Pengantar
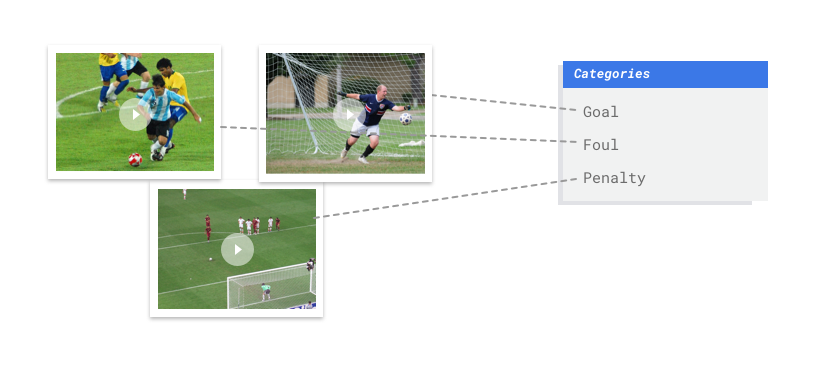
Bayangkan Anda adalah seorang pelatih di tim sepak bola. Anda memiliki banyak koleksi video game yang ingin digunakan untuk mempelajari kekuatan dan kelemahan tim Anda. Akan sangat berguna untuk menggabungkan berbagai tindakan seperti melakukan gol, melakukan foul, dan tendangan penalti dari beberapa pertandingan ke dalam satu video. Tapi ada ratusan jam video untuk ditinjau dan banyak tindakan untuk dilacak. Pekerjaan menonton setiap video dan menandai segmen secara manual untuk menyoroti setiap tindakan adalah hal yang membosankan dan memakan waktu. Dan Anda harus melakukan hal ini untuk setiap musim. Bukankah lebih mudah untuk mengajari komputer untuk otomatis mengidentifikasi dan menandai tindakan ini setiap kali muncul dalam video?
Mengapa Machine Learning (ML) merupakan alat yang tepat untuk masalah ini?
 Pemrograman klasik mengharuskan programmer untuk menentukan petunjuk langkah demi langkah
agar dapat diikuti komputer. Namun, pertimbangkan kasus penggunaan mengidentifikasi tindakan spesifik
dalam game sepak bola. Terdapat begitu banyak variasi warna, sudut, resolusi, dan pencahayaan yang akan mengharuskan coding terlalu banyak aturan untuk memberi tahu mesin cara membuat keputusan yang benar. Sulit untuk membayangkan dari mana
Anda akan memulai.
Untungnya, machine learning ditempatkan dengan baik untuk menyelesaikan masalah ini.
Pemrograman klasik mengharuskan programmer untuk menentukan petunjuk langkah demi langkah
agar dapat diikuti komputer. Namun, pertimbangkan kasus penggunaan mengidentifikasi tindakan spesifik
dalam game sepak bola. Terdapat begitu banyak variasi warna, sudut, resolusi, dan pencahayaan yang akan mengharuskan coding terlalu banyak aturan untuk memberi tahu mesin cara membuat keputusan yang benar. Sulit untuk membayangkan dari mana
Anda akan memulai.
Untungnya, machine learning ditempatkan dengan baik untuk menyelesaikan masalah ini.
Panduan ini membimbing Anda untuk memahami bagaimana AutoML Video Intelligence Classification dapat menyelesaikan masalah ini, alur kerjanya, dan jenis masalah lain yang dirancang untuk dipecahkan.
Bagaimana cara kerja AutoML Video Intelligence Classification?
 AutoML Video Intelligence Classification adalah tugas supervised learning. Ini berarti Anda melatih, menguji, dan memvalidasi model machine learning dengan contoh video yang sudah diberi label. Dengan model terlatih, Anda dapat memasukkan video baru, lalu model akan menghasilkan output segmen video dengan label. Label adalah "jawaban" yang diprediksi dari model. Misalnya, model terlatih untuk kasus penggunaan sepak bola akan memungkinkan Anda memasukkan video sepak bola baru dan segmen video output dengan label yang menjelaskan rekaman aksi seperti "sasaran", "pelanggaran pribadi", dan sebagainya.
