Setelah melatih model, AutoML Translation menggunakan item dari set TEST untuk mengevaluasi kualitas dan akurasi model baru. AutoML Translation mengekspresikan kualitas model menggunakanSkor BLEU (Bilingual Evaluation Understudy), yang menunjukkan seberapa mirip teks kandidat dengan teks referensi, dengan nilai yang mendekati satu berarti lebih banyak teks yang serupa.
Skor BLEU memberikan penilaian keseluruhan terhadap kualitas model. Anda juga dapat mengevaluasi output model untuk item data tertentu dengan mengekspor kumpulan set TEST dengan prediksi model. Data yang diekspor mencakup teks referensi (dari set data asli) dan teks kandidat model.
Gunakan data ini untuk mengevaluasi kesiapan model Anda. Jika Anda tidak puas dengan tingkat kualitasnya, pertimbangkan untuk menambahkan pasangan kalimat pelatihan yang lebih banyak (dan lebih beragam). Salah satu opsi adalah menambahkan lebih banyak pasangan kalimat. Gunakan link Add Files di kolom judul. Setelah menambahkan file, latih model baru dengan mengklik tombol Train New Model di halaman Train. Ulangi proses ini sampai Anda mencapai tingkat kualitas yang cukup tinggi.
Mendapatkan evaluasi model
UI web
Buka konsol AutoML Translation dan klik ikon bola lampu di samping Models di menu navigasi sebelah kiri. Model yang tersedia akan ditampilkan. Untuk setiap model, informasi berikut disertakan: Set data (tempat model dilatih), Sumber (bahasa sumber), Target (target bahasa), Model dasar (digunakan untuk melatih model).
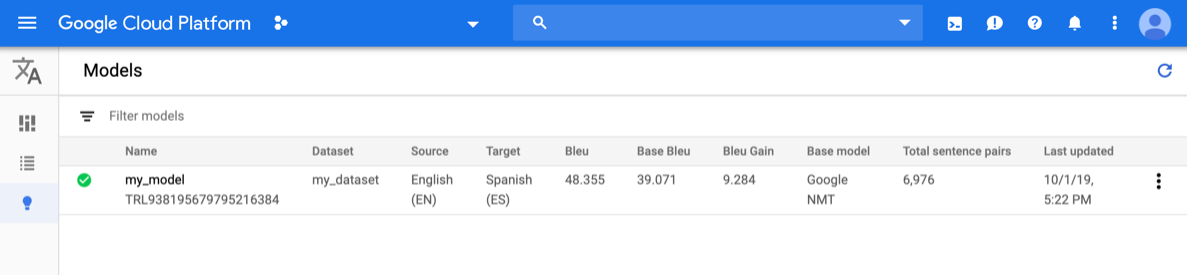
Untuk melihat model project yang berbeda, pilih project dari menu drop-down di kanan atas panel judul.
Klik baris untuk model yang ingin dievaluasi.
Opsi tab Predict tersedia.
Di sini, Anda dapat menguji model dan melihat hasilnya untuk model kustom dan model dasar yang digunakan untuk melatih.
