TPU v6e
Este documento descreve a arquitetura e as configurações disponíveis no Cloud TPU v6e (Trillium).
O Trillium é o acelerador de IA mais recente do Cloud TPU. Em todas as plataformas técnicas, como a API e os registros, e ao longo deste documento, o Trillium será chamado de v6e.
Com 256 chips por pod, a v6e compartilha muitas semelhanças com a v5e. Esse sistema é otimizado para ser o produto de maior valor para treinamento, ajuste e disponibilização de transformadores, conversão de texto em imagem e redes neurais convolucionais (CNNs).
Arquitetura do sistema
Cada chip da v6e contém um TensorCore. Cada TensorCore tem duas unidades de multiplicação de matriz (MXU), uma unidade vetorial e uma escalar. A tabela a seguir mostra as principais especificações e os valores da TPU v6e em comparação com a TPU v5e.
| Especificação | v5e | v6e |
|---|---|---|
| Desempenho/custo total de propriedade (TCO) (esperado) | 0,65x | 1 |
| Pico de computação por chip (bf16) | 197 TFLOPs | 918 TFLOPs |
| Pico de computação por chip (Int8) | 393 TOPs | 1836 TOPs |
| Capacidade de HBM por chip | 16 GB | 32 GB |
| Largura de banda de HBM por chip | 800 GBps | 1600 GBps |
| Largura de banda da interconexão entre chips (ICI) | 1600 Gbps | 3200 Gbps |
| Portas de ICI por chip | 4 | 4 |
| DRAM por host | 512 GiB | 1536 GiB |
| Chips por host | 8 | 8 |
| Tamanho do Pod de TPU | 256 chips | 256 chips |
| Topologia de interconexão | Toro 2D | Toro 2D |
| Pico de computação de BF16 por pod | 50,63 PFLOPs | 234,9 PFLOPs |
| Largura de banda de redução total por pod | 51,2 TB/s | 102,4 TB/s |
| Largura de banda de bissecção por pod | 1,6 TB/s | 3,2 TB/s |
| Configuração de NIC por host | 2 NICs de 100 Gbps | 4 NICs de 200 Gbps |
| Largura de banda da rede do data center por pod | 6,4 Tbps | 25,6 Tbps |
| Recursos especiais | - | SparseCore |
Configurações aceitas
A tabela abaixo mostra as formas de fração 2D disponíveis na v6e:
| Topologia | Chips de TPU | Hosts | VMs | Tipo de acelerador (API TPU) | Tipo de máquina (API GKE) | Escopo |
|---|---|---|---|---|---|---|
| 1x1 | 1 | 1/8 | 1 | v6e-1 |
ct6e-standard-1t |
Subhost |
| 2x2 | 4 | 1/2 | 1 | v6e-4 |
ct6e-standard-4t |
Subhost |
| 2x4 | 8 | 1 | 1 | v6e-8 |
ct6e-standard-8t |
Host único |
| 2x4 | 8 | 1 | 2 | - | ct6e-standard-4t |
Host único |
| 4x4 | 16 | 2 | 4 | v6e-16 |
ct6e-standard-4t |
Vários hosts |
| 4x8 | 32 | 4 | 8 | v6e-32 |
ct6e-standard-4t |
Vários hosts |
| 8x8 | 64 | 8 | 16 | v6e-64 |
ct6e-standard-4t |
Vários hosts |
| 8x16 | 128 | 16 | 32 | v6e-128 |
ct6e-standard-4t |
Vários hosts |
| 16x16 | 256 | 32 | 64 | v6e-256 |
ct6e-standard-4t |
Vários hosts |
As frações com oito chips (v6e-8) conectadas a uma única VM são otimizadas para
inferência e permitem que todos os oito chips sejam usados em uma única carga de trabalho de disponibilização. É possível
realizar inferência de vários hosts com o Pathways on Cloud. Para mais informações, consulte
Realizar inferência de vários hosts usando o Pathways.
Para informações sobre o número de VMs em cada topologia, consulte Tipos de VM.