AutoML Video Intelligence Classification adalah tugas supervised learning. Ini berarti Anda melatih, menguji, dan memvalidasi model machine learning dengan contoh video yang sudah diberi label. Dengan model terlatih, Anda dapat memasukkan video baru, lalu model akan menghasilkan output segmen video dengan label. Label adalah "jawaban" yang diprediksi dari model. Misalnya, model terlatih untuk kasus penggunaan sepak bola akan memungkinkan Anda memasukkan video sepak bola baru dan segmen video output dengan label yang menjelaskan rekaman aksi seperti "sasaran", "pelanggaran pribadi", dan sebagainya.
Alur kerja AutoML Video Intelligence Classification
AutoML Video Intelligence Classification menggunakan alur kerja machine learning standar:
- Mengumpulkan data Anda: Tentukan data yang diperlukan untuk melatih dan menguji model Anda berdasarkan hasil yang ingin Anda capai.
- Siapkan data Anda: Pastikan data Anda diformat dan diberi label dengan benar.
- Train: Menetapkan parameter dan membuat model.
- Evaluasi: Tinjau metrik model.
- Deploy dan prediksi: Membuat model Anda tersedia untuk digunakan.
Tetapi sebelum mulai mengumpulkan data, Anda perlu memikirkan masalah yang ingin Anda pecahkan, yang akan menentukan persyaratan data Anda.
Mempertimbangkan kasus penggunaan Anda

Mulailah dengan masalah Anda: Apa hasil yang ingin Anda capai? Berapa banyak class yang perlu Anda prediksi? Class adalah sesuatu yang Anda inginkan agar dipelajari model Anda cara mengidentifikasi dan direpresentasikan dalam output model sebagai label (misalnya, model deteksi bola akan memiliki dua class: "ball" dan "no ball").
Bergantung pada jawaban Anda, AutoML Video Intelligence Classification akan membuat model yang diperlukan untuk menyelesaikan kasus penggunaan Anda:
Model klasifikasi biner memprediksi hasil biner (salah satu dari dua class). Gunakan ini untuk pertanyaan ya atau tidak, misalnya, hanya mengidentifikasi gol dalam pertandingan sepak bola ("Apakah ini gol atau bukan gol?"). Secara umum, masalah klasifikasi biner memerlukan lebih sedikit data video untuk dilatih daripada masalah lainnya.
Model klasifikasi kelas jamak memprediksi satu kelas dari dua atau beberapa kelas diskret. Gunakan ini untuk mengategorikan segmen video. Misalnya, mengklasifikasikan segmen koleksi video Olimpiade untuk mengetahui olahraga mana yang ditampilkan pada waktu tertentu. Output-nya memberikan segmen video yang diberi label tunggal, seperti berenang atau senam.
Model klasifikasi multi-label memprediksi satu atau beberapa class dari banyak kemungkinan class. Gunakan model ini untuk memberi label beberapa kelas dalam satu segmen video. Jenis masalah ini sering kali memerlukan lebih banyak data pelatihan karena membedakan antara banyak class akan lebih kompleks.
Contoh sepak bola sebelumnya akan memerlukan mode klasifikasi multi-label, karena class (tindakan seperti sasaran, pelanggaran pribadi, dll.) dapat terjadi secara bersamaan, yang berarti satu segmen video mungkin memerlukan beberapa label.
Catatan mengenai keadilan
Perlakuan yang adil adalah salah satu praktik responsible AI Google. Tujuan keadilan adalah untuk memahami dan mencegah perlakuan tidak adil atau merugikan terhadap orang-orang berdasarkan ras, pendapatan, orientasi seksual, agama, gender, dan karakteristik lainnya yang secara historis terkait dengan diskriminasi dan marginalisasi, kapan dan di mana hal tersebut muncul dalam sistem algoritma atau pengambilan keputusan dengan bantuan algoritma. Saat membaca panduan ini, Anda akan melihat catatan "Waspada" yang membahas lebih lanjut cara membuat model machine learning yang lebih adil. Pelajari lebih lanjut
Mengumpulkan data
 Setelah menetapkan kasus penggunaan, Anda harus mengumpulkan data video yang
akan memungkinkan Anda membuat model yang diinginkan. Data yang Anda kumpulkan untuk pelatihan dapat menentukan jenis masalah yang dapat Anda selesaikan. Berapa banyak video yang dapat Anda gunakan? Apakah video berisi contoh yang cukup untuk class yang Anda inginkan untuk diprediksi oleh model Anda? Saat mengumpulkan data video, ingatlah pertimbangan berikut.
