このページでは、評価パイプライン サービスを通じて提供されるツールである AutoSxS を使用して、ペアワイズ モデルベースの評価を行う方法について説明します。ここでは、Vertex AI API、Vertex AI SDK for Python、または Google Cloud コンソールから AutoSxS を使用する方法について説明します。
AutoSxS
Automatic side-by-side(AutoSxS)は、評価パイプライン サービスを通じて実行されるペアワイズ モデルベースの評価ツールです。AutoSxS を使用すると、Vertex AI Model Registry 内の生成 AI モデルまたは事前に生成された予測のパフォーマンスを評価できます。これにより、Vertex AI の基盤モデル、調整された生成 AI モデル、サードパーティの言語モデルをサポートできます。AutoSxS は自動評価を使用して、プロンプトへのレスポンスに優れたモデルを決定します。オンデマンドで利用可能で、人間の評価者に匹敵するパフォーマンスで言語モデルを評価します。
自動評価
大まかに言えば、この図は AutoSxS がモデル A と B の予測を 3 番目のモデルである自動評価と比較する方法を示しています。
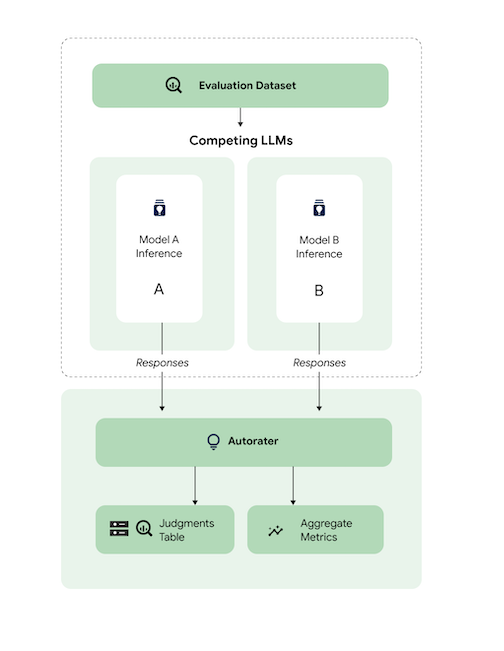
モデル A と B は入力プロンプトを受け取り、各モデルが自動評価に送信されるレスポンスを生成します。人間の評価者と同様に、自動評価は元の推論プロンプトでモデル レスポンスの品質を判断する言語モデルです。AutoSxS では、自動評価が一連の基準を使用して、推論命令に応じた 2 つのモデル レスポンスの品質を比較します。この基準を使用して、モデル A の結果とモデル B の結果を比較して、パフォーマンスが最も高いモデルを判断します。自動評価はレスポンスの選択を集約指標として出力し、各例の選択の説明と信頼スコアを出力します。詳細については、判定テーブルをご覧ください。
サポートされているモデル
AutoSxS では、事前に生成された予測が提供された場合のモデルの評価がサポートされています。AutoSxS は、Vertex AI でのバッチ予測をサポートする Vertex AI Model Registry 内の任意のモデルに対するレスポンスの自動生成もサポートしています。
テキストモデルが Vertex AI Model Registry でサポートされていない場合、AutoSxS は JSONL として Cloud Storage または BigQuery テーブルに格納されている事前に生成された予測も受け入れます。料金については、テキストの生成をご覧ください。
サポートされるタスクと基準
AutoSxS では、要約タスクと質問応答タスクのモデルの評価をサポートしています。評価基準はタスクごとに事前に定義されているため、言語評価がより客観的で、レスポンス品質が向上します。
基準はタスク別に表示されています。
要約
summarization タスクの入力トークンの上限は 4,096 です。
summarization の評価基準は次のとおりです。
| 条件 | |
|---|---|
| 1. 指示に従っている | モデルのレスポンスがプロンプトからの指示をどの程度理解しているか。 |
| 2. 根拠づけ | レスポンスには、推論コンテキストと推論命令からの情報のみが含まれているか。 |
| 3. 包括的 | モデルは、要約でキーとなる詳細をどの程度キャプチャしているか。 |
| 4. 概要 | 要約が冗長でないか。過度に飾り立てた表現が含まれていないか。過度に簡潔すぎないか。 |
質問応答
question_answering タスクの入力トークンの上限は 4,096 です。
question_answering の評価基準は次のとおりです。
| 条件 | |
|---|---|
| 1. 質問に十分に回答している | 答えが完全に質問に対応している。 |
| 2. 根拠づけ | レスポンスには、命令コンテキストと推論命令からの情報のみが含まれているか。 |
| 3. 関連性 | 回答の内容は質問と関連しているか。 |
| 4. 包括的 | モデルは、質問でキーとなる詳細をどの程度キャプチャしているか。 |
AutoSxS の評価データセットを準備する
このセクションでは、AutoSxS 評価データセットで提供する必要があるデータと、データセット構築のベスト プラクティスについて詳しく説明します。この例は、本番環境においてモデルが遭遇する可能性のある実際の入力を反映し、実際のモデルの動作を最適に対比する必要があります。
データセットのフォーマット
AutoSxS は、柔軟なスキーマを持つ単一の評価データセットを受け入れます。データセットは、BigQuery テーブルか、Cloud Storage の JSON Lines として保存されます。
評価データセットの各行は 1 つの例を表し、列は次のいずれかです。
- ID 列: 一意の例のそれぞれを識別するために使用します。
