TPU v6e
En este documento se describe la arquitectura y las configuraciones admitidas de Cloud TPU v6e (Trillium).
Trillium es la última generación de aceleradores de IA de Cloud TPU. En todas las superficies técnicas, como la API y los registros, y a lo largo de este documento, Trillium se denominará v6e.
Con una superficie de 256 chips por Pod, la versión 6e comparte muchas similitudes con la 5e. Este sistema se ha optimizado para ser el producto de mayor valor para el entrenamiento, el ajuste y el servicio de transformadores, de texto a imagen y de redes neuronales convolucionales (CNN).
Arquitectura del sistema
Cada chip v6e contiene un Tensor Core. Cada Tensor Core tiene dos unidades de multiplicación de matrices (MXU), una unidad vectorial y una unidad escalar. En la siguiente tabla se muestran las especificaciones clave y sus valores de la TPU v6e en comparación con la TPU v5e.
| Especificaciones | v5e | v6e |
|---|---|---|
| Rendimiento/coste total de propiedad (TCO) (previsto) | 0,65x | 1 |
| Rendimiento máximo por chip (bf16) | 197 TFLOPS | 918 TFLOPS |
| Pico de computación por chip (Int8) | 393 TOPS | 1836 TOPs |
| Capacidad de HBM por chip | 16 GB | 32 GB |
| Ancho de banda de HBM por chip | 800 GBps | 1600 GB/s |
| Ancho de banda de interconexión entre chips (ICI) | 1600 Gbps | 3200 Gbps |
| Puertos de ICI por chip | 4 | 4 |
| DRAM por host | 512 GiB | 1536 GiB |
| Chips por host | 8 | 8 |
| Tamaño del pod de TPUs | 256 chips | 256 chips |
| Topología de interconexión | Toroide bidimensional | Toroide bidimensional |
| Cálculo máximo de BF16 por Pod | 50,63 PFLOPS | 234,9 PFLOPS |
| Ancho de banda de All-reduce por pod | 51,2 TB/s | 102,4 TB/s |
| Ancho de banda de bisección por pod | 1,6 TB/s | 3,2 TB/s |
| Configuración de NIC por host | NIC de 2 x 100 Gbps | NIC de 4 x 200 Gbps |
| Ancho de banda de la red del centro de datos por pod | 6,4 Tbps | 25,6 Tbps |
| Funciones especiales | - | SparseCore |
Configuraciones admitidas
En la siguiente tabla se muestran las formas de corte 2D admitidas en la versión 6e:
| Topología | Chips de TPU | Hosts | VMs | Tipo de acelerador (API de TPU) | Tipo de máquina (API de GKE) | Ámbito |
|---|---|---|---|---|---|---|
| 1x1 | 1 | 1/8 | 1 | v6e-1 |
ct6e-standard-1t |
Subanfitrión |
| 2x2 | 4 | 1/2 | 1 | v6e-4 |
ct6e-standard-4t |
Subanfitrión |
| 2x4 | 8 | 1 | 1 | v6e-8 |
ct6e-standard-8t |
Un solo host |
| 2x4 | 8 | 1 | 2 | - | ct6e-standard-4t |
Un solo host |
| 4x4 | 16 | 2 | 4 | v6e-16 |
ct6e-standard-4t |
Varios hosts |
| 4x8 | 32 | 4 | 8 | v6e-32 |
ct6e-standard-4t |
Varios hosts |
| 8x8 | 64 | 8 | 16 | v6e-64 |
ct6e-standard-4t |
Varios hosts |
| 8x16 | 128 | 16 | 32 | v6e-128 |
ct6e-standard-4t |
Varios hosts |
| 16x16 | 256 | 32 | 64 | v6e-256 |
ct6e-standard-4t |
Varios hosts |
Las slices con 8 chips (v6e-8) conectadas a una sola VM están optimizadas para la inferencia, lo que permite usar los 8 chips en una sola carga de trabajo de servicio. Puedes realizar inferencias multihost con Pathways en Cloud. Para obtener más información, consulta Realizar inferencias multihost con Pathways.
Para obtener información sobre el número de VMs de cada topología, consulta Tipos de VMs.
