이 페이지에서는 평가 파이프라인 서비스를 통한 도구인 AutoSxS를 사용하여 쌍별 모델 기반 평가를 수행하는 방법을 소개합니다. Vertex AI API 또는 Python용 Vertex AI SDK를 통해 AutoSxS를 사용하는 방법을 설명합니다.
AutoSxS
자동 정렬(AutoSxS)은 평가 파이프라인 서비스를 통해 실행되는 쌍별 모델 기반 평가 도구입니다. AutoSxS는 Vertex AI Model Registry의 생성형 AI 모델 또는 사전 생성된 예측의 성능을 평가하는 데 사용됩니다. 이를 통해 Vertex AI 기반 모델, 조정된 생성형 AI 모델 및 서드파티 언어 모델을 지원할 수 있습니다. AutoSxS는 자동 평가 도구를 사용하여 프롬프트에 더 나은 응답을 제공하는 모델을 결정합니다. 주문형으로 제공되며 인간 평가자와 성능이 비슷한 언어 모델을 평가합니다.
자동 평가 도구
개략적으로 이 다이어그램은 AutoSxS가 모델 A와 B의 예측을 세 번째 모델인 자동 평가 도구와 비교하는 방법을 보여줍니다.
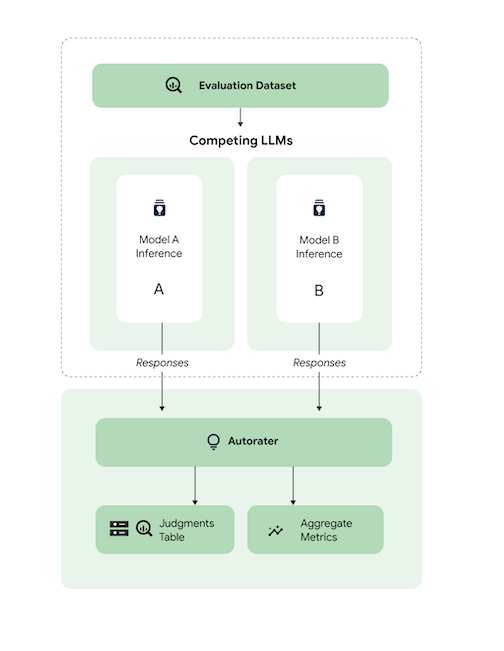
모델 A와 B는 입력 프롬프트를 수신하고 각 모델은 자동 평가 도구로 전송되는 응답을 생성합니다. 자동 평가 도구는 인간 평가자와 마찬가지로 원래의 추론 프롬프트가 지정될 경우 모델 응답의 품질을 평가하는 언어 모델입니다. 자동 평가 도구는 AutoSxS를 통해 일련의 기준을 사용하여 추론 안내에 따라 두 모델 응답의 품질을 비교합니다. 이러한 기준은 모델 A의 결과를 모델 B의 결과와 비교하여 어떤 모델이 가장 잘 수행되었는지 확인하는 데 사용됩니다. 자동 평가 도구는 반응 선호도를 집계 측정항목으로 출력하고 각 예시에 대한 선호도 설명 및 신뢰도 점수를 출력합니다. 자세한 내용은 판단 표를 참조하세요.
지원되는 모델
AutoSxS는 사전 생성된 예측이 제공되면 모든 모델의 평가를 지원합니다. 또한 AutoSxS는 Vertex AI에서 일괄 예측을 지원하는 Vertex AI 모델 레지스트리의 모든 모델에 대한 응답을 자동으로 생성하도록 지원합니다.
텍스트 모델이 Vertex AI Model Registry에서 지원되지 않는 경우 AutoSxS는 Cloud Storage 또는 BigQuery 테이블에 JSONL로 저장된 사전 생성 예측도 허용합니다. 가격 책정은 텍스트 생성을 참조하세요.
지원되는 태스크 및 기준
AutoSxS는 요약 및 질의 응답 태스크를 위한 모델 평가를 지원합니다. 평가 기준은 태스크별로 사전 정의되어 있으므로 언어 평가가 보다 객관적이고 응답 품질이 향상됩니다.
기준은 태스크별로 나열됩니다.