- データ列: プロンプト テンプレートへの記入に使用します。プロンプト パラメータをご覧ください。
- 事前に生成された予測: 同じプロンプトを使用して同じモデルによって行われた予測。事前に生成された予測を使用すると、時間とリソースを節約できます。
- 人間の好みのグラウンド トゥルース: 両方のモデルに対して事前に生成された予測が提供された場合、選択データのグラウンド トゥルースに対する AutoSxS のベンチマークに使用されます。
評価データセットの例を以下に示します。context と question はデータ列で、model_b_response には事前に生成された予測が含まれています。
context |
question |
model_b_response |
|---|---|---|
| 鋼鉄またはチタンが最も硬い素材であると考えている人もいるかもしれませんが、ダイヤモンドが実際には最も硬い素材です。 | 最も硬い素材は何ですか? | ダイヤモンドが最も硬い素材です。鋼鉄やチタンよりも硬いです。 |
AutoSxS を呼び出す方法の詳細については、モデル評価を行うをご覧ください。トークンの長さの詳細については、サポートされるタスクと基準をご覧ください。データを Cloud Storage にアップロードするには、評価データセットを Cloud Storage にアップロードするをご覧ください。
プロンプト パラメータ
多くの言語モデルでは、単一のプロンプト文字列ではなく、プロンプト パラメータを入力パラメータとして採用します。たとえば、chat-bison では、プロンプトの一部を構成する複数のプロンプト パラメータ(メッセージ、例、コンテキスト)を採用します。ただし、text-bison では、プロンプト全体を含む prompt という名前のプロンプト パラメータの 1 つのみです。
推論時と評価時にモデル プロンプト パラメータを柔軟に指定する方法について説明します。AutoSxS では、テンプレート化されたプロンプト パラメータを使用して、さまざまな想定入力がある言語モデルを柔軟に呼び出すことができます。
推論
いずれのモデルにも事前生成された予測がない場合、AutoSxS は Vertex AI Batch Prediction を使用してレスポンスを生成します。各モデルのプロンプト パラメータを指定する必要があります。
AutoSxS では、プロンプト パラメータとして評価データセットで単一の列を指定できます。
{'some_parameter': {'column': 'my_column'}}
または、評価データセットの列を変数として使用してテンプレートを定義し、プロンプト パラメータを指定することもできます。
{'some_parameter': {'template': 'Summarize the following: {{ my_column }}.'}}
推論のモデル プロンプト パラメータを指定する場合、ユーザーは保護された default_instruction キーワードをテンプレート引数として使用できます。特定のタスクのデフォルトの推論命令と置き換えます。
model_prompt_parameters = {
'prompt': {'template': '{{ default_instruction }}: {{ context }}'},
}
予測を生成する場合は、モデル プロンプト パラメータと出力列を指定します。次の例をご覧ください。
Gemini
Gemini モデルの場合、モデル プロンプト パラメータのキーは contents(必須)と system_instruction(省略可)で、これは Gemini リクエスト本文スキーマと一致します。
model_a_prompt_parameters={
'contents': {
'column': 'context'
},
'system_instruction': {'template': '{{ default_instruction }}'},
},
text-bison
たとえば、text-bison は入力に「prompt」、出力に「content」を使用します。手順は次のとおりです。
- 評価対象のモデルに必要な入力と出力を特定します。
- 入力をモデルのプロンプト パラメータとして定義します。
- 出力をレスポンス列に渡します。
model_a_prompt_parameters={
'prompt': {
'template': {
'Answer the following question from the point of view of a college professor: {{ context }}\n{{ question }}'
},
},
},
response_column_a='content', # Column in Model A response.
response_column_b='model_b_response', # Column in eval dataset.