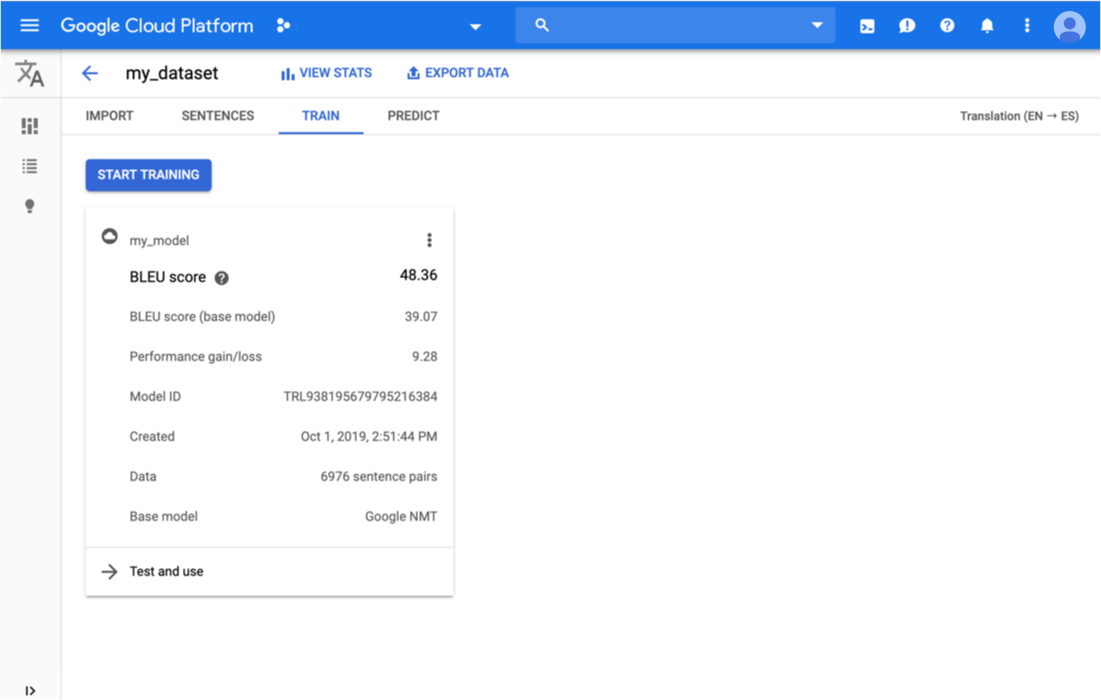
Klik tab Train tepat di bawah panel judul.
Setelah pelatihan untuk model selesai, AutoML Translation menampilkan metrik evaluasinya.
REST
Sebelum menggunakan data permintaan apa pun, lakukan penggantian sebagai berikut:
- model-name: nama lengkap model Anda. Nama lengkap model mencakup nama dan lokasi project Anda. Nama model mirip dengan contoh berikut:
projects/project-id/locations/us-central1/models/model-id. - project-id: project ID Google Cloud Platform Anda
Metode HTTP dan URL:
GET https://automl.googleapis.com/v1/model-name/modelEvaluations
Untuk mengirim permintaan Anda, perluas salah satu opsi berikut:
Anda akan melihat respons JSON yang mirip dengan berikut ini:
{
"modelEvaluation": [
{
"name": "projects/project-number/locations/us-central1/models/model-id/modelEvaluations/evaluation-id",
"createTime": "2019-10-02T00:20:30.972732Z",
"evaluatedExampleCount": 872,
"translationEvaluationMetrics": {
"bleuScore": 48.355409502983093,
"baseBleuScore": 39.071375131607056
}
}
]
}
Go
Guna mempelajari cara menginstal dan menggunakan library klien untuk AutoML Translation, silakan melihat library klien AutoML Translation. Untuk mengetahui informasi selengkapnya, silakan melihat dokumentasi referensi API Go AutoML Translation.
Untuk melakukan autentikasi ke AutoML Translation, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, baca Menyiapkan autentikasi untuk lingkungan pengembangan lokal.
Java
Guna mempelajari cara menginstal dan menggunakan library klien untuk AutoML Translation, silakan melihat library klien AutoML Translation. Untuk mengetahui informasi selengkapnya, silakan melihat dokumentasi referensi API Java AutoML Translation.
Untuk melakukan autentikasi ke AutoML Translation, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, baca Menyiapkan autentikasi untuk lingkungan pengembangan lokal.

Node.js
Guna mempelajari cara menginstal dan menggunakan library klien untuk AutoML Translation, silakan melihat library klien AutoML Translation. Untuk mengetahui informasi selengkapnya, silakan melihat dokumentasi referensi API Node.js Cloud Translation.
Untuk melakukan autentikasi ke AutoML Translation, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, baca Menyiapkan autentikasi untuk lingkungan pengembangan lokal.
Python
Guna mempelajari cara menginstal dan menggunakan library klien untuk AutoML Translation, silakan melihat library klien AutoML Translation. Untuk mengetahui informasi selengkapnya, silakan melihat dokumentasi referensi API Python Cloud Translation.
Untuk melakukan autentikasi ke AutoML Translation, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, baca Menyiapkan autentikasi untuk lingkungan pengembangan lokal.