요약
summarization 태스크에는 4,096개의 입력 토큰 한도가 있습니다.
summarization의 평가 기준 목록은 다음과 같습니다.
| 기준 | |
|---|---|
| 1. 안내 따르기 | 모델의 응답은 프롬프트의 지침을 어느 정도 이해하고 있음을 보여주나요? |
| 2. 근거 확보 | 응답에 추론 컨텍스트와 추론 명령어의 정보만 포함되나요? |
| 3. 종합적 | 모델에서 요약의 핵심 세부정보를 어느 정도 파악하나요? |
| 4. 요약 | 요약이 장황한가요? 미사여구가 포함되어 있나요? 너무 간결한가요? |
질의 응답
question_answering 태스크에는 4,096개의 입력 토큰 한도가 있습니다.
question_answering의 평가 기준 목록은 다음과 같습니다.
| 기준 | |
|---|---|
| 1. 질문에 완벽하게 답변 | 질문에 완벽하게 답변합니다. |
| 2. 근거 확보 | 응답에 안내 컨텍스트와 추론 안내의 정보만 포함되나요? |
| 3. 관련성 | 답변의 콘텐츠가 질문과 관련이 있나요? |
| 4. 종합적 | 모델에서 질문의 핵심 세부정보를 어느 정도 파악하나요? |
AutoSxS용 평가 데이터 세트 준비
이 섹션에서는 AutoSxS 평가 데이터 세트에 제공해야 하는 데이터와 데이터 세트 구축 권장사항에 대해 자세히 설명합니다. 이 예시는 모델이 프로덕션 단계에서 발생할 수 있는 실제 입력을 반영하고 실시간 모델의 작동 방식과 가장 잘 대비되어야 합니다.
데이터 세트 형식
AutoSxS는 유연한 스키마가 포함된 단일 평가 데이터 세트를 허용합니다. 데이터 세트는 BigQuery 테이블이 될 수도 있고 Cloud Storage에 JSON Lines로 저장될 수도 있습니다.
평가 데이터 세트의 각 행은 단일 예시를 나타내며 열은 다음 중 하나입니다.
- ID 열: 각각의 고유한 예시를 식별하는 데 사용됩니다.
- 데이터 열: 프롬프트 템플릿을 작성하는 데 사용됩니다. 프롬프트 매개변수 참조
- 사전 생성된 예측: 동일한 프롬프트를 사용하여 동일한 모델에서 수행한 예측입니다. 사전 생성된 예측을 사용하면 시간과 리소스가 절약됩니다.
- 사실: 인간 선호도: 두 모델에 대해 사전 생성된 예측이 제공되는 경우 사실 선호도 데이터와 비교하여 AutoSxS를 벤치마킹하는 데 사용됩니다.
다음은 context 및 question이 데이터 열이고 model_b_response에 사전 생성된 예측이 포함된 평가 데이터 세트 예시입니다.
context |
question |
model_b_response |
|---|---|---|
| 일부는 강철이 가장 단단한 소재나 티타늄이라고 생각할 수 있지만, 실제로는 다이아몬드가 가장 단단한 소재입니다. | 가장 단단한 소재는 무엇인가요? | 다이아몬드는 가장 단단한 소재로, 강철이나 티타늄보다 더 단단합니다. |
AutoSxS를 호출하는 방법에 대한 자세한 내용은 모델 평가 수행을 참조하세요. 토큰 길이에 대한 자세한 내용은 지원되는 태스크 및 기준을 참조하세요. Cloud Storage에 데이터를 업로드하려면 Cloud Storage에 평가 데이터 세트 업로드를 참조하세요.
프롬프트 매개변수
많은 언어 모델이 단일 프롬프트 문자열 대신 프롬프트 매개변수를 입력으로 사용합니다. 예를 들어 chat-bison은 프롬프트의 일부를 구성하는 여러 프롬프트 매개변수(메시지, 예시, 컨텍스트)를 사용합니다. 하지만 text-bison에는 전체 프롬프트가 포함된 prompt라는 하나의 프롬프트 매개변수만 있습니다.
추론 및 평가 시 모델 프롬프트 매개변수를 유연하게 지정하는 방법을 간략히 설명합니다. AutoSxS를 사용하면 템플릿 프롬프트 매개변수를 통해 다양한 예상 입력으로 언어 모델을 유연하게 호출할 수 있습니다.
추론
모델 중에 사전 생성된 예측이 없으면 AutoSxS는 Vertex AI 일괄 예측을 사용하여 응답을 생성합니다. 각 모델의 프롬프트 매개변수를 지정해야 합니다.
AutoSxS에서는 평가 데이터 세트의 단일 열을 프롬프트 매개변수로 제공할 수 있습니다.
{'some_parameter': {'column': 'my_column'}}
또는 평가 데이터 세트의 열을 변수로 사용하여 템플릿을 정의하여 프롬프트 매개변수를 지정할 수 있습니다.
