Diese Seite bietet eine Übersicht über die Abstimmung von Text- und Chatmodellen und die Destillation von Textmodellen. Sie erfahren mehr über die verfügbaren Abstimmungstypen und die Funktionsweise der Destillation. Außerdem erfahren Sie mehr über die Vorteile der Feinabstimmung und Destillation sowie Szenarien, in denen Sie ein Textmodell optimieren oder destillieren sollten.
Modelle abstimmen
Sie haben folgende Möglichkeiten, ein Textmodell abzustimmen:
Überwachte Abstimmung: Die Textgenerierung und Textchat-Modelle unterstützen die überwachte Abstimmung. Die überwachte Abstimmung eines Textmodells ist eine gute Option, wenn die Ausgabe Ihres Modells nicht komplex und relativ einfach zu definieren ist. Die überwachte Abstimmung wird für Klassifizierung, Sentimentanalyse, Entitätsextraktion, Zusammenfassung von Inhalten, die nicht komplex sind, und domainspezifische Abfragen geschrieben. Bei Codemodellen ist die überwachte Abstimmung die einzige Option. Informationen zum Optimieren eines Textmodells mit überwachter Abstimmung finden Sie unter Textmodelle mit überwachter Abstimmung optimieren.
Bestärkendes Lernen durch menschliches Feedback (RLHF): Das Basismodell für die Textgenerierung und einige Flan-Modelle für die Text-zu-Text-Übertragungstransformation (Flan-T5) unterstützen die RLHF-Abstimmung. Die RLHF-Abstimmung ist eine gute Option, wenn die Ausgabe Ihres Modells komplex ist. RLHF funktioniert gut bei Modellen mit Zielen auf Sequenzebene, die mit überwachter Abstimmung nicht leicht zu unterscheiden sind. Die RLHF-Abstimmung wird für die Beantwortung von Fragen, zur Zusammenfassung komplexer Inhalte und für die Erstellung von Inhalten empfohlen, z. B. eine Umschreibung. Informationen zum Abstimmen eines Textmodells mit RLHF-Abstimmung finden Sie unter Textmodelle mit RLHF-Abstimmung abstimmen.
Vorteile der Abstimmung von Textmodellen
Abgestimmte Textmodelle werden mit mehr Beispielen trainiert, als in einen Prompt passen. Aus diesem Grund können Sie nach der Abstimmung eines vortrainierten Modells weniger Beispiele in der Eingabeaufforderung angeben als für das ursprüngliche vortrainierte Modell. Das Anfordern von weniger Beispielen führt zu folgenden Vorteilen:
- Geringere Latenz bei Anfragen.
- Weniger Tokens werden verwendet.
- Eine geringere Latenz und weniger Tokens führen zu geringeren Inferenzkosten.
Modelldestillation
Zusätzlich zur überwachten und RLHF-Abstimmung unterstützt Vertex AI die Modelldestillation. Bei der Destillation wird ein kleineres Schülermodell mit einem größeren Lehrermodell trainiert, um das Verhalten des größeren Modells zu imitieren, während die Größe verkleinert wird.
Es gibt mehrere Arten der Modelldestillation, darunter:
- Antwortbasiert: Trainieren Sie das Schülermodell anhand der Antwortwahrscheinlichkeiten des Lehrermodells.
- Featurebasiert: Trainieren Sie das Schülermodell, um die inneren Ebenen des Lehrermodells nachzuahmen.
- Beziehungsbasiert: Trainieren Sie das Schülermodell mit Beziehungen in den Eingabe- oder Ausgabedaten des Lehrermodells.
- Selbstdestillation: Die Modelle der Lehrkräfte und Schüler/Studenten haben die gleiche Architektur und das Modell trainiert sich selbst.
Vorteile der Schritt-für-Schritt-Anleitung
Eine schrittweise Destillation bietet unter anderem folgende Vorteile:
- Verbesserte Genauigkeit: Die schrittweise Destillation wurde gewiesen, dass sie die standardmäßigen Few-Shot-Prompts auf LLMs übertrifft.
- Ein destilliertes LLM kann Ergebnisse für die spezifischen Endaufgaben der Nutzer erzielen, die den Ergebnissen von viel größeren LLMs ähneln.
- Überwinden Sie Dateneinschränkungen. Sie können DSS mit einem Prompt-Dataset ohne Label mit nur wenigen tausend Beispielen verwenden.
- Kleinere Hosting-Fußabdrücke.
- Geringere Latenzzeit für die Weiterleitung.
