Halaman ini memberikan ringkasan tentang menyesuaikan model teks dan chat serta menyaring model teks. Anda akan mempelajari jenis-jenis tuning yang tersedia dan cara kerja penyaring. Anda juga akan mempelajari manfaat tuning dan distilasi, serta skenario jika Anda ingin menyesuaikan atau menyaring model teks.
Menyesuaikan jenis untuk model teks
Anda dapat memilih salah satu metode berikut untuk menyesuaikan model teks:
Penyesuaian yang diawasi - Model pembuatan teks dan chat teks mendukung penyesuaian yang diawasi. Penyesuaian model teks yang diawasi adalah opsi yang bagus jika output model Anda tidak kompleks dan relatif mudah ditentukan. Penyesuaian yang diawasi direkomendasikan untuk klasifikasi, analisis sentimen, ekstraksi entity, peringkasan konten yang tidak kompleks, dan penulisan kueri khusus domain. Untuk model kode, penyesuaian yang diawasi adalah satu-satunya opsi. Untuk mempelajari cara menyesuaikan model teks dengan penyesuaian yang diawasi, lihat Menyesuaikan model teks dengan penyesuaian yang diawasi.
Reinforcement Learning from Human Feedback (RLHF) - Model dasar pembuatan teks dan beberapa model transformer transfer teks-ke-teks Flan (Flan-T5) mendukung penyesuaian RLHF. Penyesuaian RLHF adalah opsi yang bagus jika output model Anda kompleks. RLHF berfungsi dengan baik pada model dengan tujuan level urutan yang tidak mudah dibedakan dengan penyesuaian yang diawasi. Penyesuaian RLHF direkomendasikan untuk question answering, peringkasan konten yang kompleks, dan pembuatan konten, seperti penulisan ulang. Untuk mempelajari cara menyesuaikan model teks dengan penyesuaian RLHF, lihat Menyesuaikan model teks dengan penyesuaian RLHF.
Manfaat penyesuaian model teks
Model teks yang disesuaikan dilatih pada lebih banyak contoh daripada yang dapat dimuat dalam perintah. Oleh karena itu, setelah model yang dilatih sebelumnya disesuaikan, Anda dapat memberikan lebih sedikit contoh dalam perintah dibandingkan perintah pada model asli yang dilatih sebelumnya. Dengan diperlukannya lebih sedikit contoh, berikut manfaat yang akan diberikan:
- Latensi yang lebih rendah dalam permintaan.
- Lebih sedikit token yang digunakan.
- Latensi yang lebih rendah dan token yang lebih sedikit akan mengurangi biaya inferensi.
Distilasi model
Selain penyesuaian RLHF dan yang diawasi, Vertex AI mendukung distilasi model. Distilasi adalah proses melatih model siswa yang lebih kecil pada model pengajar yang lebih besar untuk meniru perilaku model yang lebih besar sambil mengecilkan ukuran.
Ada beberapa jenis distilasi model, termasuk:
- Berdasarkan respons: Latih model siswa tentang probabilitas respons model pengajar.
- Berbasis fitur: Latih model siswa untuk meniru lapisan dalam model pengajar.
- Berbasis hubungan: Latih model siswa tentang hubungan dalam data input atau output model pengajar.
- Penyaringan mandiri: Model pengajar dan siswa memiliki arsitektur yang sama dan model ini mengajarkan dirinya sendiri.
Menyaring langkah demi langkah menggunakan Vertex AI
Vertex AI mendukung suatu bentuk distilasi berbasis respons yang disebut distilasi langkah demi langkah (DSS). DSS adalah metode untuk melatih model yang lebih kecil khusus tugas melalui chain of thinking (COT) prompting.
Untuk menggunakan DSS, Anda memerlukan set data pelatihan kecil yang terdiri dari input dan label. Jika label tidak tersedia, model pengajar akan membuat label tersebut. Argumentasi diekstrak oleh proses DSS, kemudian digunakan untuk melatih model kecil dengan tugas pembuatan alasan dan tugas prediksi umum. Hal ini memungkinkan model kecil membangun penalaran perantara sebelum mencapai prediksi akhir.
Diagram berikut menunjukkan cara penyaringan langkah demi langkah menggunakan permintaan COT untuk mengekstrak alasan dari model bahasa besar (LLM). Alasan digunakan untuk melatih model khusus tugas yang lebih kecil.