{'some_parameter': {'template': 'Summarize the following: {{ my_column }}.'}}
추론을 위한 모델 프롬프트 매개변수를 제공할 때 사용자는 보호된 default_instruction 키워드를 템플릿 인수로 사용할 수 있으며 이는 지정된 작업에 대한 기본 추론 안내로 대체됩니다.
model_prompt_parameters = {
'prompt': {'template': '{{ default_instruction }}: {{ context }}'},
}
예측을 생성하는 경우 모델 프롬프트 매개변수와 출력 열을 제공합니다.
예를 들어 text-bison은 입력에 '프롬프트'를 사용하고 출력에는 '콘텐츠'를 사용합니다. 다음 단계를 따르세요.
- 평가 중인 모델에 필요한 입력과 출력을 파악합니다.
- 입력을 모델 프롬프트 매개변수로 정의합니다.
- 출력을 응답 열에 전달합니다.
model_a_prompt_parameters={
'prompt': {
'template': {
'Answer the following question from the point of view of a college professor: {{ context }}\n{{ question }}'
},
},
},
response_column_a='content', # Column in Model A response.
response_column_b='model_b_response', # Column in eval dataset.
평가
추론을 위해 프롬프트 매개변수를 제공해야 하는 것처럼 평가를 위해서도 프롬프트 매개변수를 제공해야 합니다. 자동 평가 도구에는 다음 프롬프트 매개변수가 필요합니다.
| 자동 평가 도구 프롬프트 매개변수 | 사용자 구성 가능 여부 | 설명 | 예 |
|---|---|---|---|
| 자동 평가 도구 안내 | No | 주어진 응답을 판단하는 데 자동 평가 도구가 사용해야 하는 기준을 설명하는 보정된 안내입니다. | 질문에 답변하고 안내를 가장 잘 따르는 응답을 선택하세요. |
| 추론 안내 | 예 | 각 후보 모델이 수행해야 하는 작업에 대한 설명 | 질문에 정확하게 답변하기: 가장 단단한 소재는 무엇인가요? |
| 추론 컨텍스트 | 예 | 수행 중인 태스크에 대한 추가 컨텍스트입니다. | 티타늄과 다이아몬드는 모두 구리보다 단단하지만, 다이아몬드는 강도가 98이고 티타늄은 36입니다. 등급이 높을수록 강도가 높습니다. |
| 응답 | 수1 | 평가할 응답 쌍(각 후보 모델에서 하나씩) | 마름모형 |
1사전 생성된 응답을 통해서만 프롬프트 매개변수를 구성할 수 있습니다.
매개변수를 사용하는 샘플 코드:
autorater_prompt_parameters={
'inference_instruction': {
'template': 'Answer the following question from the point of view of a college professor: {{ question }}.'
},
'inference_context': {
'column': 'context'
}
}
모델 A와 B는 동일한 정보 제공 여부에 관계없이 다른 형식의 추론 명령 및 컨텍스트를 가질 수 있습니다. 즉, 자동 평가 도구는 별도의 단일 추론 안내와 컨텍스트를 사용한다는 것을 의미합니다.
평가 데이터 세트의 예시
이 섹션에서는 모델 B에 대해 사전 생성된 예측을 포함하여 질의 응답 태스크 평가 데이터 세트의 예시를 제공합니다. 이 예시에서 AutoSxS는 모델 A에 대해서만 추론을 수행합니다. 질문과 컨텍스트가 동일한 예시를 구분하기 위해 id 열을 제공합니다.
{
"id": 1,
"question": "What is the hardest material?",
"context": "Some might think that steel is the hardest material, or even titanium. However, diamond is actually the hardest material.",
"model_b_response": "Diamond is the hardest material. It is harder than steel or titanium."
}
{
"id": 2,
"question": "What is the highest mountain in the world?",
"context": "K2 and Everest are the two tallest mountains, with K2 being just over 28k feet and Everest being 29k feet tall.",
"model_b_response": "Mount Everest is the tallest mountain, with a height of 29k feet."
}
{
"id": 3,
"question": "Who directed The Godfather?",
"context": "Mario Puzo and Francis Ford Coppola co-wrote the screenplay for The Godfather, and the latter directed it as well.",
"model_b_response": "Francis Ford Coppola directed The Godfather."
}
{
"id": 4,
"question": "Who directed The Godfather?",
"context": "Mario Puzo and Francis Ford Coppola co-wrote the screenplay for The Godfather, and the latter directed it as well.",
"model_b_response": "John Smith."
}
권장사항
평가 데이터 세트를 정의할 때는 다음 권장사항을 따르세요.
- 모델이 프로덕션 단계에서 처리하는 입력 유형을 나타내는 예시를 제공합니다.
- 데이터 세트에는 최소 하나의 평가 예시가 포함되어야 합니다. 고품질 집계 측정항목을 확보하려면 약 100개의 예시가 권장됩니다. 400개가 넘는 예시가 제공되면 집계 측정항목의 품질 개선 비율이 감소하는 경향이 있습니다.