評価
推論のプロンプト パラメータを指定する必要があるのと同じように、評価のプロンプト パラメータも指定する必要があります。自動評価では、次のプロンプト パラメータが必要です。
| 自動評価プロンプト パラメータ | ユーザーによる構成可否 | 説明 | 例 |
|---|---|---|---|
| 自動評価の指示 | × | 特定のレスポンスを判定するために自動評価が使用する基準を記述している調整された指示。 | 質問に回答し、最も指示に従っているレスポンスを選びます。 |
| 推論命令 | ○ | 各候補モデルが行うタスクの説明。 | 「最も硬い素材は何ですか?」という質問に正確に回答します。 |
| 推論コンテキスト | ○ | 実行されているタスクの追加コンテキスト。 | チタンとダイヤモンドはどちらも銅よりも硬いですが、ダイヤモンドの硬度評価は 98 で、チタンの評価は 36 です。評価が高いほど硬度が高くなります。 |
| レスポンス | ×1 | 評価するレスポンスのペア(各候補モデルから 1 つずつ)。 | ダイヤモンド |
1プロンプト パラメータは、事前に生成されたレスポンスを使用してのみ構成できます。
パラメータを使用したサンプルコード:
autorater_prompt_parameters={
'inference_instruction': {
'template': 'Answer the following question from the point of view of a college professor: {{ question }}.'
},
'inference_context': {
'column': 'context'
}
}
モデル A と B は、同じ情報が提供されるかどうかにかかわらず、異なる形式の推論命令とコンテキストを持つことができます。つまり、自動評価は独立した 1 つの推論命令とコンテキストを用います。
評価データセットの例
このセクションでは、モデル B に対して事前に生成された予測を含む、質問応答タスク評価データセットの例を示します。この例では、AutoSxS はモデル A に対してのみ推論を行います。同じ質問の例とコンテキストで区別するために id 列を提供します。
{
"id": 1,
"question": "What is the hardest material?",
"context": "Some might think that steel is the hardest material, or even titanium. However, diamond is actually the hardest material.",
"model_b_response": "Diamond is the hardest material. It is harder than steel or titanium."
}
{
"id": 2,
"question": "What is the highest mountain in the world?",
"context": "K2 and Everest are the two tallest mountains, with K2 being just over 28k feet and Everest being 29k feet tall.",
"model_b_response": "Mount Everest is the tallest mountain, with a height of 29k feet."
}
{
"id": 3,
"question": "Who directed The Godfather?",
"context": "Mario Puzo and Francis Ford Coppola co-wrote the screenplay for The Godfather, and the latter directed it as well.",
"model_b_response": "Francis Ford Coppola directed The Godfather."
}
{
"id": 4,
"question": "Who directed The Godfather?",
"context": "Mario Puzo and Francis Ford Coppola co-wrote the screenplay for The Godfather, and the latter directed it as well.",
"model_b_response": "John Smith."
}
ベスト プラクティス
評価データセットを定義する際は、次のベスト プラクティスに従ってください。
- 本番環境で処理するモデルの入力タイプを表す例を提供します。
- データセットには少なくとも 1 つの評価例が含まれている必要があります。高品質の集計指標を確保するために、約 100 個の例をおすすめします。集約指標の品質改善率は、400 を超える例を指定すると減少する傾向があります。
- プロンプトの作成ガイドについては、テキスト プロンプトを設計するをご覧ください。
- いずれかのモデルで事前生成された予測を使用している場合は、評価データセットの列に事前生成された予測を含めます。事前生成された予測を提供すると、Vertex Model Registry にないモデルの出力を比較し、レスポンスを再利用できるため、便利です。
モデル評価を行う
モデルを評価するには、REST API、Vertex AI SDK for Python、またはGoogle Cloud コンソールを使用します。
次の構文を使用して、モデルのパスを指定します。
- パブリッシャーのモデル:
publishers/PUBLISHER/models/MODEL例:publishers/google/models/text-bison チューニング済みモデル:
projects/PROJECT_NUMBER/locations/LOCATION/models/MODEL@VERSION例:projects/123456789012/locations/us-central1/models/1234567890123456789
REST
モデル評価ジョブを作成するには、pipelineJobs メソッドを使用して POST リクエストを送信します。
リクエストのデータを使用する前に、次のように置き換えます。
- PIPELINEJOB_DISPLAYNAME :
pipelineJobの表示名。 - PROJECT_ID :パイプライン コンポーネントを実行する Google Cloud プロジェクト。
- LOCATION: パイプライン コンポーネントを実行するリージョン。
