생성형 AI 모델을 빌드하고 평가한 후에는 이 모델을 사용하여 챗봇과 같은 에이전트를 빌드할 수 있습니다. Gen AI evaluation service를 사용하면 사용 사례의 태스크와 목표를 완료하는 에이전트의 능력을 측정할 수 있습니다.
개요
다음과 같은 옵션으로 에이전트를 평가할 수 있습니다.
최종 응답 평가: 에이전트의 최종 출력(에이전트가 목표를 달성했는지 여부)을 평가합니다.
진행 경로 평가: 에이전트가 최종 응답에 도달하기 위해 취한 경로(도구 호출 시퀀스)를 평가합니다.
Gen AI Evaluation Service를 사용하면 에이전트 실행을 트리거하고 하나의 Vertex AI SDK 쿼리로 궤적 평가와 최종 응답 평가 모두에 대한 측정항목을 얻을 수 있습니다.
고객 지원 담당자
Gen AI Evaluation Service는 다음과 같은 에이전트 카테고리를 지원합니다.
| 고객 지원 담당자 | 설명 |
|---|---|
| 에이전트 엔진 템플릿으로 빌드된 에이전트 | 에이전트 엔진(Vertex AI의 LangChain)은 에이전트를 배포하고 관리할 수 있는 Google Cloud 플랫폼입니다. |
| 에이전트 엔진의 맞춤설정 가능한 템플릿을 사용하여 빌드된 LangChain 에이전트 | LangChain은 오픈소스 플랫폼입니다. |
| 커스텀 에이전트 함수 | 커스텀 에이전트 함수는 에이전트에 대한 프롬프트를 받아 사전에서 응답과 궤적을 반환하는 유연한 함수입니다. |
에이전트 평가를 위한 측정항목 정의
최종 응답 또는 궤적 평가를 위한 측정항목을 정의합니다.
최종 응답 평가
최종 응답 평가는 모델 응답 평가와 동일한 프로세스를 따릅니다. 자세한 내용은 평가 측정항목 정의를 참고하세요.
궤적 평가
다음 측정항목은 예상 궤적을 따르는 모델의 기능을 평가하는 데 도움이 됩니다.
완전 일치
예측된 궤적이 참조 궤적과 동일하고 동일한 순서로 동일한 도구 호출이 수행되면 trajectory_exact_match 측정항목은 점수 1을 반환하고, 그렇지 않으면 0을 반환합니다.
측정항목 입력 파라미터
| 입력 매개변수 | 설명 |
|---|---|
predicted_trajectory |
에이전트가 최종 응답에 도달하는 데 사용하는 도구 호출 목록입니다. |
reference_trajectory |
에이전트가 쿼리를 충족하는 데 사용할 것으로 예상되는 도구입니다. |
출력 점수
| 값 | 설명 |
|---|---|
| 0 | 예측된 궤적이 참조와 일치하지 않습니다. |
| 1 | 예측된 궤적이 참조와 일치합니다. |
순서 일치
예측된 궤적에 참조 궤적의 모든 도구 호출이 동일한 순서로 포함되어 있고 추가 도구 호출이 포함될 수도 있는 경우 trajectory_in_order_match 측정항목은 점수 1을 반환하고, 그렇지 않은 경우에는 0을 반환합니다.
측정항목 입력 파라미터
| 입력 매개변수 | 설명 |
|---|---|
predicted_trajectory |
에이전트가 최종 응답에 도달하는 데 사용하는 예측된 궤적입니다. |
reference_trajectory |
에이전트가 쿼리를 충족하기 위해 예상하는 예측된 궤도입니다. |
출력 점수
| 값 | 설명 |
|---|---|
| 0 | 예측된 궤적의 도구 호출이 참조 궤적의 순서와 일치하지 않습니다. |
| 1 | 예측된 궤적이 참조와 일치합니다. |
순서가 정해져 있지 않은 일치
예측된 궤적에 참조 궤적의 모든 도구 호출이 포함되어 있지만 순서가 중요하지 않고 추가 도구 호출이 포함될 수 있는 경우 trajectory_any_order_match 측정항목은 점수 1을 반환하고 그렇지 않은 경우에는 0을 반환합니다.
측정항목 입력 파라미터
| 입력 매개변수 | 설명 |
|---|---|
predicted_trajectory |
에이전트가 최종 응답에 도달하는 데 사용하는 도구 호출 목록입니다. |
reference_trajectory |
에이전트가 쿼리를 충족하는 데 사용할 것으로 예상되는 도구입니다. |
출력 점수
| 값 | 설명 |
|---|---|
| 0 | 예측된 궤도에 참조 궤적의 일부 도구 호출이 포함되어 있지 않습니다. |
| 1 | 예측된 궤적이 참조와 일치합니다. |
Precision
trajectory_precision 측정항목은 예측된 궤적의 도구 호출 중 참조 궤적에 따라 실제로 관련이 있거나 올바른 호출의 수를 측정합니다.