- 프롬프트를 작성하는 방법은 텍스트 프롬프트 설계를 참조하세요.
- 각 모델에 대해 사전 생성된 예측을 사용하는 경우 평가 데이터 세트의 열에 사전 생성된 예측을 포함합니다. 사전 생성된 예측을 제공하면 Vertex Model Registry에 없는 모델의 출력을 비교하고 응답을 재사용할 수 있게 해주기 때문에 유용합니다.
모델 평가 수행
REST API 또는 Python용 Vertex AI SDK를 사용하여 모델을 평가할 수 있습니다.
다음 구문을 사용하여 모델 경로를 지정합니다.
- 게시자 모델:
publishers/PUBLISHER/models/MODEL예시:publishers/google/models/text-bison 조정된 모델:
projects/PROJECT_NUMBER/locations/LOCATION/models/MODEL@VERSION예시:projects/123456789012/locations/us-central1/models/1234567890123456789
REST
모델 평가 작업을 만들려면 pipelineJobs 메서드를 사용하여 POST 요청을 전송합니다.
요청 데이터를 사용하기 전에 다음을 바꿉니다.
- PIPELINEJOB_DISPLAYNAME :
pipelineJob의 표시 이름입니다. - PROJECT_ID : 파이프라인 구성요소를 실행하는 Google Cloud 프로젝트입니다.
- LOCATION: 파이프라인 구성요소를 실행하는 리전입니다.
us-central1가 지원됩니다. - OUTPUT_DIR: 평가 출력을 저장할 Cloud Storage URI입니다.
- EVALUATION_DATASET : BigQuery 테이블 또는 평가 예시가 포함된 JSONL 데이터 세트에 대한 Cloud Storage 경로의 쉼표로 구분된 목록입니다.
- TASK : 평가 태스크이며
[summarization, question_answering]중 하나일 수 있습니다. - ID_COLUMNS : 고유한 평가 예를 구분하는 열입니다.
- AUTORATER_PROMPT_PARAMETERS : 열 또는 템플릿에 매핑된 자동 평가 도구 프롬프트 매개변수입니다. 예상되는 매개변수는
inference_instruction(작업 수행 방법에 대한 세부정보) 및inference_context(작업 수행을 위해 참조할 콘텐츠)입니다. 예를 들어{'inference_context': {'column': 'my_prompt'}}는 자동 평가 도구의 컨텍스트에 대한 평가 데이터 세트의 'my_prompt' 열을 사용합니다. - RESPONSE_COLUMN_A : 사전 정의된 예측이 포함된 평가 데이터 세트의 열 이름 또는 예측을 포함하는 모델 A 출력의 열 이름 중 하나입니다. 값이 제공되지 않으면 올바른 모델 출력 열 이름을 추론하려고 시도합니다.
- RESPONSE_COLUMN_B : 사전 정의된 예측이 포함된 평가 데이터 세트의 열 이름 또는 예측을 포함하는 모델 B 출력의 열 이름 중 하나입니다. 값이 제공되지 않으면 올바른 모델 출력 열 이름을 추론하려고 시도합니다.
- MODEL_A(선택사항): 정규화된 모델 리소스 이름(
projects/{project}/locations/{location}/models/{model}@{version}) 또는 게시자 모델 리소스 이름(publishers/{publisher}/models/{model})입니다. 모델 A 응답이 지정된 경우 이 매개변수를 제공하면 안 됩니다. - MODEL_B(선택사항): 정규화된 모델 리소스 이름(
projects/{project}/locations/{location}/models/{model}@{version}) 또는 게시자 모델 리소스 이름(publishers/{publisher}/models/{model})입니다. 모델 B 응답이 지정된 경우 이 매개변수를 제공하면 안 됩니다. - MODEL_A_PROMPT_PARAMETERS(선택사항): 열 또는 템플릿에 매핑된 모델 A의 프롬프트 템플릿 매개변수입니다. 모델 A 응답이 사전 정의되어 있으면 이 매개변수를 제공해서는 안 됩니다. 예를 들어
{'prompt': {'column': 'my_prompt'}}는prompt라는 프롬프트 매개변수에 평가 데이터 세트의my_prompt열을 사용합니다. - MODEL_B_PROMPT_PARAMETERS(선택사항): 열 또는 템플릿에 매핑된 모델 B의 프롬프트 템플릿 매개변수입니다. 모델 B 응답이 사전 정의되어 있으면 이 매개변수를 제공해서는 안 됩니다. 예를 들어
{'prompt': {'column': 'my_prompt'}}는prompt라는 프롬프트 매개변수에 평가 데이터 세트의my_prompt열을 사용합니다.
