TPU v6e
Este documento descreve a arquitetura e as configurações suportadas da Cloud TPU v6e (Trillium).
O Trillium é o acelerador de IA de última geração da Cloud TPU. Em todas as superfícies técnicas, como a API e os registos, e ao longo deste documento, o Trillium vai ser referido como v6e.
Com uma área de 256 chips por Pod, a v6e partilha muitas semelhanças com a v5e. Este sistema está otimizado para ser o produto de maior valor para a preparação, o ajuste preciso e a publicação de transformadores, texto para imagem e redes neurais convolucionais (CNN).
Arquitetura do sistema
Cada chip v6e contém um TensorCore. Cada TensorCore tem 2 unidades de multiplicação de matrizes (MXU), uma unidade vetorial e uma unidade escalar. A tabela seguinte mostra as especificações principais e os respetivos valores para a TPU v6e em comparação com a TPU v5e.
| Especificação | v5e | v6e |
|---|---|---|
| Desempenho/custo total de propriedade (TCO) (previsto) | 0,65x | 1 |
| Capacidade de computação máxima por chip (bf16) | 197 TFLOPs | 918 TFLOPs |
| Pico de computação por chip (Int8) | 393 TOPs | 1836 TOPs |
| Capacidade de HBM por chip | 16 GB | 32 GB |
| Largura de banda da HBM por chip | 800 GBps | 1600 GBps |
| Largura de banda de interligação entre chips (ICI) | 1600 Gbps | 3200 Gbps |
| Portas ICI por chip | 4 | 4 |
| DRAM por anfitrião | 512 GiB | 1536 GiB |
| Chips por anfitrião | 8 | 8 |
| Tamanho do pod TPU | 256 chips | 256 chips |
| Topologia de interligação | Toro 2D | Toro 2D |
| BF16 peak compute per Pod | 50,63 PFLOPs | 234,9 PFLOPs |
| Largura de banda de redução total por Pod | 51,2 TB/s | 102,4 TB/s |
| Largura de banda de bissecção por agrupamento | 1,6 TB/s | 3,2 TB/s |
| Configuração da NIC por anfitrião | 2 x NIC de 100 Gbps | NIC de 4 x 200 Gbps |
| Largura de banda da rede do centro de dados por Pod | 6,4 Tbps | 25,6 Tbps |
| Funcionalidades especiais | - | SparseCore |
Configurações suportadas
A tabela seguinte mostra os formatos de fatias 2D suportados para v6e:
| Topologia | Chips de TPU | Anfitriões | VMs | Tipo de acelerador (API TPU) | Tipo de máquina (API GKE) | Âmbito |
|---|---|---|---|---|---|---|
| 1x1 | 1 | 1/8 | 1 | v6e-1 |
ct6e-standard-1t |
Subanfitrião |
| 2x2 | 4 | 1/2 | 1 | v6e-4 |
ct6e-standard-4t |
Subanfitrião |
| 2x4 | 8 | 1 | 1 | v6e-8 |
ct6e-standard-8t |
Anfitrião único |
| 2x4 | 8 | 1 | 2 | - | ct6e-standard-4t |
Anfitrião único |
| 4x4 | 16 | 2 | 4 | v6e-16 |
ct6e-standard-4t |
Vários anfitriões |
| 4x8 | 32 | 4 | 8 | v6e-32 |
ct6e-standard-4t |
Vários anfitriões |
| 8x8 | 64 | 8 | 16 | v6e-64 |
ct6e-standard-4t |
Vários anfitriões |
| 8x16 | 128 | 16 | 32 | v6e-128 |
ct6e-standard-4t |
Vários anfitriões |
| 16x16 | 256 | 32 | 64 | v6e-256 |
ct6e-standard-4t |
Vários anfitriões |
As fatias com 8 chips (v6e-8) anexadas a uma única VM estão otimizadas para a inferência, o que permite que todos os 8 chips sejam usados numa única carga de trabalho de publicação. Pode
realizar inferência com vários anfitriões usando o Pathways on Cloud. Para mais informações, consulte o artigo
Realize a inferência em vários anfitriões com o Pathways
Para obter informações sobre o número de VMs para cada topologia, consulte o artigo Tipos de VMs.