정밀도는 다음과 같이 계산됩니다. 예측된 궤적의 작업 중 참조 궤적에 표시되는 작업 수를 셉니다. 이 수를 예측된 궤적의 총 작업 수로 나눕니다.
측정항목 입력 파라미터
| 입력 매개변수 | 설명 |
|---|---|
predicted_trajectory |
에이전트가 최종 응답에 도달하는 데 사용하는 도구 호출 목록입니다. |
reference_trajectory |
에이전트가 쿼리를 충족하는 데 사용할 것으로 예상되는 도구입니다. |
출력 점수
| 값 | 설명 |
|---|---|
| [0,1] 범위의 부동 소수점 | 점수가 높을수록 예측된 궤적이 더 정확합니다. |
재현율
trajectory_recall 측정항목은 참조 궤적의 필수 도구 호출 중 예측된 궤적에 실제로 캡처된 호출 수를 측정합니다.
재현율은 다음과 같이 계산됩니다. 참조 궤적의 작업 중 예측된 궤적에 표시되는 작업 수를 셉니다. 이 수를 참조 궤적의 총 작업 수로 나눕니다.
측정항목 입력 파라미터
| 입력 매개변수 | 설명 |
|---|---|
predicted_trajectory |
에이전트가 최종 응답에 도달하는 데 사용하는 도구 호출 목록입니다. |
reference_trajectory |
에이전트가 쿼리를 충족하는 데 사용할 것으로 예상되는 도구입니다. |
출력 점수
| 값 | 설명 |
|---|---|
| [0,1] 범위의 부동 소수점 | 점수가 높을수록 예측된 궤적의 재현율이 높습니다. |
단일 도구 사용
trajectory_single_tool_use 측정항목은 측정항목 사양에 지정된 특정 도구가 예측된 궤적에 사용되는지 확인합니다. 도구 호출 순서나 도구 사용 횟수는 확인하지 않고 도구가 있는지 여부만 확인합니다.
측정항목 입력 파라미터
| 입력 매개변수 | 설명 |
|---|---|
predicted_trajectory |
에이전트가 최종 응답에 도달하는 데 사용하는 도구 호출 목록입니다. |
출력 점수
| 값 | 설명 |
|---|---|
| 0 | 도구가 없습니다. |
| 1 | 도구가 있습니다. |
또한 기본적으로 다음 두 가지 에이전트 실적 측정항목이 평가 결과에 추가됩니다. EvalTask에서는 지정할 필요가 없습니다.
latency
에이전트가 응답을 반환하는 데 걸린 시간입니다.
| 값 | 설명 |
|---|---|
| 부동 | 초 단위로 계산됩니다. |
failure
에이전트 호출이 오류를 발생시켰는지 아니면 성공했는지를 설명하는 불리언입니다.
출력 점수
| 값 | 설명 |
|---|---|
| 1 | 오류 |
| 0 | 유효한 응답이 반환됨 |
에이전트 평가를 위한 데이터 세트 준비
최종 응답 또는 궤적 평가를 위해 데이터 세트를 준비합니다.
최종 응답 평가의 데이터 스키마는 모델 응답 평가의 스키마와 유사합니다.
계산 기반 궤적 평가의 경우 데이터 세트에서 다음 정보를 제공해야 합니다.
| 입력 유형 | 입력 필드 콘텐츠 |
|---|---|
predicted_trajectory |
에이전트가 최종 응답에 도달하는 데 사용하는 도구 호출 목록입니다. |
reference_trajectory(trajectory_single_tool_use metric에는 필요하지 않음) |
에이전트가 쿼리를 충족하는 데 사용할 것으로 예상되는 도구입니다. |
평가 데이터 세트 예시
다음 예는 궤적 평가를 위한 데이터 세트를 보여줍니다. trajectory_single_tool_use를 제외한 모든 측정항목에 reference_trajectory가 필요합니다.
reference_trajectory = [
# example 1
[
{
"tool_name": "set_device_info",
"tool_input": {
"device_id": "device_2",
"updates": {
"status": "OFF"
}
}
}
],
# example 2
[
{
"tool_name": "get_user_preferences",
"tool_input": {
"user_id": "user_y"
}
},
{
"tool_name": "set_temperature",
"tool_input": {
"location": "Living Room",
"temperature": 23
}
},
]
]
predicted_trajectory = [
# example 1
[
{
"tool_name": "set_device_info",
"tool_input": {
"device_id": "device_3",
"updates": {
"status": "OFF"
}
}
}
],
# example 2
[
{
"tool_name": "get_user_preferences",
"tool_input": {
"user_id": "user_z"
}
},
{
"tool_name": "set_temperature",
"tool_input": {
"location": "Living Room",
"temperature": 23
}
},
]
]
eval_dataset = pd.DataFrame({
"predicted_trajectory": predicted_trajectory,
"reference_trajectory": reference_trajectory,
})
평가 데이터 세트 가져오기
다음 형식으로 데이터 세트를 가져올 수 있습니다.