JSON 요청 본문
{
"displayName": "PIPELINEJOB_DISPLAYNAME",
"runtimeConfig": {
"gcsOutputDirectory": "gs://OUTPUT_DIR",
"parameterValues": {
"evaluation_dataset": "EVALUATION_DATASET",
"id_columns": ["ID_COLUMNS"],
"task": "TASK",
"autorater_prompt_parameters": AUTORATER_PROMPT_PARAMETERS,
"response_column_a": "RESPONSE_COLUMN_A",
"response_column_b": "RESPONSE_COLUMN_B",
"model_a": "MODEL_A",
"model_a_prompt_parameters": MODEL_A_PROMPT_PARAMETERS,
"model_b": "MODEL_B",
"model_b_prompt_parameters": MODEL_B_PROMPT_PARAMETERS,
},
},
"templateUri": "https://us-kfp.pkg.dev/ml-pipeline/google-cloud-registry/autosxs-template/default"
}
curl을 사용하여 요청을 보냅니다.
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/pipelineJobs"
응답
"state": "PIPELINE_STATE_PENDING",
"labels": {
"vertex-ai-pipelines-run-billing-id": "1234567890123456789"
},
"runtimeConfig": {
"gcsOutputDirectory": "gs://my-evaluation-bucket/output",
"parameterValues": {
"evaluation_dataset": "gs://my-evaluation-bucket/output/data.json",
"id_columns": [
"context"
],
"task": "question_answering",
"autorater_prompt_parameters": {
"inference_instruction": {
"template": "Answer the following question: {{ question }} }."
},
"inference_context": {
"column": "context"
}
},
"response_column_a": "",
"response_column_b": "response_b",
"model_a": "publishers/google/models/text-bison@001",
"model_a_prompt_parameters": {
"prompt": {
"template": "Answer the following question from the point of view of a college professor: {{ question }}\n{{ context }} }"
}
},
"model_b": "",
"model_b_prompt_parameters": {}
}
},
"serviceAccount": "123456789012-compute@developer.gserviceaccount.com",
"templateUri": "https://us-kfp.pkg.dev/ml-pipeline/google-cloud-registry/autosxs-template/default",
"templateMetadata": {
"version": "sha256:7366b784205551ed28f2c076e841c0dbeec4111b6df16743fc5605daa2da8f8a"
}
}
Python용 Vertex AI SDK
Python용 Vertex AI SDK를 설치하거나 업데이트하는 방법은 Python용 Vertex AI SDK 설치를 참조하세요. Python API에 대한 자세한 내용은 Python API용 Vertex AI SDK를 참조하세요.
파이프라인 매개변수에 대한 자세한 내용은 Google Cloud 파이프라인 구성요소 참조 문서를 확인하세요.
요청 데이터를 사용하기 전에 다음을 바꿉니다.
- PIPELINEJOB_DISPLAYNAME :
pipelineJob의 표시 이름입니다. - PROJECT_ID : 파이프라인 구성요소를 실행하는 Google Cloud 프로젝트입니다.
- LOCATION: 파이프라인 구성요소를 실행하는 리전입니다.
us-central1가 지원됩니다. - OUTPUT_DIR: 평가 출력을 저장할 Cloud Storage URI입니다.
- EVALUATION_DATASET : BigQuery 테이블 또는 평가 예시가 포함된 JSONL 데이터 세트에 대한 Cloud Storage 경로의 쉼표로 구분된 목록입니다.
- TASK : 평가 태스크이며
[summarization, question_answering]중 하나일 수 있습니다. - ID_COLUMNS : 고유한 평가 예를 구분하는 열입니다.
- AUTORATER_PROMPT_PARAMETERS : 열 또는 템플릿에 매핑된 자동 평가 도구 프롬프트 매개변수입니다. 예상되는 매개변수는
inference_instruction(작업 수행 방법에 대한 세부정보) 및inference_context(작업 수행을 위해 참조할 콘텐츠)입니다. 예를 들어{'inference_context': {'column': 'my_prompt'}}는 자동 평가 도구의 컨텍스트에 대한 평가 데이터 세트의 'my_prompt' 열을 사용합니다. - RESPONSE_COLUMN_A : 사전 정의된 예측이 포함된 평가 데이터 세트의 열 이름 또는 예측을 포함하는 모델 A 출력의 열 이름 중 하나입니다. 값이 제공되지 않으면 올바른 모델 출력 열 이름을 추론하려고 시도합니다.