Setelah menetapkan kasus penggunaan, Anda harus mengumpulkan data video yang
akan memungkinkan Anda membuat model yang diinginkan. Data yang Anda kumpulkan untuk pelatihan dapat menentukan jenis masalah yang dapat Anda selesaikan. Berapa banyak video yang dapat Anda gunakan? Apakah video berisi contoh yang cukup untuk class yang Anda inginkan untuk diprediksi oleh model Anda? Saat mengumpulkan data video, ingatlah pertimbangan berikut.
Sertakan video yang cukup
 Umumnya, makin banyak video pelatihan dalam set data Anda, makin baik hasil Anda. Jumlah
video yang direkomendasikan juga disesuaikan dengan kompleksitas masalah yang Anda
coba selesaikan. Misalnya, Anda akan membutuhkan lebih sedikit data video untuk masalah klasifikasi biner (memprediksi satu class dari dua class) daripada masalah multi-label (memprediksi satu atau lebih class dari sekian banyak class).
Umumnya, makin banyak video pelatihan dalam set data Anda, makin baik hasil Anda. Jumlah
video yang direkomendasikan juga disesuaikan dengan kompleksitas masalah yang Anda
coba selesaikan. Misalnya, Anda akan membutuhkan lebih sedikit data video untuk masalah klasifikasi biner (memprediksi satu class dari dua class) daripada masalah multi-label (memprediksi satu atau lebih class dari sekian banyak class).
Kompleksitas hal yang Anda coba klasifikasikan juga dapat menentukan jumlah data video yang Anda butuhkan. Perhatikan kasus penggunaan sepak bola, yaitu membuat model untuk membedakan tembakan aksi. Bandingkan dengan model yang membedakan spesies burung kolibri. Mempertimbangkan nuansa dan kesamaan dalam warna, ukuran, dan bentuk: Anda memerlukan lebih banyak data pelatihan agar model tersebut dapat mempelajari cara mengidentifikasi setiap spesies secara akurat.
Gunakan aturan ini sebagai dasar untuk memahami kebutuhan data video minimal Anda:
- 200 contoh video per kelas jika Anda memiliki sedikit kelas dan kelasnya berbeda
- 1.000+ contoh video per class jika Anda memiliki lebih dari 50 class,atau jika class mirip satu sama lain
Jumlah data video yang diperlukan mungkin lebih banyak dari yang Anda miliki saat ini. Pertimbangkan untuk mendapatkan lebih banyak video melalui penyedia pihak ketiga. Misalnya, Anda dapat membeli atau mendapatkan lebih banyak video sepak bola jika tidak memiliki cukup untuk model ID tindakan game.
Distribusikan video secara merata di seluruh kelas
Cobalah untuk memberikan jumlah contoh pelatihan yang serupa untuk setiap kelas. Berikut alasannya: Bayangkan 80% set data latihan Anda adalah video sepak bola yang menampilkan tendangan gol, tetapi hanya 20% video yang menggambarkan pelanggaran pribadi atau tendangan penalti. Dengan distribusi class yang tidak setara, model Anda lebih mungkin memprediksi bahwa tindakan tertentu merupakan sasaran. Ini mirip dengan menulis tes pilihan ganda, di mana 80% jawaban yang benar adalah "C": Model yang cerdas akan dengan cepat dapat mengetahui bahwa "C" adalah tebakan yang cukup bagus sepanjang waktu.

