Puedes usar el SDK de Vertex AI para Python a fin de evaluar de manera programática tus modelos de lenguaje generativo.
Instala el SDK de Vertex AI
Si deseas instalar la evaluación rápida desde el SDK de Vertex AI para Python, ejecuta el siguiente comando:
pip install --upgrade google-cloud-aiplatform[rapid_evaluation]
Si quieres obtener más información, consulta Instala el SDK de Vertex AI para Python.
Autentica el SDK de Vertex AI
Después de instalar el SDK de Vertex AI para Python, debes autenticarte. En los siguientes temas, se explica cómo autenticar con el SDK de Vertex AI si trabajas de forma local y en Colaboratory:
Si desarrollas de manera local, configura las credenciales predeterminadas de la aplicación (ADC) en tu entorno local:
Instala Google Cloud CLI y, luego, inicialízala a través de la ejecución del siguiente comando:
gcloud initCrea credenciales de autenticación locales para tu Cuenta de Google:
gcloud auth application-default loginSe muestra una pantalla de acceso. Después de acceder, tus credenciales se almacenan en el archivo de credenciales local que usa ADC. Para obtener más información sobre cómo trabajar con ADC en un entorno local, consulta Entorno de desarrollo local.
Si trabajas en Colaboratory, ejecuta el siguiente comando en una celda de Colab para autenticarte:
from google.colab import auth auth.authenticate_user()Este comando abre una ventana en la que puedes completar la autenticación.
Consulta la referencia del SDK de evaluación rápida para obtener más información sobre el SDK de evaluación rápida.
Crea una tarea de evaluación
Debido a que la evaluación se basa en su mayoría en las tareas con los modelos de IA generativa, la evaluación en línea presenta la abstracción de las tareas de evaluación para facilitar los casos de uso de evaluación. A fin de obtener comparaciones justas para los modelos generativos, por lo general, puedes ejecutar evaluaciones de modelos y solicitar plantillas en un conjunto de datos de evaluación y sus métricas asociadas de forma repetida. La clase EvalTask está diseñada para admitir este nuevo paradigma de evaluación. Además, EvalTask te permite integrar sin problemas en Vertex AI Experiments, que puede ayudar a hacer un seguimiento de la configuración y los resultados de cada ejecución de la evaluación.
Vertex AI Experiments puede ayudarte a interpretar y administrar los resultados de la evaluación, lo que te permite tomar medidas en menos tiempo. En el siguiente ejemplo, se muestra cómo crear una instancia de la clase EvalTask y ejecutar una evaluación:
from vertexai.preview.evaluation import EvalTask
eval_task = EvalTask(
dataset=DATASET,
metrics=["bleu", "rouge_l_sum"],
experiment=EXPERIMENT_NAME
)
El parámetro metrics acepta una lista de métricas, lo que permite la evaluación simultánea de varias métricas en una sola llamada de evaluación.
Preparación del conjunto de datos de evaluación
Los conjuntos de datos se pasan a una instancia EvalTask como un DataFrame de Pandas, donde cada fila representa un ejemplo de evaluación separado (llamado instancia) y cada columna representa un parámetro de entrada de métrica. Consulta métricas para ver las entradas que espera cada métrica. Proporcionamos varios ejemplos a fin de compilar el conjunto de datos de evaluación para diferentes tareas de evaluación.
Evaluación de resúmenes
Construye un conjunto de datos para un resumen puntual con las siguientes métricas:
summarization_qualitygroundednessfulfillmentsummarization_helpfulnesssummarization_verbosity
Teniendo en cuenta los parámetros de entrada de métricas necesarios, debes incluir las siguientes columnas en nuestro conjunto de datos de evaluación:
instructioncontextresponse
En este ejemplo, tenemos dos instancias de resumen. Crea los campos instruction y context como entradas, que son necesarias para las evaluaciones de tareas de resumen:
instructions = [
# example 1
"Summarize the text in one sentence.",
# example 2
"Summarize the text such that a five-year-old can understand.",
]
contexts = [
# example 1
"""As part of a comprehensive initiative to tackle urban congestion and foster
sustainable urban living, a major city has revealed ambitious plans for an
extensive overhaul of its public transportation system. The project aims not
only to improve the efficiency and reliability of public transit but also to
reduce the city\'s carbon footprint and promote eco-friendly commuting options.