- RESPONSE_COLUMN_B : 사전 정의된 예측이 포함된 평가 데이터 세트의 열 이름 또는 예측을 포함하는 모델 B 출력의 열 이름 중 하나입니다. 값이 제공되지 않으면 올바른 모델 출력 열 이름을 추론하려고 시도합니다.
- MODEL_A(선택사항): 정규화된 모델 리소스 이름(
projects/{project}/locations/{location}/models/{model}@{version}) 또는 게시자 모델 리소스 이름(publishers/{publisher}/models/{model})입니다. 모델 A 응답이 지정된 경우 이 매개변수를 제공하면 안 됩니다. - MODEL_B(선택사항): 정규화된 모델 리소스 이름(
projects/{project}/locations/{location}/models/{model}@{version}) 또는 게시자 모델 리소스 이름(publishers/{publisher}/models/{model})입니다. 모델 B 응답이 지정된 경우 이 매개변수를 제공하면 안 됩니다. - MODEL_A_PROMPT_PARAMETERS(선택사항): 열 또는 템플릿에 매핑된 모델 A의 프롬프트 템플릿 매개변수입니다. 모델 A 응답이 사전 정의되어 있으면 이 매개변수를 제공해서는 안 됩니다. 예를 들어
{'prompt': {'column': 'my_prompt'}}는prompt라는 프롬프트 매개변수에 평가 데이터 세트의my_prompt열을 사용합니다. - MODEL_B_PROMPT_PARAMETERS(선택사항): 열 또는 템플릿에 매핑된 모델 B의 프롬프트 템플릿 매개변수입니다. 모델 B 응답이 사전 정의되어 있으면 이 매개변수를 제공해서는 안 됩니다. 예를 들어
{'prompt': {'column': 'my_prompt'}}는prompt라는 프롬프트 매개변수에 평가 데이터 세트의my_prompt열을 사용합니다.
import os
from google.cloud import aiplatform
parameters = {
'evaluation_dataset': 'EVALUATION_DATASET',
'id_columns': ['ID_COLUMNS'],
'task': 'TASK',
'autorater_prompt_parameters': AUTORATER_PROMPT_PARAMETERS,
'response_column_a': 'RESPONSE_COLUMN_A',
'response_column_b': 'RESPONSE_COLUMN_B',
'model_a': 'MODEL_A',
'model_a_prompt_parameters': MODEL_A_PROMPT_PARAMETERS,
'model_b': 'MODEL_B',
'model_b_prompt_parameters': MODEL_B_PROMPT_PARAMETERS,
}
aiplatform.init(project='PROJECT_ID', location='LOCATION', staging_bucket='gs://OUTPUT_DIR')
aiplatform.PipelineJob(
display_name='PIPELINEJOB_DISPLAYNAME',
pipeline_root=os.path.join('gs://OUTPUT_DIR', 'PIPELINEJOB_DISPLAYNAME'),
template_path=(
'https://us-kfp.pkg.dev/ml-pipeline/google-cloud-registry/autosxs-template/default'),
parameter_values=parameters,
).run()
평가 결과 보기
AutoSxS 파이프라인에서 생성된 다음 아티팩트를 검사하여 Vertex AI Pipelines에서 평가 결과를 확인할 수 있습니다:
- 판단 테이블은 AutoSxS 중재에 의해 생성됩니다.
- 집계 측정항목은 AutoSxS 측정항목 구성요소에 의해 생성됩니다.
- 인간 선호도 정렬 측정항목은 AutoSxS 측정항목 구성요소에 의해 생성됩니다.
판단
AutoSxS는 사용자가 예시 수준에서 모델 성능을 이해하는 데 도움이 되는 판단(예시 수준 측정항목)을 출력합니다. 판단에는 다음 정보가 포함됩니다.
- 추론 프롬프트
- 모델 응답
- 자동 평가 도구 결정
- 평점 설명
- 신뢰도 점수
판단은 Cloud Storage에 JSONL 형식으로 기록되거나 다음 열이 포함된 BigQuery 테이블에 쓸 수 있습니다.
| 열 | 설명 |
|---|---|
| ID 열 | 고유한 평가 예시를 구분하는 열입니다. |
inference_instruction |
모델 응답을 생성하는 데 사용되는 안내입니다. |
inference_context |
모델 응답을 생성하는 데 사용되는 컨텍스트 |
response_a |
추론 안내 및 컨텍스트가 지정된 모델 A의 응답입니다. |
response_b |
추론 안내 및 컨텍스트가 지정된 모델 B의 응답입니다. |
choice |
더 나은 응답을 제공하는 모델입니다. 가능한 값은 Model A, Model B 또는 Error입니다. Error는 오류로 인해 자동 평가 도구가 모델 A의 응답이 최선인지 또는 모델 B의 응답이 최선인지 확인할 수 없음을 나타냅니다. |
confidence |
0 - 1의 점수로, 자동 평가 도구가 선택에 얼마나 확신하는지 나타냅니다. |
explanation |
자동 평가 도구가 선택한 이유입니다. |
집계 측정항목
AutoSxS는 판단 테이블을 사용하여 집계(계약 성사율) 측정항목을 계산합니다. 인간 선호도 데이터를 제공하지 않으면 다음과 같은 집계 측정항목이 생성됩니다.
