Gemini API di Vertex AI memungkinkan Anda mengirimkan input multimodal seperti teks, gambar, dan video sebagai bagian dari perintah ke model Gemini. Halaman ini memberikan praktik terbaik untuk mendesain perintah multimodal dan cara memecahkan masalah jika perintah Anda tidak berfungsi seperti yang diharapkan. Untuk panduan umum tentang desain perintah, lihat strategi desain perintah yang kami rekomendasikan, atau lihat daftar praktik terbaik khusus multimodal berikut.
Dasar-dasar desain perintah
Menggunakan petunjuk khusus
Perintah yang jelas dan mendetail akan memberikan hasil terbaik. Jika Anda memiliki output tertentu, sertakan persyaratan tersebut dalam perintah untuk meningkatkan kemungkinan Anda mendapatkan output yang benar.
Meskipun perintah tampak jelas bagi orang yang menulisnya, perintah tersebut mungkin kurang spesifik. Untuk menyesuaikan perilaku model, pertimbangkan bagaimana perintah Anda dapat ditafsirkan dan pastikan petunjuk yang Anda berikan spesifik dan jelas.
Jika Anda menyertakan gambar papan informasi bandara di bawah sebagai bagian dari perintah Anda, meminta model untuk "mendeskripsikan gambar ini" saja dapat menghasilkan deskripsi umum. Jika Anda ingin model mengurai waktu dan kota dari gambar, sertakan permintaan tersebut langsung dalam perintah Anda.
| Perintah | Respons model |
|---|---|

Jelaskan gambar ini. |
Gambar menampilkan papan kedatangan dan keberangkatan bandara. |
| Perintah yang diperbarui | Respons yang lebih baik |
|---|---|
|
Parse the time and city from the airport board shown in this image into a list. |
|
Menambahkan contoh
Model dapat menerima beberapa input untuk digunakan sebagai contoh guna memahami output yang Anda inginkan. Menambahkan contoh ini dapat membantu model mengidentifikasi pola dan menerapkan hubungan antara gambar dan respons yang diberikan ke contoh baru. Hal ini disebut "few-shot" learning.
Dalam contoh berikut, output awal adalah kalimat lengkap yang juga berisi negara (Brasil). Jika output yang diinginkan hanya kota, bukan negara, menambahkan contoh few-shot ke perintah Anda dapat memandu model untuk merespons dalam format tersebut.
| Perintah | Respons model |
|---|---|

Tentukan kota beserta tempat terkenalnya. |
Landmark ini adalah patung Kristus Penebus di Rio de Janeiro, Brasil. |
| Perintah yang diperbarui | Respons yang lebih baik |
|---|---|
|
Tentukan kota beserta tempat terkenalnya. 
|
kota: Roma, landmark: Colosseum. |

|
kota: Beijing, landmark: Kota Terlarang |
|
|
kota: Rio de Janeiro, landmark: patung Kristus Penebus |
Membagi tugas yang kompleks menjadi tugas-tugas yang lebih kecil
Untuk tugas kompleks seperti tugas yang memerlukan pemahaman dan penalaran visual, bagi tugas menjadi langkah-langkah yang lebih kecil dan lebih mudah, atau minta model secara langsung untuk berpikir langkah demi langkah dalam perintah.
| Perintah | Respons model |
|---|---|