Schritt-für-Schritt-Anleitung zur Destillation mit Vertex AI
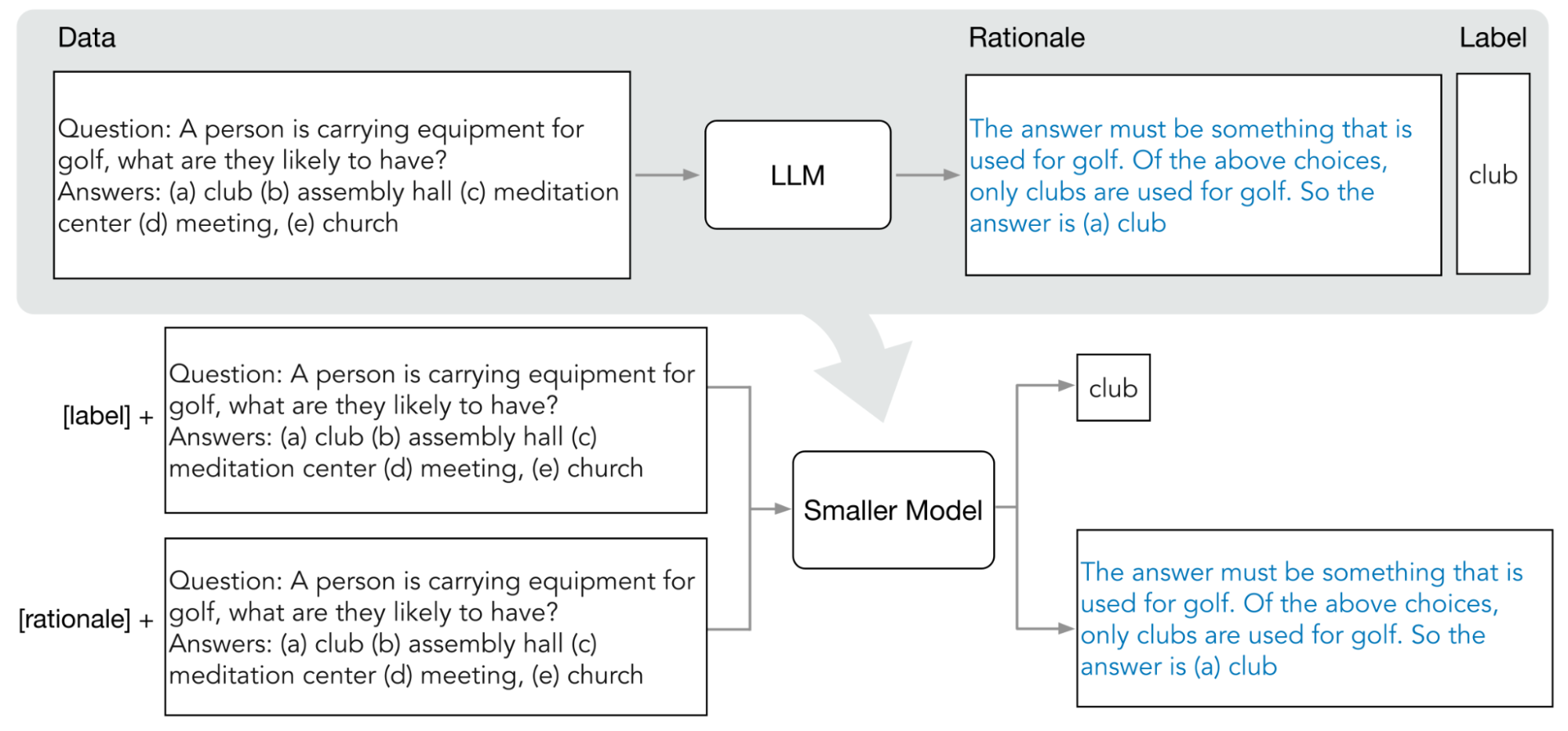
Vertex AI unterstützt eine Form der antwortbasierten Destillation, die als Schritt-für-Schritt-Destillation (DSS) bezeichnet wird. DSS ist eine Methode zum Trainieren kleinerer, aufgabenspezifischer Modelle über Chain of Thought Prompts (COT-Prompts).
Zur Verwendung von DSS benötigen Sie ein kleines Trainings-Dataset, das aus Eingaben und Labels besteht. Wenn keine Labels verfügbar sind, generiert das Lehrermodell die Labels. Die Grundsätze werden vom DSS-Prozess extrahiert und dann zum Trainieren des kleinen Modells mit einer Aufgabe zur Logikgenerierung und einer typischen Vorhersageaufgabe verwendet. Dadurch kann das kleine Modell Zwischenursachen erstellen, bevor es die endgültige Vorhersage erreicht.
Das folgende Diagramm zeigt, wie eine schrittweise Destillation mit COT-Prompts die Gründe aus einem Large Language Model (LLM) extrahieren kann. Die Überlegungen werden zum Trainieren kleinerer aufgabenspezifischer Modelle verwendet.
Kontingent
Jedes Google Cloud-Projekt benötigt ein ausreichendes Kontingent zum Ausführen eines Abstimmungsjobs. Ein Abstimmungsjob verwendet 8 GPUs. Wenn Ihr Projekt nicht ein ausreichendes Kontingent für einen Abstimmungsjob hat oder Sie mehrere gleichzeitige Abstimmungsjobs in Ihrem Projekt ausführen möchten, müssen Sie zusätzliche Kontingente anfordern.
In der folgenden Tabelle sind der Typ und die Menge des anzufordernden Kontingents abhängig von der Region aufgeführt, in der Sie die Feinabstimmung angegeben haben:
| Region | Ressourcenkontingent | Menge pro gleichzeitigem Job |
|---|---|---|
|
|
8 |
|
96 | |
|
|
64 |
Preise
Wenn Sie ein Foundation Model optimieren oder destillieren, bezahlen Sie die Kosten für die Ausführung der Abstimmungs- oder Destillationspipeline. Wenn Sie ein abgestimmtes oder destilliertes Grundlagenmodell für einen Vertex AI-Endpunkt bereitstellen, fallen für das Hosting keine Gebühren an. Für die Bereitstellung von Vorhersagen zahlen Sie denselben Preis wie für die Bereitstellung von Vorhersagen mit einem unbearbeiteten Foundation Model (zur Feinabstimmung) oder des Schülermodells (zur Destillation). Informationen zu den Foundation Models, die abgestimmt und destilliert werden können, finden Sie unter Foundation Models. Preisinformationen finden Sie unter Preise für Generative AI in Vertex AI.
Nächste Schritte
- Foundation Model mithilfe der überwachten Abstimmung abstimmen
- Foundation Model mithilfe der RLHF-Abstimmung abstimmen
- Codemodell abstimmen.
- Textmodell verkleinern