| 측정항목 | 설명 |
|---|---|
| 자동 평가 도구 모델 A의 계약 성사율 | 자동 평가 도구가 모델 A의 응답이 더 좋았다고 결정한 시간 비율입니다. |
| 자동 평가 도구 모델 B의 계약 성사율 | 자동 평가 도구가 모델 B의 응답이 더 좋았다고 결정한 시간 비율입니다. |
계약 성사율에 대해 자세히 알아보려면 행 기반 결과와 자동 확장 처리의 설명을 통해 결과와 설명이 기대치에 부합하는지 확인하세요.
인간 선호도 정렬 측정항목
인간 선호도 데이터가 제공되면 AutoSxS는 다음 측정항목을 출력합니다.
| 측정항목 | 설명 | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 자동 평가 도구 모델 A의 계약 성사율 | 자동 평가 도구가 모델 A의 응답이 더 좋았다고 결정한 시간 비율입니다. | ||||||||||||||
| 자동 평가 도구 모델 B의 계약 성사율 | 자동 평가 도구가 모델 B의 응답이 더 좋았다고 결정한 시간 비율입니다. | ||||||||||||||
| 인간 선호도 모델 A의 계약 성사율 | 인간이 모델 A의 응답이 더 좋았다고 결정한 시간 비율입니다. | ||||||||||||||
| 인간 선호도 모델 B 계약 성사율 | 인간이 모델 B의 응답이 더 좋았다고 결정한 시간 비율입니다. | ||||||||||||||
| TP | 자동 평가 도구 및 인간 선호도 모두 모델 A의 응답이 더 좋았다고 평가한 예시 수입니다. | ||||||||||||||
| FP | 자동 평가 도구가 모델 A를 더 좋은 응답으로 선택했지만 인간 선호도는 모델 B를 더 좋은 응답으로 선택한 예시 수입니다. | ||||||||||||||
| TN | 자동 평가 도구 및 인간 선호도 모두 모델 B의 응답이 더 좋았다고 평가한 예시 수입니다. | ||||||||||||||
| FN | 자동 평가 도구가 모델 B를 더 좋은 응답으로 선택했지만 인간 선호도는 모델 A를 더 좋은 응답으로 선택한 예시 수입니다. | ||||||||||||||
| 정확성 | 자동 평가 도구가 인간 평가자에게 동의한 시간 비율입니다. | ||||||||||||||
| 정밀도 | 자동 평가 도구가 모델 A의 응답이 더 좋았다고 생각한 경우 중 자동 평가 도구와 사람이 모두 모델 A의 응답이 더 좋다고 생각한 시간 비율입니다. | ||||||||||||||
| 재현율 | 사람이 모델 A의 응답이 더 좋았다고 생각한 경우 중 자동 평가 도구와 사람이 모두 모델 A의 응답이 더 좋다고 생각한 시간 비율입니다. | ||||||||||||||
| F1 | 정밀도와 재현율의 조화 평균입니다. | ||||||||||||||
| Cohen 카파 | 자동 평가 도구와 인간 평가자 간의 동의 여부를 측정하며 무작위 평가의 가능성을 고려합니다. 코헨은 다음과 같은 해석을 제안합니다.
|
AutoSxS 사용 사례
세 가지 사용 사례 시나리오에서 AutoSxS를 사용하는 방법을 살펴볼 수 있습니다.
모델 비교
참조 1p 모델에 대해 조정된 자사(1p) 모델을 평가합니다.
두 모델 모두에서 추론이 동시에 실행되도록 지정할 수 있습니다.
이 코드 샘플은 Vertex Model Registry의 조정된 모델을 동일한 레지스트리의 참조 모델과 비교하여 평가합니다.
# Evaluation dataset schema:
# my_question: str
# my_context: str
parameters = {
'evaluation_dataset': DATASET,
'id_columns': ['my_context'],
'task': 'question_answering',
'autorater_prompt_parameters': {
'inference_instruction': {'column': 'my_question'},
'inference_context': {'column': 'my_context'},
},
'model_a': 'publishers/google/models/text-bison@001',
'model_a_prompt_parameters': {QUESTION: {'template': '{{my_question}}\nCONTEXT: {{my_context}}'}},
'response_column_a': 'content',
'model_b': 'projects/abc/locations/abc/models/tuned_bison',
'model_b_prompt_parameters': {'prompt': {'template': '{{my_context}}\n{{my_question}}'}},
'response_column_b': 'content',
}
예측 비교
참조 3p 모델과 비교하여 조정된 타사(3p) 모델을 평가합니다.