Mungkin tidak mungkin untuk mendapatkan jumlah video yang sama untuk setiap kelas. Contoh berkualitas tinggi dan tidak bias mungkin juga sulit untuk beberapa kelas. Coba ikuti rasio 1:10: jika kelas terbesar memiliki 10.000 video, kelas terkecil harus memiliki setidaknya 1.000 video.
Menangkap variasi
Data video Anda harus menangkap keragaman ruang masalah Anda. Semakin beragam contoh yang dilihat model selama pelatihan, semakin mudah model tersebut melakukan generalisasi ke contoh baru atau yang kurang umum. Pikirkan tentang model klasifikasi tindakan sepak bola: Anda dapat menyertakan video dengan berbagai sudut kamera, waktu siang dan malam, serta berbagai gerakan pemain. Mengekspos model ke berbagai data akan meningkatkan kemampuan modelnya untuk membedakan satu tindakan dari tindakan lainnya.
Mencocokkan data dengan output yang diinginkan

Temukan video pelatihan yang secara visual mirip dengan video yang akan Anda masukkan ke dalam model untuk prediksi. Misalnya, jika semua video pelatihan Anda diambil pada musim dingin atau malam hari, pola pencahayaan dan warna di lingkungan tersebut akan memengaruhi model Anda. Jika Anda kemudian menggunakan model tersebut untuk menguji video yang diambil pada musim panas atau siang hari, Anda mungkin tidak akan menerima prediksi yang akurat.
Pertimbangkan faktor tambahan berikut: * Resolusi video * Frame video per detik * Sudut kamera * Latar belakang
Menyiapkan data

Setelah mengumpulkan video yang ingin disertakan dalam set data, Anda harus memastikan video tersebut berisi kotak pembatas dengan label agar model mengetahui apa yang harus dicari.
Mengapa video saya memerlukan kotak pembatas dan label?
Bagaimana cara model Klasifikasi Kecerdasan Video AutoML belajar mengidentifikasi pola? Itulah yang dilakukan kotak pembatas dan label selama pelatihan. Contohnya sepak bola: setiap contoh video harus menyertakan kotak pembatas di sekitar gambar aksi. Kotak-kotak itu juga memerlukan label seperti "tujuan", "pelanggaran pribadi", dan "tendangan penalti" yang ditetapkan kepadanya. Jika tidak, model tidak akan tahu apa yang harus dicari. Menggambar kotak dan menetapkan label ke contoh video Anda dapat memakan waktu. Jika perlu, pertimbangkan untuk menggunakan layanan pelabelan untuk mengalihdayakan karya kepada orang lain.
Melatih model Anda
Setelah data video pelatihan disiapkan, Anda siap untuk membuat model machine learning. Perhatikan bahwa Anda dapat menggunakan set data yang sama untuk membuat model machine learning yang berbeda, meskipun model tersebut memiliki jenis masalah yang berbeda.
Salah satu manfaat AutoML Video Intelligence Classification adalah parameter default akan memandu Anda ke model machine learning yang andal. Namun, Anda mungkin perlu menyesuaikan parameter bergantung pada kualitas data dan hasil yang Anda cari. Contoh:
- Jenis prediksi (tingkat perincian yang diproses video Anda)
- Kecepatan frame
- Resolusi
Mengevaluasi model Anda
 Setelah pelatihan model selesai, Anda akan menerima ringkasan performanya. Metrik evaluasi model didasarkan pada performa model terhadap sebagian set data Anda (set data validasi). Ada beberapa metrik dan konsep utama yang perlu dipertimbangkan saat menentukan apakah model Anda siap digunakan dalam data sebenarnya atau tidak.
Setelah pelatihan model selesai, Anda akan menerima ringkasan performanya. Metrik evaluasi model didasarkan pada performa model terhadap sebagian set data Anda (set data validasi). Ada beberapa metrik dan konsep utama yang perlu dipertimbangkan saat menentukan apakah model Anda siap digunakan dalam data sebenarnya atau tidak.