City officials anticipate that this strategic investment will enhance
accessibility for residents and visitors alike, ushering in a new era of
efficient, environmentally conscious urban transportation.""",
# example 2
"""A team of archaeologists has unearthed ancient artifacts shedding light on a
previously unknown civilization. The findings challenge existing historical
narratives and provide valuable insights into human history.""",
]
Si tienes tu respuesta de LLM (el resumen) lista y deseas realizar una evaluación del uso de tu propia predicción (BYOP), puedes crear tu entrada de respuesta de la siguiente manera:
responses = [
# example 1
"A major city is revamping its public transportation system to fight congestion, reduce emissions, and make getting around greener and easier.",
# example 2
"Some people who dig for old things found some very special tools and objects that tell us about people who lived a long, long time ago! What they found is like a new puzzle piece that helps us understand how people used to live.",
]
Con estas entradas, estamos listos para crear nuestro conjunto de datos de evaluación y EvalTask.
eval_dataset = pd.DataFrame(
{
"instruction": instructions,
"context": contexts,
"response": responses,
}
)
eval_task = EvalTask(
dataset=eval_dataset,
metrics=[
'summarization_quality',
'groundedness',
'fulfillment',
'summarization_helpfulness',
'summarization_verbosity'
],
experiment=EXPERIMENT_NAME
)
Evaluación general de la generación de texto
Algunas métricas basadas en modelos, como coherence, fluency y safety, solo necesitan la respuesta del modelo para evaluar la calidad:
eval_dataset = pd.DataFrame({
"response": ["""The old lighthouse, perched precariously on the windswept cliff,
had borne witness to countless storms. Its once-bright beam, now dimmed by time
and the relentless sea spray, still flickered with stubborn defiance."""]
})
eval_task = EvalTask(
dataset=eval_dataset,
metrics=["coherence", "fluency", "safety"],
experiment=EXPERIMENT_NAME
)
Evaluación basada en procesamiento
Las métricas basadas en procesamiento, como la coincidencia exacta, bleu y rouge, comparan una respuesta a una referencia y, según corresponda, necesitan campos de respuesta y referencia en el conjunto de datos de evaluación:
eval_dataset = pd.DataFrame({
"response": ["The Roman Senate was filled with exuberance due to Pompey's defeat in Asia."],
"reference": ["The Roman Senate was filled with exuberance due to successes against Catiline."],
})
eval_task = EvalTask(
dataset=eval_dataset,
metrics=["exact_match", "bleu", "rouge"],
experiment=EXPERIMENT_NAME
)
Evaluación de uso de herramientas
Para la evaluación del uso de herramientas, solo debes incluir la respuesta y la referencia en el conjunto de datos de evaluación.
eval_dataset = pd.DataFrame({
"response": ["""{
"content": "",
"tool_calls":[{
"name":"get_movie_info",
"arguments": {"movie":"Mission Impossible", "time": "today 7:30PM"}
}]
}"""],
"reference": ["""{
"content": "",
"tool_calls":[{
"name":"book_tickets",
"arguments":{"movie":"Mission Impossible", "time": "today 7:30PM"}
}]
}"""],
})
eval_task = EvalTask(
dataset=eval_dataset,
metrics=["tool_call_valid", "tool_name_match", "tool_parameter_key_match",
"tool_parameter_kv_match"],
experiment=EXPERIMENT_NAME
)
Conjuntos de métricas
Los conjuntos de métricas combinan métricas que se suelen asociar para ayudar a simplificar el proceso de evaluación. Las métricas se clasifican en los siguientes cuatro paquetes:
- Tareas de evaluación: resumen, búsqueda de respuestas y generación de texto
- Perspectivas de evaluación: similitud, seguridad y calidad
- Coherencia de entrada: todas las métricas del mismo paquete toman las mismas entradas del conjunto de datos.