us-central1がサポートされています。 - OUTPUT_DIR: 評価出力を保存する Cloud Storage URI。
- EVALUATION_DATASET : BigQuery テーブル、または評価例を含む JSONL データセットへの Cloud Storage パスのカンマ区切りのリスト。
- TASK: 評価タスク。
[summarization, question_answering]のいずれかを指定できます。 - ID_COLUMNS : 各評価例を区別する列。
- AUTORATER_PROMPT_PARAMETERS : 列またはテンプレートにマッピングされた自動評価プロンプト パラメータ。想定されるパラメータは
inference_instruction(タスクを行う方法の詳細)とinference_context(タスクの実行に関するコンテンツ)です。たとえば、{'inference_context': {'column': 'my_prompt'}}は、自動評価のコンテキストに対して評価データセットの「my_prompt」列を使用します。 - RESPONSE_COLUMN_A : 事前定義された予測を含む評価データセットの列の名前、または予測を含むモデル A の出力の列の名前。値が指定されていない場合は、正しいモデル出力列名の推定が試行されます。
- RESPONSE_COLUMN_B : 事前定義された予測を含む評価データセットの列の名前、または予測を含むモデル B の出力の列の名前。値が指定されていない場合は、正しいモデル出力列名の推定が試行されます。
- MODEL_A(省略可): 完全修飾モデルリソース名(
projects/{project}/locations/{location}/models/{model}@{version})またはパブリッシャー モデル リソース名(publishers/{publisher}/models/{model})。モデル A のレスポンスが指定されている場合は、このパラメータを指定しないでください。 - MODEL_B(省略可): 完全修飾モデルリソース名(
projects/{project}/locations/{location}/models/{model}@{version})またはパブリッシャー モデル リソース名(publishers/{publisher}/models/{model})。モデル B のレスポンスが指定されている場合は、このパラメータを指定しないでください。 - MODEL_A_PROMPT_PARAMETERS(省略可): 列またはテンプレートにマッピングされたモデル A のプロンプト テンプレート パラメータ。モデル A のレスポンスが事前定義されている場合、このパラメータは指定しないでください。例:
{'prompt': {'column': 'my_prompt'}}は、promptという名前のプロンプト パラメータに評価データセットのmy_prompt列を使用します。 - MODEL_B_PROMPT_PARAMETERS(省略可): 列またはテンプレートにマッピングされたモデル B のプロンプト テンプレート パラメータ。モデル B のレスポンスが事前定義されている場合、このパラメータは指定しないでください。例:
{'prompt': {'column': 'my_prompt'}}は、promptという名前のプロンプト パラメータに評価データセットのmy_prompt列を使用します。 - JUDGMENTS_FORMAT
(省略可): 判定結果を書き込む形式。
jsonl(デフォルト)まか、jsonまたはbigqueryを指定できます。 - BIGQUERY_DESTINATION_PREFIX: 指定された形式が
bigqueryの場合に判定結果を書き込む BigQuery テーブル。
リクエストの本文(JSON)
{
"displayName": "PIPELINEJOB_DISPLAYNAME",
"runtimeConfig": {
"gcsOutputDirectory": "gs://OUTPUT_DIR",
"parameterValues": {
"evaluation_dataset": "EVALUATION_DATASET",
"id_columns": ["ID_COLUMNS"],
"task": "TASK",
"autorater_prompt_parameters": AUTORATER_PROMPT_PARAMETERS,
"response_column_a": "RESPONSE_COLUMN_A",
"response_column_b": "RESPONSE_COLUMN_B",
"model_a": "MODEL_A",
"model_a_prompt_parameters": MODEL_A_PROMPT_PARAMETERS,
"model_b": "MODEL_B",
"model_b_prompt_parameters": MODEL_B_PROMPT_PARAMETERS,
"judgments_format": "JUDGMENTS_FORMAT",
"bigquery_destination_prefix":BIGQUERY_DESTINATION_PREFIX,
},
},
"templateUri": "https://us-kfp.pkg.dev/ml-pipeline/google-cloud-registry/autosxs-template/default"
}
curl を使用してリクエストを送信します。
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/pipelineJobs"
レスポンス
"state": "PIPELINE_STATE_PENDING",
"labels": {
"vertex-ai-pipelines-run-billing-id": "1234567890123456789"
},
"runtimeConfig": {
"gcsOutputDirectory": "gs://my-evaluation-bucket/output",
"parameterValues": {
"evaluation_dataset": "gs://my-evaluation-bucket/output/data.json",
"id_columns": [
"context"
],
"task": "question_answering",
"autorater_prompt_parameters": {
"inference_instruction": {
"template": "Answer the following question: {{ question }} }."