Tipos de VMs
Cada VM de TPU v6e pode conter 1, 4 ou 8 chips. As fatias com 4 chips ou menos têm o mesmo nó de acesso à memória não uniforme (NUMA). Para mais informações acerca dos nós NUMA, consulte o artigo Acesso à memória não uniforme na Wikipédia.
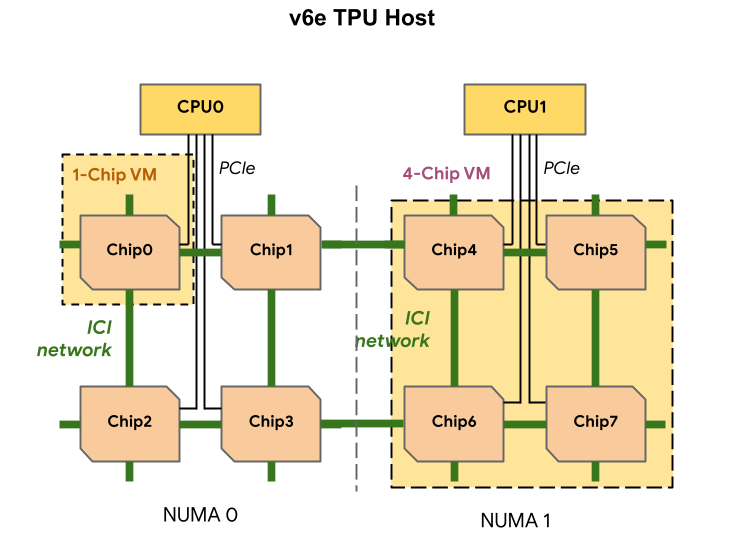
As fatias v6e são criadas com VMs de meio anfitrião, cada uma com 4 chips de TPU. Existem duas exceções a esta regra:
v6e-1: uma VM com apenas um chip, destinada principalmente a testesv6e-8: Uma VM de anfitrião completo otimizada para um exemplo de utilização de inferência com todos os 8 chips anexados a uma única VM.
A tabela seguinte mostra uma comparação dos tipos de VMs de TPUs v6e:
| Tipo de VM | Número de vCPUs por VM | RAM (GB) por MV | Número de nós NUMA por VM |
|---|---|---|---|
| VM de 1 chip | 44 | 176 | 1 |
| VM de 4 chips | 180 | 720 | 1 |
| VM de 8 chips | 180 | 1440 | 2 |
Especifique a configuração v6e
Quando atribui uma fatia de TPU v6e através da API TPU, especifica o respetivo tamanho e
formato através do parâmetro AcceleratorType.
Se estiver a usar o GKE, use a flag --machine-type para especificar um tipo de máquina que suporte a TPU que quer usar. Para mais informações, consulte o artigo Planeie TPUs no GKE na documentação do GKE.
Usar AcceleratorType
Quando atribui recursos de TPUs, usa AcceleratorType para especificar o número de TensorCores numa fatia. O valor especificado para
AcceleratorType é uma string com o formato: v$VERSION-$TENSORCORE_COUNT.
Por exemplo, v6e-8 especifica uma fatia de TPU v6e com 8 TensorCores.
O exemplo seguinte mostra como criar uma fatia de TPU v6e com 32 TensorCores
usando AcceleratorType:
gcloud
$ gcloud compute tpus tpu-vm create tpu-name \ --zone=zone \ --accelerator-type=v6e-32 \ --version=v2-alpha-tpuv6e
Consola
Na Google Cloud consola, aceda à página TPUs:
Clique em Criar TPU.
No campo Nome, introduza um nome para a TPU.
Na caixa Zona, selecione a zona onde quer criar a TPU.
Na caixa Tipo de TPU, selecione
v6e-32.Na caixa Versão do software da TPU, selecione
v2-alpha-tpuv6e. Quando cria uma VM do Cloud TPU, a versão do software da TPU especifica a versão do tempo de execução da TPU a instalar. Para mais informações, consulte o artigo Imagens de VMs de TPUs.Clique no botão de ativar/desativar Ativar colocação em fila.
No campo Nome do recurso em fila, introduza um nome para o seu pedido de recurso em fila.
Clique em Criar.
O que se segue?
- Execute a formação e a inferência com a TPU v6e