- Paradigma de evaluación: por puntos versus por pares
Puedes usar estos paquetes de métricas en el servicio de evaluación en línea para ayudarte a optimizar tu flujo de trabajo de evaluación personalizado.
En esta tabla, se incluyen detalles sobre los paquetes de métricas disponibles:
| Nombre del paquete de métricas | Nombre de la métrica | Entrada del usuario |
|---|---|---|
text_generation_similarity |
exact_matchbleurouge |
predicción referencia |
tool_call_quality |
tool_call_validtool_name_matchtool_parameter_key_matchtool_parameter_kv_match |
predicción referencia |
text_generation_quality |
coherencefluency |
predicción |
text_generation_instruction_following |
fulfillment |
predicción referencia |
text_generation_safety |
safety |
predicción |
text_generation_factuality |
groundedness |
predicción contexto |
summarization_pointwise_reference_free |
summarization_qualitysummarization_helpfulnesssummarization_verbosity |
predicción contexto instrucción |
summary_pairwise_reference_free |
pairwise_summarization_quality |
predicción contexto instrucción |
qa_pointwise_reference_free |
question_answering_qualityquestion_answering_relevancequestion_answering_helpfulness |
predicción contexto instrucción |
qa_pointwise_reference_based |
question_answering_correctness |
predicción contexto instrucción referencia |
qa_pairwise_reference_free |
pairwise_question_answering_quality |
predicción contexto instrucción |
Visualiza los resultados de la evaluación
Después de definir la tarea de evaluación, ejecuta la tarea para obtener los resultados de la evaluación, de la siguiente manera:
eval_result: EvalResult = eval_task.evaluate(
model=MODEL,
prompt_template=PROMPT_TEMPLATE
)
La clase EvalResult representa el resultado de una ejecución de evaluación, que incluye métricas de resumen y una tabla de métricas con una instancia de conjunto de datos de evaluación y métricas por instancia correspondientes. Define la clase de la siguiente manera:
@dataclasses.dataclass
class EvalResult:
"""Evaluation result.
Attributes:
summary_metrics: the summary evaluation metrics for an evaluation run.