Nilai minimum skor
Bagaimana model machine learning mengetahui bahwa gol sepak bola benar-benar merupakan gol? Setiap prediksi diberi skor keyakinan – penilaian numerik untuk kepastian model bahwa segmen video tertentu berisi class. Ambang batas skor adalah angka yang menentukan kapan skor tertentu dikonversi menjadi keputusan ya atau tidak; yaitu, nilai yang mana model Anda mengatakan "ya, angka keyakinan ini cukup tinggi untuk menyimpulkan bahwa segmen video ini berisi sasaran".

Jika nilai minimum skor rendah, model Anda akan berisiko salah melabeli segmen video. Oleh karena itu, nilai minimum skor harus didasarkan pada kasus penggunaan tertentu. Bayangkan kasus penggunaan medis seperti deteksi kanker, di mana konsekuensi kesalahan pelabelan lebih tinggi daripada kesalahan pelabelan pada video olahraga. Dalam deteksi kanker, ambang skor yang lebih tinggi sudah sesuai.
Hasil prediksi
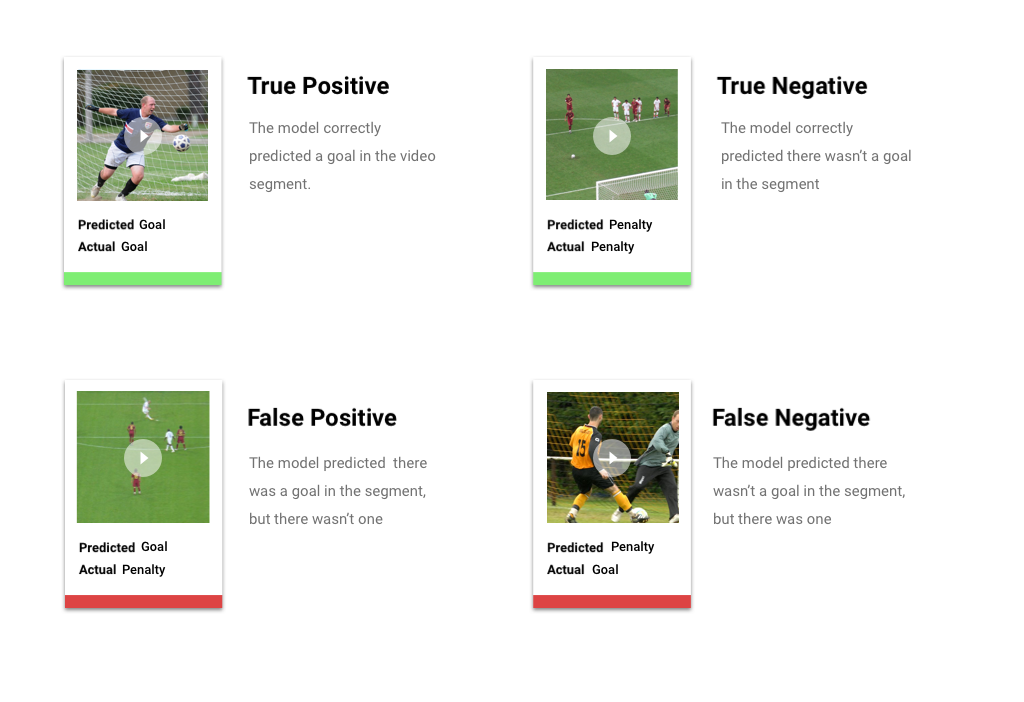
Setelah menerapkan nilai minimum skor, prediksi yang dibuat oleh model Anda akan termasuk dalam salah satu dari empat kategori. Untuk memahami kategori ini, bayangkan Anda membuat model untuk mendeteksi apakah segmen tertentu berisi gol sepak bola (atau tidak). Dalam contoh ini, sasaran adalah kelas positif (apa yang coba diprediksi oleh model).
- Positif benar: Model memprediksi kelas positif dengan benar. Model ini memprediksi sasaran dengan benar di segmen video.
- Positif palsu: Model salah memprediksi kelas positif. Model ini memprediksi sasaran ada di segmen, tetapi tidak ada sasaran.
- Negatif benar: Model memprediksi kelas negatif dengan benar. Model memprediksi dengan benar bahwa tidak ada sasaran di segmen.