모델 응답을 직접 제공하여 추론을 건너뛸 수 있습니다.
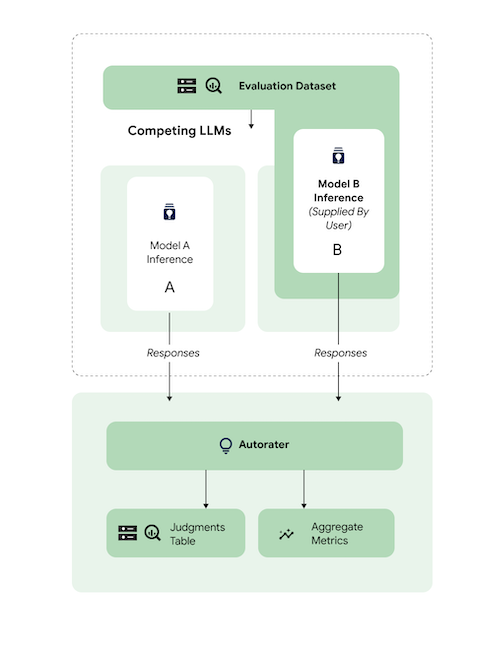
이 코드 샘플은 참조 3p 모델에 대해 조정된 3p 모델을 평가합니다.
# Evaluation dataset schema:
# my_question: str
# my_context: str
# response_b: str
parameters = {
'evaluation_dataset': DATASET,
'id_columns': ['my_context'],
'task': 'question_answering',
'autorater_prompt_parameters':
'inference_instruction': {'column': 'my_question'},
'inference_context': {'column': 'my_context'},
},
'response_column_a': 'content',
'response_column_b': 'response_b',
}
정렬 확인
지원되는 모든 작업은 자동 평가 도구 응답이 인간 선호도와 일치하는지 확인하기 위해 인간 평가자 데이터를 사용하여 벤치마킹되었습니다. AutoSxS 사용 사례를 벤치마킹하려면 정렬 집계 통계를 출력하는 AutoSxS에 직접 인간 선호도 데이터를 제공하세요.
인간 선호도 데이터 세트에 대한 정렬을 확인하려면 자동 평가 도구에 두 출력(예측 결과)을 모두 지정할 수 있습니다. 또한 추론 결과를 제공할 수도 있습니다.
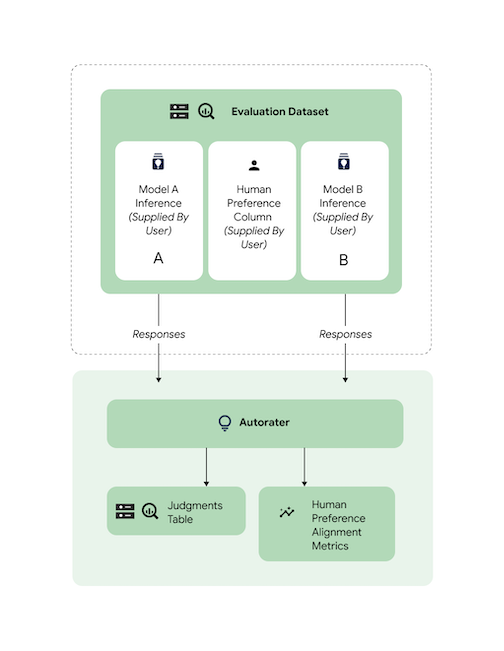
이 코드 샘플은 자동 평가 도구의 결과와 설명이 예상과 일치하는지 확인합니다.
# Evaluation dataset schema:
# my_question: str
# my_context: str
# response_a: str
# response_b: str
# actual: str
parameters = {
'evaluation_dataset': DATASET,
'id_columns': ['my_context'],
'task': 'question_answering',
'autorater_prompt_parameters': {
'inference_instruction': {'column': 'my_question'},
'inference_context': {'column': 'my_context'},
},
'response_column_a': 'response_a',
'response_column_b': 'response_b',
'human_preference_column': 'actual',
}
다음 단계
- 온라인 평가 서비스를 빠르게 실행하는 방법 알아보기. 온라인 평가 빠른 시작 사용해 보기
- 생성형 AI 모델 평가 자세히 알아보기
- 쌍별 모델 기반 평가 알아보기
- 언어 기반 모델 조정 방법 알아보기