metrics_table: a table containing eval inputs, ground truth, and
metrics per row.
"""
summary_metrics: Dict[str, float]
metrics_table: Optional[pd.DataFrame] = None
Con el uso de funciones auxiliares, los resultados de la evaluación se pueden mostrar en el notebook de Colab.
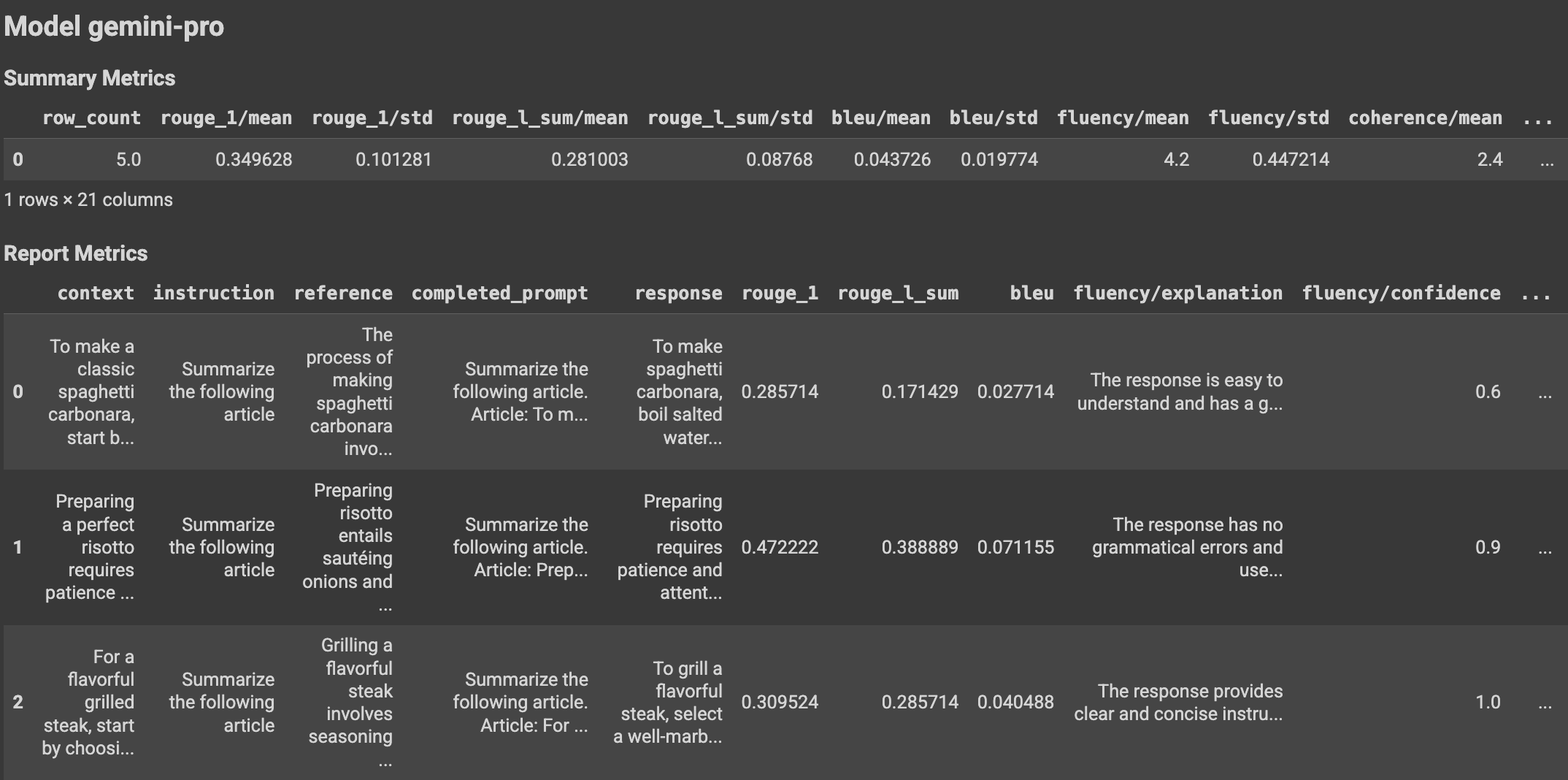
Visualizaciones
Puedes trazar las métricas de resumen en un gráfico de radar o de barras para la visualización y la comparación entre los resultados de diferentes ejecuciones de evaluación. Esta visualización puede ser útil para evaluar diferentes modelos y diferentes plantillas de instrucciones.
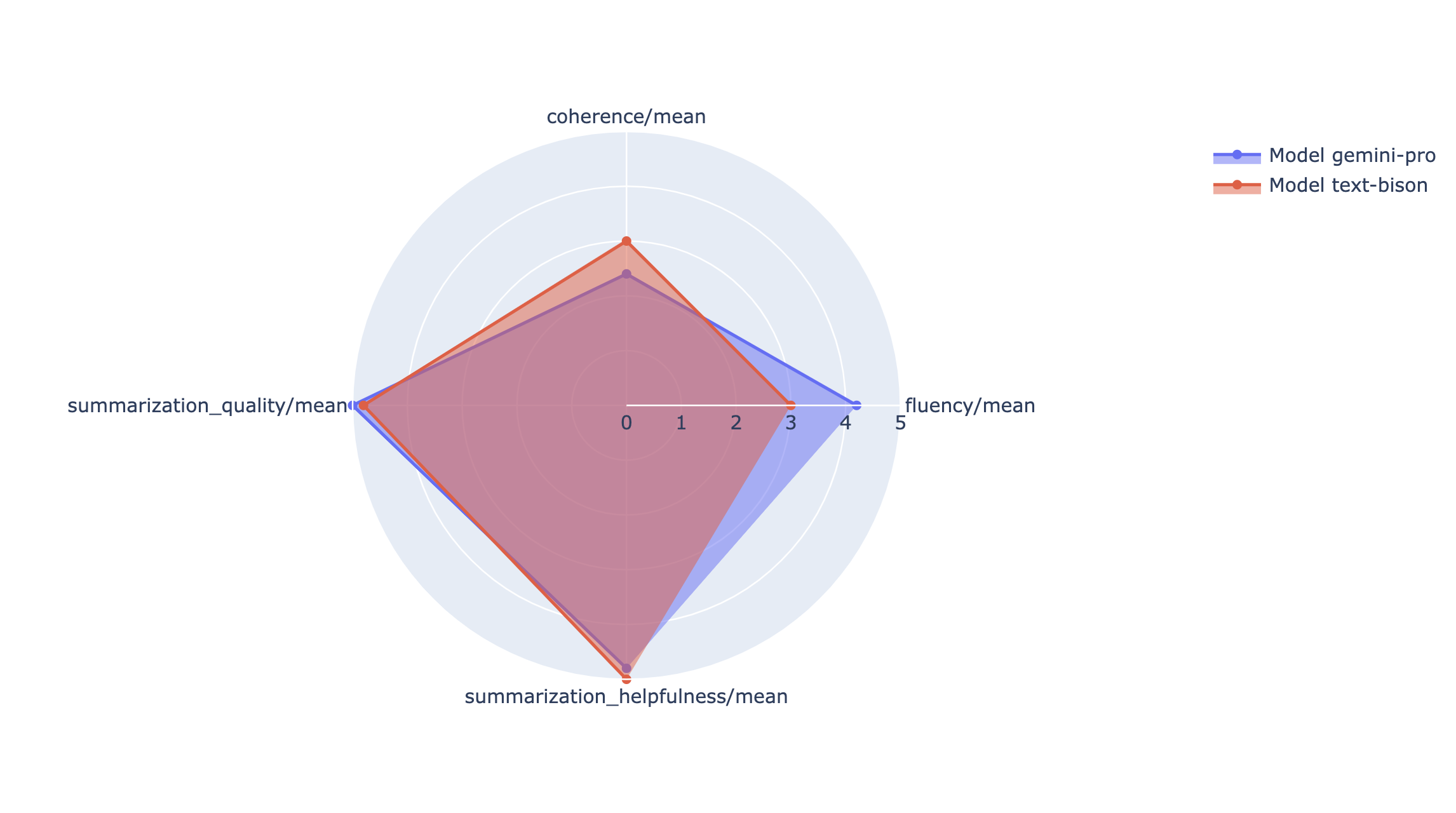
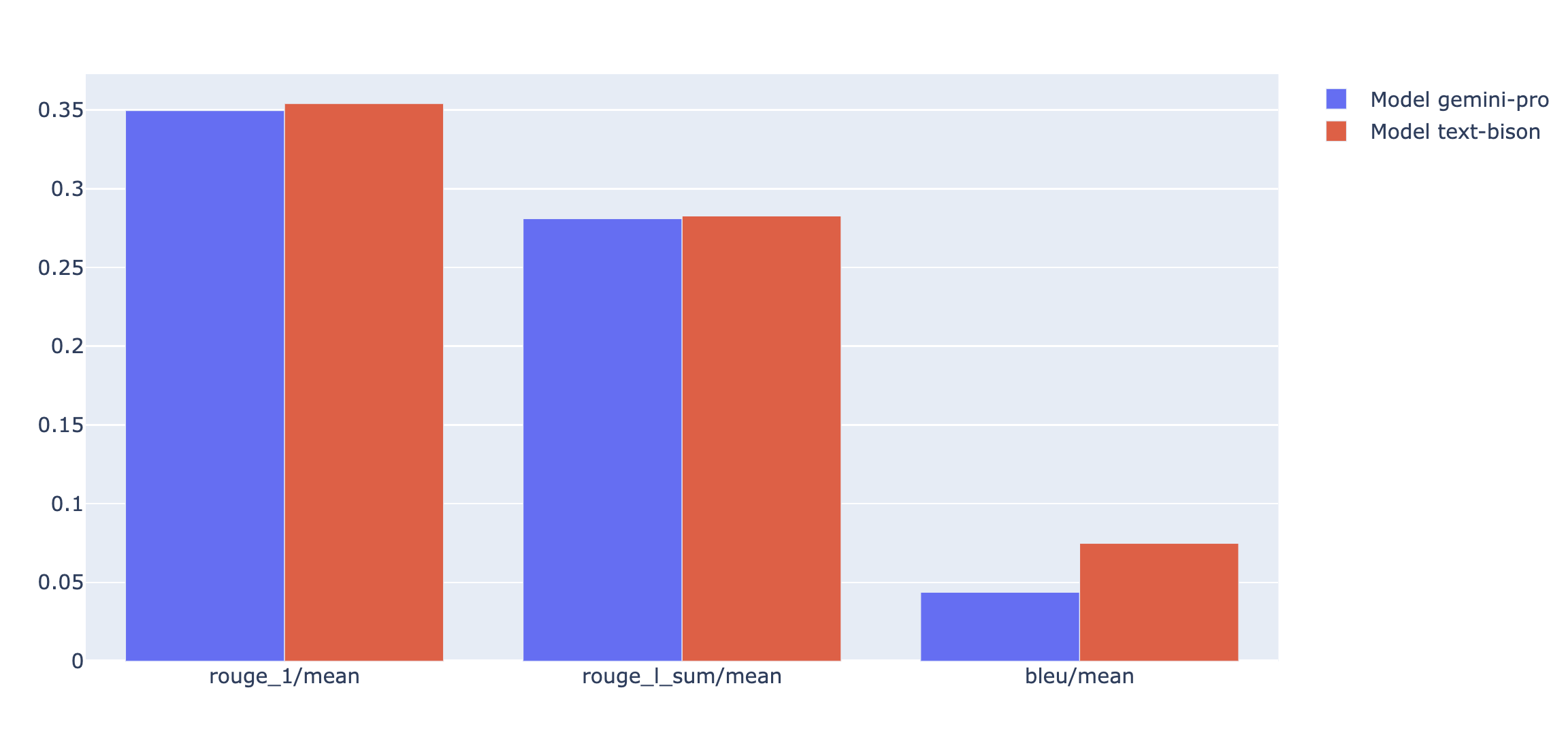
API de evaluación rápida
Para obtener información sobre la API de evaluación rápida, consulta la API de evaluación rápida.
Comprende las cuentas de servicio
El servicio de evaluación en línea usa las cuentas de servicio a fin de obtener predicciones del servicio de predicción en línea para las métricas de evaluación basadas en modelos. Esta cuenta de servicio se aprovisiona de forma automática en la primera solicitud al servicio de evaluación en línea.
| Nombre | Descripción | Dirección de correo electrónico | Rol |
|---|---|---|---|
| Agente de servicio de Rapid Eval de Vertex AI | La cuenta de servicio que se usa para obtener predicciones para la evaluación basada en modelos. | service-PROJECT_NUMBER@gcp-sa-ENV-vertex-eval.iam.gserviceaccount.com |
roles/aiplatform.rapidevalServiceAgent |
Los permisos asociados con el agente de servicio de evaluación rápida son los siguientes:
| Rol | Permisos |
|---|---|
| Agente de servicio de Rapid Eval de Vertex AI (roles/aiplatform.rapidevalServiceAgent) | aiplatform.endpoints.predict |
¿Qué sigue?
- Prueba un notebook de ejemplo de evaluación.
- Obtén información sobre la evaluación de IA generativa.
- Obtén información sobre la evaluación en pares basada en modelos con la canalización de AutoSxS.
- Obtén más información sobre la canalización de evaluación basada en procesamiento.
- Obtén información para ajustar un modelo de base.