- Negatif palsu: Model salah memprediksi kelas negatif. Model memprediksi bahwa tidak ada sasaran di segmen tersebut, tetapi ada satu sasaran.
Presisi dan perolehan
Metrik presisi dan perolehan membantu Anda memahami seberapa baik model Anda dalam menangkap informasi dan hal yang terlewatkan. Pelajari presisi dan perolehan lebih lanjut
- Presisi adalah bagian dari prediksi positif yang benar. Dari semua prediksi yang berlabel "sasaran", bagian mana yang sebenarnya berisi sasaran?
- Perolehan adalah bagian dari semua prediksi positif yang benar-benar diidentifikasi. Dari semua gol sepak bola yang dapat diidentifikasi, berapa pecahannya?
Bergantung pada kasus penggunaan, Anda mungkin perlu mengoptimalkan presisi atau perolehan. Pertimbangkan kasus penggunaan berikut.
Kasus Penggunaan: Informasi pribadi dalam video
Bayangkan Anda membuat software yang otomatis mendeteksi informasi sensitif dalam video dan memburamkannya. Konsekuensi dari hasil yang salah dapat mencakup:
- Positif palsu mengidentifikasi sesuatu yang tidak perlu disensor, tetapi tetap disensor. Hal ini mungkin mengganggu, tetapi tidak mengganggu.

- Negatif palsu gagal mengidentifikasi informasi yang perlu disensor, seperti nomor kartu kredit. Hal ini akan merilis informasi pribadi dan merupakan skenario terburuk.
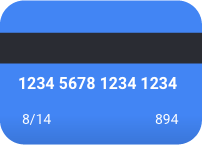
Dalam kasus penggunaan ini, penting untuk mengoptimalkan penarikan guna memastikan bahwa model menemukan semua kasus yang relevan. Model yang dioptimalkan untuk penarikan lebih cenderung memberi label pada contoh yang sedikit relevan, tetapi juga lebih mungkin untuk melabeli contoh yang salah (memburamkan lebih dari yang diperlukan).
Kasus penggunaan: Penelusuran video stok
Katakanlah Anda ingin membuat software yang memungkinkan pengguna menelusuri koleksi video berdasarkan kata kunci. Mari kita pertimbangkan hasil yang salah:
- Positif palsu (PP) menampilkan video yang tidak relevan. Karena sistem Anda mencoba menyediakan video yang relevan saja, perangkat lunak Anda tidak benar-benar melakukan apa yang harus dilakukannya.

- Negatif palsu gagal menampilkan video yang relevan. Karena banyak kata kunci memiliki ratusan video, masalah ini tidak buruk karena menampilkan video yang tidak relevan.

Dalam contoh ini, Anda perlu mengoptimalkan presisi untuk memastikan model Anda memberikan hasil yang sangat relevan dan benar. Model presisi tinggi cenderung hanya melabeli contoh yang paling relevan, tetapi mungkin melewatkan beberapa contoh. Pelajari metrik evaluasi model lebih lanjut
Deploy model Anda
 Jika sudah puas dengan performa model Anda, sekarang saatnya menggunakan model tersebut.
AutoML Video Intelligence Classification menggunakan prediksi batch, yang memungkinkan Anda mengupload file CSV
dengan jalur file ke video yang dihosting di Cloud Storage. Model Anda akan memproses setiap prediksi video dan output dalam file CSV lain. Prediksi batch bersifat asinkron, artinya model akan memproses semua permintaan prediksi terlebih dahulu sebelum menampilkan hasilnya.
Jika sudah puas dengan performa model Anda, sekarang saatnya menggunakan model tersebut.
AutoML Video Intelligence Classification menggunakan prediksi batch, yang memungkinkan Anda mengupload file CSV
dengan jalur file ke video yang dihosting di Cloud Storage. Model Anda akan memproses setiap prediksi video dan output dalam file CSV lain. Prediksi batch bersifat asinkron, artinya model akan memproses semua permintaan prediksi terlebih dahulu sebelum menampilkan hasilnya.