Kapan tisu toilet saya akan habis? |
Segera, Anda hanya memiliki 3 gulungan yang tersisa. |
| Perintah yang diperbarui | Respons yang lebih baik |
|---|---|
|
|
Soal matematika atau jenis soal cerita lainnya juga dapat dipecah menjadi tugas yang lebih kecil.
| Perintah | Respons |
|---|---|
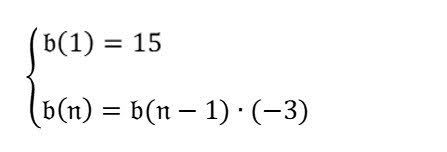
Berapa suku ke-4 dalam urutan tersebut? |
-135 |
Respons dari model salah. Coba minta model untuk mengurai masalah sebelum menjawab perintah.
| Perintah | Respons |
|---|---|
|
Parse formula dalam gambar terlebih dahulu. Kemudian, berdasarkan rumus tersebut, jawab "apa suku ke-4 dalam deret tersebut?". |
Klik untuk meluaskan hasil$$b(n) = b(n-1) * (-3)$$ $$b(1) = 15$$
Oleh karena itu, suku ke-4 dalam deret tersebut adalah -405. |
Untuk membuat respons menjadi lebih efisien, Anda dapat meminta model untuk memikirkan prompt langkah demi langkah.
| Perintah yang diperbarui | Respons yang lebih baik |
|---|---|
|
Berapa suku ke-4 dalam urutan tersebut? Berpikirlah secara berurutan. |
Istilah pertama adalah 15. Istilah kedua adalah b(1) * (-3) = 15 * (-3) = -45. Istilah ketiga adalah b(2) * (-3) = -45 * (-3) = 135. Suku keempat adalah b(3) * (-3) = 135 * (-3) = -405. |
Menentukan format output
Jika format tertentu diperlukan, Anda dapat menginstruksikan model untuk menggunakan format tersebut untuk outputnya.
| Perintah | Respons model |
|---|---|
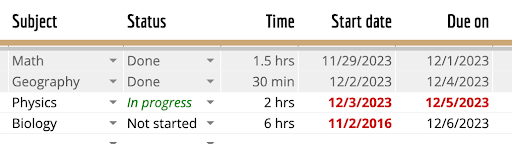
Parse tabel dalam gambar ini ke dalam format Markdown |
| Subject | Status | Time | Start date | Due on |
|-----------|-------------|---------|------------|------------|
| Math | Done | 1.5 hrs | 11/29/2023 | 12/1/2023 |
| Geography | Done | 30 min | 12/2/2023 | 12/4/2023 |
| Physics | In progress | 2 hrs | 12/3/2023 | 12/5/2023 |
| Biology | Not started | 6 hrs | 11/2/2016 | 12/6/2023 |
|
| Perintah | Respons model |
|---|---|

Berikan daftar semua atribut berikut: bahan, jenis masakan, vegetarian atau tidak, dalam format JSON |
|
Memecahkan masalah perintah multimodal
Memecahkan masalah perintah dapat melibatkan peningkatan kualitas bahasa perintah Anda, mengarahkan fokus perintah, atau menyesuaikan parameter. Berbagai pendekatan ini dapat menghasilkan peningkatan hasil, terutama setelah menentukan akar penyebab masalah.
Berfokus pada bagian gambar yang relevan
Untuk meningkatkan kualitas respons, tunjukkan bagian gambar yang paling relevan dengan perintah.
| Perintah | Respons model |
|---|---|

Berapa hari popok ini akan bertahan untuk bayi? |
Popok akan bertahan selama 198 hari sebelum habis. |
| Perintah yang diperbarui | Respons yang lebih baik |
|---|---|
|
Berapa lama popok ini akan bertahan sebelum habis? Gunakan berat yang tertera di kotak untuk menentukan usia anak, dan gunakan jumlah total popok dalam kotak. Bagi total jumlahnya dengan berapa banyak popok yang digunakan anak per hari. |
Kotak berisi 198 popok. Kotak tersebut menyatakan bahwa popok ditujukan untuk anak dengan berat 22-37 lbs. Rata-rata anak dalam rentang berat ini kemungkinan berusia antara 1 dan 2 tahun. Anak berusia 2 tahun biasanya menggunakan 6 popok per hari, jadi popok akan bertahan sekitar 33 hari (198/6). |
Menyesuaikan respons model dengan input
Minta model untuk mendeskripsikan gambar sebelum melakukan tugas dalam perintah.
| Perintah | Respons model |
|---|---|