Bahasa tambahan
C# : Ikuti Petunjuk penyiapan C# di halaman library klien, lalu buka Dokumentasi referensi AutoML Translation untuk .NET.
PHP : Ikuti Petunjuk penyiapan PHP di halaman library klien, lalu buka Dokumentasi referensi AutoML Translation untuk PHP.
Ruby : Ikuti Petunjuk penyiapan Ruby di halaman library klien, lalu buka Dokumentasi referensi AutoML Translation untuk Ruby.
Mengekspor data pengujian dengan prediksi model
Setelah melatih model, AutoML Translation menggunakan item dari set TEST untuk mengevaluasi kualitas dan akurasi model baru. Dari konsol AutoML Translation, Anda dapat mengekspor kumpulan set TEST untuk melihat perbandingan output model dengan teks referensi dari set data asli. AutoML Translation menyimpan file TSV ke bucket Google Cloud Storage, yang setiap barisnya memiliki format berikut:
Source sentence tab Reference translation tab Model candidate translation
UI web
Buka konsol AutoML Translation dan klik ikon bola lampu di sebelah kiri "Models" di menu navigasi sebelah kiri untuk menampilkan model yang tersedia.
Untuk melihat model project yang berbeda, pilih project dari menu drop-down di kanan atas panel judul.
Pilih model.
Klik tombol Export Data di kolom judul.
Masukkan jalur lengkap ke bucket Google Cloud Storage tempat Anda ingin menyimpan file .tsv yang diekspor.
Anda harus menggunakan bucket yang terkait dengan project saat ini.
Pilih model yang data TEST-nya ingin Anda ekspor.
Menu drop-down Testing set with model predictions mencantumkan model yang dilatih menggunakan set data input yang sama.
Klik Export.
AutoML Translation menulis file bernama model-name
_evaluated.tsvdi bucket Google Cloud Storage yang ditentukan.
Mengevaluasi dan membandingkan model menggunakan set pengujian baru
Dari konsol AutoML Translation, Anda dapat mengevaluasi ulang model yang ada dengan menggunakan serangkaian set data pengujian baru. Dalam satu evaluasi, Anda dapat menyertakan hingga 5 model berbeda, lalu membandingkan hasilnya.
Mengupload data pengujian ke Cloud Storage sebagainilai yang dipisahkan
tab (.tsv ) atau sebagai fileTranslation Memory eXchange (.tmx ).
AutoML Translation mengevaluasi model Anda terhadap set pengujian, lalu menghasilkan skor evaluasi. Secara opsional, Anda dapat menyimpan hasil untuk setiap model sebagai file .tsv di bucket Cloud Storage, dengan setiap baris memiliki format berikut:
Source sentence tab Model candidate translation tab Reference translation
UI web
Buka konsol AutoML Translation dan klik Models di panel navigasi sebelah kiri untuk menampilkan model yang tersedia.
Untuk melihat model project yang berbeda, pilih project dari menu drop-down di kanan atas panel judul.
Pilih salah satu model yang ingin dievaluasi.
Klik tab Evaluate tepat di bawah panel judul.