Cloud Storage에 저장된 JSONL 또는 CSV 파일
BigQuery 테이블
Pandas DataFrame
Gen AI Evaluation Service는 에이전트를 평가하는 방법을 보여주기 위해 공개 데이터 세트 예시를 제공합니다. 다음 코드는 Cloud Storage 버킷에서 공개 데이터 세트를 가져오는 방법을 보여줍니다.
# dataset name to be imported
dataset = "on-device" # Alternatives: "customer-support", "content-creation"
# copy the tools and dataset file
!gcloud storage cp gs://cloud-ai-demo-datasets/agent-eval-datasets/{dataset}/tools.py .
!gcloud storage cp gs://cloud-ai-demo-datasets/agent-eval-datasets/{dataset}/eval_dataset.json .
# load the dataset examples
import json
eval_dataset = json.loads(open('eval_dataset.json').read())
# run the tools file
%run -i tools.py
여기서 dataset는 다음 공개 데이터 세트 중 하나입니다.
"on-device": 홈 기기를 제어하는 온디바이스 Home Assistant. 에이전트는 '침실 에어컨이 오후 11시에서 오전 8시 사이에 켜지고 그 외 시간에는 꺼지도록 예약해 줘.'와 같은 쿼리를 지원합니다."customer-support": 고객 지원 담당자 에이전트는 '대기 중인 주문을 취소하고 미해결 지원 티켓을 에스컬레이션해 주시겠어요?'와 같은 문의를 지원합니다."content-creation": 마케팅 콘텐츠 제작 에이전트 에이전트는 '2024년 12월 25일에만 예산을 50% 줄여 소셜 미디어 사이트 Y에서 일회성 캠페인으로 캠페인 X 일정을 변경해줘.'와 같은 쿼리를 지원합니다.
에이전트 평가 실행
궤적 또는 최종 응답 평가를 위한 평가를 실행합니다.
에이전트 평가의 경우 다음 코드와 같이 응답 평가 측정항목과 궤적 평가 측정항목을 혼합할 수 있습니다.
single_tool_use_metric = TrajectorySingleToolUse(tool_name='tool_name')
eval_task = EvalTask(
dataset=EVAL_DATASET,
metrics=[
"rouge_l_sum",
"bleu",
custom_trajectory_eval_metric, # custom computation-based metric
"trajectory_exact_match",
"trajectory_precision",
single_tool_use_metric,
response_follows_trajectory_metric # llm-based metric
],
)
eval_result = eval_task.evaluate(
runnable=RUNNABLE,
)
측정항목 맞춤설정
궤적 평가를 위한 대규모 언어 모델 기반 측정항목을 템플릿 인터페이스를 사용하거나 처음부터 맞춤설정할 수 있으며, 자세한 내용은 모델 기반 측정항목 섹션을 참조고하세요. 다음은 템플릿 예시입니다.
response_follows_trajectory_prompt_template = PointwiseMetricPromptTemplate(
criteria={
"Follows trajectory": (
"Evaluate whether the agent's response logically follows from the "
"sequence of actions it took. Consider these sub-points:\n"
" - Does the response reflect the information gathered during the trajectory?\n"
" - Is the response consistent with the goals and constraints of the task?\n"
" - Are there any unexpected or illogical jumps in reasoning?\n"
"Provide specific examples from the trajectory and response to support your evaluation."
)
},
rating_rubric={
"1": "Follows trajectory",
"0": "Does not follow trajectory",
},
input_variables=["prompt", "predicted_trajectory"],
)
response_follows_trajectory_metric = PointwiseMetric(
metric="response_follows_trajectory",
metric_prompt_template=response_follows_trajectory_prompt_template,
)
다음과 같이 궤적 평가 또는 응답 평가를 위한 커스텀 계산 기반 측정항목을 정의할 수도 있습니다.
def essential_tools_present(instance, required_tools = ["tool1", "tool2"]):
trajectory = instance["predicted_trajectory"]
tools_present = [tool_used['tool_name'] for tool_used in trajectory]
if len(required_tools) == 0:
return {"essential_tools_present": 1}
score = 0
for tool in required_tools:
if tool in tools_present:
score += 1
return {
"essential_tools_present": score/len(required_tools),
}
custom_trajectory_eval_metric = CustomMetric(name="essential_tools_present", metric_function=essential_tools_present)
결과 보기 및 해석
궤적 평가 또는 최종 응답 평가의 경우 평가 결과는 다음과 같이 표시됩니다.
