmo assim. Isso pode ser um incômodo, mas não é algo prejudicial.

- Um falso negativo não identifica informações que precisam ser censuradas, como um número de cartão de crédito. Isso vaza informações particulares e é a pior das hipóteses.
Nesse caso de uso, é essencial otimizar o recall para garantir que o modelo encontre todos os casos relevantes. É mais provável que um modelo otimizado para recall rotule exemplos pouco relevantes e também os incorretos, desfocando mais do que o necessário.
Caso de uso: pesquisa de vídeos salvos
Digamos que você queira criar um software que permita aos usuários pesquisar em uma biblioteca de vídeos com base em uma palavra-chave. Veja os resultados incorretos:
- Um falso positivo retorna um vídeo irrelevante. Como o sistema está tentando fornecer apenas vídeos relevantes, o software não está realmente fazendo o que foi criado para fazer.

- Um falso negativo não retorna um vídeo relevante. Como muitas palavras-chave têm centenas de vídeos, esse problema não é tão ruim quanto retornar um resultado irrelevante.

Nesse exemplo, é bom otimizar a precisão para garantir que o modelo forneça resultados corretos e altamente relevantes. Um modelo de alta precisão provavelmente rotulará apenas os exemplos mais relevantes, mas pode deixar alguns de fora. Saiba mais sobre as métricas de avaliação de modelos.
Implantar seu modelo
 Quando o desempenho for satisfatório para você, é hora de usar o modelo.
A classificalçao do AutoML Video Intelligence utiliza predições em lote, que possibilitam o upload de um arquivo CSV com caminhos de arquivos para vídeos hospedados no Cloud Storage. O modelo processará cada vídeo e predição de saída em outro arquivo CSV. A predição em lote é assíncrona, indicando que o modelo processará todas as solicitações antes de gerar os resultados.
Quando o desempenho for satisfatório para você, é hora de usar o modelo.
A classificalçao do AutoML Video Intelligence utiliza predições em lote, que possibilitam o upload de um arquivo CSV com caminhos de arquivos para vídeos hospedados no Cloud Storage. O modelo processará cada vídeo e predição de saída em outro arquivo CSV. A predição em lote é assíncrona, indicando que o modelo processará todas as solicitações antes de gerar os resultados.