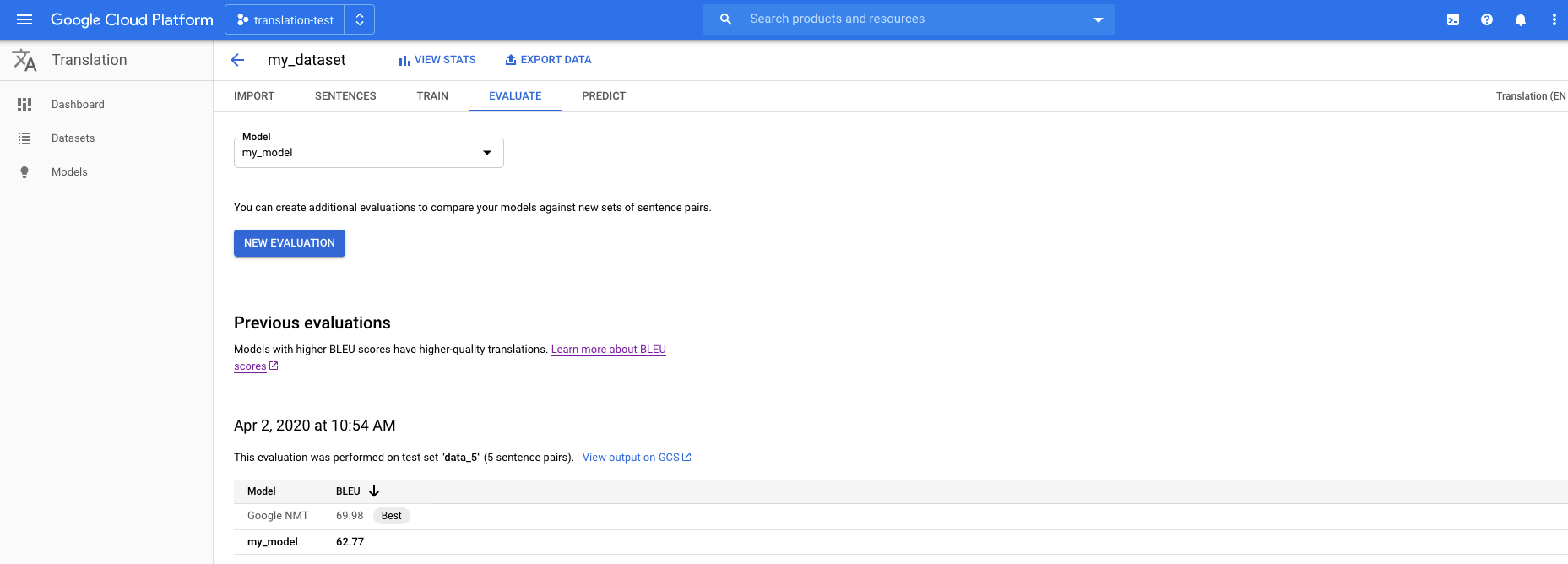
Di tab Evaluate, klik New Evaluation.
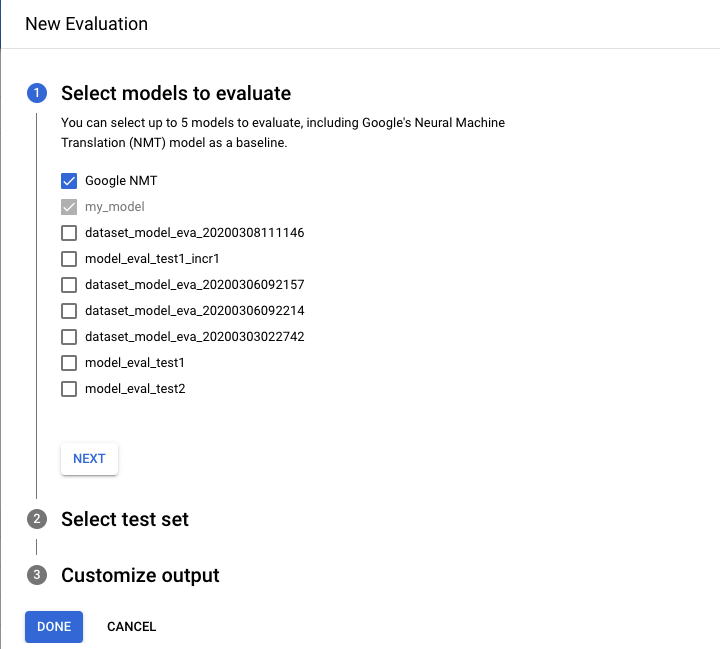
- Pilih model yang ingin dievaluasi dan dibandingkan. Model saat ini harus dipilih, dan Google NMT dipilih secara default, yang Anda dapat batalkan pilihannya.
- Tentukan nama untuk Test set name guna membantu Anda membedakannya dari evaluasi lain, lalu pilih set pengujian baru dari Cloud Storage.
- Jika Anda ingin mengekspor prediksi yang didasarkan pada set pengujian Anda, tentukan bucket Cloud Storage tempat hasil akan disimpan (tarif standar harga per karakter berlaku).
Klik Done.
AutoML Translation menampilkan skor evaluasi dalam format tabel di konsol setelah evaluasi selesai. Anda hanya dapat menjalankan satu evaluasi pada satu waktu. Jika Anda menentukan bucket untuk menyimpan hasil prediksi, AutoML Translation akan menulis file bernama model-name_test-set-name
.tsvke bucket.