Apa kesamaan antara gambar-gambar ini? |
Keempat gambar tersebut adalah contoh fotografi lanskap. |
| Perintah yang diperbarui | Respons yang lebih baik |
|---|---|
|
Pertama, jelaskan isi setiap gambar secara mendetail. Apa kesamaan antara gambar-gambar ini? |
Gambar pertama menunjukkan seseorang sedang mengemas koper. Gambar kedua menunjukkan lorong kosong di pusat perbelanjaan. Gambar ketiga menampilkan gulungan tisu toilet. Gambar keempat menampilkan laut yang gelap dan berbadai. Kesamaan antara gambar-gambar ini adalah bahwa semuanya merupakan contoh ruang liminal. Ruang liminal adalah tempat atau situasi yang berada di antara dua tempat atau situasi lainnya. Mereka sering kali ditandai dengan rasa tidak pasti atau ambigu. Gambar pertama menunjukkan orang yang berada di antara rumah dan sedang dalam perjalanan. Gambar kedua menunjukkan lorong di antara dua toko. Gambar ketiga adalah tisu toilet, yang dapat mewakili kamar mandi. Kamar mandi adalah ruang transisi antara ranah pribadi dan publik. Ini adalah tempat di mana kita mempersiapkan diri untuk masuk atau keluar dari dunia luar. Gambar keempat menunjukkan laut yang tenang dan laut yang berbadai. Ruang liminal bisa terasa menarik dan mengganggu. Tempat tersebut bisa menjadi tempat awal yang baru atau tempat akhir. Tempat tersebut bisa menjadi tempat untuk merenung atau tempat untuk bertindak. |
Anda dapat secara eksplisit meminta model untuk merujuk pada apa yang ada dalam gambar.
| Perintah yang diperbarui | Respons yang lebih baik |
|---|---|
|
Apa kesamaan antara gambar-gambar ini? Lihat isi gambar dalam respons Anda. |
Semua gambar terkait dengan perjalanan. Gambar pertama menunjukkan seseorang sedang mengemas koper, gambar kedua menunjukkan lorong kosong di pusat perbelanjaan, gambar ketiga menunjukkan tumpukan tisu toilet, dan gambar keempat menunjukkan laut yang gelap dan badai. Semua gambar ini terkait dengan perjalanan karena semuanya adalah hal-hal yang dibutuhkan atau digunakan orang saat bepergian. Gambar pertama menunjukkan seseorang sedang mengemas koper, yang merupakan sesuatu yang dilakukan orang saat mereka akan bepergian. Gambar kedua menampilkan lorong kosong di pusat perbelanjaan, yang merupakan tempat orang sering pergi untuk membeli barang untuk perjalanan mereka. Gambar ketiga menampilkan tumpukan tisu toilet, yang sering digunakan orang saat bepergian. Gambar keempat menunjukkan laut yang gelap dan badai, yang sering dialami orang saat bepergian. |
Tips yang sama berlaku untuk output kreatif. Minta model secara eksplisit untuk menyertakan aspek dari gambar; hal ini dapat meningkatkan kualitas output.
| Perintah | Respons model |
|---|---|