},
"inference_context": {
"column": "context"
}
},
"response_column_a": "",
"response_column_b": "response_b",
"model_a": "publishers/google/models/text-bison@002",
"model_a_prompt_parameters": {
"prompt": {
"template": "Answer the following question from the point of view of a college professor: {{ question }}\n{{ context }} }"
}
},
"model_b": "",
"model_b_prompt_parameters": {}
}
},
"serviceAccount": "123456789012-compute@developer.gserviceaccount.com",
"templateUri": "https://us-kfp.pkg.dev/ml-pipeline/google-cloud-registry/autosxs-template/default",
"templateMetadata": {
"version": "sha256:7366b784205551ed28f2c076e841c0dbeec4111b6df16743fc5605daa2da8f8a"
}
}
Vertex AI SDK for Python
Vertex AI SDK for Python のインストールまたは更新の方法については、Vertex AI SDK for Python をインストールするをご覧ください。Python API の詳細については、Vertex AI SDK for Python API をご覧ください。
パイプライン パラメータの詳細については、Google Cloud パイプライン コンポーネントのリファレンス ドキュメントをご覧ください。
リクエストのデータを使用する前に、次のように置き換えます。
- PIPELINEJOB_DISPLAYNAME :
pipelineJobの表示名。 - PROJECT_ID :パイプライン コンポーネントを実行する Google Cloud プロジェクト。
- LOCATION: パイプライン コンポーネントを実行するリージョン。
us-central1がサポートされています。 - OUTPUT_DIR: 評価出力を保存する Cloud Storage URI。
- EVALUATION_DATASET : BigQuery テーブル、または評価例を含む JSONL データセットへの Cloud Storage パスのカンマ区切りのリスト。
- TASK: 評価タスク。
[summarization, question_answering]のいずれかを指定できます。 - ID_COLUMNS : 各評価例を区別する列。
- AUTORATER_PROMPT_PARAMETERS : 列またはテンプレートにマッピングされた自動評価プロンプト パラメータ。想定されるパラメータは
inference_instruction(タスクを行う方法の詳細)とinference_context(タスクの実行に関するコンテンツ)です。たとえば、{'inference_context': {'column': 'my_prompt'}}は、自動評価のコンテキストに対して評価データセットの「my_prompt」列を使用します。 - RESPONSE_COLUMN_A : 事前定義された予測を含む評価データセットの列の名前、または予測を含むモデル A の出力の列の名前。値が指定されていない場合は、正しいモデル出力列名の推定が試行されます。
- RESPONSE_COLUMN_B : 事前定義された予測を含む評価データセットの列の名前、または予測を含むモデル B の出力の列の名前。値が指定されていない場合は、正しいモデル出力列名の推定が試行されます。
- MODEL_A(省略可): 完全修飾モデルリソース名(
projects/{project}/locations/{location}/models/{model}@{version})またはパブリッシャー モデル リソース名(publishers/{publisher}/models/{model})。モデル A のレスポンスが指定されている場合は、このパラメータを指定しないでください。 - MODEL_B(省略可): 完全修飾モデルリソース名(
projects/{project}/locations/{location}/models/{model}@{version})またはパブリッシャー モデル リソース名(publishers/{publisher}/models/{model})。モデル B のレスポンスが指定されている場合は、このパラメータを指定しないでください。 - MODEL_A_PROMPT_PARAMETERS(省略可): 列またはテンプレートにマッピングされたモデル A のプロンプト テンプレート パラメータ。モデル A のレスポンスが事前定義されている場合、このパラメータは指定しないでください。例:
{'prompt': {'column': 'my_prompt'}}は、promptという名前のプロンプト パラメータに評価データセットのmy_prompt列を使用します。 - MODEL_B_PROMPT_PARAMETERS(省略可): 列またはテンプレートにマッピングされたモデル B のプロンプト テンプレート パラメータ。モデル B のレスポンスが事前定義されている場合、このパラメータは指定しないでください。例:
{'prompt': {'column': 'my_prompt'}}は、promptという名前のプロンプト パラメータに評価データセットのmy_prompt列を使用します。 - JUDGMENTS_FORMAT
(省略可): 判定結果を書き込む形式。
jsonl(デフォルト)まか、jsonまたはbigqueryを指定できます。 - BIGQUERY_DESTINATION_PREFIX: 指定された形式が
bigqueryの場合に判定結果を書き込む BigQuery テーブル。
import os
from google.cloud import aiplatform
parameters = {
'evaluation_dataset': 'EVALUATION_DATASET',
'id_columns': ['ID_COLUMNS'],
'task': 'TASK',
'autorater_prompt_parameters': AUTORATER_PROMPT_PARAMETERS,
'response_column_a': 'RESPONSE_COLUMN_A',
'response_column_b': 'RESPONSE_COLUMN_B',
'model_a': 'MODEL_A',
'model_a_prompt_parameters': MODEL_A_PROMPT_PARAMETERS,
'model_b': 'MODEL_B',
'model_b_prompt_parameters': MODEL_B_PROMPT_PARAMETERS,
'judgments_format': 'JUDGMENTS_FORMAT',
'bigquery_destination_prefix':
BIGQUERY_DESTINATION_PREFIX,
}
aiplatform.init(project='PROJECT_ID', location='LOCATION', staging_bucket='gs://OUTPUT_DIR')
aiplatform.PipelineJob(
display_name='PIPELINEJOB_DISPLAYNAME',
pipeline_root=os.path.join('gs://OUTPUT_DIR', 'PIPELINEJOB_DISPLAYNAME'),
template_path=(
'https://us-kfp.pkg.dev/ml-pipeline/google-cloud-registry/autosxs-template/default'),
parameter_values=parameters,
).run()
コンソール
Google Cloud コンソールでペアワイズ モデル評価ジョブを作成するには、次の手順で操作します。
Google 基盤モデルから始めるか、Vertex AI Model Registry にすでに存在するモデルを使用します。
Google 基盤モデルを評価するには:
Vertex AI Model Garden に移動し、ペアワイズ評価をサポートするモデル(
text-bisonなど)を選択します。[評価] をクリックします。
表示されたメニューで [選択] をクリックして、モデル バージョンを選択します。
[モデルを保存] ペインで、モデルのコピーがまだない場合は、Vertex AI Model Registry にモデルのコピーを保存するよう求められることがあります。モデル名を入力し、[保存] をクリックします。
[評価の作成] ページが表示されます。[Evaluate Method] ステップで、[このモデルを別のモデルと比較して評価する] を選択します。
[続行] をクリックします。
Vertex AI Model Registry で既存のモデルを評価するには:
[Vertex AI Model Registry] ページに移動します。
評価するモデルの名前をクリックします。モデルタイプがペアワイズ評価をサポートしていることを確認します。たとえば、
text-bisonです。[評価] タブで [SxS] をクリックします。
[SxS 評価を作成] をクリックします。
評価の作成ページの各ステップで、必要な情報を入力し、[続行] をクリックします。
[評価データセット] ステップで、評価目標と、選択したモデルと比較するモデルを選択します。評価データセットを選択し、ID 列(レスポンス列)を入力します。
[モデル設定] ステップで、データセットにすでに存在するモデル レスポンスを使用するか、Vertex AI Batch Prediction を使用してレスポンスを生成するかを指定します。両方のモデルのレスポンス列を指定します。Vertex AI バッチ予測オプションでは、推論モデル プロンプト パラメータを指定できます。