Tipos de máquinas virtuales
Cada VM de TPU v6e puede contener 1, 4 u 8 chips. Las porciones de 4 chips o menos tienen el mismo nodo de acceso a memoria no uniforme (NUMA). Para obtener más información sobre los nodos NUMA, consulta Acceso a memoria no uniforme en Wikipedia.
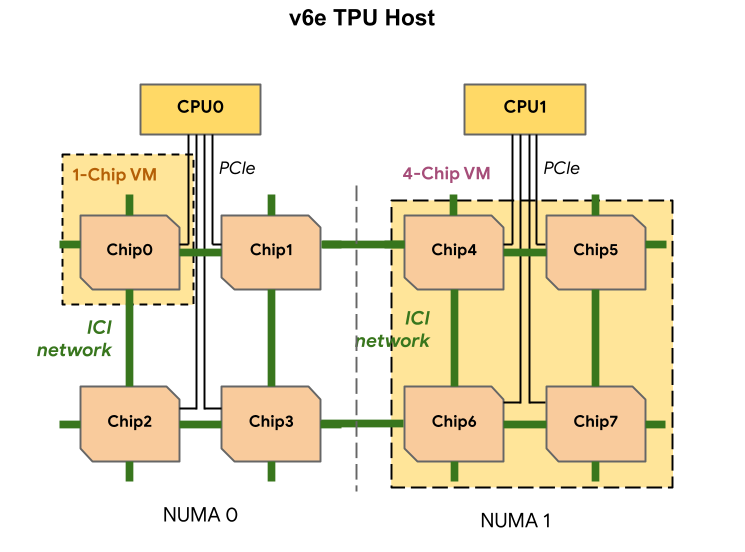
Las porciones v6e se crean con VMs de medio host, cada una con 4 chips de TPU. Esta regla tiene dos excepciones:
v6e-1: una VM con un solo chip, pensada principalmente para pruebasv6e-8: una VM de host completo optimizada para un caso práctico de inferencia con los 8 chips conectados a una sola VM.
En la siguiente tabla se comparan los tipos de máquinas virtuales de TPU v6e:
| Tipo de VM | Número de vCPUs por VM | RAM (GB) por VM | Número de nodos NUMA por VM |
|---|---|---|---|
| VM de 1 chip | 44 | 176 | 1 |
| VM de 4 chips | 180 | 720 | 1 |
| VM de 8 chips | 180 | 1440 | 2 |
Especificar la configuración de v6e
Cuando asignas un segmento de TPU v6e mediante la API de TPU, especificas su tamaño y forma con el parámetro AcceleratorType.
Si usas GKE, utiliza la marca --machine-type para especificar un tipo de máquina que admita la TPU que quieras usar. Para obtener más información, consulta el artículo Planificar las TPUs en GKE de la documentación de GKE.
Usar AcceleratorType
Cuando asignas recursos de TPU, usas AcceleratorType para especificar el número de Tensor Cores de un segmento. El valor que especifiques para AcceleratorType es una cadena con el formato v$VERSION-$TENSORCORE_COUNT.
Por ejemplo, v6e-8 especifica un segmento de TPU v6e con 8 Tensor Cores.
En el siguiente ejemplo se muestra cómo crear un segmento de TPU v6e con 32 TensorCores mediante AcceleratorType:
gcloud
$ gcloud compute tpus tpu-vm create tpu-name \ --zone=zone \ --accelerator-type=v6e-32 \ --version=v2-alpha-tpuv6e
Consola
En la Google Cloud consola, ve a la página TPUs:
Haz clic en Crear TPU.
En el campo Name (Nombre), introduce un nombre para tu TPU.
En el cuadro Zona, selecciona la zona en la que quieras crear la TPU.
En el cuadro Tipo de TPU, selecciona
v6e-32.En el cuadro Versión de software de TPU, selecciona
v2-alpha-tpuv6e. Al crear una máquina virtual de TPU de Cloud, la versión del software de TPU especifica la versión del tiempo de ejecución de TPU que se va a instalar. Para obtener más información, consulta Imágenes de VMs de TPU.Haz clic en el interruptor Habilitar colas.
En el campo Queued resource name (Nombre del recurso en cola), introduce un nombre para tu solicitud de recurso en cola.
Haz clic en Crear.