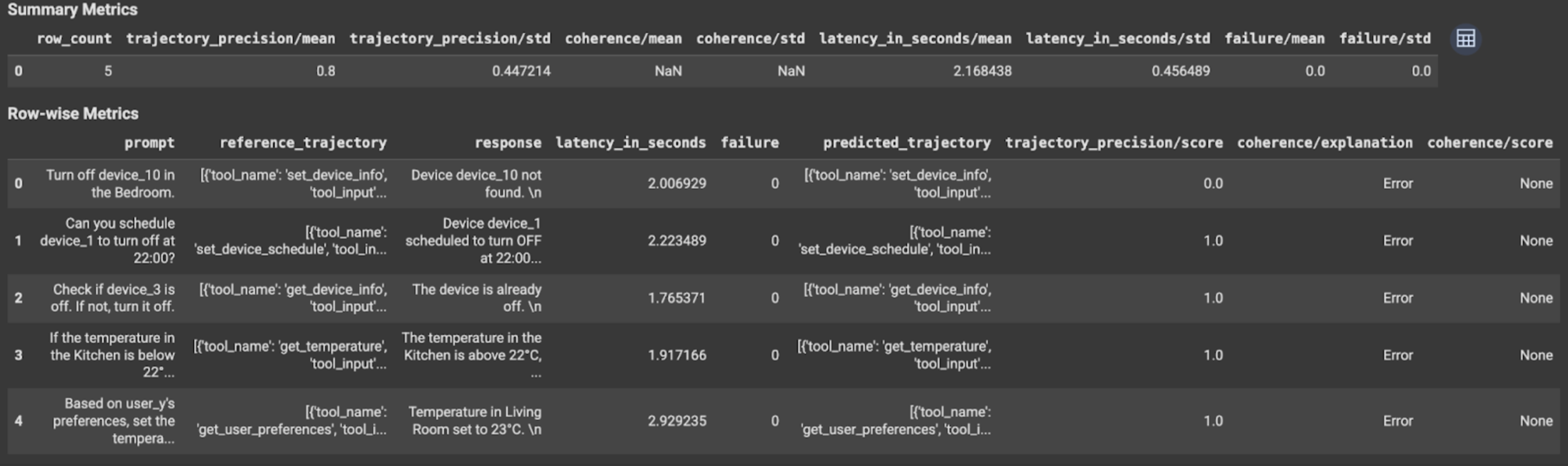
평가 결과에는 다음 정보가 포함됩니다.
최종 응답 측정항목
인스턴스 수준 결과
| 열 | 설명 |
|---|---|
| 응답 | 에이전트가 생성한 최종 응답입니다. |
| latency_in_seconds | 응답을 생성하는 데 걸린 시간입니다. |
| 실패 | 유효한 응답이 생성되었는지 여부를 나타냅니다. |
| 점수 | 측정항목 사양에 지정된 응답에 대해 계산된 점수입니다. |
| 설명 | 측정항목 사양에 지정된 점수에 대한 설명입니다. |
결과 집계
| 열 | 설명 |
|---|---|
| 평균 | 모든 인스턴스의 평균 점수입니다. |
| 표준 편차 | 모든 점수의 표준 편차입니다. |
궤적 측정항목
인스턴스 수준 결과
| 열 | 설명 |
|---|---|
| predicted_trajectory | 에이전트가 최종 응답에 도달하기 위해 따르는 도구 호출 시퀀스입니다. |
| reference_trajectory | 예상되는 도구 호출 시퀀스입니다. |
| 점수 | 측정항목 사양에 지정된 예측된 궤적과 참조 궤적에 대해 계산된 점수입니다. |
| latency_in_seconds | 응답을 생성하는 데 걸린 시간입니다. |
| 실패 | 유효한 응답이 생성되었는지 여부를 나타냅니다. |
결과 집계
| 열 | 설명 |
|---|---|
| 평균 | 모든 인스턴스의 평균 점수입니다. |
| 표준 편차 | 모든 점수의 표준 편차입니다. |
Agent2Agent(A2A) 프로토콜
멀티 에이전트 시스템을 빌드하는 경우 A2A 프로토콜을 검토하는 것이 좋습니다. A2A 프로토콜은 기반 프레임워크와 관계없이 AI 에이전트 간의 원활한 통신과 협업을 지원하는 개방형 표준입니다. 2025년 6월에 Google Cloud 에서 Linux Foundation에 제공했습니다. A2A SDK를 사용하거나 샘플을 사용해 보려면 GitHub 저장소를 확인하세요.
다음 단계
다음 에이전트 평가 노트북을 사용해 보세요.