[自動評価の設定] ステップで、自動評価のプロンプト パラメータと評価の出力場所を入力します。
[評価を開始] をクリックします。
評価の結果を表示する
Vertex AI Pipelines で評価結果を確認するには、AutoSxS パイプラインによって生成された次のアーティファクトを調べます。
- 判定テーブルは、AutoSxS アービターによって生成されます。
- 集約指標は、AutoSxS 指標コンポーネントによって生成されます。
- 人間の好みのアライメント指標は、AutoSxS 指標コンポーネントによって生成されます。
判定
AutoSxS は、ユーザーがサンプルレベルでモデルのパフォーマンスを理解できるよう判定(サンプルレベルの指標)を出力します。判定には次の情報が含まれます。
- 推論プロンプト
- モデルのレスポンス
- 自動評価の決定
- 評価の説明
- 信頼性スコア
判定は、JSONL 形式で Cloud Storage に、または次の列を使用して BigQuery テーブルに書き込むことができます。
| 列 | 説明 |
|---|---|
| ID 列 | 各評価例を区別する列。 |
inference_instruction |
モデル レスポンスの生成に使用する命令。 |
inference_context |
モデル レスポンスの生成に使用するコンテキスト。 |
response_a |
推論命令とコンテキストが指定されたモデル A のレスポンス。 |
response_b |
推論命令とコンテキストが指定されたモデル B のレスポンス。 |
choice |
より良いレスポンスを持つモデル。指定可能な値は Model A、Model B、Error です。Error は、エラーによって自動評価がモデル A のレスポンスとモデル B のレスポンスのどちらが最適かを判断できなかったことを意味します。 |
confidence |
0~1 のスコア。自動評価が選択した信頼度を示します。 |
explanation |
自動評価がそれを選択した理由。 |
集約指標
AutoSxS では、判定テーブルを使用して集約(勝率)指標を計算します。人間の好みのデータが指定されていない場合、次の集約指標が生成されます。
| 指標 | 説明 |
|---|---|
| 自動評価モデル A の勝率 | 自動評価がモデル A のレスポンスの方が優れていると判定した時間の割合。 |
| 自動評価モデル B の勝率 | 自動評価がモデル B のレスポンスの方が優れていると判定した時間の割合。 |
勝率をより深く理解するには、行ベースの結果と自動評価の説明を確認して、結果と説明が期待どおりであるかどうかを判断します。
人間の好みのアライメント指標
人間の好みのデータが指定されている場合、AutoSxS は次の指標を出力します。
| 指標 | 説明 | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 自動評価モデル A の勝率 | 自動評価がモデル A のレスポンスの方が優れていると判定した時間の割合。 | ||||||||||||||
| 自動評価モデル B の勝率 | 自動評価がモデル B のレスポンスの方が優れていると判定した時間の割合。 | ||||||||||||||
| 人間の好みのモデル A の勝率 | 人間がモデル A のレスポンスの方が優れていると判定した時間の割合。 | ||||||||||||||
| 人間の選好のモデル B の勝率 | 人間がモデル B のレスポンスの方が優れていると判定した時間の割合。 | ||||||||||||||
| TP | 自動評価と人間の好みの両方が、モデル A のレスポンスの方が良いと判定したサンプル数。 | ||||||||||||||
| FP | 自動評価がモデル A をより良いレスポンスとして選択したものの、人間の選好はモデル B の方がより良いレスポンスであるとしたサンプル数。 | ||||||||||||||
| TN | 自動評価と人間の好みの両方が、モデル B のレスポンスの方が良いと判定したサンプル数。 | ||||||||||||||
| FN | 自動評価がモデル B をより良いレスポンスとして選択したものの、人間の選好はモデル A の方がより良いレスポンスであるとしたサンプル数。 | ||||||||||||||
| 精度 | 自動評価が人間の評価者と合意した時間の割合。 | ||||||||||||||
| 適合率 | 自動評価がモデル A のレスポンスの方が良いと考えたすべてのケースのうち、自動評価と人間の両方がモデル A の方が良いレスポンスであると考えた時間の割合。 | ||||||||||||||
| 再現率 | 人間がモデル A のレスポンスの方が良いと考えたすべてのケースのうち、自動評価と人間の両方がモデル A の方が良いレスポンスであると考えた時間の割合。 | ||||||||||||||
| F1 | 適合率と再現率の調和平均。 | ||||||||||||||
| コーエンのカッパ係数 | ランダムな一致の可能性を考慮した、自動評価と人間の評価者の一致の測定値。コーエンは次のように解釈します。
|
AutoSxS のユースケース
3 つのユースケース シナリオを使って AutoSxS の使用方法を確認します。