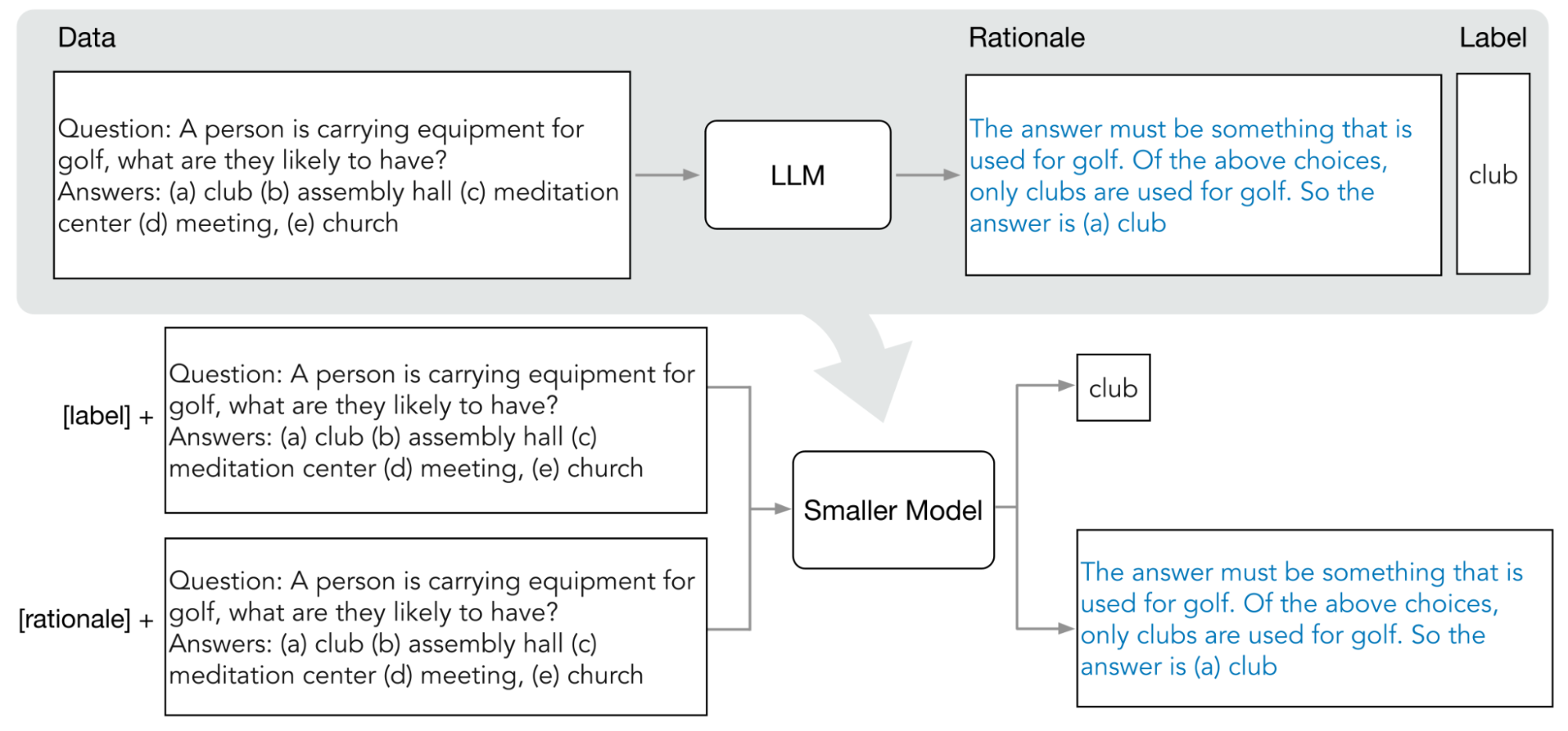
Manfaat penyaringan langkah demi langkah
Manfaat penyulingan langkah demi langkah meliputi:
- Akurasi yang lebih baik: Distilasi langkah demi langkah telah terbukti mengungguli beberapa shot prompting standar pada LLM.
- LLM yang disaring dapat mencapai hasil pada tugas akhir spesifik pengguna yang mirip dengan hasil dari LLM yang jauh lebih besar.
- Mengatasi kendala data. Anda dapat menggunakan DSS dengan set data perintah tidak berlabel yang hanya memiliki beberapa ribu contoh.
- Jejak hosting yang lebih kecil.
- Mengurangi latensi inferensi.
Langkah selanjutnya
- Pelajari cara menyesuaikan model dasar menggunakan penyesuaian yang diawasi.
- Pelajari cara menyesuaikan model dasar menggunakan penyesuaian RLHF.
- Pelajari cara menyesuaikan model kode.
- Pelajari cara menyaring model teks.