Bisakah Anda menulis puisi tentang gambar ini untuk saya? |
Little bunny, so soft and brown,
Hopping through the field, up and down.
Your ears so long, your tail so small,
You're the cutest creature of them all.You nibble on the grass, so green and sweet,
And hop away when you see me.
But I'll always be your friend,
Little bunny, until the very end. |
| Perintah yang diperbarui | Respons yang lebih baik |
|---|---|
|
Dapatkah Anda menulis puisi deskriptif dan dramatis tentang gambar ini dan menyertakan lokasinya? |
Little bunny on the green,
Ears so long, so keen.
What do you see out there,
In the distance, where you stare?Is it the ocean blue,
Sparkling in the sun's hue?
Or the waves that crash and roar,
A rhythm that you adore?Little bunny, tell me true,
What captures your attention so?
Is it the salty breeze,
Or the seagulls' cries that please?Perhaps it's the vastness of it all,
A world so big and small.
A place where dreams can roam,
And adventures can be sown.Little bunny, I wonder what you dream,
As you sit on the grass, so serene.
Do you yearn to explore the deep,
Or stay on land, where you can leap?Whatever it may be, little bunny,
Keep that spark of wonder burning brightly.
For in your dreams and aspirations,
Lies a world waiting for your creation. |
Menentukan penyebab kegagalan perintah
Perintah dapat gagal karena model tidak memahami gambar sama sekali, atau karena model tidak melakukan langkah-langkah penalaran yang benar setelahnya. Untuk membedakan alasan tersebut, minta model untuk mendeskripsikan isi gambar.
Dalam contoh ini, jika model merespons dengan makanan ringan yang tampak tidak biasa jika dipadukan dengan teh (seperti popcorn), pertama-tama tentukan apakah model mengenali bahwa gambar tersebut berisi teh.
| Perintah | Perintah untuk pemecahan masalah |
|---|---|

Apa camilan yang bisa saya buat dalam 1 menit yang cocok dengan ini? |
Jelaskan apa yang ada dalam gambar ini. |
Meminta model untuk menjelaskan penalarannya dapat membantu mempersempit bagian penalaran yang salah, jika ada.
| Perintah | Perintah untuk pemecahan masalah |
|---|---|
|
Apa camilan yang bisa saya buat dalam 1 menit yang cocok dengan ini? |
Apa camilan yang bisa saya buat dalam 1 menit yang cocok dengan ini? Harap jelaskan alasannya. |
Menyesuaikan parameter pengambilan sampel
Di setiap permintaan, Anda tidak hanya mengirimkan perintah multimodal, tetapi juga serangkaian parameter pengambilan sampel ke model. Model ini dapat memberikan hasil yang berbeda untuk nilai parameter yang berbeda. Bereksperimenlah dengan berbagai parameter untuk mendapatkan nilai terbaik untuk tugas tersebut. Parameter yang paling sering disesuaikan adalah sebagai berikut:
Temperatur
Suhu digunakan untuk pengambilan sampel selama pembuatan respons, yang terjadi saat top-P dan top-K diterapkan. Suhu mengontrol tingkat keacakan dalam pemilihan token. Suhu yang lebih rendah cocok untuk perintah yang memerlukan respons yang lebih deterministik dan kurang terbuka atau kreatif, sedangkan suhu yang lebih tinggi dapat memberikan hasil yang lebih beragam atau kreatif. Suhu 0 bersifat deterministik, yang berarti bahwa respons probabilitas tertinggi kemungkinan besar akan dipilih.
Untuk sebagian besar kasus penggunaan, mulailah dengan suhu 0,4. Jika Anda memerlukan hasil yang lebih kreatif, tingkatkan suhu. Jika Anda mengamati halusinasi yang jelas, turunkan suhu.
Top-P
Top-P mengubah cara model memilih token untuk output. Token dipilih dari yang paling mungkin hingga yang paling tidak mungkin sampai jumlah probabilitasnya sama dengan nilai top-P. Misalnya, jika token A, B, dan C memiliki probabilitas 0,6, 0,3, 0,1 dan nilai top-P adalah 0,9, maka model akan memilih A atau B sebagai token berikutnya dengan menggunakan suhu dan mengecualikan C sebagai kandidat.
Tentukan nilai yang lebih rendah untuk respons acak yang lebih sedikit dan nilai yang lebih tinggi untuk respons acak yang lebih banyak. Nilai default top-P adalah 1,0.
Langkah berikutnya
- Coba tutorial panduan memulai menggunakan Vertex AI Studio atau Vertex AI API.
- Untuk mulai menggunakan Gemini API di Vertex AI, lihat panduan memulai Gemini API di Vertex AI.