モデルを比較する
ファースト パーティ(1p)のリファレンス モデルに対して調整された 1p モデルを評価します。
推論が両方のモデルで同時に実行されるように指定できます。
このコードサンプルは、Vertex Model Registry の調整されたモデルを、同じレジストリのリファレンス モデルに対して評価します。
# Evaluation dataset schema:
# my_question: str
# my_context: str
parameters = {
'evaluation_dataset': DATASET,
'id_columns': ['my_context'],
'task': 'question_answering',
'autorater_prompt_parameters': {
'inference_instruction': {'column': 'my_question'},
'inference_context': {'column': 'my_context'},
},
'model_a': 'publishers/google/models/text-bison@002',
'model_a_prompt_parameters': {QUESTION: {'template': '{{my_question}}\nCONTEXT: {{my_context}}'}},
'response_column_a': 'content',
'model_b': 'projects/abc/locations/abc/models/tuned_bison',
'model_b_prompt_parameters': {'prompt': {'template': '{{my_context}}\n{{my_question}}'}},
'response_column_b': 'content',
}
予測を比較する
3p のリファレンス モデルに対して、調整されたサードパーティ(3p)モデルを評価します。
モデルのレスポンスを直接渡すことで、推論をスキップできます。
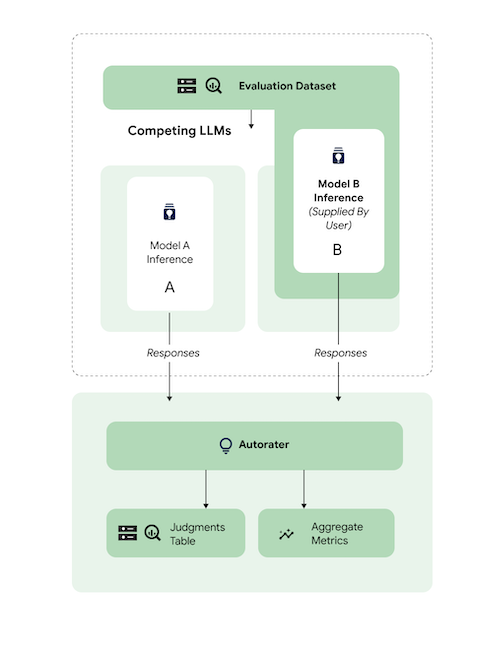
このコードサンプルは、3p のリファレンス モデルに対して調整された 3p モデルを評価します。
# Evaluation dataset schema:
# my_question: str
# my_context: str
# response_b: str
parameters = {
'evaluation_dataset': DATASET,
'id_columns': ['my_context'],
'task': 'question_answering',
'autorater_prompt_parameters':
'inference_instruction': {'column': 'my_question'},
'inference_context': {'column': 'my_context'},
},
'response_column_a': 'content',
'response_column_b': 'response_b',
}
アライメントを確認する
サポートされているすべてのタスクは、自動評価のレスポンスが人間の好みと一致するように、人間の評価者データを使用してベンチマークされています。ユースケースに対して AutoSxS のベンチマークを行う場合は、人間の好みのデータを AutoSxS に直接提供してください。これにより、アライメント集計の統計情報が出力されます。
人間の好みのデータセットとのアライメントを確認するには、両方の出力(予測結果)を自動評価に指定します。推論の結果を提供することもできます。
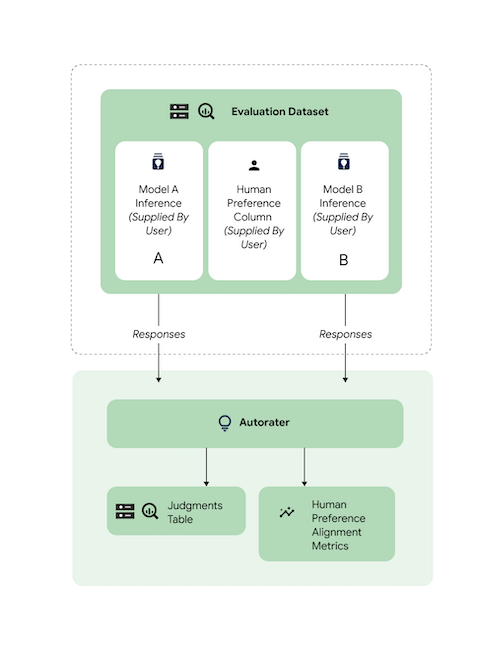
このコードサンプルは、自動評価の結果と説明が想定どおりの内容であることを確認します。
# Evaluation dataset schema:
# my_question: str
# my_context: str
# response_a: str
# response_b: str
# actual: str
parameters = {
'evaluation_dataset': DATASET,
'id_columns': ['my_context'],
'task': 'question_answering',
'autorater_prompt_parameters': {
'inference_instruction': {'column': 'my_question'},
'inference_context': {'column': 'my_context'},
},
'response_column_a': 'response_a',
'response_column_b': 'response_b',
'human_preference_column': 'actual',
}
次のステップ
- 生成 AI の評価について学習する。
- Gen AI Evaluation Service によるオンライン評価について確認する。
- 言語基盤モデルのチューニング方法を確認する。