Memahami Skor BLEU
BLEU (BiLingual Evaluation Understudy) adalah metrik untuk mengevaluasi teks yang diterjemahkan mesin secara otomatis. Skor BLEU adalah angka antara nol dan satu yang mengukur kesamaan teks terjemahan mesin dengan kumpulan terjemahan referensi berkualitas tinggi. Nilai 0 berarti output yang diterjemahkan mesin tidak memiliki tumpang-tindih dengan terjemahan referensi (kualitas rendah) sedangkan nilai 1 berarti tumpang-tindih yang sempurna dengan terjemahan referensi (kualitas tinggi).
Telah terbukti bahwa skor BLEU berkorelasi baik dengan penilaian manusia terhadap kualitas terjemahan. Perhatikan bahwa bahkan penerjemah manusia pun tidak mencapai skor sempurna 1,0.
AutoML menampilkan skor BLEU sebagai persentase, bukan desimal antara 0 dan 1.
Interpretasi
Mencoba membandingkan skor BLEU di berbagai korpora dan bahasa sangat tidak dianjurkan. Bahkan membandingkan skor BLEU untuk korpus yang sama tetapi dengan jumlah terjemahan referensi yang berbeda dapat sangat menyesatkan.
Namun, sebagai panduan kasar, interpretasi skor BLEU berikut (dinyatakan sebagai persentase, bukan desimal) mungkin dapat membantu.
| Skor BLEU | Interpretasi |
|---|---|
| < 10 | Hampir tidak berguna |
| 10 - 19 | Sulit untuk memahami intinya |
| 20 - 29 | Intinya jelas, tetapi memiliki kesalahan tata bahasa yang signifikan |
| 30 - 40 | Terjemahan mudah dipahami hingga cukup baik. |
| 40 - 50 | Terjemahan berkualitas tinggi |
| 50 - 60 | Terjemahan berkualitas sangat tinggi, memadai, dan fasih |
| > 60 | Kualitas terjemahan sering kali lebih baik daripada kualitas terjemahan manusia |
Gradien warna berikut dapat digunakan sebagai penafsiran skor BLEU skala umum:

Rincian matematis
Secara matematis, skor BLEU didefinisikan sebagai:
dengan
\[ precision_i = \dfrac{\sum_{\text{snt}\in\text{Cand-Corpus}}\sum_{i\in\text{snt}}\min(m^i_{cand}, m^i_{ref})} {w_t^i = \sum_{\text{snt'}\in\text{Cand-Corpus}}\sum_{i'\in\text{snt'}} m^{i'}_{cand}} \]
di mana
- \(m_{cand}^i\hphantom{xi}\) adalah jumlah i-gram dalam kandidat yang cocok dengan terjemahan referensi
- \(m_{ref}^i\hphantom{xxx}\) adalah jumlah i-gram dalam terjemahan referensi
- \(w_t^i\hphantom{m_{max}}\) adalah jumlah total i-gram dalam terjemahan kandidat
Formula ini terdiri dari dua bagian: penalti penyingkatan dan tumpang-tindih n-gram.
Penalti Penyingkatan
Penalti penyingkatan akan menghukum terjemahan yang dihasilkan terlalu pendek dibandingkan dengan panjang referensi terdekat dengan peluruhan eksponensial. Sanksi penyingkatan ini mengompensasi fakta bahwa skor BLEU tidak memiliki istilah perolehan.Tumpang-tindih N-Gram
Tumpang-tindih n-gram menghitung jumlah unigram, bigram, trigram, dan empat gram (i=1,...,4) cocok dengan pasangan n-gram dalam terjemahan referensi. Istilah ini berfungsi sebagai metrik presisi. Unigram memperhitungkan kecukupan, sedangkan n-gram yang lebih panjang memperhitungkan kefasihan terjemahan. Untuk menghindari penghitungan berlebih, jumlah n-gram dipotong ke jumlah n-gram maksimal yang terjadi dalam referensi (\(m_{ref}^n\)).