Tipos de VM
Cada VM de TPU v6e pode conter um, quatro ou 8 chips. As frações de quatro chips e menores têm o mesmo nó de acesso à memória não uniforme (NUMA). Para mais informações sobre nós NUMA, consulte Acesso à memória não uniforme na Wikipédia.
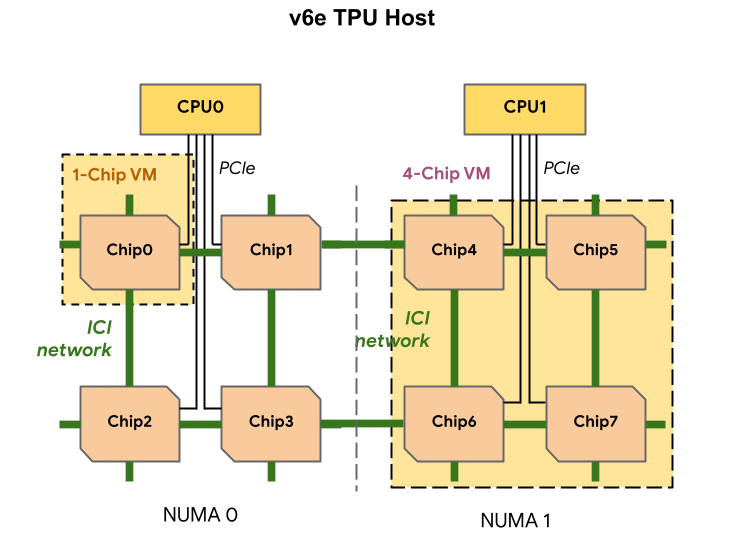
As frações da v6e são criadas usando VMs de meio host, cada uma com quatro chips de TPU. Há duas exceções a essa regra:
v6e-1: uma VM com apenas um chip, destinada principalmente a testes.v6e-8: uma VM de host completo otimizada para um caso de uso de inferência com todos os oito chips conectados a uma única VM.
A tabela abaixo mostra uma comparação dos tipos de VM da TPU v6e:
| Tipo de VM | Número de vCPUs por VM | RAM (GB) por VM | Número de nós NUMA por VM |
|---|---|---|---|
| VM de um chip | 44 | 176 | 1 |
| VM de quatro chips | 180 | 720 | 1 |
| VM de oito chips | 180 | 1440 | 2 |
Especificar a configuração da v6e
Ao alocar uma fração de TPU v6e usando a API TPU, especifique o tamanho e
o formato dela usando o parâmetro AcceleratorType.
Se você estiver usando o GKE, use a flag --machine-type para especificar um
tipo de máquina que aceite a TPU que você quer usar. Para mais informações, consulte
Planejar TPUs no GKE na documentação
do GKE.
Usar AcceleratorType
Ao alocar recursos de TPU, use AcceleratorType para especificar o número
de TensorCores em uma fração. O valor especificado para
AcceleratorType é uma string com o formato: v$VERSION-$TENSORCORE_COUNT.
Por exemplo, v6e-8 especifica uma fração de TPU v6e com oito TensorCores.
O exemplo abaixo mostra como criar uma fração de TPU v6e com 32 TensorCores
usando AcceleratorType:
gcloud
$ gcloud compute tpus tpu-vm create tpu-name \ --zone=zone \ --accelerator-type=v6e-32 \ --version=v2-alpha-tpuv6e
Console
No console do Google Cloud , acesse a página TPUs:
Clique em Criar TPU.
No campo Nome, insira um nome para a TPU.
Na caixa Zona, selecione a zona em que você quer criar a TPU.
Na caixa Tipo de TPU, selecione
v6e-32.Na caixa Versão do software de TPU, selecione
v2-alpha-tpuv6e. Ao criar uma VM do Cloud TPU, a versão do software de TPU especifica a versão do ambiente de execução da TPU que será instalada. Para mais informações, consulte Imagens de VM de TPU.Clique no botão Ativar enfileiramento.
No campo Nome do recurso em fila, digite um nome para a solicitação de recurso em fila.
Clique em Criar.