Contoh
Menghitung \(precision_1\)
Pertimbangkan kalimat referensi dan terjemahan kandidat ini:
Referensi: the cat is on the mat
Kandidat: the the the cat mat
Langkah pertama adalah menghitung kemunculan setiap unigram dalam kalimat referensi dan terjemahan kandidat. Perhatikan bahwa metrik BLEU peka terhadap huruf besar/kecil.
| Unigram | \(m_{cand}^i\hphantom{xi}\) | \(m_{ref}^i\hphantom{xxx}\) | \(\min(m^i_{cand}, m^i_{ref})\) |
|---|---|---|---|
the |
3 | 2 | 2 |
cat |
1 | 1 | 1 |
is |
0 | 1 | 0 |
on |
0 | 1 | 0 |
mat |
1 | 1 | 1 |
Jumlah total unigram dalam kandidat (\(w_t^1\)) adalah 5, jadi \(precision_1\) = (2 + 1 + 1)/5 = 0,8.
Menghitung skor BLEU
Referensi:
The NASA Opportunity rover is battling a massive dust storm on Mars .
Kandidat 1:
The Opportunity rover is combating a big sandstorm on Mars .
Kandidat 2:
A NASA rover is fighting a massive storm on Mars .
Contoh di atas terdiri dari satu referensi dan dua kandidat terjemahan. Kalimat tersebut ditokenkan sebelum menghitung skor BLEU seperti yang ditunjukkan di atas; misalnya, periode akhir dihitung sebagai token terpisah.
Untuk menghitung skor BLEU untuk setiap terjemahan, kami menghitung statistik berikut.
- Presisi N-Gram
Tabel berikut berisi presisi n-gram untuk kedua kandidat. - Penalti penyingkatan
Penalti singkatnya sama untuk kandidat 1 dan kandidat 2 karena kedua kalimatnya terdiri dari 11 token. - Skor BLEU
Perhatikan bahwa diperlukan minimal satu gram yang cocok dengan berat 4 gram untuk mendapatkan skor BLEU > 0. Karena terjemahan kandidat 1 tidak memiliki 4 gram yang cocok, terjemahan tersebut memiliki skor BLEU 0.
| Metrik | Kandidat 1 | Kandidat 2 |
|---|---|---|
| \(precision_1\) (1gram) | 8/11 | 9/11 |
| \(precision_2\) (2gram) | 4/10 | 5/10 |
| \(precision_3\) (3gram) | 2/9 | 2/9 |
| \(precision_4\) (4gram) | 0/8 | 1/8 |
| Penalti Penyingkatan | 0,83 | 0,83 |
| Skor BLEU | 0,0 | 0,27 |
Properti
BLEU adalah Metrik Berbasis Korpus
Metrik BLEU berperforma buruk saat digunakan untuk mengevaluasi setiap kalimat. Misalnya, kedua kalimat contoh tersebut mendapatkan skor BLEU yang sangat rendah meskipun keduanya menangkap sebagian besar artinya. Karena statistik n-gram untuk setiap kalimat kurang bermakna, BLEU dibuat dengan merancang metrik berbasis korpus; yaitu, statistik diakumulasikan di seluruh korpus saat menghitung skor. Perhatikan bahwa metrik BLEU yang dinyatakan di atas tidak dapat diperhitungkan untuk kalimat individual.Tidak ada perbedaan antara kata konten dan kata fungsi
Metrik BLEU tidak membedakan antara kata konten dan kata fungsi, yaitu, kata fungsi yang dihapus seperti "a" akan tetap mendapat penalti yang sama seolah-olah nama "NASA" dengan salah diganti dengan "ESA".Tidak pandai dalam menangkap makna dan gramatikalitas kalimat
Penghilangan sebuah kata, seperti kata "not", dapat mengubah polaritas kalimat. Selain itu, dengan hanya mempertimbangkan n-gram dengan n≤4 akan mengabaikan dependensi jarak jauh sehingga BLEU sering kali hanya memberikan penalti kecil untuk kalimat yang tidak memiliki tata bahasa yang baik.Normalisasi dan Tokenisasi
Sebelum menghitung skor BLEU, referensi dan terjemahan kandidat dinormalisasi dan ditokenkan. Pilihan langkah normalisasi dan tokenisasi secara signifikan memengaruhi skor akhir BLEU.